锦书在线
80.52M · 2026-03-21

2024 年开始,随着 Cursor 的火爆,ChatGPT、Claude、Gemini 都推出了自家的 AI CLI
那种勃勃生机、万物竞发的景象,犹在眼前。
随着各家 AI CLI 的快速迭代,每个工具都有其独特的配置系统
这些配置虽然格式相似(大多基于 Markdown 和 JSON),但目录结构、文件格式和转换逻辑却各不相同。
比如 Gemini、IFlow、Codex 是 TOML 格式,Cursor、Claude Code、CodeBuddy、OpenCode 是 JSON 格式。
当我想在不同工具间切换时,面临着一个尴尬的现实:我需要手动复制粘贴、修改格式、调整路径,耗时且容易出错。
特别是 Commands 的参数语法($ARGUMENTS vs {{args}})、MCP 的配置格式(JSON vs TOML vs JSONC)、以及不同工具对环境变量的处理方式都存在细微差异。
这正是我开发 ai-sync 的初衷——一个能够自动化处理这些格式转换和路径解析的工具,让我可以在不同 AI CLI 之间无缝迁移配置,专注于代码本身而不是配置文件。
源码:github.com/beixiyo/ai-…
安装
npm i -g @jl-org/ai-sync
使用 交互式执行,只需要一行命令即可同步配置到不同工具:
$ ai-sync
? 选择要迁移到的工具(使用方向键导航,空格选择,回车确认):
◯ Cursor
⬤ Claude Code
⬤ OpenCode
◯ Gemini CLI
◯ IFlow CLI
◯ Codex
◯ CodeBuddy
? 配置到当前项目(否则为全局配置)? (y/N) n
? 是否自动覆盖已存在的文件? (y/N) y
开始迁移...
迁移 Commands... (2/2)
迁移 Skills... (1/1)
迁移 Rules... (1/1)
迁移 MCP... (1/1)
迁移 Agents... (1/1)
--- 迁移完成 ---
工具: Claude Code, OpenCode
成功: 15
跳过: 3
错误: 0
整个工具都是 AI 驱动开发的,尤其是文档、测试等,我将着重教大家如何使用这些 AI 工具。
尤其是 Commands、Skills、Hooks、Agents、MCP 这些配置的意思,让大家不会一头雾水。
定义给 AI 的内置提示词,相当于给 AI 设定的"系统指令"或"行为准则"。
AGENTS.md(项目级别)
CLAUDE.mdGEMINI.mdCODEBUDDY.md# 项目编码规范
- 样式优先使用 TailwindCSS
与 Rules 基本一致,但支持交互式调用和参数传递。通过在输入框输入 / 唤起命令,可以传递参数并接收结果。
$ARGUMENTS、$1)---
description: 创建新的 React 组件
---
创建一个名为 `$1` 的 React 组件,包含以下功能:
- 使用 TypeScript
- 支持 className 和 style 属性
- 导出为具名导出
组件路径:`src/components/$1/index.tsx`
标准化流程(SOP)或领域知识教学,教 AI 理解某个领域的知识,让它按照步骤执行任务,还可以包含脚本引用。
description、name)excel-skill、pdf-skill、code-review-skill 等---
description: Excel 文件处理技能包
name: Excel Processing
---
## Excel 文件读取
使用以下步骤读取 Excel 文件:
1. 检查文件格式(.xlsx, .xls)
2. 使用 pandas 读取数据
3. 验证数据完整性
## Excel 数据处理
[数据处理的详细步骤...]
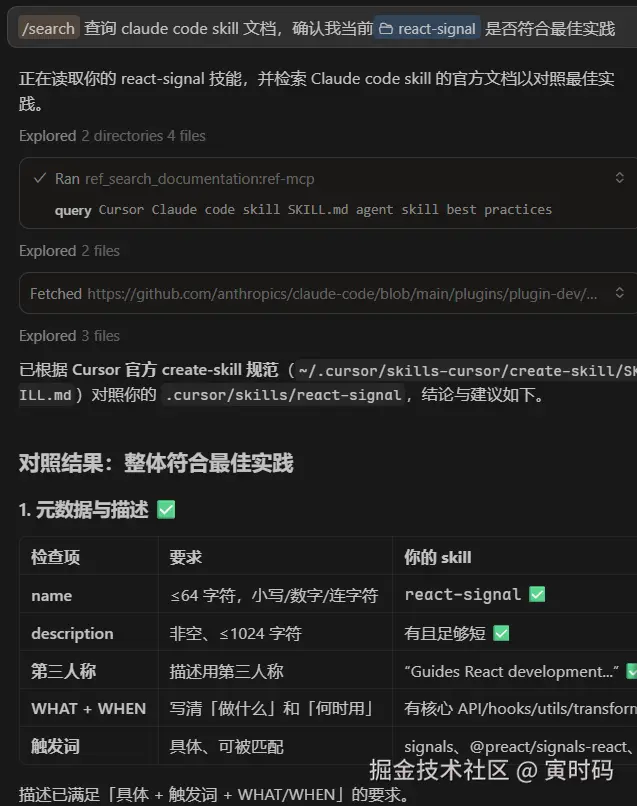
| 检查项 | 要求 |
|---|---|
| name | ≤64 字符,小写/数字/连字符 |
| description | 非空、≤1024 字符 |
| 第三人称 | 描述用第三人称 |
| WHAT + WHEN | 写清「做什么」和「何时用」 |
| 触发词 | 具体、可被匹配 |
描述需满足「具体 + 触发词 + WHAT/WHEN」的要求。
| 检查项 | 要求 |
|---|---|
| SKILL.md 行数 | 建议 <500 行,通过 references 文件夹引用其他文件来实现渐进式披露 |
| 渐进式披露 | 主文件放要点,细节放引用 references 文件夹,脚本放在 scripts 文件夹 |
| 引用层级 | 仅一层引用 |
| 术语一致 | 全文统一用语 |
在 AI 执行的不同时间点自动执行操作,类似于 Git hooks 或 Web 框架的生命周期钩子。
settings.json),指定触发时机和执行的命令{
"version": 1,
"hooks": {
"afterFileEdit": [
{
"command": "bash ..."
}
]
}
}
不占用主上下文的子代理,专注于执行特定任务,然后将结果返回给主代理。
---
description: 代码搜索 Agent
mode: subagent
... 其他元数据,比如权限等,各家配置不同
---
你是一个代码搜索专家,专注于在代码库中查找相关代码片段
模型上下文协议,本质上是调用本地 stdio 进程或远程接口,但初始会加载所有工具描述,非常浪费 Token。
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/project"]
},
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"]
}
}
}
| 术语 | 本质 | 参数支持 | 自动调用 | Token 消耗 | 适用场景 |
|---|---|---|---|---|---|
| Rules | 内置提示词 | -- | 低 | 全局规范、项目约定 | |
| Commands | 可调用提示词 | 无 | 常用任务、重复操作 | ||
| Skills | SOP/领域知识 | 低 | 标准化流程、特定领域技能、脚本引用 | ||
| Hooks | 生命周期钩子 | -- | 无 | 自动化工作流、代码质量保证、关键记录... | |
| Agents | 子代理 | -- | 低 | 任务分解、专注执行、结果返回 | |
| MCP | 外部工具调用 | 高 | 扩展能力、复杂操作、通常实现本地无法实现的复杂功能 |
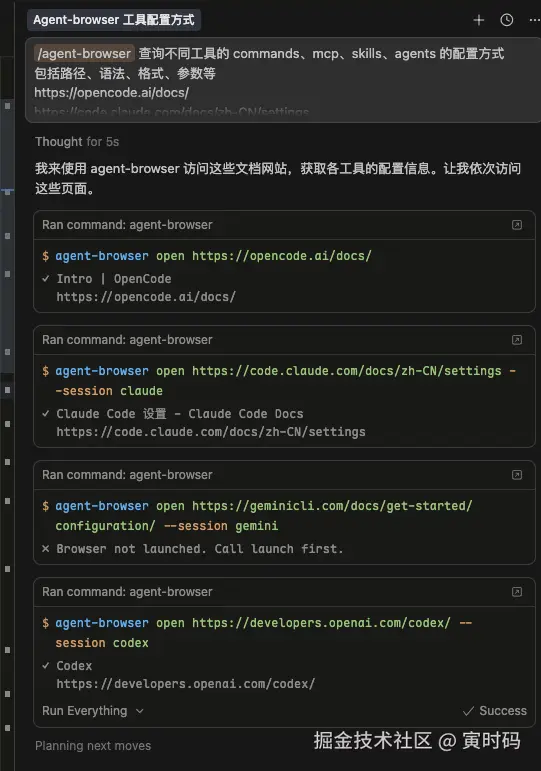
以下面这些工具为例,查询它们的配置文档:
但是都用 AI 了,我还自己查吗?这不是太麻烦了吗?
所以有两种选择:
来比较一下这两种方式的优缺点:
为了确保查询的文档准确,所以我选择了第二种方式,打开浏览器查询。
agent-browser 是 Vercel Labs 开源的、面向 AI Agent 的无头浏览器自动化 CLI,采用 Rust CLI + Node 守护进程架构,默认使用 Chromium。
安装
npm install -g agent-browser
agent-browser install # 下载 Chromium
Linux 需安装系统依赖时:agent-browser install --with-deps(或 npx playwright install-deps chromium)。
推荐工作流(Snapshot + Ref)
agent-browser open example.com
agent-browser snapshot -i # -i 仅交互元素,减少输出
button "Submit" [ref=e2]、textbox "Email" [ref=e3] 的 ref,用 @e2、@e3 操作:
agent-browser click @e2
agent-browser fill @e3 "test@example.com"
agent-browser get text @e1
snapshot,用新 ref 继续操作。Ref 方式对 AI 友好:确定性、无需重新查 DOM,且 snapshot 输出紧凑,利于节省 Token。
常用命令速览
| 类型 | 命令示例 |
|---|---|
| 导航 | agent-browser open <url>、back、forward、reload |
| 快照 | agent-browser snapshot(可选 -i、-c、-d 深度、-s "#selector") |
| 点击/输入 | click @e2、fill @e3 "文本"、type、press Enter |
| 查询 | get text @e1、get url、get title |
| 等待 | wait 2000、wait --text "Welcome"、wait <selector> |
| 截图/PDF | screenshot [path]、screenshot --full、pdf <path> |
| 多会话 | --session name 或 AGENT_BROWSER_SESSION=name |
| 持久配置 | --profile ~/.my-profile 持久化 cookies/登录态 |
| Agent 输出 | 加 --json 得到机器可读结果,便于 AI 解析 |
与 AI 协作时
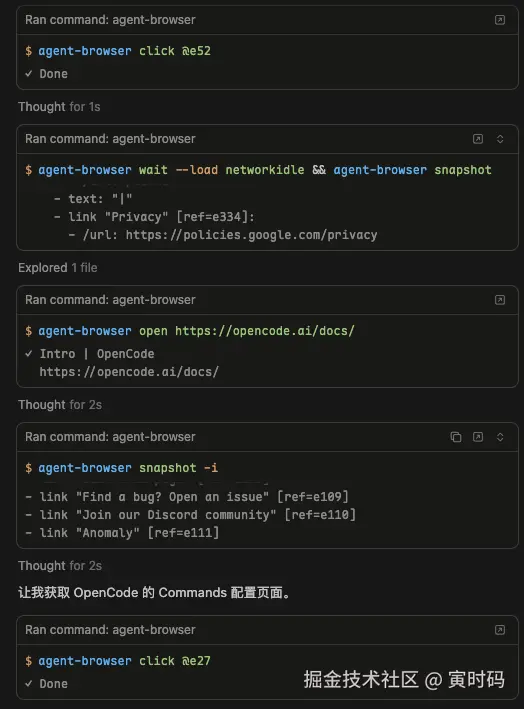
open → snapshot -i --json,让 AI 解析树和 ref;click @ex、fill @ex "..." 等按 ref 执行;is visible @ex、is enabled @ex 等。更多命令与选项见官方文档:agent-browser.dev 或 GitHub README。
来看看示例:
我把链接发送给他,让他自己查询文档总结给我
他自己能点击页面查看更多内容,比如图中的 click @e52
重要提醒:AI 提供的内容不可完全信赖。 在收集到各工具的配置规则后,我逐一访问官方网站进行了验证。以下是我整理的核心配置规则文档。
各工具 Commands 配置对比:
| 特性 | Gemini CLI | Cursor | Claude Code | CodeBuddy | OpenCode | Codex CLI |
|---|---|---|---|---|---|---|
| 文件格式 | TOML | Markdown | Markdown | Markdown | Markdown / JSON | TOML / YAML |
| 项目位置 | .gemini/commands/ | .cursor/commands/ | .claude/commands/ | .codebuddy/commands/ | .opencode/commands/ | .codex/prompts/ |
| 全局位置 | ~/.gemini/commands | ~/.cursor/commands/ | ~/.claude/commands/ | ~/.codebuddy/commands/ | ~/.config/opencode/commands/ | ~/.codex/prompts/ |
| 参数语法 | {{args}} | 无特殊语法 | $ARGUMENTS, $1, $2 | $ARGUMENTS, $1, $2 | $ARGUMENTS, $1, $2 | $ARGUMENTS, $1, $2, 命名参数 |
| Shell执行 | !{command} | 不支持 | !command`` (需声明 allowed-tools) | !command`` (需声明 allowed-tools) | !command`` (无需声明) | 配置文件白名单 |
| 文件引用 | @{filepath} | 不支持 | @filename | @filename | @filename | @filename |
各工具 Skills 配置对比:
Claude Code 的 Skills 存储在 .claude/skills/<skill_name>/SKILL.md,支持 YAML frontmatter 配置名称、描述、可用的工具列表、运行模型等。
OpenCode 兼容 Claude Code 的 Skills 格式,存储在 .opencode/skills/<name>/SKILL.md 和 ~/.config/opencode/skills/<name>/SKILL.md。
各工具 Rules 配置对比:
Cursor 使用 MDC(Markdown Components)格式,存储在 .cursor/rules/ 目录下的多个文件中。
Claude Code 使用单个 Markdown 文件,全局存储在 ~/.claude/CLAUDE.md,项目存储在 CLAUDE.md 或 .claude/CLAUDE.md。
Gemini CLI 同样使用单个 Markdown 文件,全局存储在 ~/.gemini/GEMINI.md。
各工具 MCP 配置对比:
MCP(Model Context Protocol)允许 AI 工具与外部服务集成。各工具的配置文件位置和格式差异较大:
| 工具 | 配置文件路径 | 结构 | Local MCP | Remote MCP |
|---|---|---|---|---|
| Cursor | ~/.cursor/mcp.json | {"mcpServers": {...}} | command, args, env | url, headers |
| Claude Code | ~/.claude.json | {"mcpServers": {...}} | command, args | url, type |
| OpenCode | ~/.config/opencode/opencode.jsonc | {"mcp": {...}} | type: "local", command[] | type: "remote", url |
| Gemini CLI | ~/.gemini/settings.json | {"mcpServers": {...}} | command, args, env | httpUrl, type |
关键配置差异总结:
OpenCode 使用 "mcp" 作为根字段,而其他工具使用 "mcpServers"。OpenCode 的 Local MCP 命令格式是数组形式。Gemini 的远程地址使用 httpUrl 而非 url。OpenCode 支持 enabled 字段控制 MCP 开关。
这些配置规则的整理,为后续的迁移逻辑设计奠定了基础。
现在 AI 工具到处都是,已经渗透到了工作的方方面面中。但先别急着嗨,问问自己:你的 AI 是在「写代码」,还是在「猜代码」?
很多人用 AI 的姿势是这样的:打开 Chat 框,扔一句“帮我实现个用户登录”,然后等着 AI 吐出一堆看着像那么回事、跑起来全是 Bug 的代码。接着就是无尽的“改一下这个”、“不对是那个”,最后 Token 爆炸,心态崩了,还得自己重写。
这不叫 AI 编程,这叫抽奖。
真正的高效 AI 交互,不是靠模型抽卡,而是靠工作流(Workflow)。我花了大半年时间调试我的 Agent 技能包(Skills),总结出了一套拒绝幻觉、高信噪比的交互模式。今天不聊虚的,直接把我的核心配置摊开来讲。
很多人觉得跟 AI 聊计划是浪费时间。大错特错。
没有计划的 AI 就是个无头苍蝇。写个小 Demo 还行,一旦涉及多文件改动,AI 经常写着写着就忘了上下文,或者把 A 文件的改动覆盖了 B 文件的逻辑。
在此之前,我会要求 AI 必须先读取 invoke-plan 技能。
---
name: invoke-plan
description: 当用户提出复杂需求或大型功能开发、提到"计划"/"规划"/"任务分解"等关键词、或需要将模糊需求转化为具体执行步骤时使用。创建自驱动的分步执行计划,实时更新进度
---
## Rules
创建自驱动的分步执行计划,实时更新进度
## Execution Steps
1. 需求澄清:询问背景、目标、技术栈(已明确则跳过)
2. 计划创建:生成 `/plan/<plan-name>.md`,包含背景、Todo Checklist、进度更新
3. 逐步执行:每次执行一个步骤,完成后更新计划
4. 等待确认:每步完成后等待验收确认再进行下一步
遇到复杂需求(比如“实现 Commands 迁移逻辑”),不要直接写代码。必须先生成一个 /plan/commands-migration.md 文件。
这个计划文件不仅仅是给人看的,更是给 AI 的外部存储器。
# 错误示范
User: 帮我实现 commands 工具迁移的代码。
AI: 好的,这是代码... (直接生成,大概率忽略了参数格式差异)
# 正确姿势 (基于 invoke-plan skill)
AI: 收到。这是一个复杂任务,我将创建一个执行计划 `/plan/commands-migration.md`:
1. [ ] 分析 Cursor 与 Claude Code 的 Commands 格式差异
2. [ ] 编写 Markdown 解析器
3. [ ] 实现参数占位符转换 ($ARGUMENTS -> $1)
4. [ ] 编写单元测试
...
请确认计划,确认后我将执行第一步。随后我会跟踪进度,并更新计划文件。
这样做的最大好处是:随时可以中断,随时可以恢复。 哪怕你关机睡觉,第二天回来,AI 读一下 plan 文件,立马就能接上进度。
AI 最让人头疼的就是幻觉。尤其是遇到新的库或者不熟悉的 API,它特别喜欢一本正经地胡说八道。
比如你要用 Hono 写后端,AI 可能会凭记忆给你编一个不存在的 hono.useCustomMiddleware()。
很多 AI 助手(如 Cursor、ChatGPT)都自带 Web Search 功能,那为什么还需要额外的工具?
为了解决这个问题,我引入了一系列专门为 AI 优化过的 MCP 工具,它们各司其职:
Context7 MCP
Ref MCP
ref_search_documentation) 和网页阅读 (ref_read_url) 能力。Grep.app MCP (gh-grep-mcp)
Exa MCP (search-mcp)
基于这些工具,我定义了一套严格的 Search 优先级策略,写在 search/SKILL.md 里。
---
name: search
description: 当需要查资料、找文档、搜代码示例或联网检索时使用。按优先级选择工具,仅在上述工具都无结果时才使用 Web Search
---
# 搜索策略
按**优先级**选择工具,避免一上来就用 Web Search。只有当前述工具都查不到或明确需要实时/新闻类信息时,才使用 Web Search
## 工具与优先级
| 优先级 | 工具 | 作用 | 适用场景 |
|--------|------|------|----------|
| 1 | **ref-mcp** | 查询库/框架/API 的**官方文档** | 语法、API 签名、配置项、概念说明 |
| 1 | **context7-mcp** | 查询库/框架的**文档与代码示例**(可与 ref 二选一或互补) | 文档 + 示例代码、用法、最佳实践 |
| 2 | **gh** (CLI) | 查询 **GitHub 仓库/文件/分支/Issue/PR** | 已知仓库名、看源码、看 Issue/PR、仓库元信息 |
| 3 | **gh-grep-mcp** | 按**代码或关键词**在 GitHub 上搜索 | 找真实项目里的代码示例、用法、类似实现 |
| 4 | **search-mcp** | **联网搜索**(MCP 提供的搜索能力) | 教程、博客、报错信息、通用问题 |
| 5 | **Web Search** | 通用联网搜索(最后手段) | 仅当 ref/context7/gh/gh-grep/search-mcp 都无结果或需实时/新闻时使用 |
## 使用说明
### 文档类(API、语法、概念)
- **ref-mcp**、**context7-mcp**:都是「查文档」,可先试一个,不够再试另一个
- 已知是某库/框架的用法时,优先用这两个,再考虑 GitHub 或搜索
### GitHub 类
- **gh**:已知 `owner/repo` 或要查某个仓库里的文件、分支、Issue、PR 时用 gh
- **gh-grep-mcp**:不知道在哪个仓库、只想「按代码或关键词在 GitHub 上搜」时用,适合找代码示例、真实用法
### 联网与兜底
- 教程、报错信息、通用问题:优先 **search-mcp**
- **Web Search**:仅在前述工具都找不到或明确需要最新/实时信息时使用
**禁止**:在未先尝试 ref/context7/gh/gh-grep/search-mcp 的情况下,直接使用 Web Search 查文档或代码示例
我不允许 AI 上来就由着性子乱搜。它必须按这个顺序来:
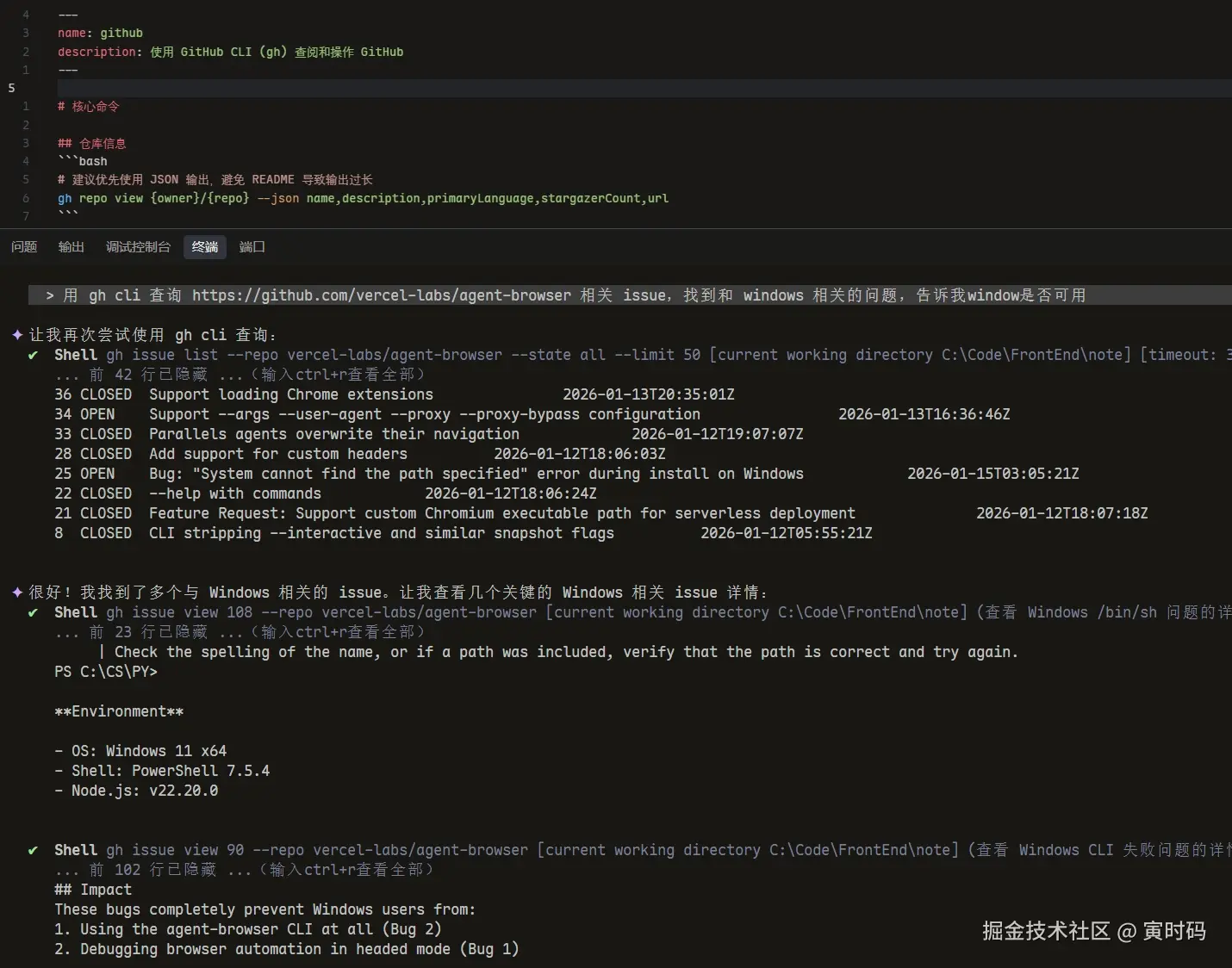
context7-mcp 非常好用,它能直接拿到带代码示例的文档片段。gh 命令行工具,直接去仓库里看 README 或者 examples 目录。gh repo view 看项目元数据。找到 agent-browser 关于 Windows 使用的 issue。这比我自己找问题快多了
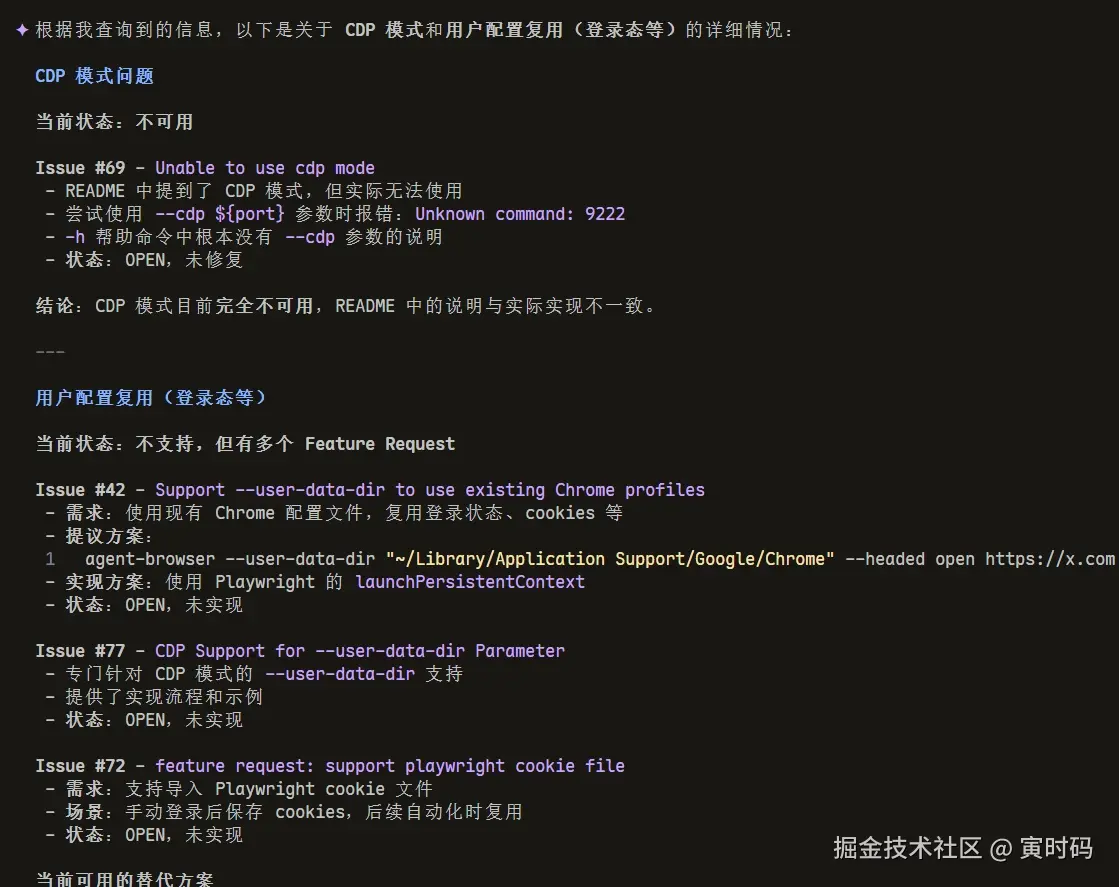
找到 CDP 模式 issue
查询文档验证
GitHub CLI 是一个命令行工具,用于在终端中直接与 GitHub 交互。适合让 LLM 通过命令行查阅和阅读仓库内容,节省 MCP Token 消耗。
# Windows (使用 winget 或 scoop)
# 或者 Github Releases 下载
winget install --id GitHub.cli
# 或
scoop install gh
# macOS
brew install gh
# Linux
# 参考:
(type -p wget >/dev/null || (sudo apt update && sudo apt install wget -y))
&& sudo mkdir -p -m 755 /etc/apt/keyrings
&& out=$(mktemp) && wget -nv -O$out
&& cat $out | sudo tee /etc/apt/keyrings/githubcli-archive-keyring.gpg > /dev/null
&& sudo chmod go+r /etc/apt/keyrings/githubcli-archive-keyring.gpg
&& sudo mkdir -p -m 755 /etc/apt/sources.list.d
&& echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/githubcli-archive-keyring.gpg] stable main" | sudo tee /etc/apt/sources.list.d/github-cli.list > /dev/null
&& sudo apt update
&& sudo apt install gh -y
身份验证:
gh auth login # 交互式登录
gh auth status # 查看认证状态
gh auth refresh # 刷新 token
# 读取文件内容(需解码)
gh api "repos/{owner}/{repo}/contents/{path/to/file}" --jq '.content' | base64 -d
# 读取 README
gh api "repos/{owner}/{repo}/readme" --jq '.content' | base64 -d
# 列出目录(仅显示名称,节省 Token)
gh api "repos/{owner}/{repo}/contents/{path}" --jq '.[].name'
更多命令让 AI 教你就行了,我就不浪费大家时间了
LLM 的 Context Window 再大也是有限的。更可怕的是,上下文越长,AI 的注意力越涣散(Lost in the Middle 现象)。
当你发现 AI 开始车轱辘话来回说,或者忽略你刚发的要求时,就是时候重置上下文了。
但我绝不会直接清空对话,那样还得把需求重说一遍。我使用 summary 技能来进行“无损交接”。
我会让 AI 生成一份标准化的交接文档,格式锁死:
---
name: summary
description: 总结当前任务的上下文和进度,以便切换 LLM 或重置上下文
---
# Context Handoff Summary
请分析当前的对话上下文、代码修改记录和任务目标,并结合重要上下文,生成一份详细的任务交接文档。这份文档将用于提供给另一个 LLM 以继续当前的工作
## 任务摘要要求
请按照以下格式输出:
### 1. 背景与目标 (Background & Goals)
- 简述当前任务的核心背景
- 明确当前阶段的最终目标
### 2. 当前进度与现状 (Current Progress)
- 列出已经完成的工作
- 描述当前正在进行的修改
- **特别说明**: 如果当前代码有逻辑错误、编译失败或运行异常,请详细说明现状及你认为的原因
### 3. 重要文件引用 (Key File References)
- 列出与任务核心相关的最重要的文件路径
- 简要说明每个文件的作用或为何重要
### 4. 待办事项与下一步计划 (Remaining Tasks & Next Steps)
- 明确接下来需要执行的具体步骤
- 提供给新 LLM 的建议指令
有了这个,点击 IDE 的 "New Chat",把这段话往里一贴,无缝衔接。
代码写完了,能不能用?别急着 merge。
在 code-review/SKILL.md 里,我要求 AI 必须按六个维度审查代码,而不是只会说“代码写得很棒”这种废话:
并且,分级报告:严重、警告、建议。没有红灯才能过。
---
name: code-review
description: 当用户要求进行代码审查、提到"review"/"审查"/"重构"/"优化代码"等关键词、或代码需要质量检查时使用。检查重复代码、逻辑冲突、多余逻辑、SRP违反、模块耦合、硬编码/死代码等6个维度
---
## Target
检查6个维度:重复代码、逻辑冲突、多余逻辑、SRP违反、模块耦合、硬编码/死代码
## Execution Steps
检查以下6个维度,用严重/警告/建议分级:
1. **重复代码** - 相同或相似的代码逻辑在多处出现
2. **逻辑冲突** - 存在矛盾或互相抵消的逻辑
3. **多余逻辑** - 不必要的计算、判断或冗余代码
4. **SRP违反** - 单一职责原则违反,一个函数/类做了太多事情
5. **模块耦合** - 模块间依赖关系过于复杂或紧耦合
6. **硬编码/死代码** - 魔法数字、未使用的代码、永远不会执行的分支
## Format
src/foo.ts 行 120-160;src/bar.ts 行 20-40utils/transform.ts,新增单元测试
## NOTE
- 只进行观察和分析,不修改代码直到用户确认
- 优先报告严重问题(),再是警告(),最后是建议()
- 每个问题都要说明"为什么这是个问题"和"如何修复"
- 如果代码整体质量很好,也要明确指出
这是我最喜欢的一条规则:遵循“不猜测,只验证”原则。
很多 AI 看到报错就开始瞎猜:“可能是版本问题?可能是环境问题?” 然后让你试一堆没用的命令。
在 fix-bug/SKILL.md 里,我规定了死流程:
console.log。---
name: fix-bug
description: 当用户报告 Bug 或错误、提到"bug"/"错误"/"异常"/"问题"等关键词、或代码运行不符合预期时使用。遵循"不猜测,只验证"原则,系统性排查和解决复杂Bug
---
## Rules
遵循"不猜测,只验证"原则
## Execution Steps
1. 分析:根据提供的信息,浏览相关代码分析问题
2. 索要上下文:需要额外信息(环境变量、依赖版本、配置、日志)且无法获取时,主动提问
3. 日志打印:信息不足时,建议在特定位置添加日志,要求重新运行并提供输出
4. Web项目:可访问时打开浏览器调试;无法获取时,指导查看DevTool并要求提供错误/API详情
5. 迭代修复:提出修复方案 → 等待反馈 → 持续循环直到确认修复
AI 确实很强,但如果不加以引导,它就是一匹脱缰的野马。
通过 ai-sync,我解决了配置迁移的痛点;通过 Skills 和 Workflow,我解决了 AI 幻觉和不可控的问题。
这套组合拳打下来,我的编程体验发生了质的变化:从“抽奖式编程”变成了“指挥官式编程”。
如果你也想体验这种掌控感:
npm i -g @jl-org/ai-sync~/.claude/skills 或 ~/.cursor/skills 里。
