一键传输wifi互传
118.12M · 2026-02-04

背景:
大家好,我是【小林】,近期对于AiAgent颇有兴趣,很多人都问,这么久不更新Flutter文章是不是弃坑了呢?
其实并没有,原因有以下,第一是近一个月工作比较忙,需求比较多,全身心的投入到了业务开发,没有太多时间去沉淀自己的想法和思路(仅剩不多的精力还留给了agent项目!!)第二就是流量不太好,我的Flutter文章虽然点赞、收藏、评论占阅读量的比重很大,但是阅读量始终卡在2000,让我也觉得比较缺乏动力...
话说回来,其实做这个agent项目还是源于我在去年公司做的项目,简单描述就是文生图、图生图,不过当时受制于AI远没有今天这么强大等等综合的原因吧,我有特别多的想法没有实践出来,我觉得现在应该有能力实现一部分出来了。
这套Agent工作流本质上来说就是当人面对一个复杂需求时,需要的不是单个 AI 模型,而是一个能"思考"、"决策"、"执行"的智能系统。
这篇文章讲清楚一件事:如何用 LangGraph 设计和实现一个完整的 AI Agent 工作流。从需求分析到架构设计,从节点编排到流式执行,基于真实的工程实践。(有机会和时间可以详细讲讲我这个项目是如何从零到一实现的)
做个 AI 绘图功能,第一反应是什么?
// 最简单的方式:直接调 API
async function generateImage(prompt: string) {
const result = await llm.call(prompt);
return result;
}
但这有几个问题:
问题1:用户说的不专业
问题2:无法理解上下文
问题3:无法自我优化
这些问题,本质上是 "单次调用"模式的局限 。用户想要的是一个能"理解意图 → 检索知识 → 执行任务 → 质量检查 → 优化调整"的完整流程。
Agent 工作流就是把复杂任务拆解成多个步骤,每个步骤由专门的"节点"(Node)负责,节点之间通过"状态"(State)传递数据。
打个比方:
实际场景中,Agent 工作流的价值体现在:
场景1:内容创作团队 编辑说"写一篇关于 AI 的文章",传统方式直接生成一篇。但 Agent 工作流会:
场景2:智能客服 用户说"我的订单怎么还没到",传统方式可能直接查数据库。但 Agent 工作流会:
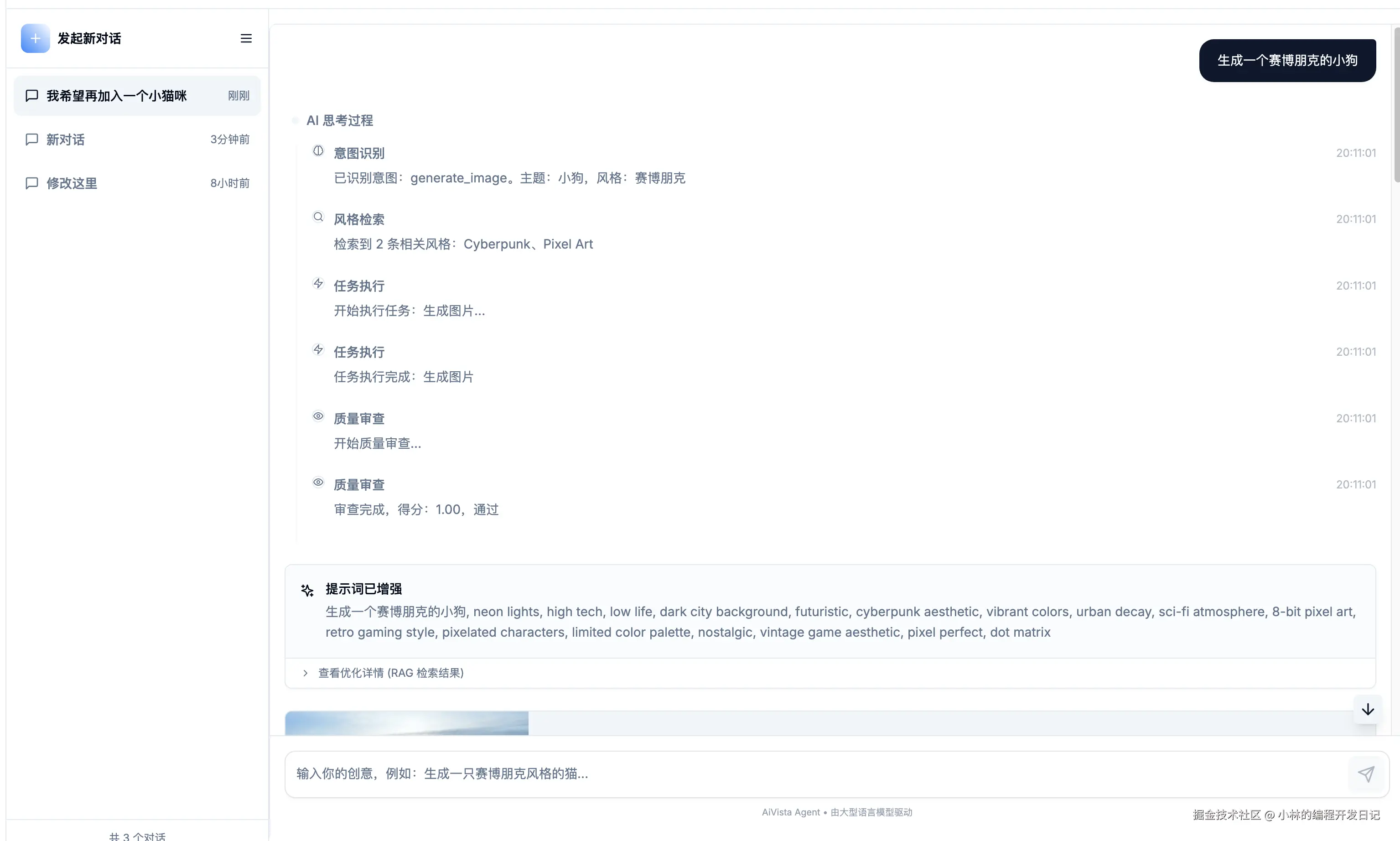
场景3:AI 绘图助手(本文重点) 用户说"生成一只赛博朋克风格的猫",Agent 工作流会:
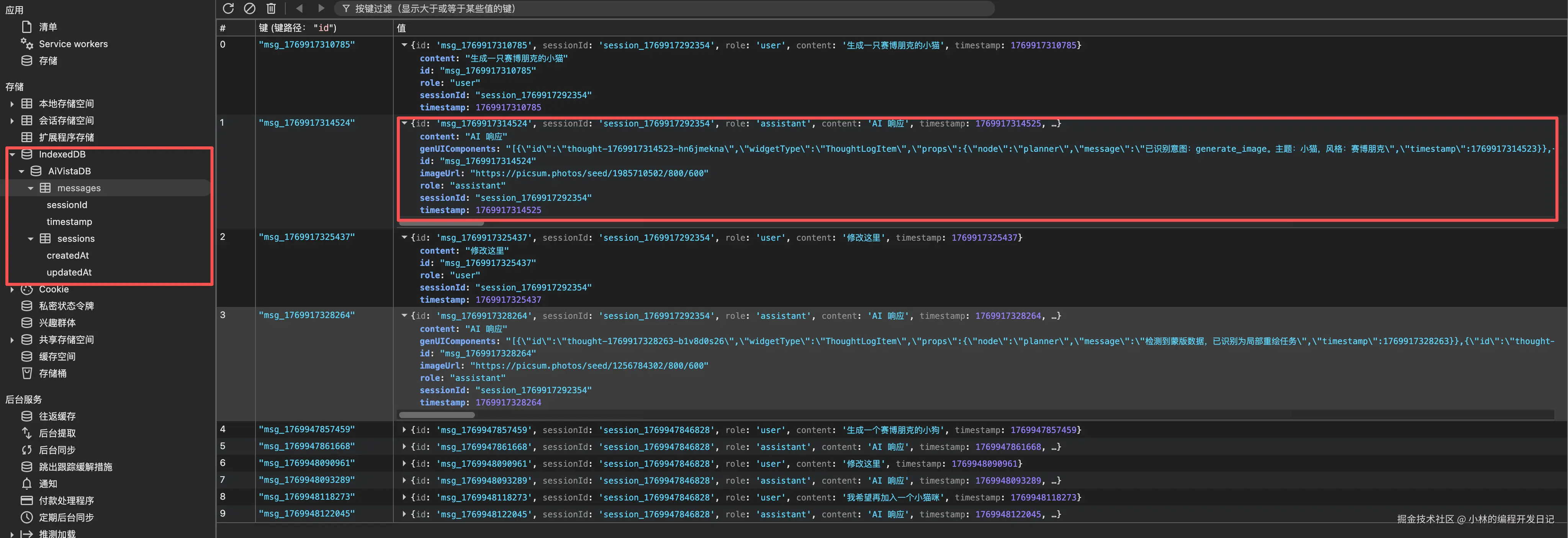
[截图位置:展示一个完整的 Agent 工作流执行过程,包含每个节点的状态]
做 Agent 工作流,有几个选择:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| LangChain Chain | 简单直接 | 不支持循环、条件分支复杂 | 简单的线性任务 |
| AutoGPT | 自主性强 | 过于黑盒,难定制 | 自主探索类任务 |
| 自己写状态机 | 完全可控 | 重复造轮子 | 有特殊需求 |
| LangGraph | 灵活+可视化 | 学习曲线陡 | 复杂工作流 |
选 LangGraph 的三个理由:
理由1:状态图模式
// 定义状态
interface AgentState {
userInput: string;
intent?: IntentResult;
enhancedPrompt?: string;
result?: string;
}
// 定义图(节点 + 边)
const graph = new StateGraph(AgentStateAnnotation)
.addNode("planner", plannerNode)
.addNode("rag", ragNode)
.addNode("executor", executorNode)
.addEdge("planner", "rag")
.addEdge("rag", "executor")
.compile();
理由2:支持流式执行
// 实时看到每个节点的输出
for await (const chunk of graph.stream(initialState)) {
console.log(chunk); // { planner: { intent: {...} } }
}
理由3:可视化和调试 LangGraph 提供了可视化工具,能直接看到工作流结构和执行路径。
先明确目标:做一个智能图像生成助手,用户用自然语言描述需求,系统自动完成。
核心功能:
非功能需求:
基于需求,设计了四个节点的工作流:
用户输入
↓
[Planner] 意图识别 → { action: "generate_image", style: "cyberpunk" }
↓
[RAG] 风格检索 → { enhancedPrompt: "一只猫, neon lights, high tech..." }
↓
[Executor] 执行生成 → { imageUrl: "https://..." }
↓
[Critic] 质量检查 → { passed: true }
↓
返回结果
为什么要这四个节点?
| 节点 | 职责 | 为什么需要 |
|---|---|---|
| Planner | 理解用户意图 | 用户表达不精确,需要 LLM 解析 |
| RAG | 检索增强风格 | 用户的"风格"描述可能不专业 |
| Executor | 执行生成 | 调用图像生成 API |
| Critic | 质量检查 | AI 生成不稳定,需要筛选 |
LangGraph 的核心是状态(State),状态在节点间传递和更新。
interface AgentState {
// 输入
userInput: {
text: string; // 用户输入的文本
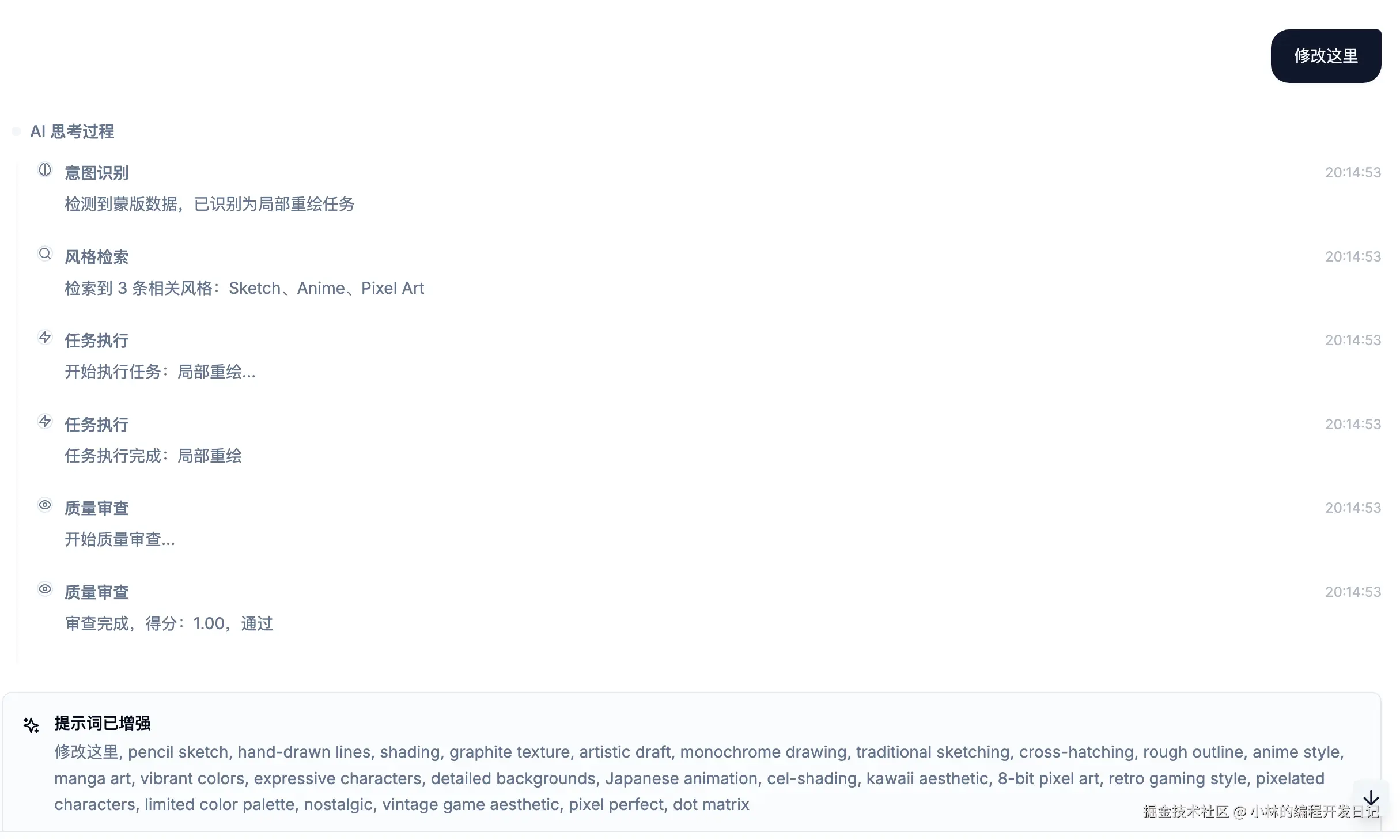
maskData?: { // 蒙版数据(局部重绘时)
base64: string;
imageUrl: string;
};
previousPrompts?: string[]; // 历史提示词(多轮对话)
};
// 中间状态
intent?: { // Planner 的输出
action: 'generate_image' | 'inpainting' | 'adjust_parameters';
style?: string;
confidence: number;
};
enhancedPrompt?: { // RAG 的输出
original: string;
retrieved: Array<{ style: string; prompt: string; }>;
final: string;
};
// 输出
executionResult?: {
imageUrl: string;
metadata?: any;
};
// 元数据
sessionId: string;
thoughtLogs?: Array<{ // 思考日志(用于展示)
node: string;
message: string;
timestamp: number;
}>;
}
状态设计原则:
Partial<AgentState>,而不是直接修改thoughtLogs 记录每个节点的决策过程metadata 字段,方便后续加字段职责:分析用户输入,提取关键信息。
实现方式:调用 LLM,要求结构化输出。
@Injectable()
export class PlannerNode {
async execute(state: AgentState): Promise<Partial<AgentState>> {
const systemPrompt = `
你是一个专业的 AI 图像生成助手。请分析用户的输入,识别用户的意图。
可能的意图类型:
- generate_image: 用户想要生成新图片
- inpainting: 用户想要修改图片的某个区域(通常伴随蒙版数据)
- adjust_parameters: 用户想要调整生成参数
请以 JSON 格式返回分析结果。
输出格式:
{
"action": "generate_image",
"subject": "猫",
"style": "赛博朋克",
"confidence": 0.9
}
`;
const intent = await this.llmService.chatWithJson<IntentResult>(
[
{ role: 'system', content: systemPrompt },
{ role: 'user', content: state.userInput.text }
],
{ temperature: 0.3, jsonMode: true }
);
// 特殊处理:如果有蒙版,强制设为 inpainting
if (state.userInput.maskData && intent.action !== 'inpainting') {
intent.action = 'inpainting';
}
return {
intent,
thoughtLogs: [{
node: 'planner',
message: `已识别意图:${intent.action}`,
timestamp: Date.now()
}]
};
}
}
技术要点:
jsonMode: true 确保 LLM 返回 JSONtemperature: 0.3 降低随机性,提高稳定性效果展示:
[截图位置:Planner 节点的执行效果,展示意图识别结果]
职责:根据意图检索相关风格,增强 Prompt。
为什么需要 RAG?
用户的表达往往不专业。比如用户说"赛博朋克风格",但不知道专业的 Prompt 是什么。RAG 节点会:
实现方式:
@Injectable()
export class RagNode {
constructor(private readonly knowledgeService: KnowledgeService) {}
async execute(state: AgentState): Promise<Partial<AgentState>> {
// 构建查询文本
const queryText = [
state.intent.style,
state.intent.subject,
state.userInput.text
].filter(Boolean).join(' ');
// 向量检索
const results = await this.knowledgeService.search(queryText, {
limit: 3,
minSimilarity: 0.4
});
// 构建增强 Prompt
const originalPrompt = state.userInput.text;
const retrievedPrompts = results.map(r => r.prompt).join(', ');
const finalPrompt = retrievedPrompts
? `${originalPrompt}, ${retrievedPrompts}`
: originalPrompt;
return {
enhancedPrompt: {
original: originalPrompt,
retrieved: results,
final: finalPrompt
},
thoughtLogs: [{
node: 'rag',
message: results.length > 0
? `检索到 ${results.length} 条相关风格`
: '未检索到匹配的风格',
timestamp: Date.now()
}]
};
}
}
技术要点:
minSimilarity: 0.4 过滤低相关结果效果展示:
[截图位置:RAG 检索结果展示,可以看到检索到的风格和 Prompt]
职责:调用图像生成服务,返回图片 URL。
接口设计:
为了灵活切换供应商(阿里云、DeepSeek、本地模型),设计了统一接口:
interface IImageService {
generateImage(options: {
prompt: string;
model?: string;
size?: string;
}): Promise<{ imageUrl: string }>;
inpaint(options: {
prompt: string;
image: string;
mask: string;
}): Promise<{ imageUrl: string }>;
}
实现方式:
@Injectable()
export class ExecutorNode {
constructor(
@Inject('IMAGE_SERVICE')
private readonly imageService: IImageService,
) {}
async execute(state: AgentState): Promise<Partial<AgentState>> {
if (!state.intent || !state.enhancedPrompt) {
throw new Error('Intent and enhancedPrompt are required');
}
const { action } = state.intent;
const prompt = state.enhancedPrompt.final;
let executionResult;
switch (action) {
case 'generate_image':
executionResult = await this.imageService.generateImage({
prompt,
model: state.userInput.preferredModel
});
break;
case 'inpainting':
if (!state.userInput.maskData) {
throw new Error('Inpainting requires maskData');
}
executionResult = await this.imageService.inpaint({
prompt,
image: state.userInput.maskData.imageUrl,
mask: state.userInput.maskData.base64
});
break;
default:
throw new Error(`Unknown action: ${action}`);
}
// 生成 GenUI 组件(后续会讲)
const uiComponents: GenUIComponent[] = [{
widgetType: 'ImageView',
props: {
imageUrl: executionResult.imageUrl,
width: 800,
height: 600
},
timestamp: Date.now()
}];
return {
executionResult,
uiComponents,
thoughtLogs: [{
node: 'executor',
message: '图片生成完成',
timestamp: Date.now()
}]
};
}
}
效果展示:
[见上图]
职责:检查生成结果,决定是否重试。
为什么需要?
AI 生成不稳定,有时候效果不好,需要重试。但每次都人工检查成本太高,所以需要一个自动筛选机制。
实现方式:
@Injectable()
export class CriticNode {
async execute(state: AgentState): Promise<Partial<AgentState>> {
if (!state.executionResult) {
throw new Error('Execution result is required');
}
// 基于意图置信度和随机因素评估
const baseScore = state.intent?.confidence || 0.7;
const randomFactor = Math.random() * 0.2;
const finalScore = Math.min(1.0, baseScore + randomFactor);
const passed = finalScore > 0.7;
const retryCount = state.metadata?.retryCount || 0;
return {
qualityCheck: {
passed,
score: finalScore,
feedback: passed ? '质量符合要求' : '建议重新生成'
},
metadata: {
...state.metadata,
retryCount: passed ? 0 : retryCount + 1,
shouldRetry: !passed && retryCount < 3
},
thoughtLogs: [{
node: 'critic',
message: `质量评分:${finalScore.toFixed(2)}`,
timestamp: Date.now()
}]
};
}
}
重试逻辑:
在 LangGraph 的条件边(Conditional Edge)中处理:
graph.addConditionalEdges(
'executor',
(state) => {
if (state.metadata?.shouldRetry) {
return 'critic'; // 重试,回到 Critic
}
return END; // 结束
}
);
效果展示:
[见上图]
传统方式:后端返回 JSON,前端解析。
// 后端
{ type: 'image', url: 'https://...' }
// 前端
if (result.type === 'image') {
return <img src={result.url} />;
}
问题:
核心思想:后端只管下发"组件配置",前端自己渲染。
interface GenUIComponent {
widgetType: string; // 组件类型
props: Record<string, any>; // 组件属性
updateMode?: 'append' | 'replace' | 'update'; // 更新模式
timestamp?: number;
}
示例:
// Agent 想显示一张图片
{
widgetType: "ImageView",
props: {
imageUrl: "https://...",
width: 800,
height: 600
},
updateMode: "replace"
}
// Agent 想显示一个进度条
{
widgetType: "ProgressBar",
props: {
progress: 50,
status: "生成中..."
},
updateMode: "update"
}
Append(追加):在当前界面后面加新内容
// 场景:多轮对话,每次生成新图片
{ widgetType: "ImageView", updateMode: "append" }
Replace(替换):替换当前组件
// 场景:重绘时,用新图片替换旧图片
{ widgetType: "ImageView", updateMode: "replace" }
Update(更新):更新现有组件的属性
// 场景:进度更新
{
widgetType: "ProgressBar",
updateMode: "update",
props: { progress: 50 }
}
前端有个通用渲染器,根据 widgetType 动态渲染:
export function GenUIRenderer({ component }: { component: GenUIComponent }) {
const { widgetType, props } = component;
switch (widgetType) {
case 'SmartCanvas':
return <SmartCanvas {...props} />;
case 'ImageView':
return <ImageView {...props} />;
case 'AgentMessage':
return <AgentMessage {...props} />;
default:
return <div>Unknown widget: {widgetType}</div>;
}
}
最复杂的 GenUI 组件是 SmartCanvas,它不只是显示图片,还能:
技术实现:
const handleMouseDown = (e: React.MouseEvent) => {
if (mode !== 'masking') return;
setIsDrawing(true);
const ctx = canvasRef.current.getContext('2d');
ctx.strokeStyle = 'rgba(255, 0, 0, 0.5)';
ctx.lineWidth = 20;
ctx.lineCap = 'round';
ctx.beginPath();
ctx.moveTo(x, y);
};
const handleMouseMove = (e: React.MouseEvent) => {
if (!isDrawing) return;
ctx.lineTo(x, y);
ctx.stroke();
};
用户画完蒙版后,前端把 Canvas 转成 Base64,发给后端:
const base64 = canvasRef.current.toDataURL('image/png', 0.8);
// 发送给后端,调 inpainting API
为什么用 SSE?
传统方式:前端发请求 → 后端处理 → 返回结果。用户等待期间看到的是转圈。
更好的方式:后端处理到哪一步,前端就展示到哪一步。
实现方式:
// 后端:AgentService
async *executeWorkflow(initialState: AgentState): AsyncGenerator<any> {
const stream = await this.graph.stream(initialState, {
streamMode: 'updates',
});
for await (const chunk of stream) {
for (const [nodeName, stateUpdate] of Object.entries(chunk)) {
// 推送思考日志
if (stateUpdate.thoughtLogs) {
for (const log of stateUpdate.thoughtLogs) {
yield {
type: 'thought_log',
timestamp: log.timestamp,
data: {
node: log.node,
message: log.message,
},
};
}
}
}
}
}
// 前端:SSE 客户端
class SSEClient {
async connect(url, data, { onEvent, onError }) {
const response = await fetch(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(data),
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const event = this.parseSSEEvent(chunk);
onEvent(event);
}
}
}
效果:用户能看到类似这样的实时日志:
[Planner] 已识别意图:生成图片
[RAG] 检索到 3 条相关风格
[Executor] 图片生成中...
[Executor] 图片生成完成
问题:用户说"加个墨镜",系统怎么知道是在"猫"上加?
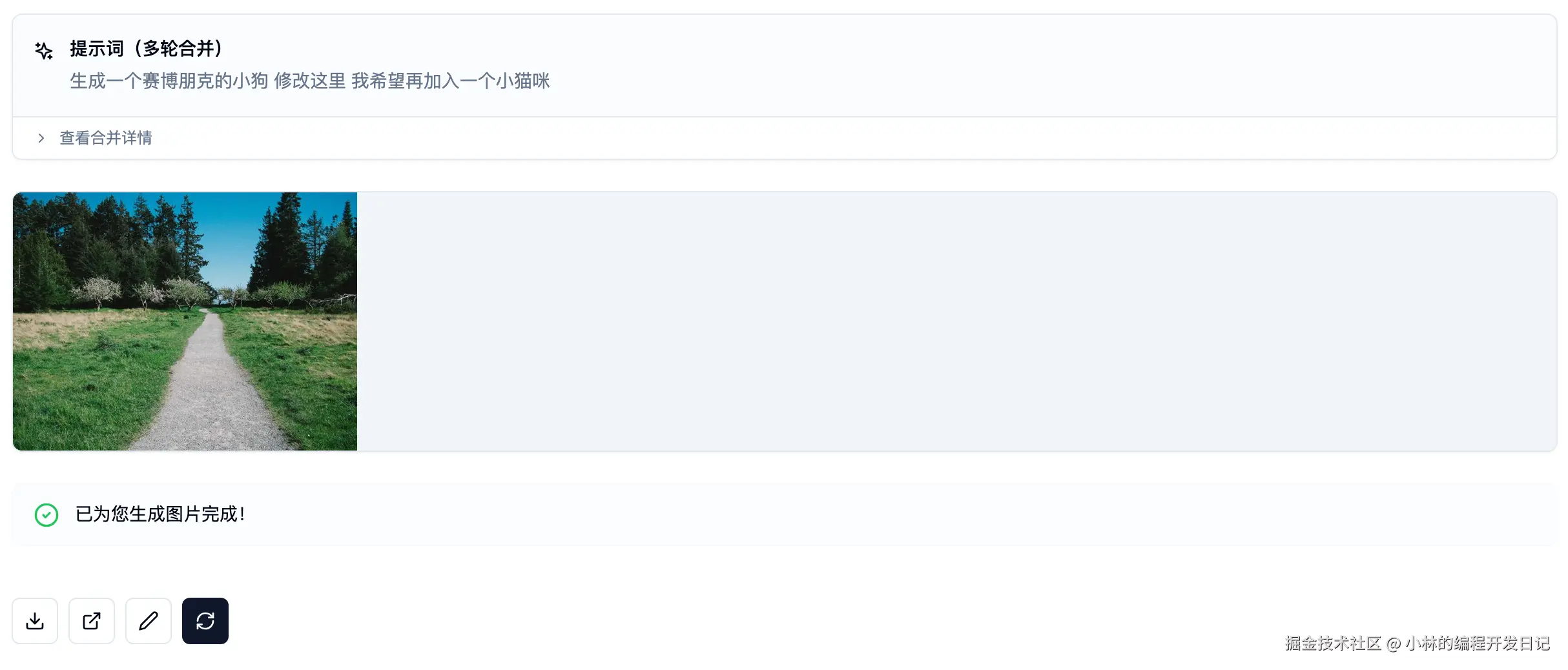
解决方案:历史 Prompt 合并
// 首轮
userInputs: ["生成一只猫"]
finalPrompt: "生成一只猫"
// 续写
userInputs: ["生成一只猫", "加个墨镜"]
finalPrompt: "生成一只猫, 加个墨镜"
// 再次续写
userInputs: ["生成一只猫", "加个墨镜", "背景改成星空"]
finalPrompt: "生成一只猫, 加个墨镜, 背景改成星空"
实现:
// 前端维护历史输入
const [previousPrompts, setPreviousPrompts] = useState<string[]>([]);
// 每次发送时带上历史
const handleSend = (text: string) => {
const newPrompts = [...previousPrompts, text];
setPreviousPrompts(newPrompts.slice(-5)); // 最多保留 5 条
agentService.chat({
text,
previousPrompts: newPrompts
});
};
// 后端合并
const finalPrompt = previousPrompts.join(', ');
为什么用向量检索?
用户输入"酷炫的风格",系统需要知道这可能对应"赛博朋克"或"科幻"。传统关键字匹配做不到,需要语义检索。
实现:
// 初始化 LanceDB
const db = await lancedb.connect('./data/lancedb');
const table = await db.openTable('styles');
// 生成查询向量
const embedding = await embeddingService.embedQuery("酷炫的风格");
// 向量检索
const results = await table
.vectorSearch(embedding)
.limit(3)
.distanceType('cosine')
.toArray();
数据准备:
预置了 N 种风格数据:
| 风格 | Embedding 向量 | Prompt |
|---|---|---|
| 赛博朋克 | [0.1, 0.2, ...] | neon lights, high tech... |
| 水彩 | [0.3, 0.1, ...] | soft colors, watercolor... |
| ... | ... | ... |
坑1:状态更新不是自动合并
// 错误做法
const newState = { ...state, intent: newIntent };
// 正确做法
const update = { intent: newIntent };
currentState = { ...currentState, ...update };
坑2:条件边的返回值
// 错误
return someObject;
// 正确:必须返回字符串(节点名)或 END
return 'nextNodeName';
坑:连接断开后没有自动重连
解决:实现指数退避重连
let retryCount = 0;
while (retryCount < 5) {
try {
await connect();
break;
} catch (error) {
retryCount++;
const delay = Math.pow(2, retryCount) * 1000;
await sleep(delay);
}
}
坑1:在高分屏上模糊
// 需要处理 devicePixelRatio
const dpr = window.devicePixelRatio || 1;
canvas.width = width * dpr;
canvas.height = height * dpr;
ctx.scale(dpr, dpr);
坑2:Base64 太大导致传输慢
// 优化:缩放后再传输
const resizedCanvas = document.createElement('canvas');
resizedCanvas.width = 800;
resizedCanvas.height = 600;
ctx.drawImage(originalCanvas, 0, 0, 800, 600);
const base64 = resizedCanvas.toDataURL('image/png', 0.8);
工作流设计:
GenUI 协议:
关键技术:
项目已完全开源,欢迎 Star 和 PR:
GitHub:[github.com/xinqingaa/a…]
文档:[github.com/xinqingaa/a…]
关于 Agent 开发的一点体会:
关于 LangGraph:
如果你也在做 Agent,希望这篇文章能帮到你。有问题欢迎在评论区讨论,或者直接提 Issue。**
最后,如果这篇文章对你有帮助,点个赞吧~
(完)

