


哈曼卡顿Harman Kardon One(哈曼卡顿智能音箱)
156.1MB · 2026-03-12

阅读时长: ~10 min
你可以学习到:
TL;DR: OpenClaw 将上下文管理抽象为一个可插拔的 ContextEngine 接口,核心生命周期包括 bootstrap → ingest → assemble → compact。默认的 Legacy Engine 以 SessionManager + JSONL 为基座,通过 6 步流水线(加载 → 清洗 → 校验 → 裁剪 → 组装 → 调用)完成上下文准备。面对长会话,它用 Compaction 摘要 + Memory Flush 持久化双管齐下,确保不会撑爆 Token 窗口。整套架构通过 Plugin Slot 机制对外开放,你可以替换为任何自定义引擎。
如果你用过 ChatGPT,你一定遇到过这个场景——聊着聊着,它突然"失忆"了,把你之前说的关键信息忘得一干二净。
这不是 AI"笨",而是 Token 窗口有限。每个 LLM 都有一个上下文窗口大小限制(比如 32K、128K Tokens),一旦对话历史超出这个容量,就必须做取舍:是丢掉早期对话?还是做摘要压缩?还是把关键信息存到"长期记忆"里?
对于一个 7x24 自主运行的 AI Agent 来说,这个问题尤为严峻——它不像聊天机器人那样一问一答就结束,它需要在持续运行中维护工具调用结果、文件操作历史、项目上下文等大量信息。
OpenClaw(龙虾 AI)作为一个 GitHub 星标 27 万的开源 AI Agent 框架,给出了一套相当优雅的解决方案。今天我们就来拆解它的**上下文引擎(Context Engine)**架构。
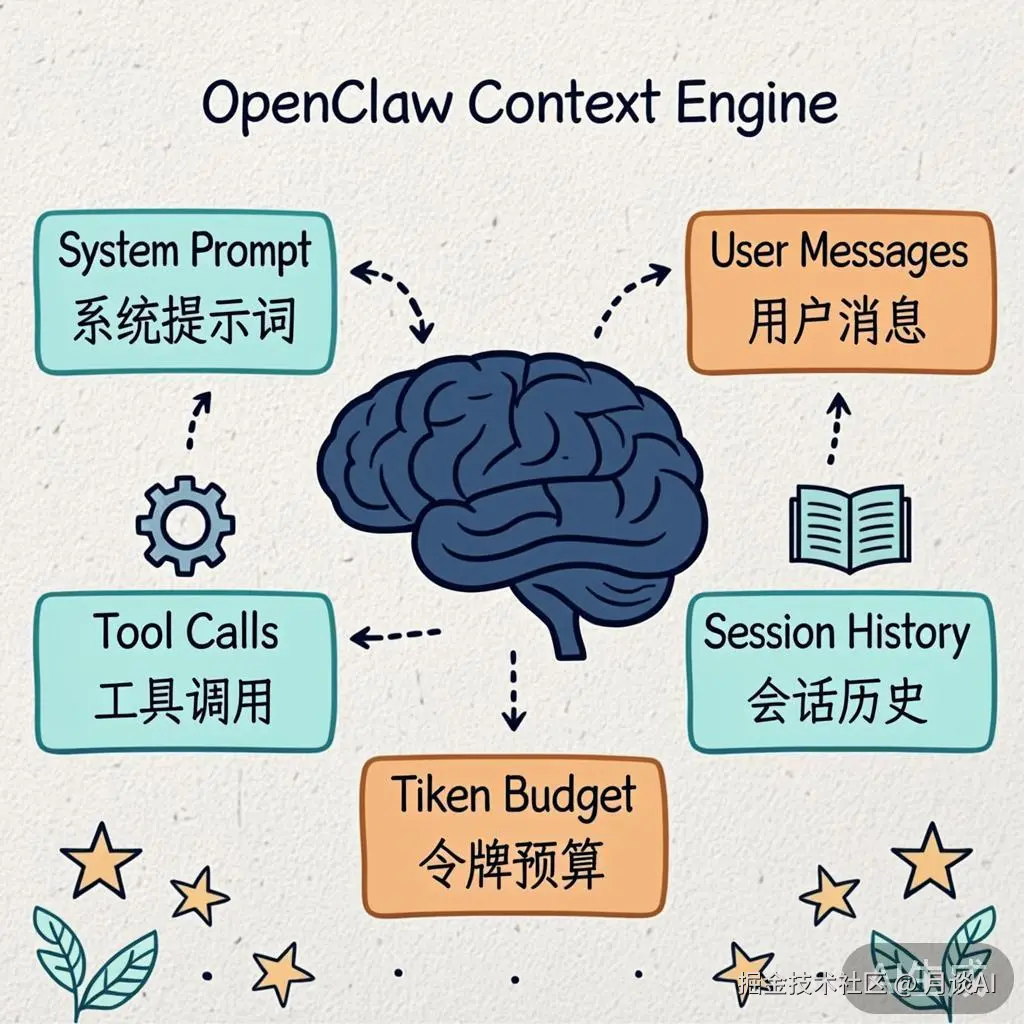
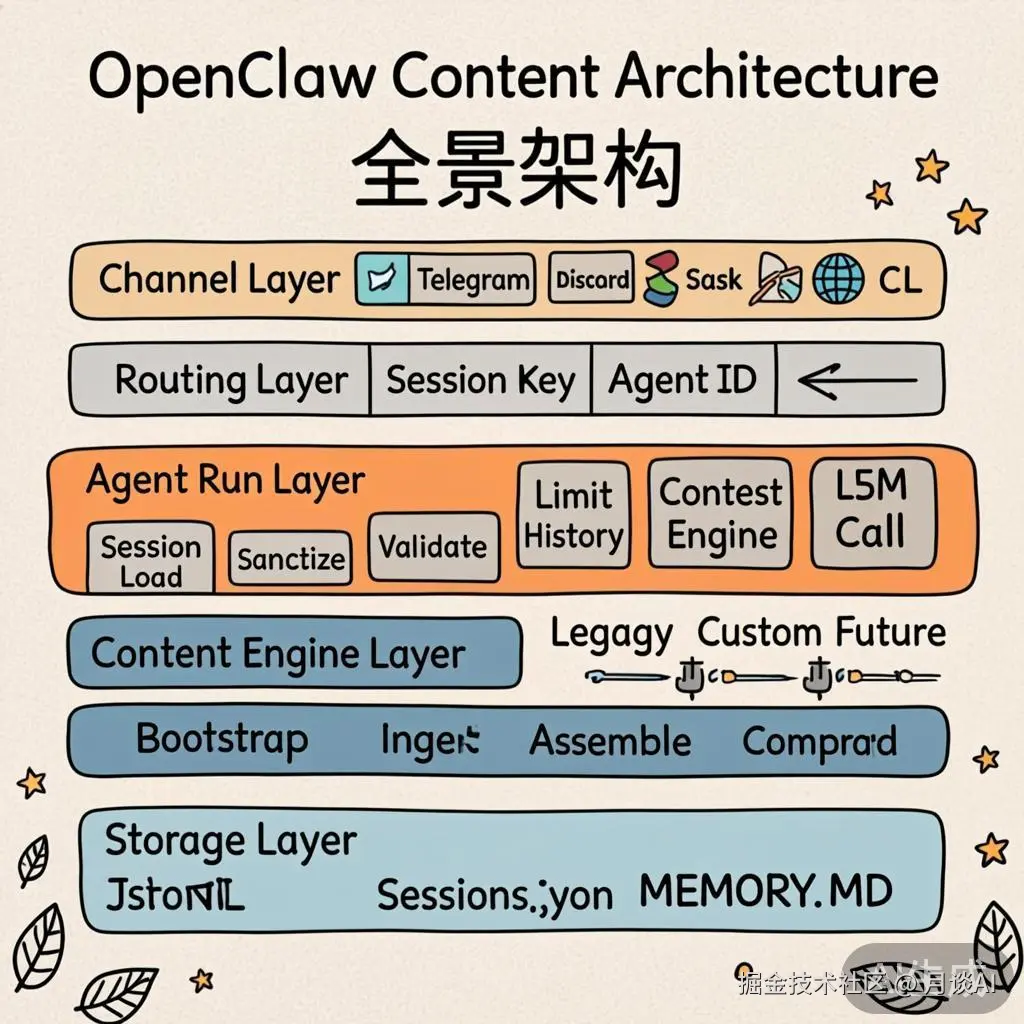
在深入细节之前,让我们先看看一条用户消息从进入 OpenClaw 到最终被 LLM 处理,经历了怎样的上下文组装之旅。
整个流水线可以概括为 6 步:
Session Load → Sanitize → Validate → Limit History → Assemble → LLM Call
加载会话 消息清洗 格式校验 历史裁剪 组装上下文 模型调用
Step 1: Session Load(加载会话)
const sessionManager = await SessionManager.open(sessionFile);
OpenClaw 使用 SessionManager(来自 @mariozechner/pi-coding-agent)加载会话 Transcript。每个会话是一个 JSONL 文件,每一行是一条 AgentMessage,按时间顺序追加。
Step 2: Sanitize(消息清洗)
sanitizeSessionHistory(messages, {
sanitizeImages: true,
sanitizeToolCallIds: true,
dropThinkingBlocks: policy.dropThinkingBlocks,
});
清洗阶段处理的是"脏数据"——包括过大的图片、无效的 Tool Call ID、模型的 Thinking Block 等。不同的 Provider(Anthropic、Google、OpenAI)对消息格式有不同的要求,这一步确保兼容性。
Step 3: Validate(格式校验)
if (policy.validateAnthropicTurns) validateAnthropicTurns(messages);
if (policy.validateGeminiTurns) validateGeminiTurns(messages);
每个 LLM Provider 对消息轮次有自己的规则(比如 Anthropic 要求 user/assistant 严格交替),这里根据 TranscriptPolicy 做针对性校验和修复。
Step 4: Limit History(历史裁剪)
messages = limitHistoryTurns(messages, historyLimit);
这是最直接的"减负"策略——只保留最近 N 轮用户对话。实现很精巧:从后向前扫描,计数用户消息,超出限制就截断。
export function limitHistoryTurns(
messages: AgentMessage[],
limit: number | undefined,
): AgentMessage[] {
if (!limit || limit <= 0 || messages.length === 0) return messages;
let userCount = 0;
let lastUserIndex = messages.length;
for (let i = messages.length - 1; i >= 0; i--) {
if (messages[i].role === "user") {
userCount++;
if (userCount > limit) {
return messages.slice(lastUserIndex);
}
lastUserIndex = i;
}
}
return messages;
}
注意这里的设计巧思:它不是简单地取最后 N 条消息,而是取最后 N 轮用户发起的对话(包括每轮中对应的 assistant 回复和 tool call/result)。这样能保证上下文的完整性。
Step 5: Assemble(组装上下文)
const assembleResult = await contextEngine.assemble({
sessionId,
messages: sanitizedMessages,
tokenBudget,
});
组装阶段将清洗、校验、裁剪后的消息交给 Context Engine 做最终的整理,并估算 Token 消耗。
Step 6: LLM Call(模型调用)
const systemPrompt = createSystemPromptOverride(appendPrompt);
applySystemPromptOverrideToSession(activeSession, systemPrompt);
// -> streamSimple() or provider-specific stream function
最终,组装好的 System Prompt + 对话消息一并发送给 LLM。
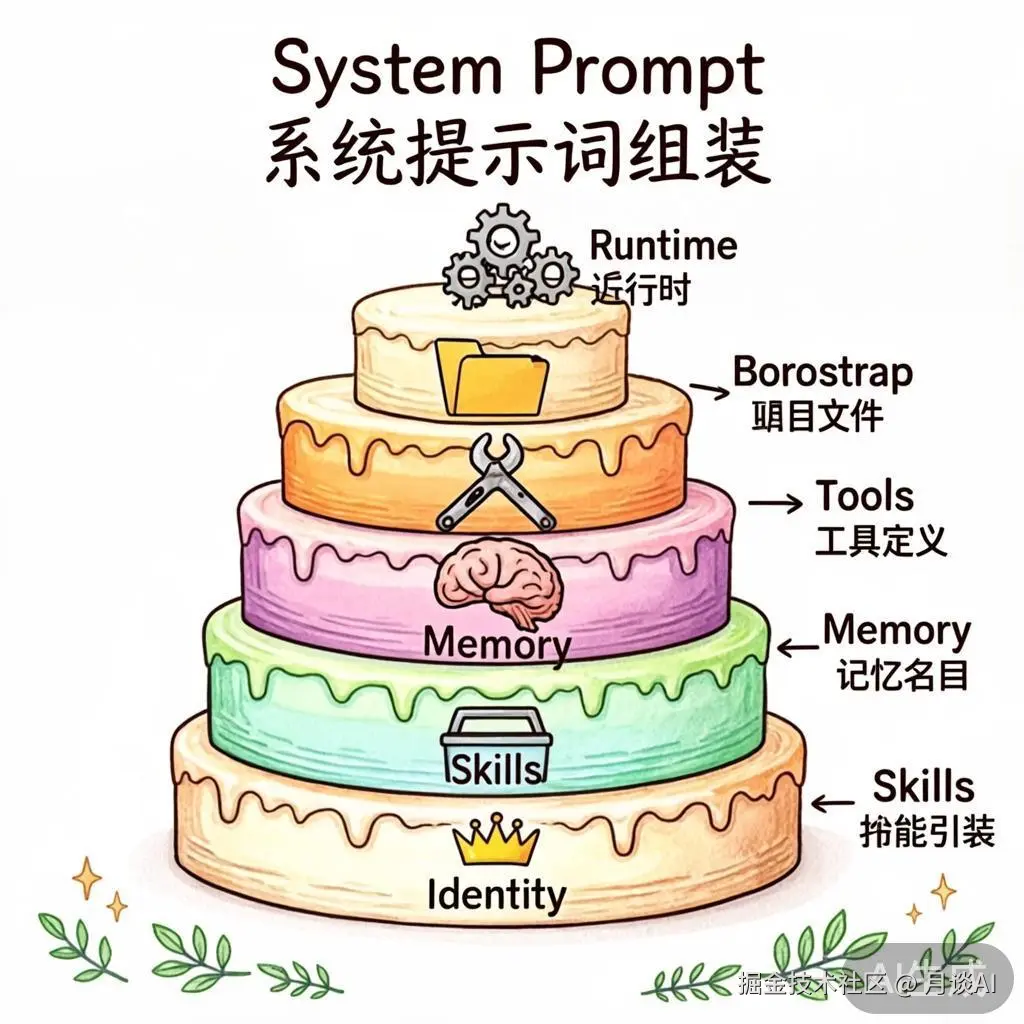
System Prompt 是每次 LLM 调用的"人格基座",OpenClaw 的 System Prompt 不是一个静态字符串,而是通过 buildAgentSystemPrompt() 动态组装的多层结构。
System Prompt 的组装入口在 src/agents/system-prompt.ts,按照以下层次叠加:
| 层次 | 内容 | 来源 |
|---|---|---|
| Identity | Agent 身份标识 | 配置文件 |
| Skills | 可用技能列表 | buildWorkspaceSkillSnapshot() |
| Memory | 记忆召回指令 | Memory tools 可用时注入 |
| Authorized Senders | 授权用户信息 | Owner 配置 |
| Time | 时区信息(仅时区,保持缓存稳定) | 运行时 |
| Tooling | 工具列表和使用说明 | createOpenClawCodingTools() |
| Workspace | 工作区信息 | Bootstrap files |
| Runtime | 运行环境信息(OS、Shell 等) | 运行时检测 |
其中 Skills 层的实现很有意思——它不是把所有 Skill 的完整内容塞进 System Prompt,而是只放一个精简的技能索引:
function buildSkillsSection(params: { skillsPrompt?: string; readToolName: string }) {
return [
"## Skills (mandatory)",
"Before replying: scan <available_skills> <description> entries.",
`- If exactly one skill clearly applies: read its SKILL.md at <location> with `${params.readToolName}`, then follow it.`,
"- If multiple could apply: choose the most specific one, then read/follow it.",
"- If none clearly apply: do not read any SKILL.md.",
// ...
];
}
Agent 被告知:"这里有一份技能清单,如果需要某个技能,用 Read 工具去读取它的 SKILL.md"。这种按需加载的设计避免了把所有技能文档塞满上下文窗口。
除了 System Prompt 本身,OpenClaw 还通过 resolveBootstrapContextForRun() 注入项目上下文文件。这些文件是放在工作区根目录的约定文件:
AGENTS.md / CLAUDE.md — 项目指南和 Agent 行为约束MEMORY.md — 长期记忆文件TOOLS.md — 自定义工具说明IDENTITY.md — Agent 身份定义BOOTSTRAP.md — 启动时注入的额外信息注入时有总量限制:bootstrapMaxChars(单文件默认 20,000 字符)和 bootstrapTotalMaxChars(总计默认 150,000 字符),超出部分会被截断,并在 System Prompt 中附加警告。
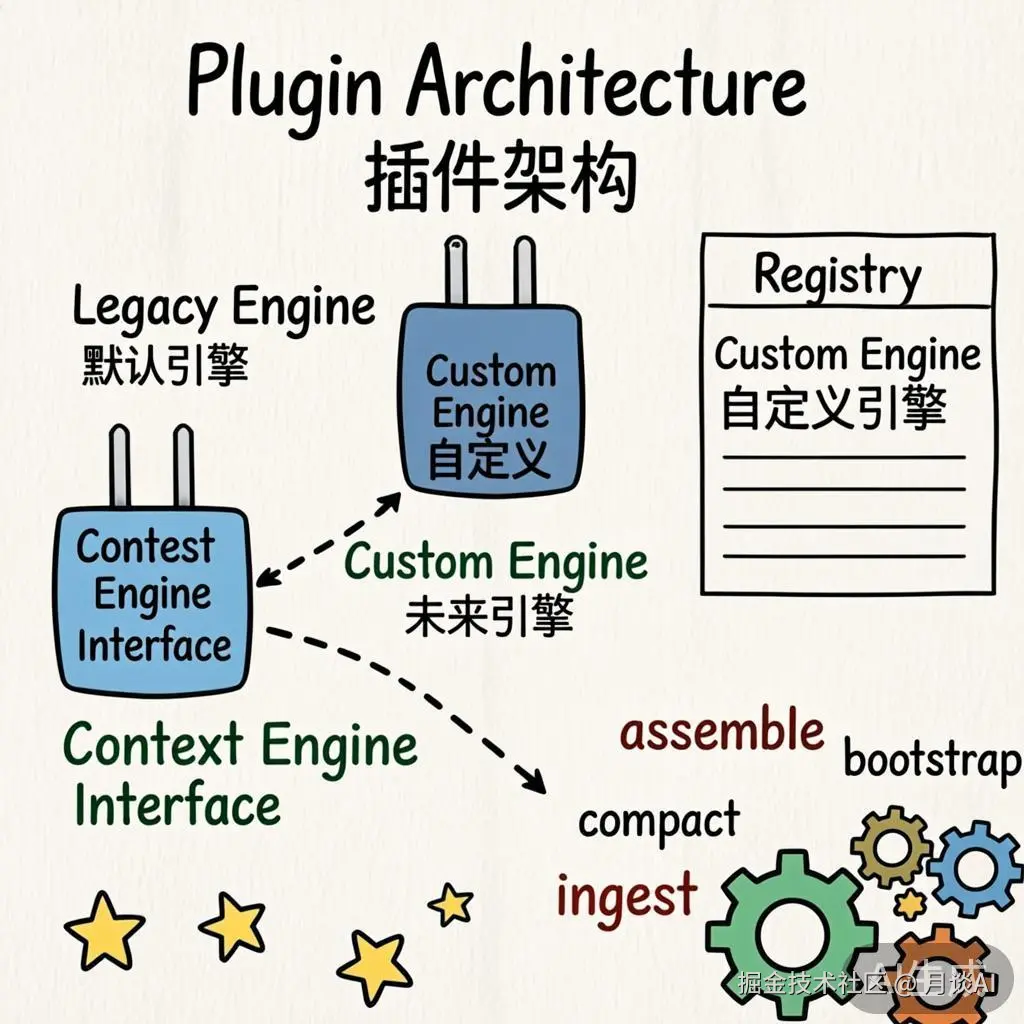
OpenClaw 上下文管理的灵魂在于 ContextEngine 接口: 一个可插拔契约。
export interface ContextEngine {
readonly info: ContextEngineInfo;
// 生命周期方法
bootstrap?(params: { sessionId: string; sessionFile: string }): Promise<BootstrapResult>;
ingest(params: { sessionId: string; message: AgentMessage }): Promise<IngestResult>;
ingestBatch?(params: { sessionId: string; messages: AgentMessage[] }): Promise<IngestBatchResult>;
afterTurn?(params: { sessionId: string; messages: AgentMessage[]; ... }): Promise<void>;
// 核心方法
assemble(params: { sessionId: string; messages: AgentMessage[]; tokenBudget?: number }): Promise<AssembleResult>;
compact(params: { sessionId: string; sessionFile: string; tokenBudget?: number; force?: boolean; ... }): Promise<CompactResult>;
// 子 Agent 管理
prepareSubagentSpawn?(params: { parentSessionKey: string; childSessionKey: string }): Promise<SubagentSpawnPreparation | undefined>;
onSubagentEnded?(params: { childSessionKey: string; reason: SubagentEndReason }): Promise<void>;
dispose?(): Promise<void>;
}
这个接口定义了上下文引擎的完整生命周期:
| 方法 | 职责 | 调用时机 |
|---|---|---|
bootstrap | 初始化引擎状态,可导入历史上下文 | 会话首次启动 |
ingest | 逐条摄入消息 | 每条消息产生后 |
ingestBatch | 批量摄入一轮对话的所有消息 | 一轮对话结束后 |
afterTurn | 轮次后置处理(持久化、触发后台压缩等) | Agent 回复完成后 |
assemble | 在 Token 预算内组装最终上下文 | 每次 LLM 调用前 |
compact | 压缩上下文,生成摘要,删减旧消息 | Token 接近上限时 |
type AssembleResult = {
messages: AgentMessage[]; // 最终发给 LLM 的消息列表
estimatedTokens: number; // 估算的 Token 总量
systemPromptAddition?: string; // 引擎需要追加的 System Prompt 片段
};
type CompactResult = {
ok: boolean;
compacted: boolean;
result?: {
summary?: string; // 压缩摘要内容
firstKeptEntryId?: string; // 保留的第一条消息 ID
tokensBefore: number; // 压缩前 Token 数
tokensAfter?: number; // 压缩后 Token 数
};
};
引擎注册使用 process-global Symbol 确保跨 chunk 共享:
const CONTEXT_ENGINE_REGISTRY_STATE = Symbol.for("openclaw.contextEngineRegistryState");
function registerContextEngine(id: string, factory: ContextEngineFactory): void {
getContextEngineRegistryState().engines.set(id, factory);
}
async function resolveContextEngine(config?: OpenClawConfig): Promise<ContextEngine> {
const engineId = config?.plugins?.slots?.contextEngine ?? "legacy";
const factory = getContextEngineRegistryState().engines.get(engineId);
return factory();
}
解析顺序:
config.plugins.slots.contextEngine 配置"legacy"这意味着你可以通过配置轻松切换到自定义引擎:
plugins:
slots:
contextEngine: my-custom-engine
默认的 LegacyContextEngine 充当了一个适配器——它把现有的基于 SessionManager 的逻辑包装成 ContextEngine 接口:
class LegacyContextEngine implements ContextEngine {
readonly info = { id: "legacy", name: "Legacy Context Engine", version: "1.0.0" };
async ingest(): Promise<IngestResult> {
return { ingested: false }; // No-op: SessionManager 负责持久化
}
async assemble(params): Promise<AssembleResult> {
return { messages: params.messages, estimatedTokens: 0 }; // Pass-through
}
async compact(params): Promise<CompactResult> {
const { compactEmbeddedPiSessionDirect } =
await import("../agents/pi-embedded-runner/compact.runtime.js");
return compactEmbeddedPiSessionDirect({ ...params.runtimeContext, ...params });
}
}
设计思路很清晰:
ingest 是 no-op,因为消息持久化由 SessionManager 已有逻辑处理assemble 是 pass-through,因为上下文清洗/校验逻辑在 attempt.ts 的流水线中compact 委托给已有的 compactEmbeddedPiSessionDirect 函数这种渐进式迁移的设计模式值得学习——先用接口包装现有行为,再逐步将逻辑迁移到引擎内部。
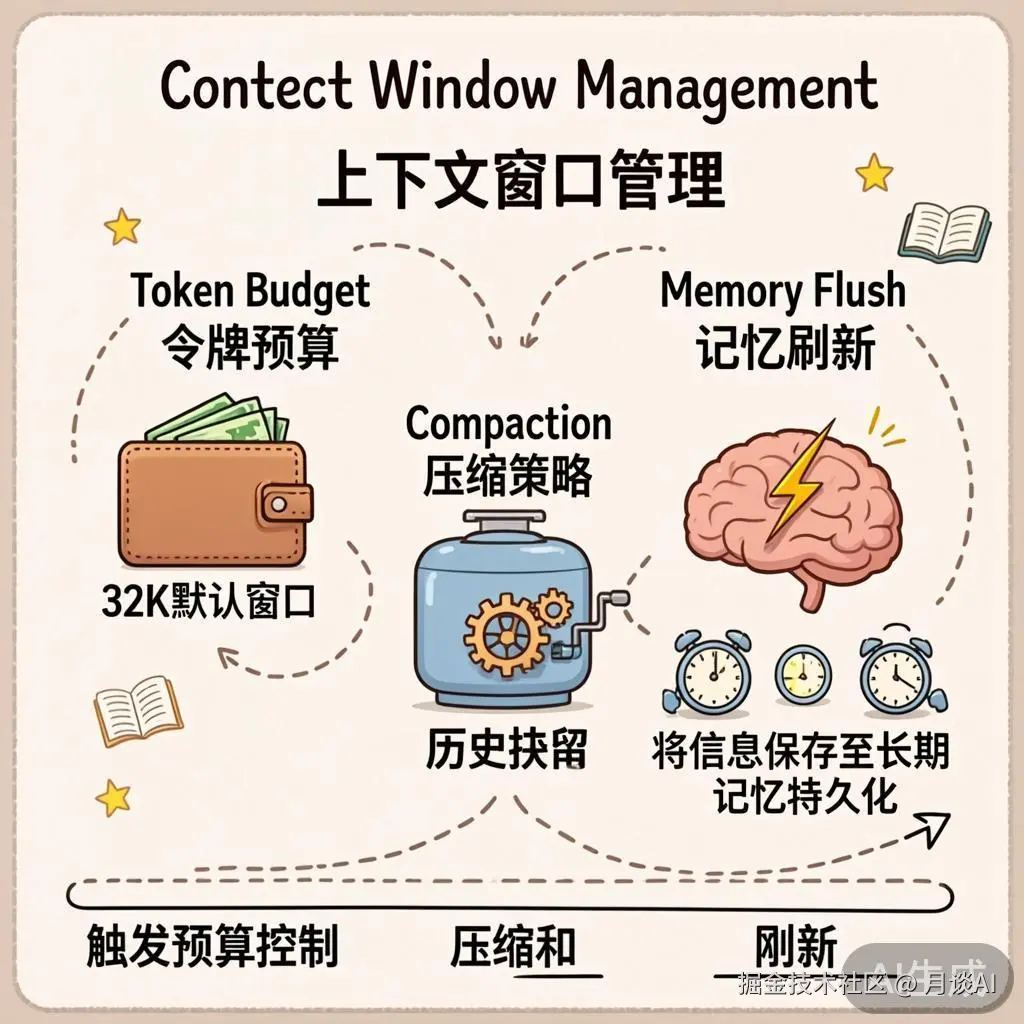
当会话越来越长,上下文 Token 不可避免地会接近窗口限制。OpenClaw 用三种策略来应对:
每次 LLM 调用都有一个明确的 Token 预算:
const contextTokens =
config.agents?.defaults?.contextTokens ??
modelCatalogContextWindow ??
DEFAULT_CONTEXT_TOKENS; // 32,000
预算来源的优先级:用户配置 > 模型目录中的窗口大小 > 默认值 32K。这个预算会传递给 contextEngine.assemble() 和 compact(),作为它们工作的硬约束。
当 Token 接近预算时,Compaction 机制启动。它的核心思路是:用 LLM 生成摘要来替代旧的对话历史。
Compaction 实现:
Compaction 可以通过多种方式触发:
/compact 命令为了安全性,Compaction 有一个超时保护:
compactWithSafetyTimeout(compactParams, EMBEDDED_COMPACTION_TIMEOUT_MS);
Memory Flush 是 Compaction 的"高级版"——它不仅仅压缩上下文,还将关键信息持久化到长期记忆文件中。
实现:
async function runMemoryFlushIfNeeded(params) {
// 当预计 Token 数接近窗口上限时触发
if (projectedTokens > contextWindowTokens - reserveTokensFloor - softThresholdTokens) {
await runEmbeddedPiAgent({
trigger: "memory",
// 用一个专门的 memory-flush prompt 驱动 Agent
// 让它把重要信息写入 MEMORY.md 和 memory/*.md
});
}
}
Memory Flush 的工作流程:
MEMORY.md这与 Agent 日常使用的 Memory 工具(memory_search / memory_get)配合使用——System Prompt 中有明确的指令:
这样即使旧对话被压缩了,关键信息仍然可以通过 Memory 工具被召回。
一条消息从 T@elegrimm/Discord/Slack 等渠道进入后,首先要经过路由确定它属于哪个 Agent、哪个会话。
路由的核心,匹配优先级从高到低:
binding.peer — 精确的用户绑定binding.peer.parent — 父级用户绑定binding.guild+roles — Discord 服务器 + 角色binding.guild — Discord 服务器binding.team — Slack 团队binding.account — 账户级别binding.channel — 渠道级别default — 兜底 Agent路由输出一个 sessionKey(格式如 agent:agentId:telegram:dm:userId),这个 key 唯一标识一个会话。
OpenClaw 的会话持久化策略令人赞赏的简洁:
~/.openclaw/agents/<agentId>/sessions/<sessionId>.jsonl~/.openclaw/agents/<agentId>/sessions/sessions.json每条 AgentMessage 追加写入 JSONL 文件,格式如下:
type AgentMessage = {
role: "user" | "assistant" | "toolResult";
content: TextBlock | ImageBlock | ToolCallBlock | ToolResultBlock;
// ...
};
Session Store 则维护会话的元数据:
type SessionEntry = {
sessionId: string;
sessionFile: string; // JSONL 文件路径
contextTokens: number; // 当前 Token 估算
compactionCount: number; // 已执行的压缩次数
memoryFlushAt: number; // 上次 Memory Flush 时间戳
skillsSnapshot: SkillSnapshot[];
// ...
};
为什么选 JSONL 而不是 SQLite?因为:
不同的 LLM Provider 对消息格式有不同的要求,TranscriptPolicy 封装了这些差异:
type TranscriptPolicy = {
sanitizeMode: "default" | "google";
sanitizeToolCallIds: boolean; // Anthropic 需要
validateAnthropicTurns: boolean; // user/assistant 严格交替
validateGeminiTurns: boolean; // Google 特定的轮次规则
repairToolUseResultPairing: boolean; // 修复孤立的 tool_result
dropThinkingBlocks: boolean; // 移除 Thinking 块
};
除了大刀阔斧的 Compaction,OpenClaw 还有几个精细化的优化手段:
是一个 opt-in 的 Agent 扩展:
CHARS_PER_TOKEN_ESTIMATE = 4 做粗估限制单个 Tool Result 的大小。当一个工具返回了巨大的文件内容或命令输出时,这个 Guard 确保它不会吃掉过多的上下文预算。
一个很巧妙的细节:System Prompt 中的时间信息只包含时区,不包含动态时钟。这样同一个 Agent 的多次调用可以复用 Provider 端的 System Prompt 缓存。
综合以上分析,OpenClaw 的上下文管理架构可以用以下五层来理解:
resolveAgentRoute() 将消息路由到对应的 Session Key 和 Agent IDbootstrap / ingest / assemble / compact 四大生命周期方法,支持 Legacy、Custom、Future 多种引擎实现回顾 OpenClaw 的上下文管理架构,有几个设计决策特别值得学习:
OpenClaw 没有一步到位地设计一个"完美"的 Context Engine,而是先用 Legacy Engine 包装现有行为,再通过接口逐步迁移。这种先抽象接口、再迁移实现的策略大大降低了重构风险。
Token 管理不是靠单一机制,而是多层叠加:
每一层处理不同级别的问题,层层递进。
无论是 Skills 还是 Memory,都不是一股脑塞入上下文,而是在 System Prompt 中给出索引和工具,让 Agent 在需要时主动检索。这种懒加载思路在有限的 Token 预算下尤为重要。
通过 TranscriptPolicy 封装不同 Provider 的差异,上层逻辑不需要关心当前用的是 Anthropic 还是 Google 还是 OpenAI,上下文组装流水线对所有 Provider 一视同仁。
JSONL + JSON 文件的持久化方案看起来"原始",但对于 Agent 场景却恰到好处——追加友好、可读性好、无运维负担。不是所有问题都需要数据库。
OpenClaw 的上下文管理架构展现了一个成熟开源项目对"AI 记忆"问题的系统性思考:
如果你正在构建自己的 AI Agent,OpenClaw 的上下文管理方案是一个极好的参考。特别是 ContextEngine 的插件化设计——它为未来更智能的上下文策略(比如基于 RAG 的检索式上下文、基于向量数据库的语义记忆等)预留了完美的扩展入口。
156.1MB · 2026-03-12
31.0MB · 2026-03-12
117.49M · 2026-03-12

