哈曼卡顿Harman Kardon One(哈曼卡顿智能音箱)
156.1MB · 2026-03-12

2022 年 11 月底,OpenAI 发布 ChatGPT,迅速点燃了全球范围内对 AI 的空前关注。
此后的三年里,大模型能力持续跃迁,各类 AIGC 工具密集涌现:从 GPT-4 展现的惊人多模态理解,到国内开源推理模型在能力上不断逼近甚至追赶国际先进水平,AIGC 一次次被推向公众视野,并逐渐从技术圈话题扩散为大众讨论的社会现象。
来到 2026 年,OpenClaw 等新热点进一步放大了人们对 AI Agent(自主智能体)的想象空间:AI 不再只是一个被动响应的对话框,而开始被期待能够理解目标、规划步骤、调用工具并完成任务。
对开发者而言,真正的挑战也随之浮出水面——如何把这种“自主性”落到可控、可维护、可迭代的工程体系中。随着 LLM 应用开发进入深水区,业界逐渐意识到:单纯依赖 Prompt Engineering 已难以支撑复杂业务逻辑,我们正在从 "Chat-based UI" 走向 "Agentic Workflow" 。
当我们说从 Chat-based UI 走向 Agentic Workflow,我们到底在构建什么?如果只把 Agent 理解为“加了一层 prompt 的 LLM 接口”,很多工程问题(状态、工具可靠性、审计、迭代)都会在落地时集中爆发。因此,我们需要从工程视角把 Agent 定义清楚,再进一步设计框架与实现细节。
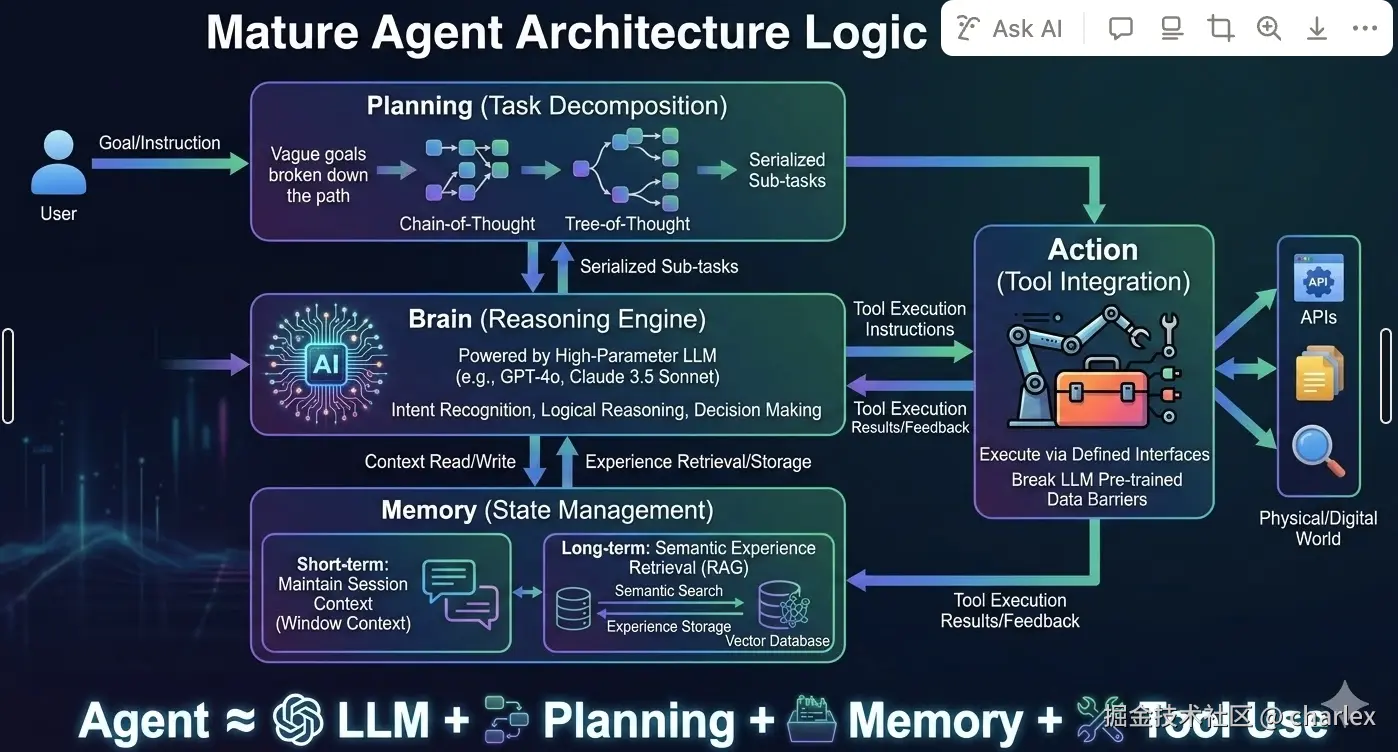
在软件工程视角下,AI Agent 不仅仅是一个封装了 LLM 的接口,而是一个以大模型推理能力为计算核心引擎的闭环控制系统。
一个 Agent 架构包含:
Brain (Reasoning Engine): 由高参数量 LLM(如 GPT-5.3, Claude 3.5 Sonnet)驱动,负责意图识别、逻辑推理与决策。
Planning (Task Decomposition): 负责将模糊的目标拆解为具体的子任务(如 Chain-of-Thought 或 Tree-of-Thought)。
Memory (State Management): 每一次模型交互都是无状态,需要人为补充上下文实现带状态模型思考。
Action (Tool Integration): 通过定义的接口与物理/数字世界交互,打破 LLM 的预训练数据壁垒。
当我们接受了 Agent 的基本构成(推理、规划、记忆、工具)之后,下一步就是:这些能力在不同框架里分别如何被抽象与组织?市面上主流框架各种各样,使用者需要根据实现情况进行选型。
| 框架 | 主要编程语言 | 核心特点 | 适用场景 |
|---|---|---|---|
| LangChain | Python (主流) JavaScript/TypeScript | 模块化架构,生态丰富,支持链式编排 | 快速原型、高度定制的单Agent应用、RAG场景 |
| LangGraph | Python (主流) JavaScript/TypeScript | 基于图的状态管理,支持循环、分支和持久化状态 | 复杂工作流、有状态应用、多Agent协调 |
| CrewAI | Python | 角色驱动的结构化协作,模拟人类团队分工 | 业务流程自动化、内容创作、数据分析 |
| AutoGen | Python TypeScript (Beta) | 对话驱动的多Agent协作,支持迭代优化 | 研发类任务、创造性场景、代码生成 |
| MetaGPT | Python | 模拟完整AI创业团队(PM、开发、测试等) | 端到端软件开发、产品构建 |
| Semantic Kernel | C# 、Python、Java | 企业级集成,安全合规,多语言原生支持 | 现有系统智能化改造、企业级应用 |
框架看起来五花八门,但本质上它们差异主要在 实现编排方式与工程能力封装 上,而不是魔法般新增了某种能力。看完框架,我们再回到实现本质:Agent 工具能力通常可以抽象为三类。
从实现角度看,绝大多数 Agent 工具最终都可以收敛为三件事:LLM Call、Tools Call、Context Engineering。我们常用的Agent工具中实现的“规划 / 记忆 / 多 Agent / 评测”等能力,本质上都是围绕这三件事做出来的工程封装。
作用:在给定上下文与工程实现逻辑约束下,让模型推理计算并产出可执行的下一步(回答或动作)。
关键点包括:
输入格式:System / Developer / User 分层;把目标、约束、输出格式固化成模板(避免临时拼 prompt)。
输出格式:要求结构化输出(如 JSON),明确区分“最终回答”与“要调用的工具/函数”。
控制参数:temperature / top_p / max_tokens/……。
重试与降级策略:
设置停止/继续条件:何时结束、何时进入下一轮、何时给用户提供反馈。
安全护栏:越权/敏感请求拒绝、提示注入防护(把不可做的事写成硬约束并进行规则拦截)。
一句话:LLM Call 把“聊天输出”工程化为 可预测、可解析、可控制 的一步推理过程。
作用:让 Agent 获取实时信息、执行外部动作(获取信息、执行动作),并且在工程上可控。
关键点包括:
一句话:Tools Call 决定 Agent 能不能从“会说”变成 真的能做事,并且“做得可控”。
作用:为 Agent 的运行时维护一个“刚刚好”的上下文,解决模型无状态、窗口有限、信息来源杂的问题,最终让 Agent 能长期推进任务。
关键点包括:
一句话:Context Engineering 决定 Agent 的上限——它让模型在有限上下文里仍能 保持一致性、持续推进并可复用经验。
一句话总结:LLM Call 决定“想什么/怎么想”,Tools Call 决定“能做什么/怎么做”,Context Engineering 决定“每一步能拿到什么信息”。
上面三个核心回答的是:Agent 的关键组件能力如何工程化;而运行时回答的是:这些能力如何在一次任务里被组织成可循环、可中断、可复盘的执行过程。最常见的两种范式是开放性探索的 ReAct,以及更偏流程化的 Plan-and-Execute。
ReAct理论:www.promptingguide.ai/zh/techniqu…
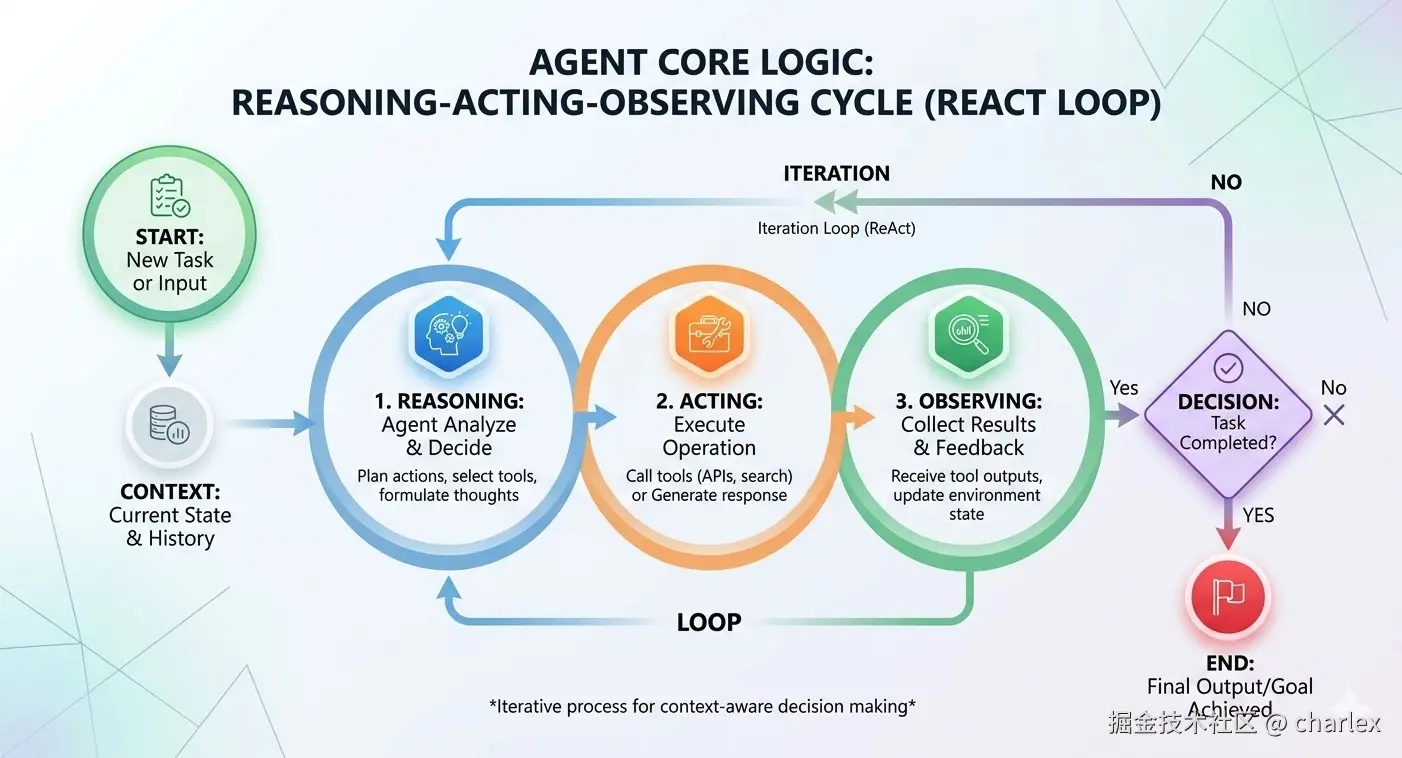
Agent 的核心运行逻辑通常是一个循环执行的推理-行动-观察流程(ReAct Loop)。
这个循环为 AI Agent 应用提供了由 LLM Call 驱动的自主决策能力:在每一轮循环中,Agent 基于当前上下文进行推理、决定下一步行动(调用工具或给出答案)、观察执行结果并更新上下文,然后进入下一轮——直到任务完成或触发终止条件。这种循环机制让 Agent 能够逐步分解复杂任务、动态调整策略、并在多步骤交互中保持目标一致性。
最大循环次数:防止无限循环(如设置总上限 max_iterations=20,过程中结合局部/全局状态动态调整)。
超时控制:单次循环或总任务的时间上限(结合局部/全局状态动态调整)。
提前终止条件:
中间状态持久化:长任务支持暂停/恢复,避免从头重来。
人机协作触发点:遇到高风险操作、模糊需求或无法自主决策时,主动请求用户确认或补充信息。
def agent_loop(task, max_iterations=10):
context = initialize_context(task)
for i in range(max_iterations):
# 1. 推理:调用 LLM 决策下一步
decision = llm_call(context)
# 2. 判断是否完成
if decision.is_final_answer:
return decision.answer
# 3. 执行工具调用
if decision.tool_call:
result = execute_tool(decision.tool_call)
context.add_observation(result)
# 4. 检查终止条件
if should_terminate(context):
break
return context.get_final_result()
Agent Loop 是 Agent 的执行引擎,它把"推理 → 行动 → 观察"变成可控、可追踪、可中断的工程化流程。
ReAct 更适合“边探索边推进”的任务:信息不全、路径不确定,需要一边推理执行一边调整策略。
例 1:开放域排障/定位问题(探索式)
例 2:复杂信息问答 + 多轮检索(研究助理)
例 3:表格/文档清洗与补全(交互式)
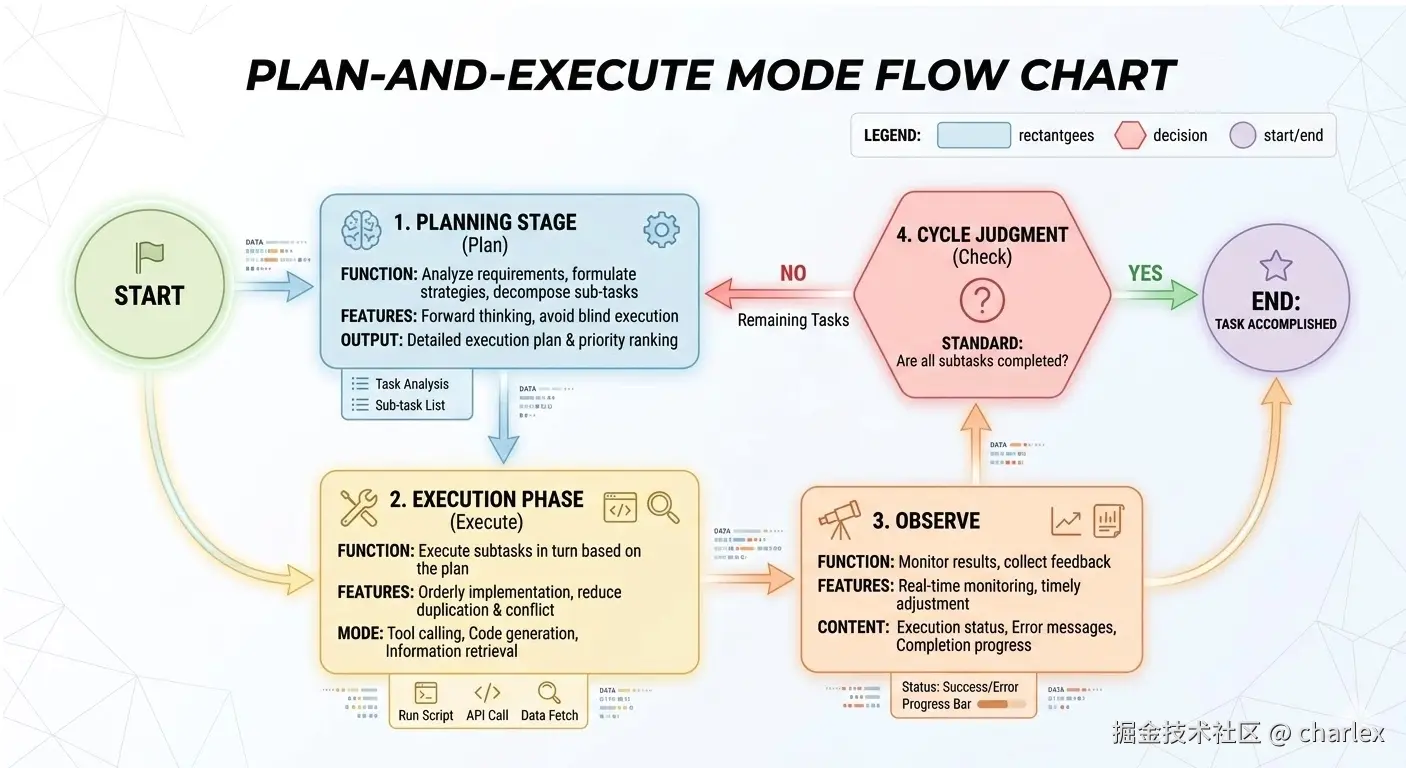
Plan-and-Execute(计划-执行)可以理解为把 Agent 做成一套“可控工作流”:先用一次(或少量几次)推理把路线图规划出来,然后让执行器按步骤落地。
它和 ReAct 的差异主要在“推理与行动的耦合度”上:
因此,Plan-and-Execute 往往把‘推理’集中在规划阶段,把‘执行’交给更稳定的执行器,并用状态来保证过程可追踪。
当前步骤、已完成产物、关键证据/链接,支持失败重试、暂停恢复。def plan_and_execute(goal):
# 1) 规划:一次性生成“可执行”的步骤清单
plan = planner_llm(goal) # e.g. [{step, tool, input, expected_output}]
state = {"i": 0, "artifacts": {}, "notes": []}
# 2) 执行:按步骤推进
while state["i"] < len(plan):
step = plan[state["i"]]
result = run_tool(step.tool, step.input)
state["notes"].append({"step": step, "result": result})
# 3) 必要时重规划:失败/信息不足/偏离目标
if result.status in ["blocked", "failed"]:
plan = replan_llm(goal, plan, state, reason=result.reason)
state["i"] = 0
continue
state["artifacts"].update(result.artifacts)
state["i"] += 1
return state["artifacts"]
下面举的不是“工具类型大全”,而是更偏 Plan-and-Execute:目标明确、步骤多、跨系统、有产物、需要可追踪/可回放。
例 1:每周周报/状态同步自动化
例 2:竞品/资料调研并沉淀知识库
例 3:需求到项目落库(PRD → 拆任务 → 建项目)
通过这篇文档,我们加深了对 AI Agent 的理解:AI 应用正在从“对话式产品(Chat-based UI)”加速走向“以任务为中心的自主工作流(Agentic Workflow)”。这意味着我们的关注点也要跟着迁移——不只是把 prompt 打磨得更顺,而是把“自主性”变成一套可控、可维护、可迭代的工程能力。
在工程视角下,我们把 AI Agent 看成一个闭环控制系统:
也正因为这四块能力要被系统性地组织起来,我们才需要理解不同框架(LangChain / CrewAI / …)各自的编排思路与工程封装差异。
下一步我们把落地问题收敛成三件事:LLM Call(让推理稳定且可解析)、Tools Call(让行动可靠且可审计)、Context Engineering(让上下文成为可运营的运行时)。同时,我们也对比了两种典型执行范式:ReAct 适合探索式推进,Plan-and-Execute 更适合流程化交付,并支持局部重规划。
到这里,我们已经有了一张“从概念到工程”的地图。接下来更有意思的部分是:当我们真的把这些东西写进系统里,会踩哪些坑?上下文怎么拼才不爆 token?RAG的落地实现有多复杂?后续会用更具体的实践案例,把这套框架真正跑起来(先留个坑~)。
156.1MB · 2026-03-12
31.0MB · 2026-03-12
117.49M · 2026-03-12

