
Tabula相册整理工具2026
27.5MB · 2026-04-07

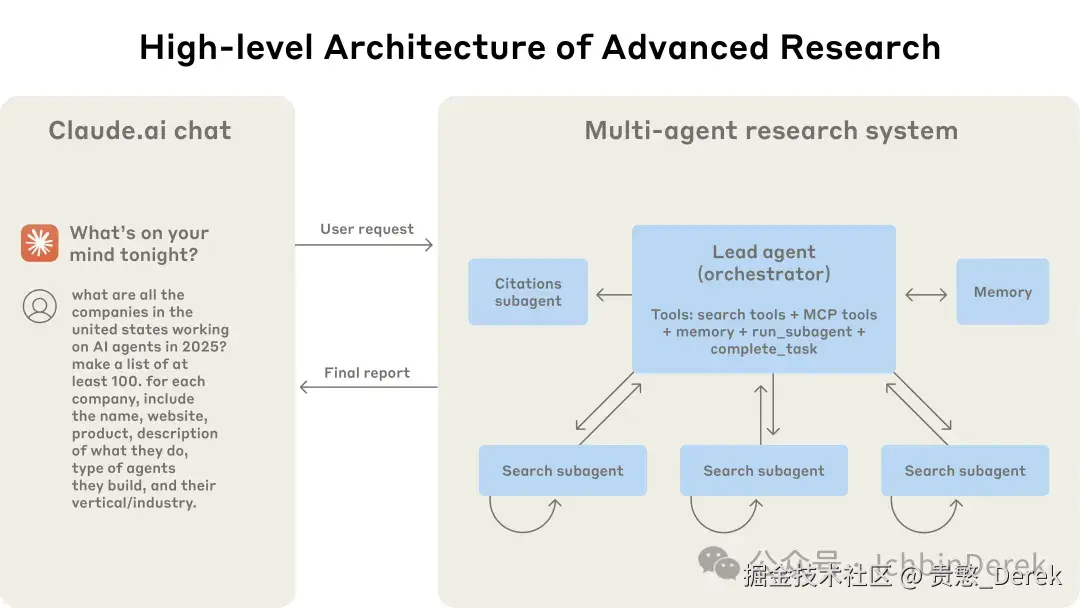
很多人的盲区是把多 Agent 理解成多开几个会话。 Anthropic 这篇工程文拆的是另一件事:Research 类任务是开放题——步骤事先定死会翻车,路径会边做边改;一条线性 one-shot 管线很难接住「既要比拼覆盖面,又要中途改方向」的活儿。于是他们落地成 Orchestrator–worker:LeadResearcher 拆策略、并行拉起 Subagent,各自占独立上下文去搜、去滤、再浓缩成高信号 tokens 回到主 Agent;末尾还有 CitationAgent 做引用对齐。[1]
更扎心的是账单侧叙事:数据里 Agent 交互约 4× 聊天 token,多 Agent 系统约 15× 聊天——所以你若没在算单位任务价值,架构再漂亮也可能只是在贵价并行里兜圈子。与此同时,内部评测叙事里 Claude Opus 4 任 Lead、Sonnet 4 任子 Agent 的多 Agent 方案,在自家 internal research eval 上相对 单 Agent Opus 4 有约 90.2% 的相对提升;但这 不是 公开的全行业基准,我读的时候会自动降级成「方向信号」。[1]
预防针:下文按 原文结构 压缩——为何适合多 Agent → 效果与 token 经济学 → 架构 → 八条 Prompt/工具原则 → 评测 → 产线可靠性 → 附录提示;钩子是 认知反差(会话数 vs 并行容量),骨架是 知识树。[1]
产品能力总览另见 Claude Research 原稿。[2]
| 站段 | 一句话 |
|---|---|
| 问题形状 | 开放题研究:动态、路径依赖;要像人一样跟着线索走。 [1] |
| 核心隐喻(原文) | 搜索本质是 压缩:子 Agent 并行各自窗口里压缩子问题,再交给 Lead 汇总。 [1] |
| 效果叙事 | 广撒网、多头并进类查询更吃香;S&P 500 信息技术板块公司董事名单例:多 Agent 分解并行能成,单 Agent 慢串行检索易挂。 [1] |
| BrowseComp 启发 | 原文对 OpenAI BrowseComp 做方差分解叙事:约 95% 性能方差由三因素解释,其中 token 用量单独约 80%(另含工具调用次数、模型选择)。 [1][3] |
| 架构 | Lead → Memory(防长窗丢计划)→ 并行 Subagent → CitationAgent;相对静态 RAG,强调 多步动态检索。 [1] |
| 落地杠杆 | Prompt、工具描述、评测、tracing、彩虹发布;Lead 同步等子集是瓶颈,异步是下一档复杂度。 [1][6] |
我读原文时抓住三条 收回严谨表述 前的直觉:
一旦「聪明」过了阈值,多 Agent 被原文写成扩展性能的关键手段——类比是人类个体智商涨幅有限,但协作与分工让社会能力指数级抬升(教学比喻,不当历史结论)。[1]
不适合(原文直说的一类) :所有 Agent 必须强共享同一上下文、或 Agent 间 依赖链极重、要实时协调 的域——很多编码任务可并行块不如 research 多;LLM Agent 实时委派与协同还不稳。[1]
内部提升:Opus 4 Lead + Sonnet 4 Subagent vs 单 Agent Opus 4,内部 research eval 约 +90.2% ( 内部语境)。[1]
成本:Agent 用法 token 约 4× 聊天;多 Agent 系统约 15× 聊天——原文结论很直白:只有任务价值够高,才扛得住。[1]
BrowseComp 叙事:除自家 eval 外,原文用公开 BrowseComp 做统计叙事——token 用量、工具调用次数、模型选择 三者解释大部分方差;Claude Sonnet 4 升级 的增益叙事里,甚至被写成 大于 在 Sonnet 3.7 上 加倍 token 预算——我读这句的方式是:先换模型再找并行,别只会堆预算。[1][3]
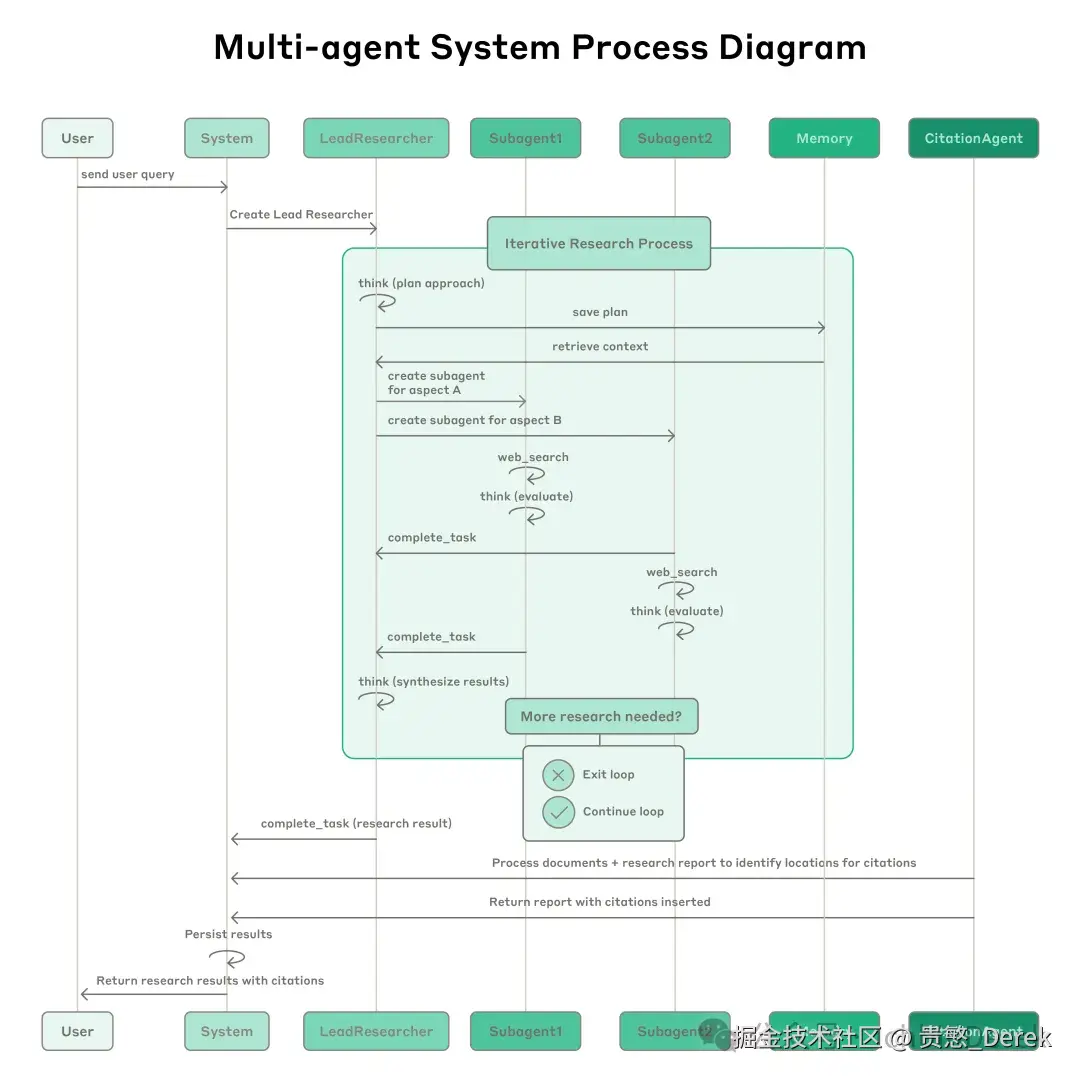
用户查询进来,LeadResearcher 进入迭代环:Extended thinking 一类能力用于规划;计划写入 Memory——因为上下文到 约 200,000 tokens 会截断,计划不能丢。[1][4]
然后 Lead 并行创建多个 Subagent(文内图示两个,实际「任意数量」),各自动态用搜索等工具;子侧用 interleaved thinking 在工具结果后做质量评估与改查询。[1][4]
Lead 汇总、决定要不要再加子任务或改策略;信息够了就交给 CitationAgent,在文档与研究报告里 对齐可引用位置,再返回带引用的成品。[1]
与 静态 RAG(一次相似度捞 chunk)相对,正文强调 多步、可随发现调整 的检索链。[1]
早期翻车原文写得很具体:一次 50 个子 Agent、为不存在来源无限搜、互相刷无效更新——协调复杂度爆炸。他们的主杠杆是 Prompt + 工具。[1]
策略底层是人类专家研究习惯(分解、评来源、深度 vs 广度)+ 护栏防失控;示例 prompt 见 Cookbook · Agent patterns。[5]
多 Agent 同样输入可走完全不同合法路径——三个源或十个源都可能对。评测要 结果 + 过程合理性,不是「有没有执行我预设的 Y 路径」。[1]
小样本立刻开跑:原文 ~20 条真实风格查询在早期就能放大 prompt 改动的收益(30%→80% 量级叙事)。别把「.eval 要做很大」当拖延理由。[1]
LLM-as-judge:自由文本难程序化;用 单一 LLM 调用输出 0.0–1.0 + 是否通过,维度覆盖 事实与来源一致、引用对准、完整度、来源质量、工具效率——多裁判拆件未必更稳。[1]
人工补洞:抓 SEO 内容农场优于权威 PDF 等偏见;反哺「来源质量」启发式。[1]
附录(原文 Appendix)里还有:终态评估(状态被多轮改写时);长对话用摘要 + 外存 + 清上下文的子 Agent 接力;子 Agent 大结果落盘、Lead 只传轻引用,减 传话游戏 token。[1]
状态与错误复利:长子过程要 可恢复、检查点;工具挂了让模型 自适应 + 确定性重试。[1]
排障:全链路 tracing;原文强调监控 决策与交互结构,不监控单条对话正文以护隐私。[1]
发布:Rainbow deployments——新旧版本并存、逐步切流量,避免「一刀切升级」打断在跑 Agent(概念链见 rainbow deploys 说明)。[6]
同步瓶颈:当前 Lead 同步等待一批 Subagent;中途难 实时纠偏 子探索;异步更并行,但协调/一致性/错误传播更难——原文预期模型更强后收益 worth the complexity。[1]
Agent 系统里,小改会 级联 成大行为差;一步失败可能把整个探索轨迹拧到别处——demo 到产线的缝,比想象中宽。[1]
尽管如此,原文仍列用户叙事:发现商业机会、厘清医疗选项、啃技术 bug、节省 数天 调研等。多 Agent research 要被他们写成:在 强工程 + 评测 + 工具与 prompt 细节 + 运维 之上,才能稳定规模化。[1]
文末 Clio 嵌入图给出 Research 用途分布叙事(软件开发跨域 10%、专业技术内容 8%、商业增长 8%、学术与教学材料 7% 、核查人物地点机构 5% 等—— 我读时当「内部产品画像切片」,不是市场调研终极真理)。[1]
| 材料 | 我怎么读 |
|---|---|
| +90.2% | 内部 research eval;对外承诺请用自建金标或可复现公开集。 [1] |
| 15× / 4× | 成本量级叙事;你业务要换算成「单次节省 vs 单次 spend」。 [1] |
| BrowseComp 方差 | 启发式:token 吃紧时,先查瓶颈是 检索还是引用质量。 [1][3] |
| −40% 工具任务时间 | 工具描述工程 ROI 的个案叙事;复现取决于域与工具。 [1] |
| 类型 | 内容 |
|---|---|
| 事实 | 原文 URL;Jun 13, 2025;作者 Jeremy Hadfield 等;Cookbook / 文档链接见参考文献。 [1] |
| 原文观点 | 并行研究、Memory、Citation、八条原则、评测与 rainbow 部署叙事。 [1] |
| 笔者解读 | 最值得迁移的是 委派规格 + 工具描述迭代 + 小样本 eval + tracing;子 Agent 数量抄作业不如抄 effort scaling 规则。 [1] |
| 批判性提醒 | CitationAgent 对齐引用位置,不等于消掉子结论矛盾;LLM judge 会塑造能通过 rubric 的「标准脸」文风;同步编排下 Lead 难 mid-flight 纠偏——边界在正文里都有伏笔。 [1] |
Rust 入门:一个写了 6 年 Python 的人,聊聊真实体验和踩坑
python Web开发从入门到精通(十一)Flask入门如此简单!10分钟搭建可运行的个人博客雏形

