
哈曼卡顿Harman Kardon One(哈曼卡顿智能音箱)
156.1MB · 2026-03-12

0x00 概要
0x01 大模型 Agent 记忆系统
0x02 大模型 Agent 记忆系统分类体系
0x03 比对
0x04 OpenHands Memory功能解析
0x03 关键组件
0xFF 参考
大模型正在从生成工具演化为具有长期交互能力的智能体,这对“记忆能力”提出了更高的要求,因为大模型的 “记忆能力”,决定了它能走多远,从单轮问答到多轮协作,从通用助手到垂直 Agent,核心都是 “能否记住关键信息、锚定核心目标”——只有记忆突破,AI才能“持续陪伴”,这是增加用户黏性的必然。
而LLM有限的上下文窗口决定了我们不可能将所有历史信息塞入提示。因此,设计一个高效的 「记忆检索」机制至关重要。这不仅仅是技术选型(如使用向量数据库),更是策略设计。如何将对话历史、过往的行动轨迹、成功的经验与失败的教训进行压缩、提炼并结构化存储。
我们看看大模型 Agent 记忆系统的核心设计、挑战与实现路径。
在以自然语言为接口、大模型为核心的 Software 3.0 时代,AI Agent 作为上下文驱动的生成式应用,需突破传统上下文窗口的固有局限。传统依赖上下文窗口维持对话状态与任务记忆的方式,存在长度受限、组织无序、知识静态、成本高昂四大痛点 —— 既无法承载超长历史信息,也难以高效检索与动态更新知识,更会因长文本处理消耗大量计算资源。
从系统架构视角看,Agentic System 可类比为新型操作系统:LLM 扮演 CPU 角色,上下文窗口则如同容量有限的 RAM,而上下文工程就是核心的 “内存管理器”—— 其核心职责并非简单填充数据,而是通过智能调度算法,动态决定上下文数据的加载与换出,确保系统高效运行与结果精准性。
构建持久化、结构化、可检索的 Agent 记忆系统,成为解决上述问题、支撑复杂任务执行的关键,它记录 Agent 的交互历程与知识积累,是连接短期交互与长期智能的核心纽带。
记忆系统作为 Agent 的 “数据飞轮”,是实现真正智能的关键,其核心功能可类比人类认知机制,涵盖多维度能力:
Agent 系统输出不及预期的根源,在基础模型能力达标的前提下,多归因于上下文机制失效 —— 要么缺失关键信息,要么因数据过量导致退化,进而引发幻觉。而记忆系统的构建面临三大核心难点:
在实现中,我们需要考虑很多要点,比如:哪些内容需要保存成长期记忆?什么时候保存?由谁来判断?未来如何召回?召回粒度是多少?如何修剪、更新、合并?
因此,记忆不是静态的数据库,它是一个活的系统。研究者将其生命周期拆解为三个核心过程:形成、演化、检索。
记忆形成(Formation):
记忆演化(Evolution):记忆库如果不维护,就会变得混乱、冲突、过时。
记忆检索(Retrieval)
我们来看看大模型 Agent 记忆系统分类体系的分层逻辑与功能维度解析
Agent 记忆系统的分层设计根植于 1968 年 Atkinson-Shiffrin 记忆模型的核心逻辑,结合 AI 应用场景优化后,形成 “感知 - 短期 - 长期” 三级时效分层体系,各层级功能与特性明确区分:
从实际应用功能出发,长期记忆可进一步划分为四大核心类型,覆盖不同场景的记忆需求:
LangGraph 框架从记忆与会话的绑定关系出发,将记忆简化为 “短期 - 长期” 二元结构,其中长期记忆进一步细分为三类具有明确功能边界的子类型:
短期记忆:与特定会话或任务线程强绑定,即常见的 “历史对话记录”,是 LLM 推理 API 的核心基础参数,核心作用是维持单一会话内的交互连贯性。
长期记忆:不依赖特定会话,可跨场景复用,包括:
论文 Memory in the Age of Agents: A Survey的分类非常值得我们学习。
研究者将记忆的形式归纳为三大类。这三种形式并不是互斥的,而是像人类大脑的不同区域一样协同工作。
这是目前最主流、最可解释的记忆形式。信息以离散的、可读的文本(Token)或数据块的形式存储在模型外部。根据组织方式的复杂程度,它从简单的线性记录进化到了复杂的立体结构。
Mem0 的图记忆版本,就能在对话中实时构建这种实体关系。HiAgent 或 GraphRAG)允许 Agent在宏观规划时调用顶层记忆,在执行具体操作时调用底层细节,极大地平衡了检索效率与信息密度。这种记忆形式更隐蔽。信息不再是存储在硬盘上的文字,而是直接变成了模型神经网络中的权重参数。
K-Adapter),既保留了模型的通用能力,又注入了特定领域的知识,且支持即插即用。这种记忆形式对于人类来说是不可读的,但对于机器来说效率极高。它直接存储模型推理过程中的数学表示。
上下文、知识库、记忆,它们在系统里的角色完全不同。先简略看看几个常见概念的区别。
上下文解决的是「这一次」
上下文窗口是把最近的对话和信息塞给模型,让它在当前任务里保持连贯。窗口再大也有边界,而且天然是会话级的。它适合一次性写方案、短期问答、单次任务冲刺。
知识库解决的是它「不知道」你们公司
RAG 的核心价值是补齐模型权重之外的企业知识、业务数据、文档。它更偏静态知识和结构化事实。它适合企业客服知识问答、产品文档检索、合规和规则解释。
AI 记忆解决的是它「不懂你」
AI 记忆系统要保存并调用用户过去与模型的交互历史,为新会话设置上下文,并持续改进用户画像,让 Agent 能稳定输出个性化结果。
总体上,RAG有助于Agent更准确的回答问题;而Memory则有助于Agent表现的更加智能。Memory 更像一本随时可写、可删、可更新的“笔记本”或“硬盘”;而 RAG 更像一套结构稳定、更新不那么频繁的“参考书体系”。
具体来看。
在更多时候,你需要同时使用它们:
一个优秀的AI代理需要两者兼备——RAG提供世界知识,内存提供用户理解。
上下文工程:是一种资源管理手段。因为模型的窗口有限,我们通过各种技巧(如Prompt压缩、重要性筛选)把最重要的信息塞进去。
Agent记忆:是认知建模。它决定了哪些信息值得被保留下来成为长期记忆,并在未来几天、几个月甚至几年后被调用。上下文工程是“怎么塞进去”,而 Agent记忆是“该塞什么”(的一部分)。
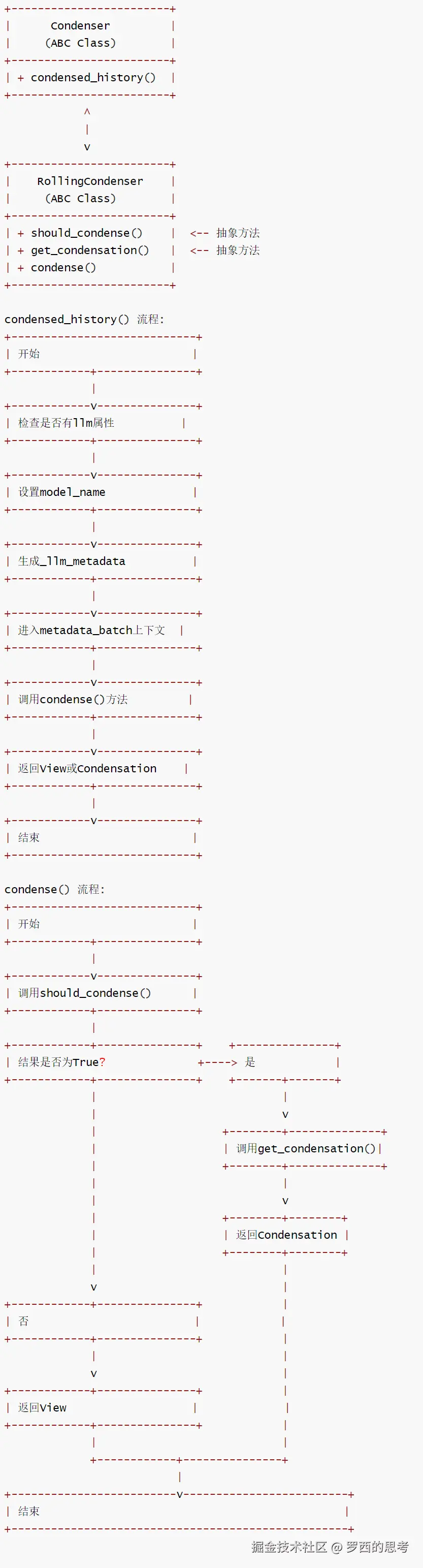
在智能代理的运行机制中,Memory模块扮演着 “记忆中心” 的角色,专门负责处理和管理代理所需的上下文信息。上下文管理的挑战在于如何在有限的上下文窗口内提供最相关的信息。由于大语言模型的上下文窗口存在容量限制,单纯把所有历史信息堆砌进去显然不现实。为此,OpenHands 设计了一套三层记忆模型:
这三个层共同构成了 OpenHands 中对话历史管理和消息处理的核心机制,分别负责压缩、表示和转换三个关键环节。既让代理能够获取到决策所需的完整上下文,又通过Condenser的机制有效避免了上下文窗口溢出,保障了代理在长时间任务中逻辑的连贯性。巧妙应对 “上下文有限” 这一难题。
memory/
│
│──── condenser/ # 历史压缩器
│ │
│ │──── condenser.py # 压缩器基类
│ │──── ... # 各种压缩策略
│
│──── conversation_memory.py # 对话内存管理
│──── view.py # 事件视图
View 作为中间数据结构,连接压缩和转换两个阶段。View 的主要工作是对原始的Event Stream进行首次过滤和整理。在众多事件中,有些对语言模型的决策没有直接帮助,比如NullAction、AgentStateChangedObservation这类 “噪声” 事件,View会将它们排除在外。同时,它还会处理 “记忆压缩” 相关事件,最终形成一个相对简洁的事件序列。作为内存管理系统里处理事件历史的关键部分,view.py 能确保代理在处理长对话历史时,不会超出上下文的限制。
Condenser.condensed_history () 方法返回压缩后的历史记录,可能包含:
ConversationMemory 的核心任务是将View提供的事件列表 —— 这些列表更贴合机器的处理方式 —— 转换成语言模型更容易理解的对话格式,也就是List[Message]。每个Message对象都包含 “角色”(比如 “用户”“助手”“工具”)和 “内容” 两部分,这正好符合大多数语言模型 API 对输入格式的要求。
ConversationMemory 专注于消息格式转换,确保消息格式正确,提高 LLM 理解效率:
相关配置:
这种设计实现了关注点分离:Condenser 专注于历史压缩,ConversationMemory 专注于消息格式化,而 View 作为中间数据结构连接两者。
Condenser是解决长上下文问题的关键环节。当View中的事件数量超出预设的阈值时,Condenser就会启动工作。它会借助语言模型对一部分较早的历史事件进行总结,生成一个简短的CondensationObservation事件。之后,用这个总结来替代那些被移除的大量原始事件,从而实现对上下文的 “有损压缩”。
Condenser 专注于历史压缩算法实现,可以通过 Condenser 减少传递给 LLM 的上下文大小,降低计算成本,也防止超出 LLM 的上下文窗口限制
实际工作流程如下:
Agent.step()(决策层)
↓
Condenser.condensed_history()(历史压缩器)
↓
View.from_events() (事件视图)
↓
返回View(events=[...])
↓
Agent处理View.events
↓
ConversationMemory.process_events()(对话内存)
↓
LLM处理压缩后的事件历史
OpenHands 原生核心记忆实现不使用图结构,默认采用线性时序文本与键值对存储;图结构仅为可选扩展方案,非框架标配。
只使用一维的扁平记忆存在一定问题:
因为OpenHands 具备灵活的插件扩展能力,若需针对复杂关联信息(如实体关系、任务依赖链路)进行记忆管理,可通过自定义记忆插件引入图结构(如知识图谱),但这并非框架原生内置的核心记忆实现方式,仅为特定场景下的可选优化方案。
我们对 View、ConversationMemory 和 Condenser 再进行详细分析。
ConversationMemory 依赖于 Condenser 的输出(特别是 View 中的事件列表)来构建消息历史
CodeActAgent 同时使用这两个组件:先通过 Condenser 压缩历史,再通过 ConversationMemory 转换为消息
筛选操作:
移除操作:
工作流程如下:
AgentController.step()
→ Condenser.condensed_history() 【筛选/压缩】
→ ConversationMemory.process_events() 【处理筛选后的事件】
→ 传递给 LLM 的消息列表 【只包含筛选后的信息】
__len__、__iter__、__getitem__),支持索引和切片操作。class View(BaseModel):
"""Linearly ordered view of events.
Produced by a condenser to indicate the included events are ready to process as LLM input.
"""
events: list[Event]
unhandled_condensation_request: bool = False
def __len__(self) -> int:
return len(self.events)
def __iter__(self):
return iter(self.events)
@overload
def __getitem__(self, key: slice) -> list[Event]: ...
@overload
def __getitem__(self, key: int) -> Event: ...
def __getitem__(self, key: int | slice) -> Event | list[Event]:
if isinstance(key, slice):
start, stop, step = key.indices(len(self))
return [self[i] for i in range(start, stop, step)]
elif isinstance(key, int):
return self.events[key]
else:
raise ValueError(f'Invalid key type: {type(key)}')
@staticmethod
def from_events(events: list[Event]) -> View:
"""Create a view from a list of events, respecting the semantics of any condensation events."""
# 识别需要遗忘的事件
forgotten_event_ids: set[int] = set()
# 处理压缩动作和需求
for event in events:
if isinstance(event, CondensationAction):
# 标记被压缩的事件ID
forgotten_event_ids.update(event.forgotten)
# Make sure we also forget the condensation action itself
# 标记压缩动作也要被遗忘
forgotten_event_ids.add(event.id)
if isinstance(event, CondensationRequestAction):
# 标记压缩请求也要被遗忘
forgotten_event_ids.add(event.id)
# 保留未被遗忘的事件
kept_events = [event for event in events if event.id not in forgotten_event_ids]
# If we have a summary, insert it at the specified offset.
summary: str | None = None
summary_offset: int | None = None
# The relevant summary is always in the last condensation event (i.e., the most recent one).
# 从后往前查找最新压缩动作中的摘要
for event in reversed(events):
if isinstance(event, CondensationAction):
if event.summary is not None and event.summary_offset is not None:
summary = event.summary
summary_offset = event.summary_offset
break
# 在指定位置插入摘要信息
if summary is not None and summary_offset is not None:
kept_events.insert(
summary_offset, AgentCondensationObservation(content=summary)
)
# Check for an unhandled condensation request -- these are events closer to the
# end of the list than any condensation action.
# 检查未处理的压缩请求
unhandled_condensation_request = False
for event in reversed(events):
if isinstance(event, CondensationAction):
break # 遇到压缩动作就停止
if isinstance(event, CondensationRequestAction):
unhandled_condensation_request = True
break
return View(
events=kept_events,
unhandled_condensation_request=unhandled_condensation_request,
)
View 与其他组件的关系如下:
CodeActAgent 使用View 的例子如下:
def step(self, state: State) -> 'Action':
# Condense the events from the state. If we get a view we'll pass those
# to the conversation manager for processing, but if we get a condensation
# event we'll just return that instead of an action. The controller will
# immediately ask the agent to step again with the new view.
condensed_history: list[Event] = []
# 获取压缩后的历史视图
match self.condenser.condensed_history(state):
case View(events=events):
# 经过压缩后的事件列表
condensed_history = events
case Condensation(action=condensation_action):
# 如果返回的是压缩动作,则立即执行
return condensation_action
# 使用压缩后的事件构建消息历史
initial_user_message = self._get_initial_user_message(state.history)
messages = self._get_messages(condensed_history, initial_user_message)
ConversationMemory使用View处理事件
此处只使用process_events 来介绍,在 process_events 方法中,系统会:
遍历所有事件(动作和观察结果)
调用相应处理方法生成消息
检查待处理的工具调用是否已完成
如果工具调用已完成(即有对应的响应):
最后过滤掉不匹配的工具调用和响应
流程如下。
13-1
代码如下。
class ConversationMemory:
"""将事件历史处理为智能体的连贯对话。"""
def __init__(self, config: AgentConfig, prompt_manager: PromptManager):
self.agent_config = config # 智能体配置
self.prompt_manager = prompt_manager # 提示管理器
def process_events(
self,
condensed_history: list[Event],
initial_user_action: MessageAction,
max_message_chars: int | None = None,
vision_is_active: bool = False,
) -> list[Message]:
"""将状态历史处理为LLM的消息列表。
确保在函数调用模式下正确处理工具调用动作。
参数:
condensed_history: 要转换的压缩事件历史
max_message_chars: 包含在LLM提示中的事件内容的最大字符数。
较长的观察结果将被截断。
vision_is_active: LLM中是否激活视觉功能。如果为True,将包含图像URL。
initial_user_action: 初始用户消息动作(如果有)。用于确保对话正确开始。
"""
events = condensed_history # 使用压缩后的事件历史
# 确保事件列表以SystemMessageAction开头,然后是MessageAction(source='user')
self._ensure_system_message(events)
self._ensure_initial_user_message(events, initial_user_action)
# 记录视觉浏览状态
logger.debug(f'Visual browsing: {self.agent_config.enable_som_visual_browsing}')
# 初始化空消息列表
messages = []
# 处理常规事件
pending_tool_call_action_messages: dict[str, Message] = {} # 待处理的工具调用消息
tool_call_id_to_message: dict[str, Message] = {} # 工具调用ID与消息的映射
# 遍历View提供的事件列表
for i, event in enumerate(events):
# 从事件创建常规消息
if isinstance(event, Action):
messages_to_add = self._process_action(
action=event,
pending_tool_call_action_messages=pending_tool_call_action_messages,
vision_is_active=vision_is_active,
)
elif isinstance(event, Observation):
messages_to_add = self._process_observation(
obs=event,
tool_call_id_to_message=tool_call_id_to_message,
max_message_chars=max_message_chars,
vision_is_active=vision_is_active,
enable_som_visual_browsing=self.agent_config.enable_som_visual_browsing,
current_index=i,
events=events,
)
else:
raise ValueError(f'未知事件类型: {type(event)}')
# 检查待处理的工具调用消息,看它们是否已完成
_response_ids_to_remove = []
for (
response_id,
pending_message,
) in pending_tool_call_action_messages.items():
assert pending_message.tool_calls is not None, (
'当启用函数调用且消息被视为待处理工具调用时,工具调用不应为None。'
f'待处理消息: {pending_message}'
)
# 检查所有工具调用是否都有对应的响应
if all(
tool_call.id in tool_call_id_to_message
for tool_call in pending_message.tool_calls
):
# 如果完成:
# -- 1. 添加**发起**工具调用的消息
messages_to_add.append(pending_message)
# -- 2. 添加工具调用的**结果**
for tool_call in pending_message.tool_calls:
messages_to_add.append(tool_call_id_to_message[tool_call.id])
tool_call_id_to_message.pop(tool_call.id)
_response_ids_to_remove.append(response_id)
# 清理已处理的待处理工具消息
for response_id in _response_ids_to_remove:
pending_tool_call_action_messages.pop(response_id)
messages += messages_to_add
# 应用最终过滤,确保上下文中的消息没有不匹配的工具调用和工具响应
messages = list(ConversationMemory._filter_unmatched_tool_calls(messages))
# 应用最终格式化
messages = self._apply_user_message_formatting(messages)
return messages
_process_action 方法会处理工具调用,工具调用类型为:
处理流程为:
在 _process_observation 方法中,ConversationMemory 处理各种工具调用的响应,工具响应类型为:
结果处理流程为:
Condensor的功能如下:
流程如下
13-2
代码如下.
Condenser抽象类和滚动压缩策略的RollingCondenser基类should_condense方法判断是否需要压缩,实现灵活的滚动压缩机制class Condenser(ABC):
"""抽象压缩器接口
压缩器接收`Event`对象列表并将其缩减为可能更小的列表。
智能体可以使用压缩器来减少在决定采取何种行动时需要考虑的事件数量。
要使用压缩器,智能体可以对当前正在考虑的`State`调用`condensed_history`方法,
并使用结果代替完整历史。
如果压缩器返回`Condensation`而不是`View`,智能体应该返回`Condensation.action`
而不是生成自己的行动。在下一个智能体步骤中,压缩器将使用该压缩事件生成新的`View`。
"""
def condensed_history(self, state: State) -> View | Condensation:
"""压缩状态的历史记录"""
# 确定LLM模型名称(如果存在)
if hasattr(self, 'llm'):
model_name = self.llm.config.model
else:
model_name = 'unknown'
# 生成LLM元数据
self._llm_metadata = state.to_llm_metadata(
model_name=model_name, agent_name='condenser'
)
# 在元数据批次上下文中执行压缩
with self.metadata_batch(state):
return self.condense(state.view)
class RollingCondenser(Condenser, ABC):
"""专门用于对滚动历史进行压缩的策略基类
滚动历史由`View.from_events`生成,该方法分析历史中的所有事件并生成
一个`View`对象,表示将发送给LLM的内容。
如果`should_condense`返回True,则压缩器负责从`View`对象生成`Condensation`对象。
这将被添加到事件历史中,当传递给`get_view`时,应该生成将传递给LLM的压缩`View`。
"""
@abstractmethod
def should_condense(self, view: View) -> bool:
"""确定是否应该压缩视图"""
@abstractmethod
def get_condensation(self, view: View) -> Condensation:
"""从视图中获取压缩结果"""
def condense(self, view: View) -> View | Condensation:
# 如果触发了压缩器特定的压缩阈值,则计算并返回压缩结果
if self.should_condense(view):
return self.get_condensation(view)
# 否则,直接返回视图
else:
return view
Condenser 使用的提示词主要存储在 llm_summarizing_condenser.py 文件中的默认常量中,同时也支持通过配置文件指定自定义提示词模板。系统使用 PromptManager 来管理这些提示词,并在需要时动态构建完整的提示词内容传递给 LLM。
prompt = """You are maintaining a context-aware state summary for an interactive agent.
You will be given a list of events corresponding to actions taken by the agent, and the most recent previous summary if one exists.
If the events being summarized contain ANY task-tracking, you MUST include a TASK_TRACKING section to maintain continuity.
When referencing tasks make sure to preserve exact task IDs and statuses.
Track:
USER_CONTEXT: (Preserve essential user requirements, goals, and clarifications in concise form)
TASK_TRACKING: {Active tasks, their IDs and statuses - PRESERVE TASK IDs}
COMPLETED: (Tasks completed so far, with brief results)
PENDING: (Tasks that still need to be done)
CURRENT_STATE: (Current variables, data structures, or relevant state)
For code-specific tasks, also include:
CODE_STATE: {File paths, function signatures, data structures}
TESTS: {Failing cases, error messages, outputs}
CHANGES: {Code edits, variable updates}
DEPS: {Dependencies, imports, external calls}
VERSION_CONTROL_STATUS: {Repository state, current branch, PR status, commit history}
PRIORITIZE:
1. Adapt tracking format to match the actual task type
2. Capture key user requirements and goals
3. Distinguish between completed and pending tasks
4. Keep all sections concise and relevant
SKIP: Tracking irrelevant details for the current task type
Example formats:
For code tasks:
USER_CONTEXT: Fix FITS card float representation issue
COMPLETED: Modified mod_float() in card.py, all tests passing
PENDING: Create PR, update documentation
CODE_STATE: mod_float() in card.py updated
TESTS: test_format() passed
CHANGES: str(val) replaces f"{val:.16G}"
DEPS: None modified
VERSION_CONTROL_STATUS: Branch: fix-float-precision, Latest commit: a1b2c3d
For other tasks:
USER_CONTEXT: Write 20 haikus based on coin flip results
COMPLETED: 15 haikus written for results [T,H,T,H,T,H,T,T,H,T,H,T,H,T,H]
PENDING: 5 more haikus needed
CURRENT_STATE: Last flip: Heads, Haiku count: 15/20"""
1. 记忆系统和 RAG
一文全解析:AI 智能体 8 种常见的记忆(Memory)策略与技术实现
mem0 源码阅读:一个工程化记忆系统
AI Agent最新「Memory」综述 |多所顶尖机构联合发布
对 COLMA 认知分层记忆架构的工程化重构与思考
AI Agent最新「Memory」综述 |多所顶尖机构联合发布
本文使用 markdown.com.cn 排版
156.1MB · 2026-03-12
31.0MB · 2026-03-12
117.49M · 2026-03-12

