


跳绳鸭
67.76M · 2026-02-04

大家好我是小肥肠。转眼又到了写论文的季节,你是不是又在为需要阅读大量参考文献发愁?今天我们将开发一个 Agent Skill。你只需提供文件源文件,它便能自动输出文献总结报告,告别低效的人肉阅读,让 AI 替你完成最枯燥的预研工作。
面对堆积如山的参考文献,最让人崩溃的往往不是看不懂,而是看不完。传统的查阅方式是逐一打开 PDF,手动标记重点,再苦哈哈地归类整理,效率极低且容易遗漏关键信息。
本文我们将开发一个 Agent Skill,利用 PyMuPDF4LLM 精准拆解 PDF 论文后调用 AI 深度分析总结。你只需提供文件,它便能自动输出结构化报告,告别低效的人肉阅读,让 AI 替你完成最枯燥的预研工作。
先来看一下实现效果,原文PDF如下:
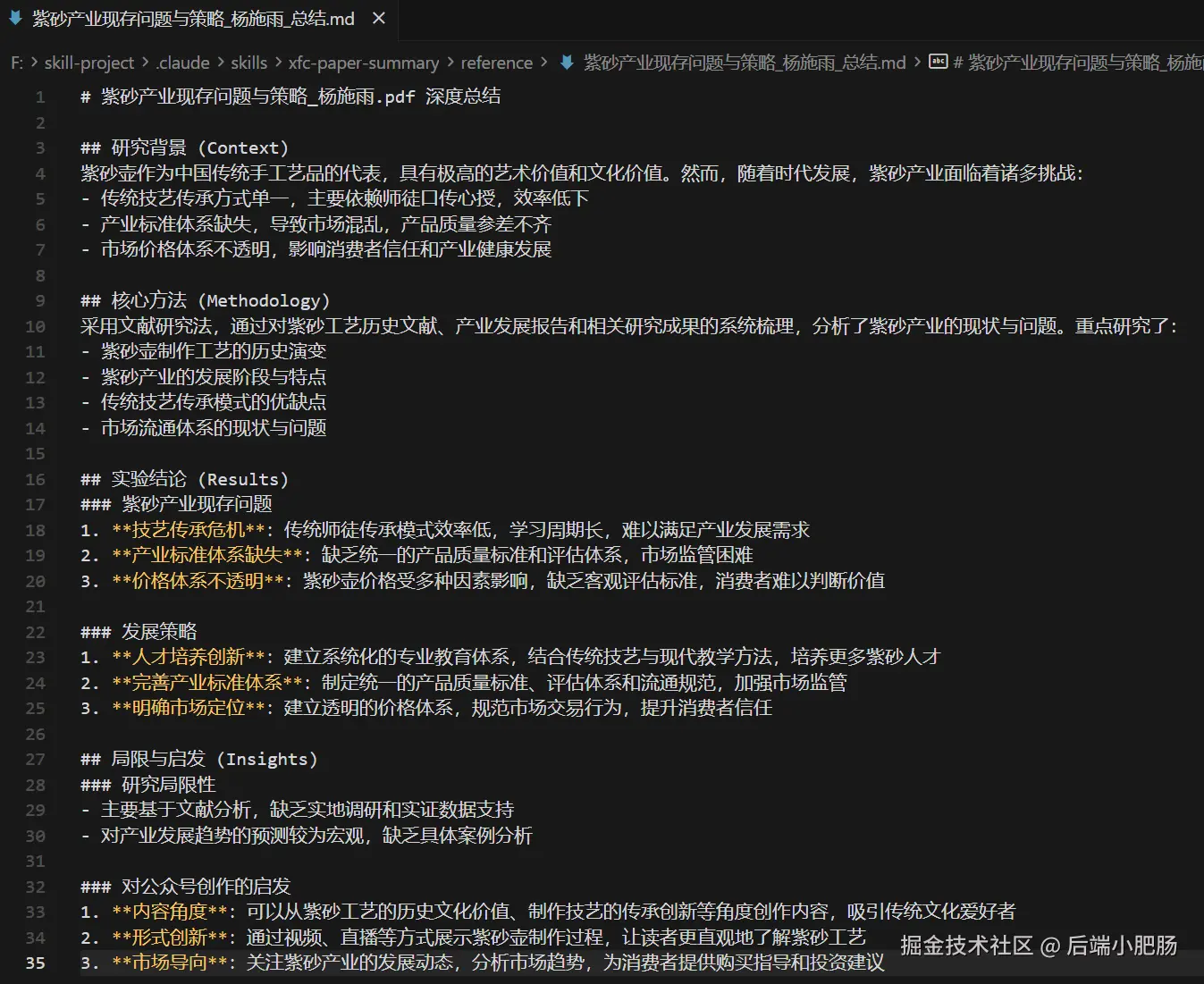
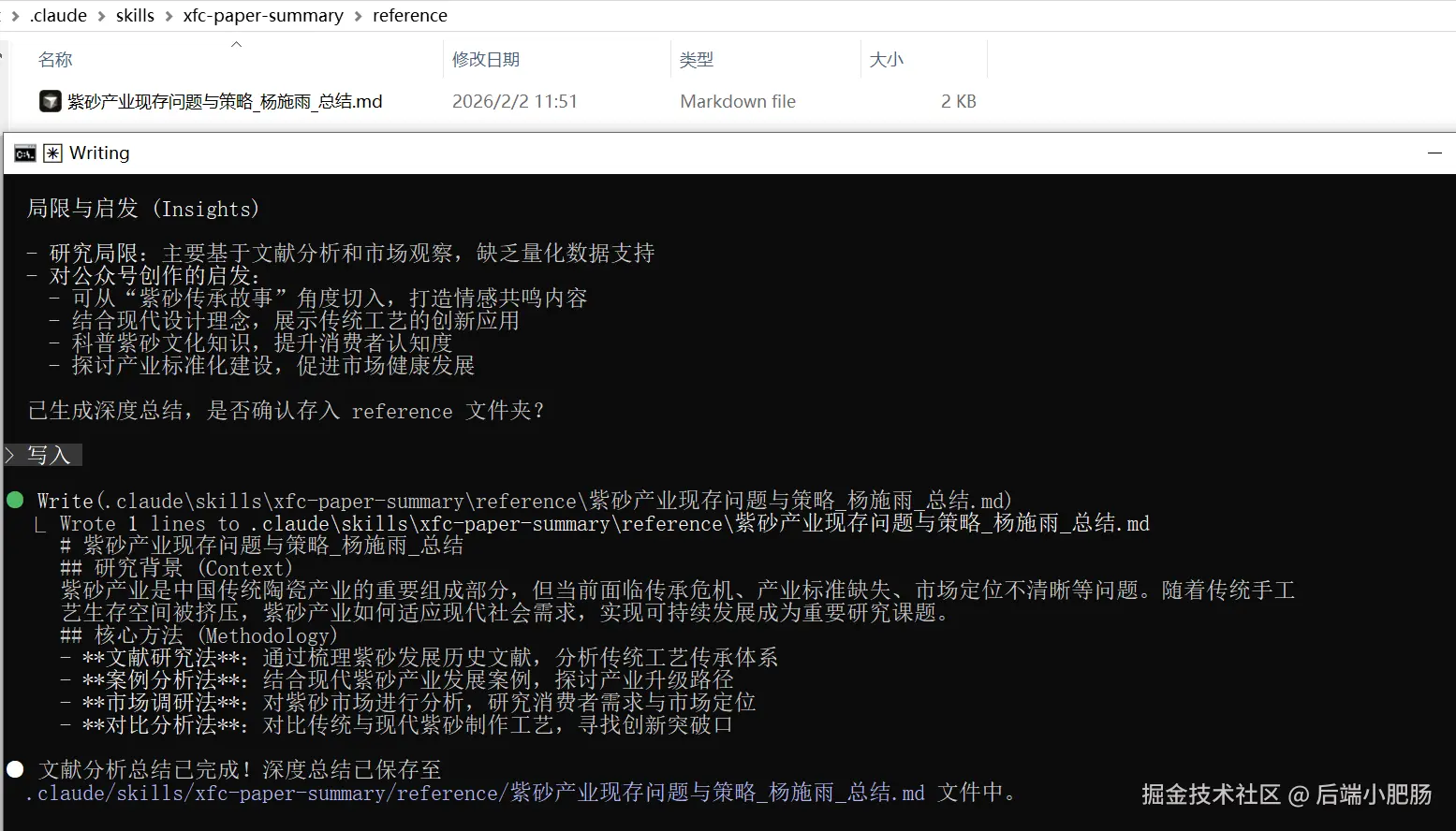
经过 Agent Skill整理后的内容:
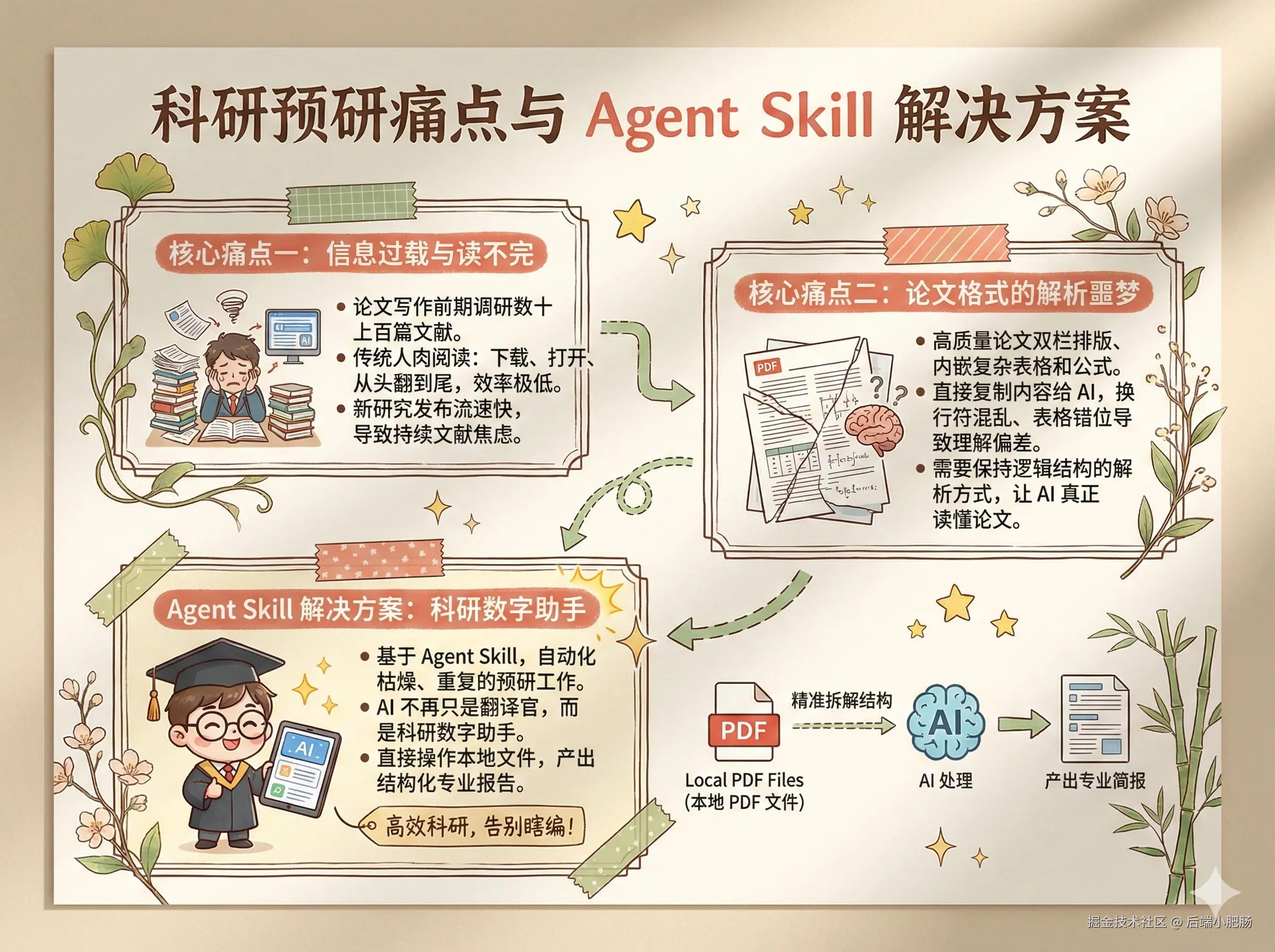
在科研或深度学习过程中,我们往往面临两个核心痛点:
从上图可以看出我们面临的主要是信息过载与论文格式难以解析的两大痛点。基于 Agent Skill,我们可以将这些枯燥、重复、高出错率的预研工作完全自动化。AI 不再只是个翻译官,而是变成了一个能直接操作本地文件、精准拆解结构并产出专业简报的科研数字助手。
在创建Skill前,需要进行几个前置操作:
安装python(这个不讲了,网上手把手教程很多,自行根据自己的操作系统搜索一下安装教程)
安装安装PyMuPDF4LLM,打开命令提示词,输入如下指令
pip install pymupdf4llm
3. 安装ClaudeCode,整合大模型,我这边整合的Doubao-Seed-Code,具体教程可参考:
文风自我进化?10分钟教你用 Agent Skills 搭建一个能“无限迭代”的小说生成器
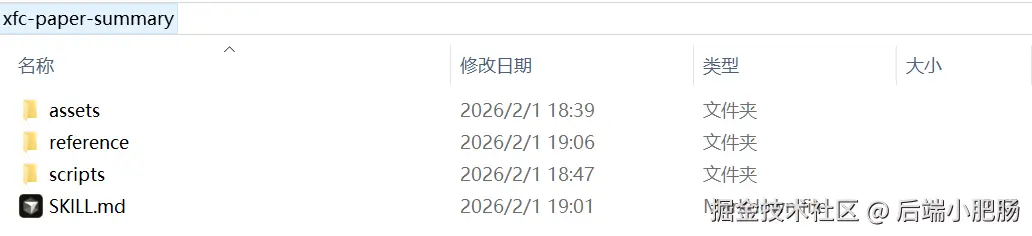
本文的Agent Skill目录结构设计如下:
xfc-paper-summary/
├── SKILL.md # 必填:使用说明 + 元数据
├── scripts/ # 可选:可执行代码
├── references/ # 可选:文档资料
└── assets/ # 可选:模板、资源文件
1. 按照上述目录结构创建文件夹
2. 编写读取文献代码
进入xfc-paper-summary/scripts/路径,创建process.py文件,填入源代码:
import pymupdf4llm
import os
import sys
def extract_pdf_to_markdown(input_path: str) -> str:
if os.path.isabs(input_path) and os.path.exists(input_path):
target_path = input_path
else:
target_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), "assets", input_path)
if not os.path.exists(target_path):
raise FileNotFoundError(f"未找到文献文件,请检查路径是否正确: {target_path}")
markdown_text = pymupdf4llm.to_markdown(target_path)
return markdown_text
if __name__ == "__main__":
if len(sys.argv) > 1:
pdf_input = sys.argv[1]
else:
assets_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), "assets")
if not os.path.exists(assets_dir):
os.makedirs(assets_dir)
pdf_files = [f for f in os.listdir(assets_dir) if f.endswith(".pdf")]
if not pdf_files:
print("Error: assets 目录下没有找到 PDF 文件,请提供绝对路径或放入 assets 中。")
sys.exit(1)
print(f"检测到 assets 中的文献: {', '.join(pdf_files)}")
pdf_input = pdf_files[0]
try:
print(f"--- 正在解析文献: {pdf_input} ---")
md = extract_pdf_to_markdown(pdf_input)
print(md)
except Exception as e:
print(f"解析过程中出现故障: {e}")
sys.exit(1)
在代码中判断有没有输入绝对路径,若没有则找到assets 文件夹,调用 pymupdf4llm 库,将原本是图片感或二进制格式的 PDF 论文转换成带格式的 Markdown 纯文本。
3. 编写SKILL.md
进入xfc-paper-summary/路径,创建SKILL.md文件,这里给出编写思路,自行去豆包里扩充就行:
---
name: xfc-paper-summary description: 资深论文解析专家。支持自动解析本地PDF并生成结构化总结报告。
---
编写提示词:
1. 调用 .claude/skills/xfc-paper-summary/scripts/process.py 解析文献
2. 深度拆解与总结,需要拆解为以下框架
- 研究背景
- 核心方法论
- 实验结论
- 局限与启发
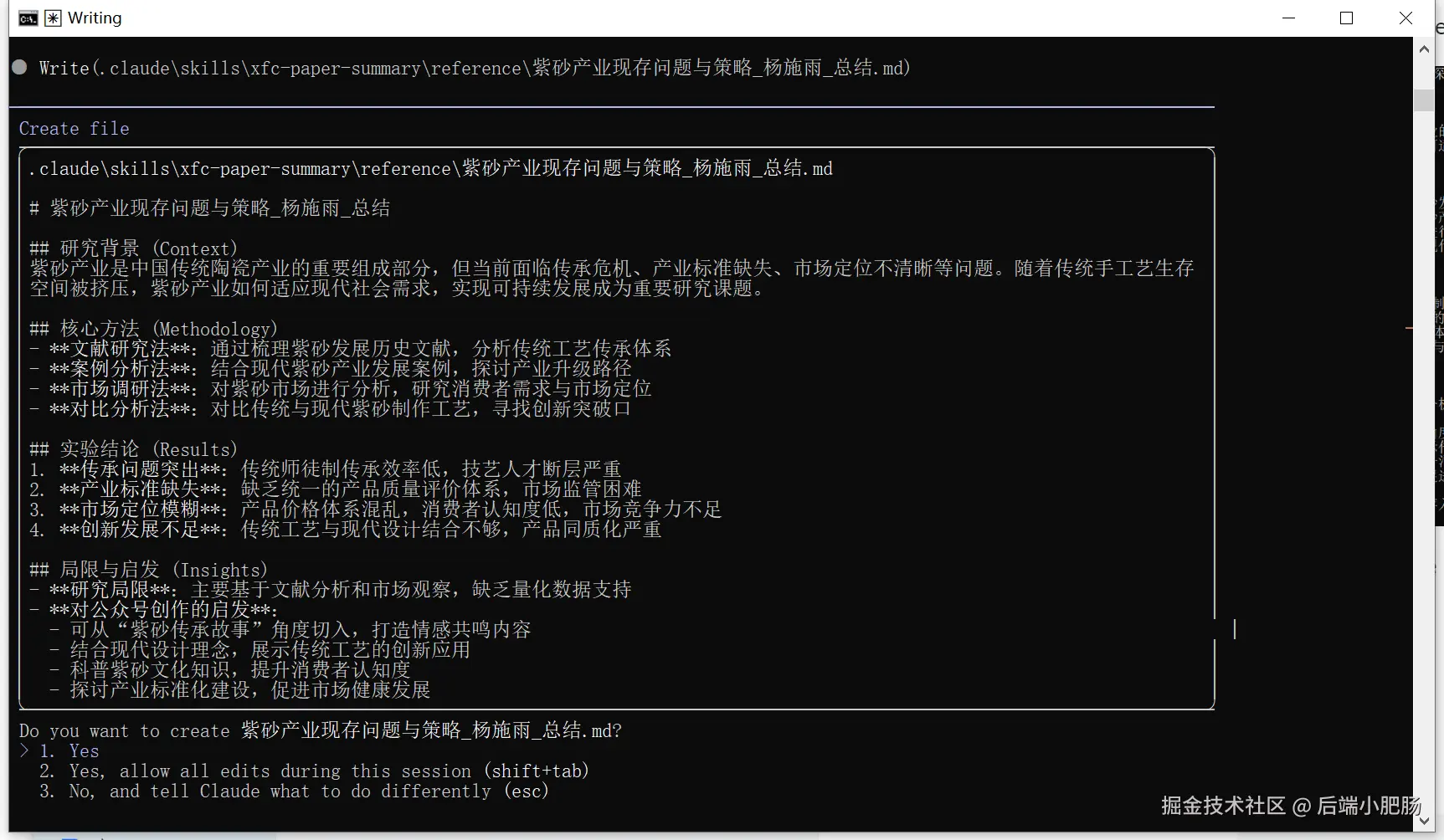
3. 使用 `write_to_file` 工具将总结后的内容写入.claude/skills/xfc-paper-summary/reference/文件夹下
4. 测试调用xfc-paper-summary
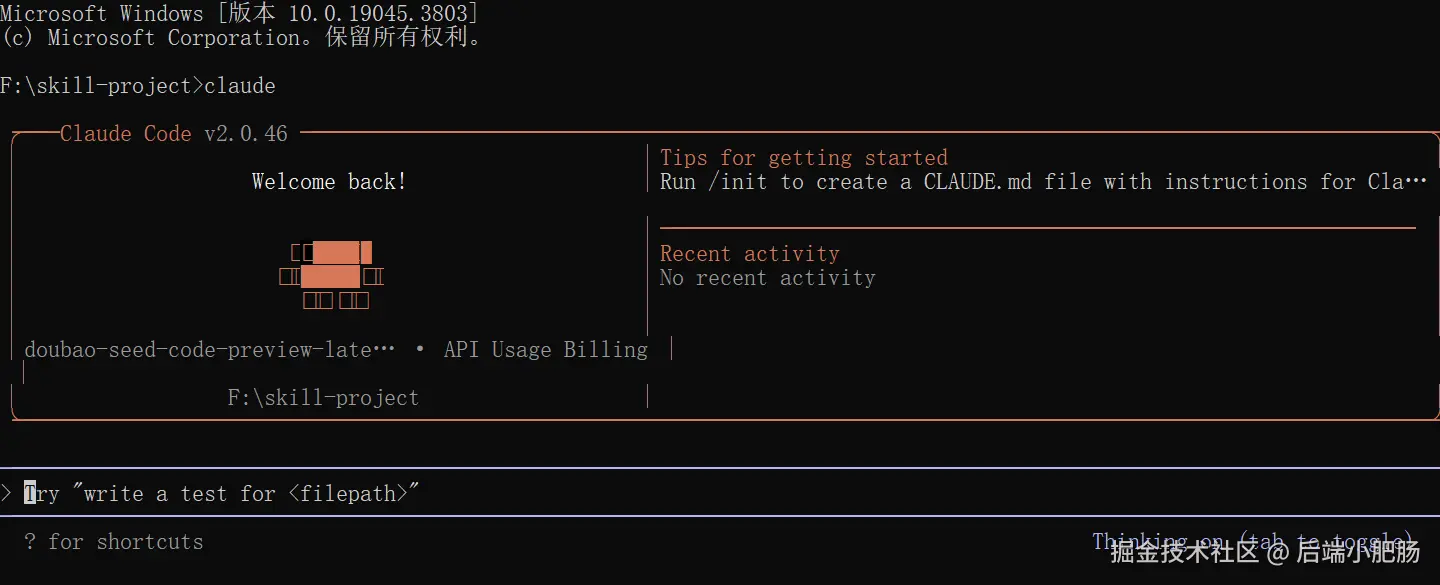
回到.claude上级目录,在文件路径处输入cmd打开命令提示符窗口:
输入"claude"
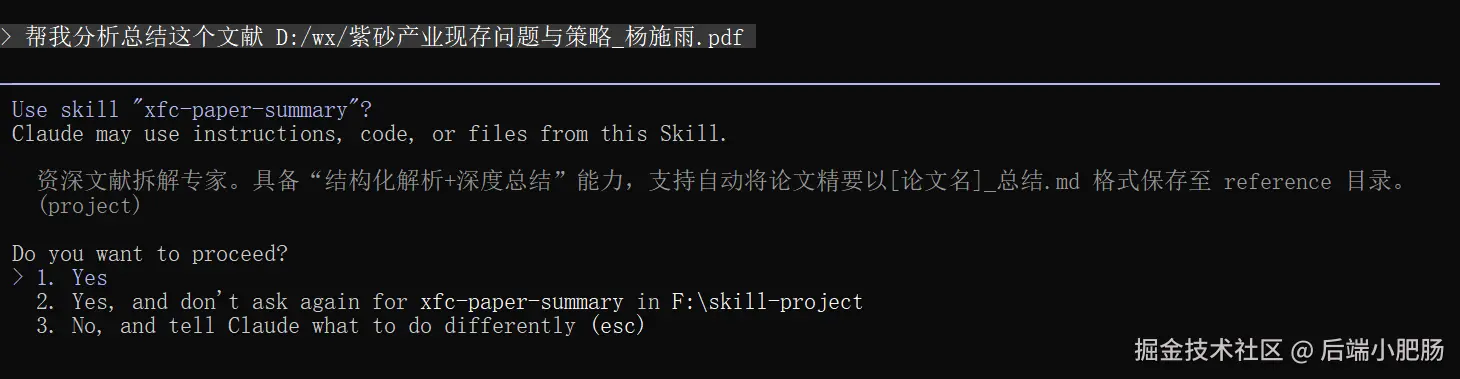
输入"帮我分析总结这个文献 D:/wx/紫砂产业现存问题与策略_杨施雨.pdf"
可以看到claude code自主调用了skill并完成了文献的拆解和总结
我们只要跟随claude code的牵引流程,不停选择yes,即可完成总结文档的写入。
以上就是整个skill构建的完整流程拆解,动手能力强的读者可以跟着教程实践一遍。上述skill已经被收录到了小肥肠共学群中,需要原件可以加入社群直接使用哦。
这种基于 Agent Skill 的开发思路,本质上是让 AI 拥有了操作本地文件和执行特定算法的能力。不仅是论文总结,你可以举一反三,将其应用在财务报表分析、技术文档库整理等更多场景中。
如本次分享对你有帮助,麻烦一键三连支持一下小肥肠,我们下期再见~

