


哈曼卡顿Harman Kardon One(哈曼卡顿智能音箱)
156.1MB · 2026-03-12

这篇文章是企业级 Prompt 工程实战指南(下):构建可复用 Prompt 架构平台的最上层架构的延伸,建议结合一起看。
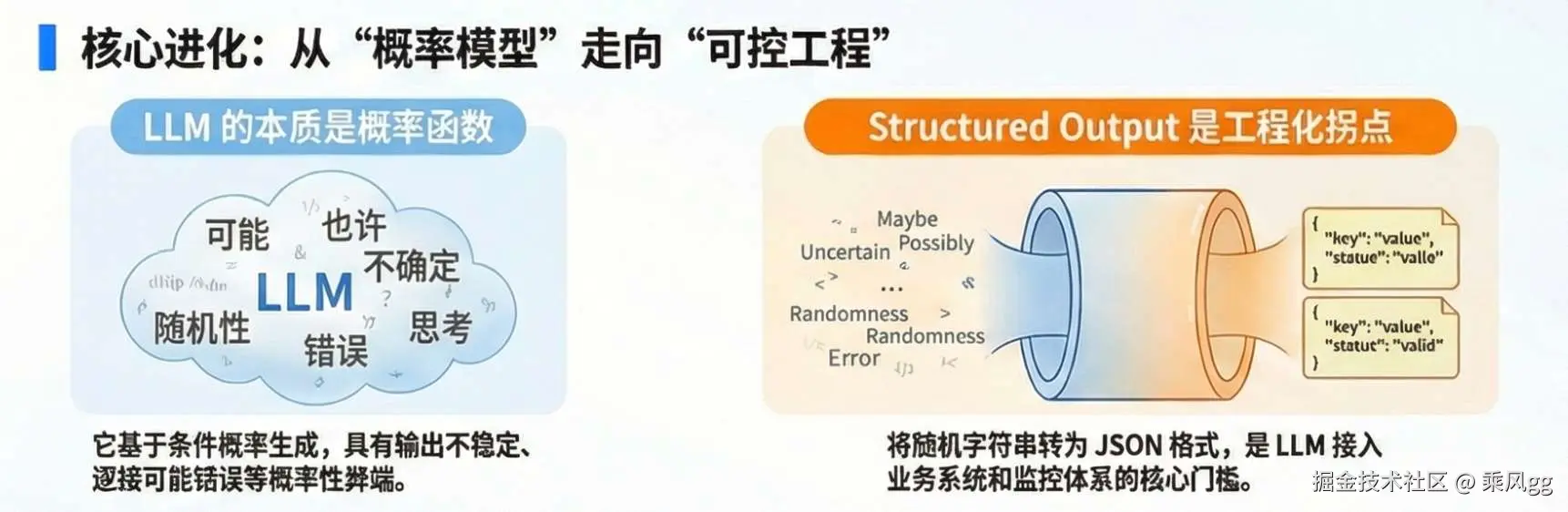
站在一线 AI 应用工程的视角,LLM 绝非业界部分人神化的“通用智能体”,其工程本质被严重忽略或者说夸大了。
它本质是:
早期我们这样用:
const text = await llm(prompt)
因为是概率输出,所以会有如下问题:
这种纯 Prompt 驱动的调用方式,在生产环境中属于典型的“脆弱架构”——无容错、无校验、无追溯,完全无法承载企业级场景的稳定性要求。
这阶段暂且可以叫:
Prompt Engineering 阶段
它仅能用于 Demo 验证、概念性验证(POC),但绝对无法支撑大规模、高可用、可追溯的企业级生产系统。
当模型支持:
response_format: { type: "json_schema" }
或者 tool calling,
我们可以把 LLM 从:
(prompt) => string
大模型返回 string:
名字:张三
年龄:28
职业:工程师
因为大模型返回的是随机字符串,所以就会有结构问题。你想像一下,如果大模型返回一段字符串,大概率那就得工程师通过正则去提取关键字符,大模型随机性很强,关键字符是会出错的,难度就会很高。
后来变成:
(input) => Promise<TypedObject>
大模型返回 TypedObject: {
name: "张三",
age: 28,
job: "工程师"
}
所以说大模型从返回随机的字符串,变成了能约定的 API,也就是 JSON 格式的 TypedObject
它带来四个工程能力:
标志着我们第一次可以把 LLM 接入:
这里又延伸出了另一个问题:
Structured Output 仅解决了“模型输出可被系统解析”的结构问题。
它不解决:
所以它是,必要条件,不是充分条件——脱离确定性约束的 Structured Output,依然是“可控的错误输出”,无法支撑企业级决策。
什么意思呢?大模型从返回字符串变成了返回 JSON,但不能保证 JSON 里面的 name 是对的,比如明明要返回 name: 张三,却返回了 name: 张二
简单来说 Structured Output 解决了大模型结构错误,但还有语义错误待解决
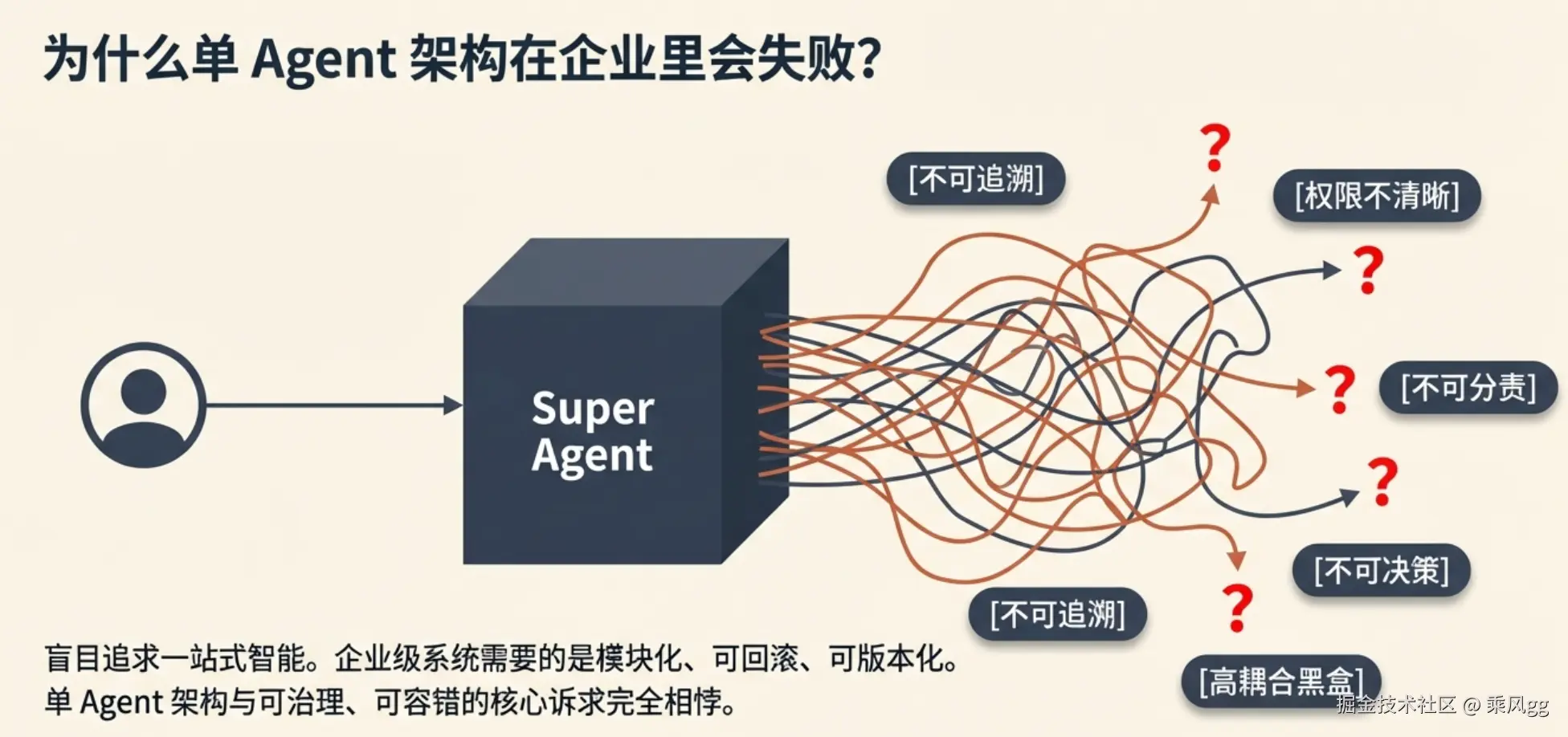
我们来延伸一下,不急着解决上面的语义错误。在很多团队在 AI 应用落地时,极易陷入“单 Agent 万能论”的误区,盲目追求“一站式智能”,设计出:
User → Super Agent → Everything
这个 Super Agent
↓
能理解需求
能自己规划
能调用工具
能执行流程
能自我修正
听起来很优雅。
问题是: 企业不是玩具场景,执行流程和自我修正决策的时候,出了事故谁背锅? AI 背不了锅吧。
我大概列一下几个问题:
在互联网企业呆过的都知道,企业真正需要的是:
这种“大而全”的单 Agent 架构,与企业级系统“可治理、可追溯、可容错”的核心诉求完全相悖,在实际落地中必然走向失控。
说到这,你们应该大概也能猜到了为什么我要延伸这个单 Agent 架构?解决这个单 Agent 架构的问题,就是解决大模型输出的语义问题的最佳工程化实现。
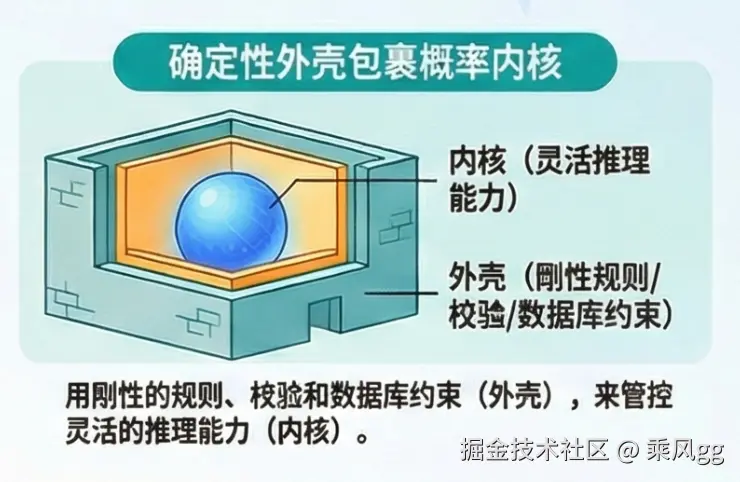
结合我多年的工作经验,企业业务系统的核心永远是质量优先,也就是“确定性底座”,即:
LLM 最主要功能就是泛化能力,它不是决策层——它的价值是 “降低语义理解成本”,而非“替代系统做决策” ,这是企业级 AI架构的核心认知底线。
企业级LLM架构的核心设计原则,本质是“确定性外壳包裹概率内核——这是平衡LLM灵活性与系统可控性的唯一可行路径。
优点:强语义表达、灵活的模糊推理能力,能快速解决传统系统难以处理的非结构化文本问题
缺点:输出非确定性、无法保证事实与业务正确性
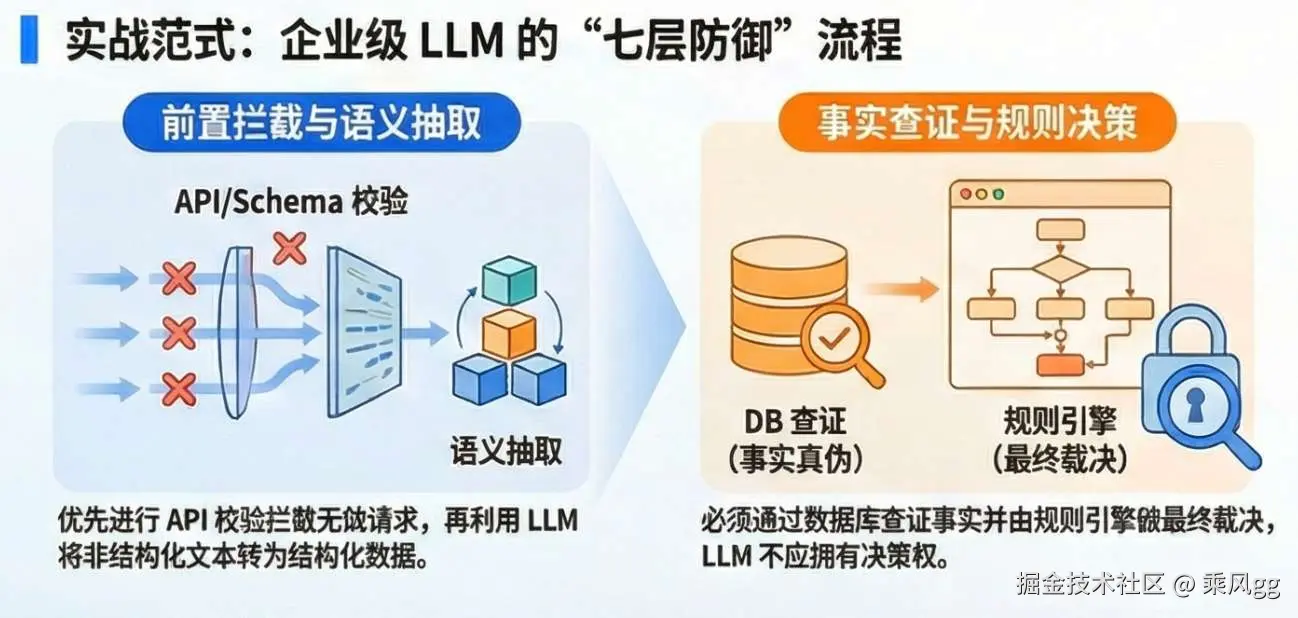
企业级系统的“安全底线”,也是 LLM 可控的核心保障,主要包括:
包括:
其核心特点是同样输入 → 同样输出
举一个 AI 付款审批系统的例子,拆解真实业务场景的架构落地细节,数据已经脱敏——这是典型的“确定性外壳+概率内核”落地案例。
用户提交:
目标:
AI 系统自动判断是否批准付款。
目的:
检查:
如果失败:
→ 直接拒绝
LLM 根本不会被调用。
原则:企业级AI架构的核心优化方向之一,就是“前置拦截无效请求”,越早拦截,系统成本越低、安全性越高
如果用户提交的是自由文本:
LLM 负责提取:
{
"amount": 800000,
"vendor": "ABC 公司",
"purpose": "Marketing"
}
这一步解决:
但它可能出错——即使开启 Structured Output,模型仍可能出现字段偏差、语义误解(如将“80万”识别为“8万”),这是由其概率本质决定的。
所以:
目的:
例如:
注意:
即使使用 structured output,也必须进行系统级二次校验——这是很多团队容易忽略的细节,也是导致系统失控的常见隐患。
因为:
在 node.js 中常见用到 zod 去做 scheme 校验,大致如下
const APISchema = z.object({
request_id: z.string().min(1),
submitter_id: z.string().min(1),
amount: z.number().gt(0),
currency: z.string().length(3).optional(),
vendor: z.string().min(1)
});
LLM 不知道:
必须查数据库。
企业级系统的“真相唯一来源”,必须是结构化数据库,而非模型的生成结果,切记、切记、切记
设立不同的规则,规则示例:
规则必须:
模型不应该做最终裁决——企业级决策的核心是“可解释、可追溯”,而模型的概率性决定了其无法承担最终决策职责,这是企业 AI 架构的核心底线。
负责:
风控是企业级系统的“最后一道安全防线”,负责拦截合规、安全类致命风险,
只有在:
才:
必须:具备完整的事务与容错机制,即
可能到这,有些人会提出疑问:
“这些层是不是重复?”
看似重复,实则各层承担着不同的“信任边界”和“风险防控职责”,关注点差异:
| 层 | 关注点 |
|---|---|
| API 校验 | 网络边界 |
| Schema 校验 | 数据结构 |
| DB 查证 | 事实 |
| 规则引擎 | 业务逻辑 |
| 风控 | 安全合规 |
| 执行层 | 事务或者人工处理 |
它们是企业级系统中不同层级的“信任边界”,每一层都在解决特定的风险问题,理论上是缺一不可。
我个人觉得以下三个是不能合并:
其他的根据业务大小,随意组合、扩展、删减,我也是提供了我的思路,欢迎有其他思路的在评论区留言!
结合前面的实战案例,Structured Output 的真正价值的是:
而不是:
经过多个项目落地验证,稳定、可控的企业 AI 架构,必然是“确定性底座优先”,而非“模型优先”,其标准形态为:
数据库 (事实真相)
↓
规则引擎(约束)
↓
工作流(秩序)
↓
LLM(语义增强)
而不是“模型主导”的反范式(这是很多团队落地失败的核心原因):
LLM
↓
数据库 / 规则 / 流程
这两种架构的区别不是技术,而是:
企业永远选择前者。
很多团队做企业AI,陷入了“唯模型论”的误区,认为:
而真正的企业级 AI 架构思维,恰恰相反:
所以,企业级 AI 项目工程化架构牢记下面几点
试想一下,当你的系统调用量从每天 100 次变成 100 万次时,
哪怕 0.1% 的错误率, 每天就是 1000 次异常,这锅你敢接吗?
欢迎关注我的公众号:深入浅出AI
156.1MB · 2026-03-12
31.0MB · 2026-03-12
117.49M · 2026-03-12
Vite 凭什么比 Webpack 快50%?揭秘闪电构建背后的黑科技
我用 OpenClaw 搭了一套运营 Agent,每天自动生产内容、分发、追踪数据——独立开发者的运营平替

