
爱回收
75.46M · 2026-04-05

上下文窗口是 LLM 最核心、最昂贵,也是最稀缺的资源。如何在这有限的空间里,精准地组织、管理和提供信息,直接决定了 Agent 的性能、成本与可靠性。本文将围绕三个核心主题展开:
1.概念定义:介绍上下文工程的基本概念和核心组成部分。
2.业界工程实践: 深入分析业界知名产品在上下文工程方面的具体实践。
3.未来展望: 探讨上下文工程后续可能的演进方向。
今天我们将探讨的问题:
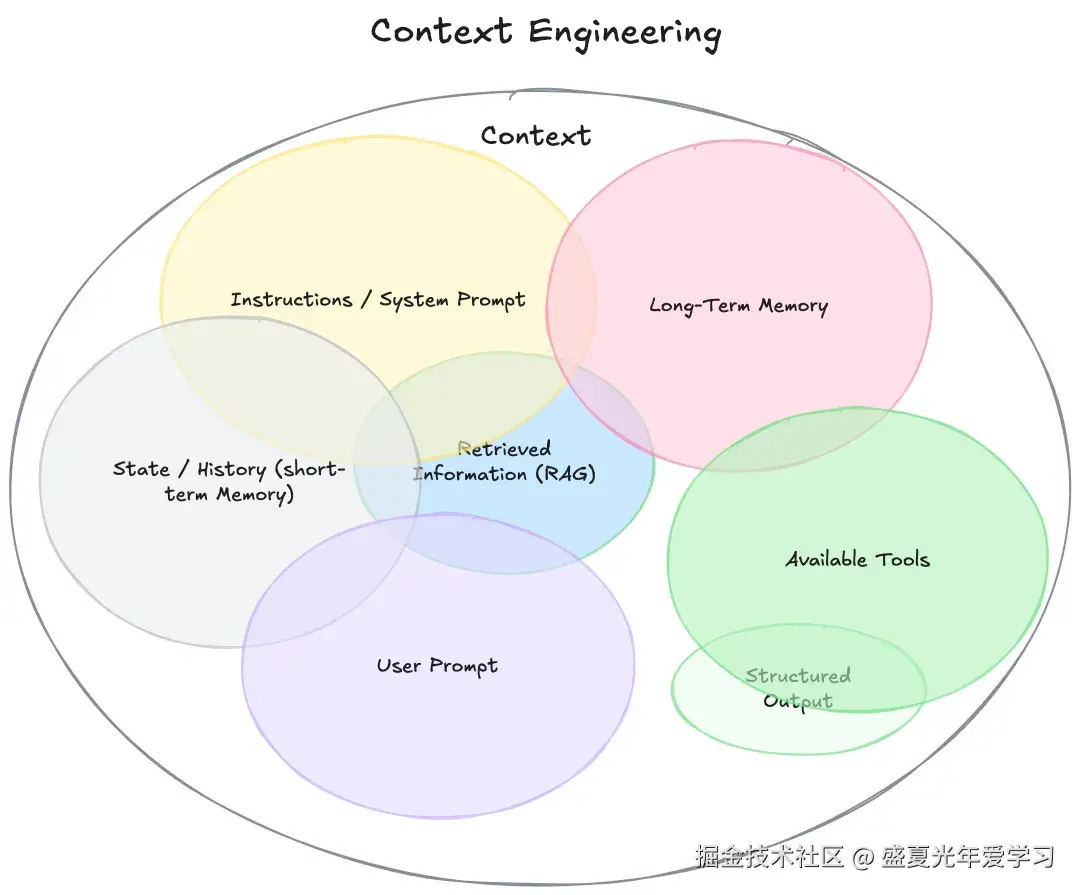
上下文工程是指构建动态系统,以合适的格式为大语言模型(LLM)提供正确的信息和工具,从而让LLM能够合理地完成任务。
它不再将“上下文”视为单一的提示词,而是模型生成响应前所看到的一切信息:系统指令、对话历史、外部知识、可用工具、输出规范等。其核心是解决“在有限窗口内,如何填入最相关信息”这一根本矛盾。
一个完整的上下文工程系统包含以下七个核心组成部分(非严格官方标准):
1.指令/系统提示词: 定义模型整体行为的初始指令,可以(也应该)包含示例、规则等。
2.用户提示词: 用户提出的即时任务或问题。
3.当前状态或对话历史(短期记忆): 用户和模型此前的对话内容,展现当前交流的背景。
4.长期记忆: 跨多次对话积累的持久性知识库,比如用户喜好、历史项目摘要、记住的特定事实。
5.检索的信息(RAG): 外部的、最新的信息,包括从文档、数据库或 API 获取的相关内容,用于回答特定问题。
6.可用工具: 模型可以调用的所有函数或内置工具定义(如检查库存、发送邮件等)。
7.结构化输出: 明确定义模型输出的格式,例如 JSON 格式的对象。
提示工程是上下文工程的子集和起点,两者在关注点、范围和隐喻上有本质区别:
| 对比维度 | Prompt Engineering | Context Engineering |
|---|---|---|
| 关注点 | 词句技巧和表达方式 | 提供全面上下文 |
| 作用范围 | 只限于任务描述的表达 | 包含文档、示例、规则、模式和验证 |
| 类比 | 就像贴一张便签 | 就像写一部详细剧本 |
在 Agent 场景下,上下文管理面临严峻挑战,这些问题统称为“Context-Rot”(上下文腐蚀)。
这是长上下文带来的根本性问题:
在上下文工程领域,有三个产品代表了不同的实践方向:
1.LangChain: 代表 Agent 框架和工具集合,早期的 Agent 框架,提供了各种Agent开发的基础设施,提出了一套上下文管理的方法论。
2.Claude Code: 代表 Code Agent 能力上限,编码 Agent 的能力标杆,在长短记忆、分层多 Agent 协作等方面有独到实践。
3.Manus: 重新展现 Agent 能力,让 Agent 回到大众视野,带动 MCP 发展,在工具使用、缓存设计等方面有独到实践。
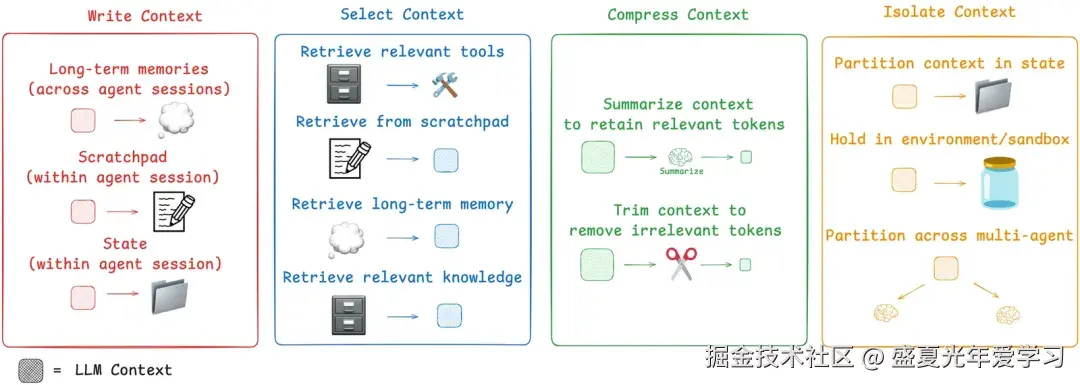
LangChain 提出了四类上下文管理的基本方法:
图片来源于网络
图片来源于网络
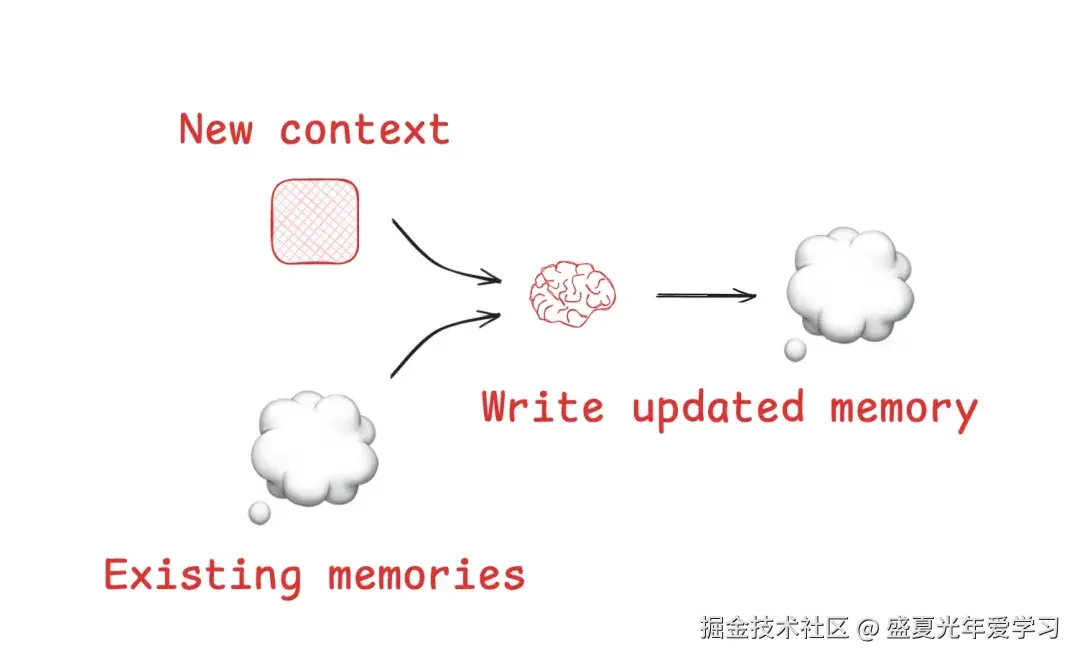
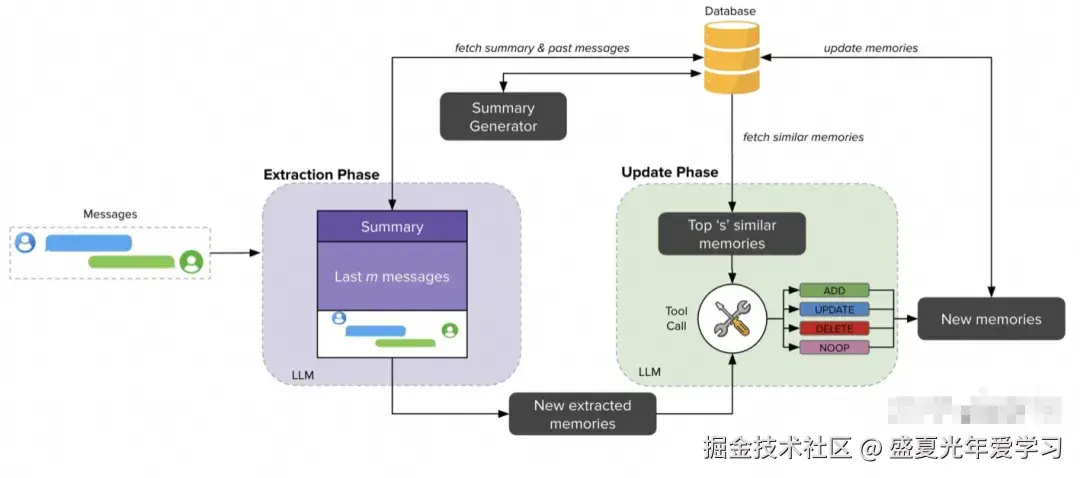
将信息保存在上下文窗口之外,以帮助 Agent 完成任务。不要将工具返回的全部原始信息都直接喂给 LLM。相反,应将其"卸载"到外部存储(如文件系统、数据库或一个专门的代理状态对象中),然后只将一个轻量级的"指针"返回给模型。
核心组件包括:
应用场景:
简单来说就是我们所熟悉的 RAG,通过检索和过滤相关信息,来控制进入 Context 的内容的数量和质量。
核心组件:
应用场景:
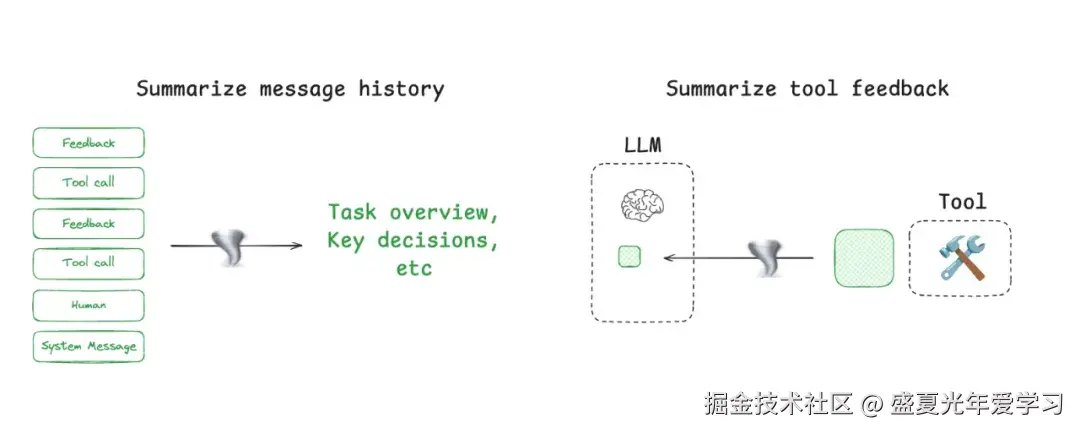
通过各种手段来裁剪上下文的内容,只保留完成任务所需的 tokens。
图片来源于网络
核心组件:
应用场景:
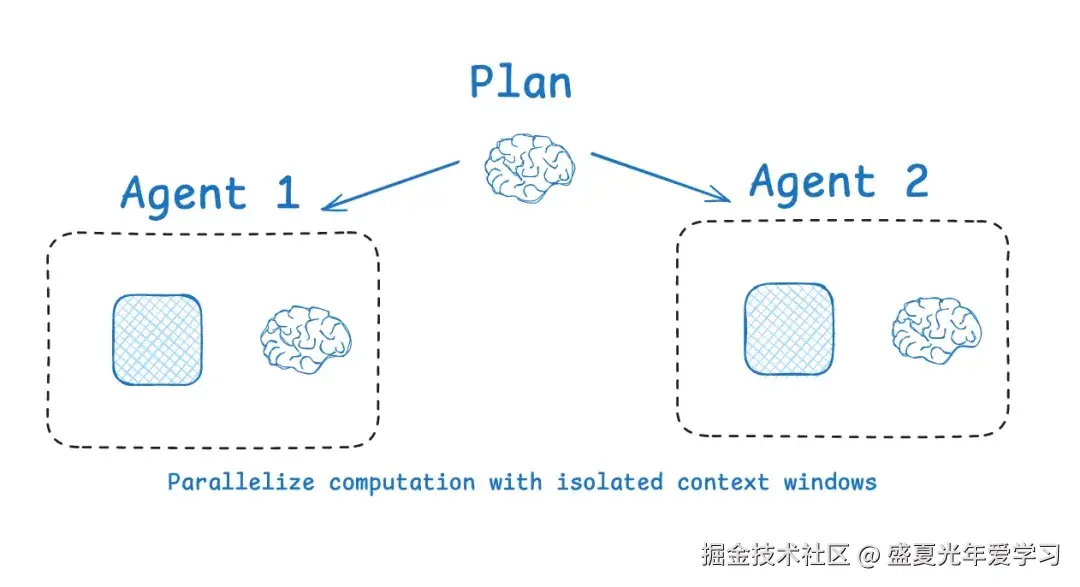
非常类似 Workflow 时代的"分而治之"思想,如果一个任务的 context 压力太过巨大,我们就拆分一下,分配给不同的 sub agents 来完成各个子任务。这样每个 agent 的 context 内容都是独立的,会更加清晰和聚焦。
核心组件:
应用场景:
Claude Code 作为编码 Agent 的标杆,在上下文工程方面有很多独到的实践。Claude Code的上下文工程设计遵循一个核心隐喻:像查字典一样工作。不是把整本字典背下来,而是通过索引从海量的信息中快速定位到需要的信息。这一理念体现在四个关键机制:CLAUDE.md(用法说明)、Auto memory(个人笔记)、自动压缩(精简摘要),以及SubAgent(分册查询)。
传统AI系统的上下文管理常陷入"背字典"的陷阱:试图将所有知识预加载到模型上下文中,导致窗口迅速膨胀、关键信息淹没。Claude Code则采用"查字典"模式:
| 模式 | 特征 | 问题 |
|---|---|---|
| 背字典 | 预加载所有可能相关的文件、文档、历史记录 | 上下文膨胀,注意力稀释,成本激增 |
| 查字典 | 保留索引(路径),按需读取,用完即释放 | 窗口精简,信息精确,成本可控 |
这一模式成立的前提是:索引必须可靠。Claude Code通过文件路径、命名规范、目录结构作为天然索引,配合shell工具(grep/glob/head/tail)实现快速定位。
CLAUDE.md并非供模型"阅读"的百科内容,而是查字典前的用法指导——告诉你这本字典怎么查、哪些词最重要、哪些词别碰。
Anthropic工程团队明确指出 :LLM是无状态函数,不会在交互中持续学习,CLAUDE.md的作用类似于函数的config参数。每次API调用自动携带,确保模型在"翻开字典"前就知道查询规则。
分层加载机制
CLAUDE.md支持四级覆盖,优先级由高到低:
./CLAUDE.md 或 .claude/CLAUDE.md~/.claude/CLAUDE.md高优先级文件中的同名配置会完全覆盖低优先级版本。这种设计类似于不同场景下的专用字典:法律词典、医学词典、技术词典,各有其用法说明,按需选用。
信噪比控制
系统提示中明确约束:"除非用户查询与CLAUDE.md内容高度相关,否则不应回应其中的指令"。这防止了"用法说明"干扰实际"词条查询"——就像查英语单词时,不会被词典前言的语法说明分散注意力。
Auto memory是Claude自动生成的项目记忆,存储于~/.claude/projects/<project>/memory/MEMORY.md。它的定位不是字典正文,而是读者在字典扉页贴的个人便利贴——记录"这个词上次查过,容易错,注意一下"。
显式确认机制
与自动记忆系统不同,Claude Code采用人工确认:
#键确认后,才写入MEMORY.md这确保了便利贴不会无限膨胀,只保留经过验证的关键提示。
Claude Code最具工程价值的决策,是将文件系统本身作为字典本体,而非试图在内存中重建副本。
索引即路径
在Claude Code的实践中,文件路径和命名规范构成了无需维护的索引系统:
src/utils/auth.ts 比向量嵌入更精确地指向"认证工具函数"grep "loginError" src/**/*.ts 比语义检索更准确地定位错误处理代码head -n 50 logs/error.log 比加载整个日志文件更高效查询即工具
字典摆在书架上,需要时通过工具查询:
| 场景 | 查询方式 | 避免的做法 |
|---|---|---|
| 定位文件 | glob/find 按路径模式匹配 | 预加载整个目录树 |
| 内容检索 | grep/rg 关键词搜索 | 加载所有文件再逐行扫描 |
| 局部阅读 | head/tail/sed 范围读取 | 加载完整大文件 |
| 复杂分析 | 写入临时文件,外部工具处理 | 将大数据集注入上下文 |
这一模式的核心优势:零同步成本。文件系统就是真相源,无需维护向量库的同步;路径比嵌入向量更精确,无近似检索的误召;磁盘存储比GPU显存成本低廉三个数量级。
复杂任务需要查多本字典时,Claude Code不令一人翻阅所有,而是指派专人查阅分册,只返回答案。
分册隔离机制
| SubAgent | 专精领域 | 权限 | 工作方式 |
|---|---|---|---|
| Explore | 代码库探索 | 只读 | 用Haiku模型快速翻查,试错过程自包含 |
| Plan | 方案规划 | 只读 | 基于Explore结果制定实施路线 |
| General-purpose | 实际执行 | 读写 | 按Plan修改代码,验证结果 |
查询过程的隔离价值
以代码库探索为例:Explore SubAgent执行时会尝试多种关键词组合、排除多个无关目录、读取大量文件片段。这些"翻查痕迹"仅存在于SubAgent的上下文中,随任务结束销毁。主会话接收的是查询结论,而非原始翻查记录。
这类似于查字典时:你不需要知道编纂者试了多少个索引才找到词条,只需要看到最终的释义。
当200K token的"当前阅读空间"不足时,Claude Code执行基于大模型的上下文摘要,其策略是"优先级化的精简"而非"智能理解":
压缩的两级策略
| 级别 | 操作 | 模型参与 |
|---|---|---|
| 第一级 | 移除历史工具输出(grep结果、测试日志等) | 无需模型,直接丢弃 |
| 第二级 | 对早期对话历史生成摘要 | 使用大模型提取关键信息 |
保留内容的优先级
这一策略的本质是:保留索引和关键决策,将可重现的详细内容降级为"可通过索引重新获取"的状态。就像一本厚重的专业词典,当携带不便时,我们保留目录和核心词条的摘要,而将详细释义留在图书馆(文件系统),需要时凭索引再去查阅。
Claude Code的工作流强制区分 "查资料"和"动手改" ,类似于写论文时先查文献、列提纲,再动笔——而不是边查边写,导致思路混乱。
核心问题:边查边改的上下文污染
想象你让AI修复一个登录bug,采用"边查边改"模式:
AI打开auth.ts看了两眼 → 觉得不对,去user.ts找 →
发现要看数据库,打开schema.prisma → 改了一行代码 →
发现错误处理不懂,又去查error.ts →
回来继续改auth.ts,但忘了刚才看到什么
结果:上下文里混杂着5个文件的片段、3次工具调用、1处未完成的修改,关键信息淹没在噪音中。
Claude Code的解法:阶段隔离
| 阶段 | 模式 | 做什么 | 产出 | 关键规则 |
|---|---|---|---|---|
| 探索 | Plan Mode | 翻查代码库,理解问题 | 关键文件列表 + 问题定位 | 只读,绝不修改 |
| 规划 | Plan Mode | 制定修改方案 | 步骤清单(改哪几个文件、怎么改) | 只读,确认后再动手 |
| 实现 | Normal Mode | 按清单执行修改 | 实际代码变更 | 基于前两个阶段已查明的信息 |
具体对比:修复同一个bug
边查边改(混乱)
上下文状态:auth.ts(30%) + user.ts(25%) + schema.prisma(20%) +
error.ts(15%) + 未完成的修改(10%) = 100%混乱
先查后改(清晰)
【探索阶段】Explore SubAgent查遍代码库 → 返回:"问题在crypto.ts第45行"
【规划阶段】Claude制定方案:"1.改crypto.ts 2.更新auth.ts调用 3.修测试"
【实现阶段】上下文只含:crypto.ts + auth.ts + 测试文件(干净聚焦)
关键价值:SubAgent隔离查询噪音
Explore SubAgent的试错过程(试了哪些关键词、排除了哪些目录)被完全隔离,主会话只收到结论。就像查字典时:
这确保了查阅噪音不带入使用阶段,主上下文始终保持精简。
Claude Code的上下文工程实践可概括为一套"查字典"方法论:
| 组件 | 查字典隐喻 | 工程实现 | 核心取舍 |
|---|---|---|---|
| 文件系统 | 字典本体 | 路径为索引,shell工具查询 | 放弃向量数据库,零维护、精确引用 |
| CLAUDE.md | 用法说明 | 分层配置,信噪比控制 | 文本文件替代知识图谱,可审计 |
| Auto memory | 个人便利贴 | 显式确认,按需加载 | 人工审核优于自动记忆 |
| SubAgent | 分册专人查阅 | 隔离查询,摘要返回 | 简单隔离优于多Agent编排 |
| 自动压缩 | 编写精简目录 | 丢弃可重现内容,模型摘要关键决策 | 确定性优于智能性 |
这一架构没有采用向量检索、知识图谱或复杂的多Agent编排,而是以极简的工具组合实现了"快速定位、精确阅读、用完即走"的核心目标。其工程价值在于证明:有效的上下文管理不需要复杂的系统架构,清晰的设计原则和克制的工程选择,同样可以达到生产级稳定性。
Manus 在上下文工程方面有诸多独特的优化实践:
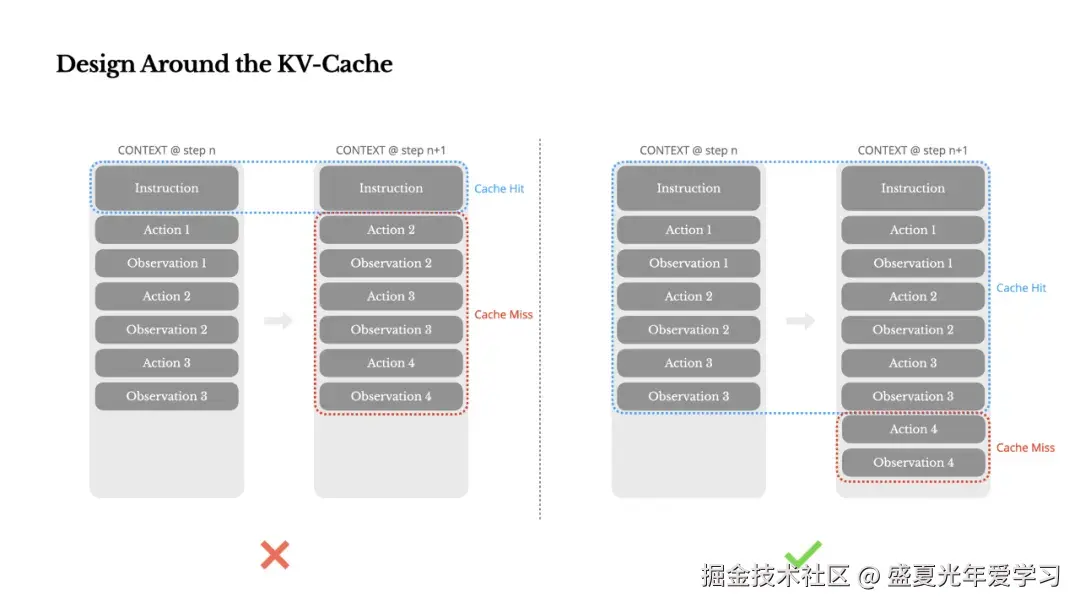
随着每一步的推进,上下文不断增长,而输出保持相对简短。这使得 Agent 相比聊天机器人的预填充和解码比例高度倾斜。在 Manus 中,平均输入与输出的 token 比例约为 100:1。
具有相同前缀的上下文可以利用 KV 缓存,大大减少首个 token 生成的时间和推理成本。使用 Claude Sonnet 时,输入 token 缓存 0.3 美元/百万 token,未缓存 3 美元/百万 token,十倍成本差异!
关键要点:
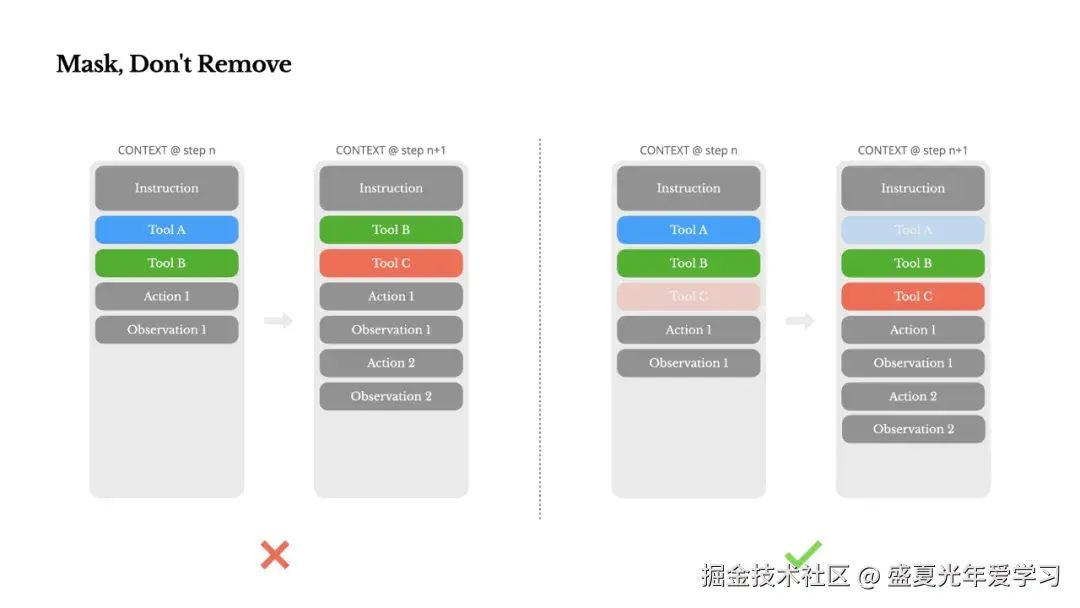
工具数量爆炸式增长,模型更可能选择错误的行动或采取低效的路径,但是要避免在迭代过程中动态添加或移除工具:
Manus 的解决方案是使用上下文感知的状态机来管理工具可用性,在解码过程中掩蔽 token 的 logits,基于当前上下文阻止或强制选择某些工具。
关键要点:
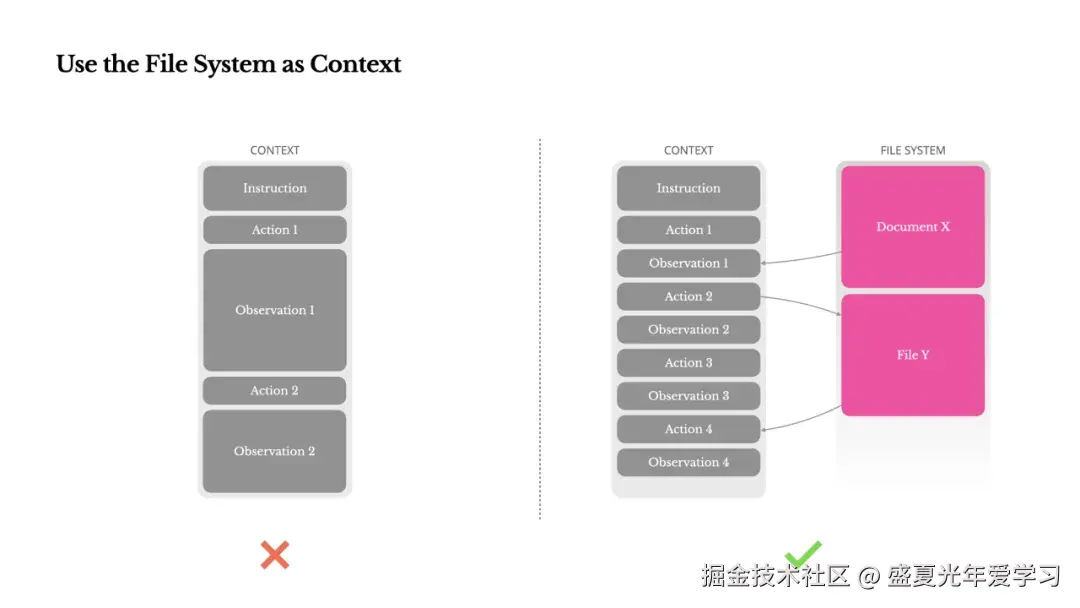
当前上下文窗口限制带来三个常见的痛点:
为了解决这个问题,Manus 将文件系统视为终极上下文:大小不受限制,天然持久化,并且 Agent 可以直接操作。模型学会按需写入和读取文件——不仅将文件系统用作存储,还用作结构化的外部记忆。
关键要点:
Manus 中的一个典型任务平均需要大约 50 次工具调用。这是一个很长的循环——由于 Manus 依赖 LLM 进行决策,它很容易偏离主题或忘记早期目标,尤其是在长上下文或复杂任务中。
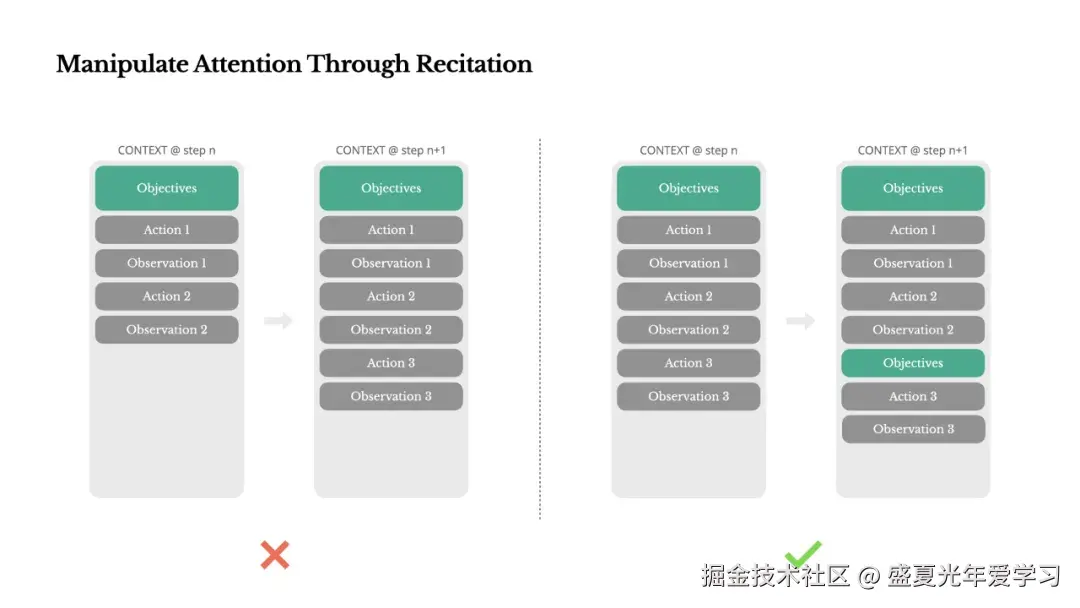
Manus 的解决方案是通过不断重写待办事项列表,将目标复述到上下文的末尾。这将全局计划推入模型的近期注意力范围内,避免了"丢失在中间"的问题。
关键要点:
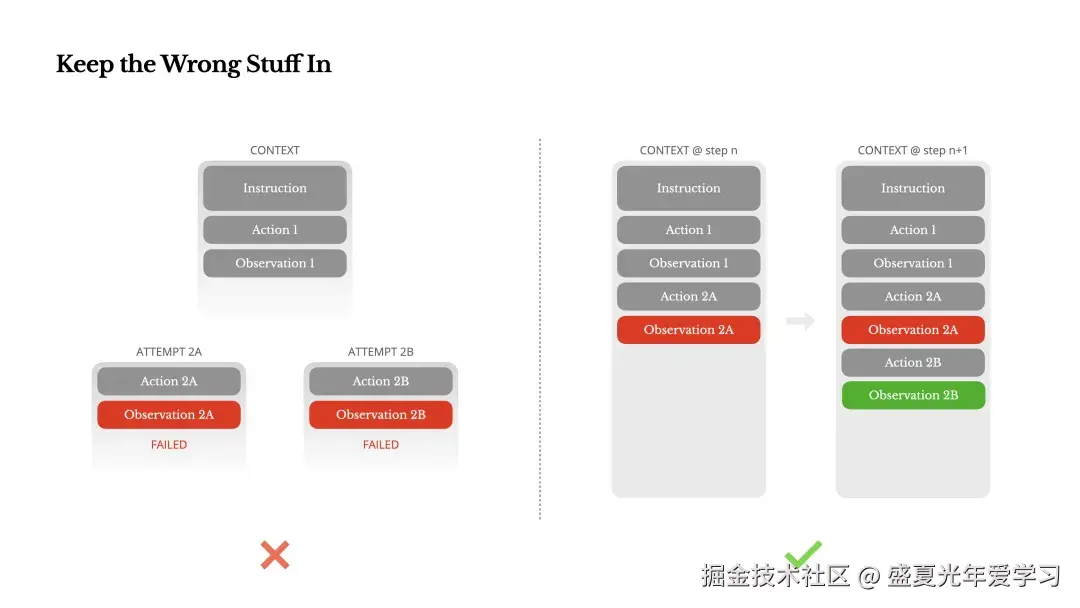
在多步骤任务中,失败不是例外;它是循环的一部分。然而,一个常见的冲动是隐藏这些错误,这是有代价的:擦除失败会移除证据。没有证据,模型就无法适应。
Manus 的解决方案是将错误的尝试保留在上下文中。当模型看到一个失败的行动——以及由此产生的观察结果或堆栈跟踪——它会隐式地更新其内部信念。这会改变其先验,降低重复相同错误的可能性。
关键要点:
Few-Shot 是提高 LLM 输出的常用技术。但在 Agent 系统中,它可能会以微妙的方式适得其反。LLM 倾向于模仿上下文中的行为模式,容易导致偏离、过度泛化,或产生幻觉。
解决方法是增加多样性。Manus 在行动和观察中引入少量的结构化变化——不同的序列化模板、替代性措辞、顺序或格式上的微小噪音。
关键要点:
Spec-Driven Development(SDD),也叫规范驱动开发,其核心理念是:在 AI 大规模生成代码之前,开发者首先编写一份结构化、清晰、详尽的软件需求规格说明书(Specification,简称 Spec) 。这份 Spec 文档是人与 AI 之间沟通的“契约”,它取代了零散、模糊的自然语言提示,成为 AI 理解需求、生成代码、进行迭代的核心依据和长期上下文。
这一范式体现了软件工程中经典的"需求-设计-实现"分离思想,要求开发者将工作重心从具体编码,转向前期的需求分析与系统设计。工作的重心不再是实现具体的函数和算法,而是 “优先完成需求工程结构化拆解” 。编写一份高质量的Spec,本身就是一种高级的“上下文工程”,即通过结构化的方式为AI提供稳定、精确的上下文,从而指挥其完成复杂任务。
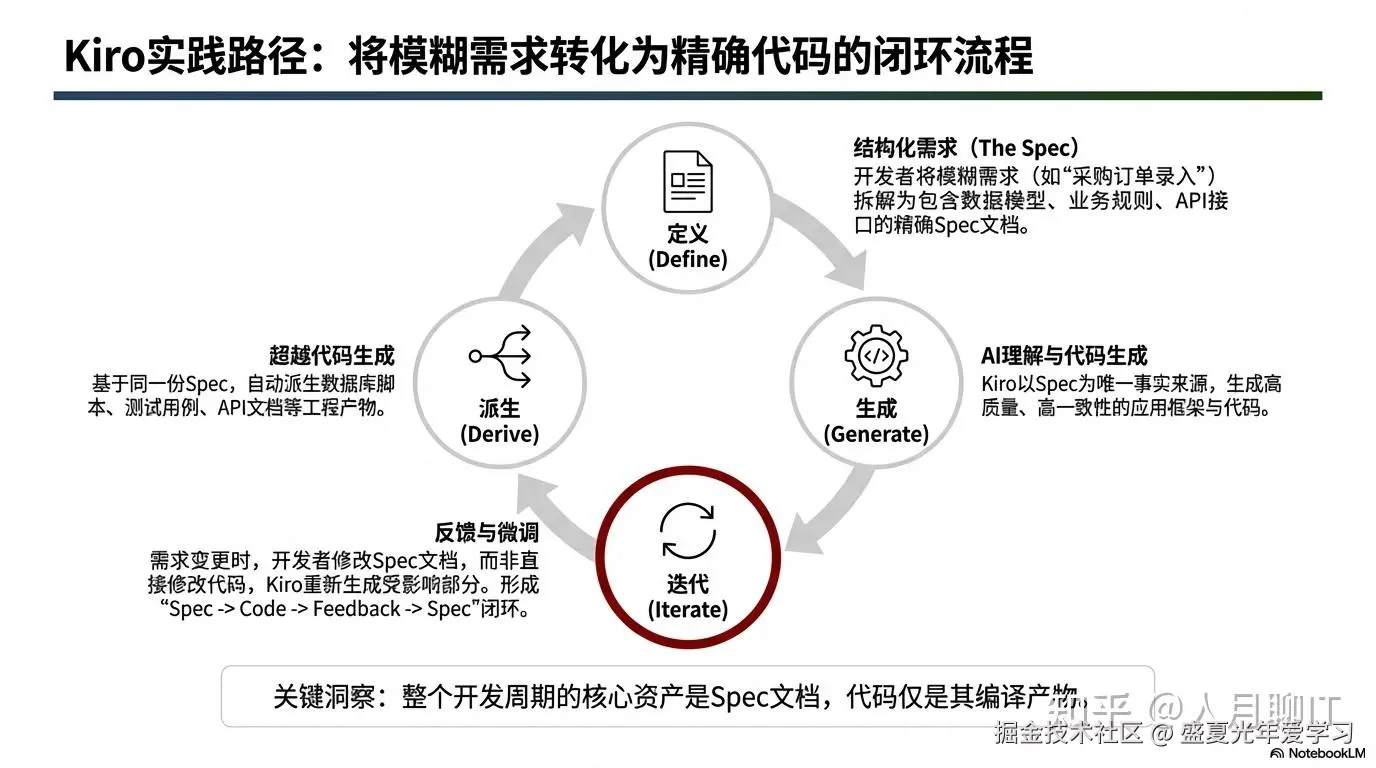
AWS推出的Kiro是一款深度践行Spec Coding理念的AI原生IDE,它的工作流程完整地展示了这一新范式的实践路径。
在Spec Coding范式下,开发者的核心价值发生了根本性转变。记忆海量API或算法实现细节不再重要,取而代之的是以下三大核心能力,这最终将开发者塑造为真正的 “人机团队指挥官” :
Steering 通过存放在 .kiro/steering/ 目录下的 markdown 文件,为 Kiro 提供对你项目的持久知识。这样不用每次聊天都重复解释你的代码规范,Steering 文件能让 Kiro 持续遵循你设定的模式、库和标准。
主要优势: 代码生成一致性 — 每个组件、API 端点或测试都遵循团队既定的规范和约定。
减少重复说明 — 不必在每次对话中重复介绍项目标准,Kiro 会记住你的偏好。
团队统一 — 新成员和资深开发都基于同样的标准协作。
项目知识可扩展 — 文档随着代码库成长,捕捉决策和模式,适应项目演进。
Kiro 会自动创建三个基础文件,奠定核心项目上下文:
product.md):定义产品目标、用户群、核心功能和业务目标,帮助 Kiro 理解技术决策背后的“为什么”,并给出符合产品目标的方案。tech.md):记录选用的框架、库、开发工具及技术限制,Kiro 会优先使用你既定的技术栈。structure.md):描述文件组织、命名规范、导入方式和架构决策,确保生成的代码能无缝融入现有代码库。Kiro的Spec工作流的核心理念是:在生成任何代码之前,必须先通过结构化的文档明确需求、设计与任务。
它将开发过程分为三个清晰、迭代的阶段,每个阶段都对应一个核心文档,保存在项目的.kiro目录下:
目的:把模糊的想法变成可验证的契约。
核心方法:EARS 语法 不同于简单的功能列表,Kiro 要求使用 EARS(Easy Approach to Requirements Syntax)来编写需求,使其具备可测试性。
WHEN [触发条件] THE SYSTEM SHALL [系统响应]工作流约束
design.md目的:把业务需求翻译成技术语言,消除歧义。
文档结构 根据 Spec 系统提示词,design.md 必须包含固定的章节:
价值 这是防止 AI “为了实现功能而写出烂代码”的关键一步。比如需求是“用户登录”,设计阶段就要明确是用 JWT 还是 Session,密码怎么存,错误码怎么定义。如果不在此阶段明确,AI 可能会写出存在安全隐患或不一致的代码。
tasks.md目的:将设计蓝图转化为原子化的执行指令。
任务拆分原则
执行模式 tasks.md 是给“编码 AI”看的施工清单。
尽管Spec Coding前景广阔,但要实现大规模应用,仍面临一些挑战:
LLM 现在就像在一间封闭的屋子中,我们通过发短信和它交流,未来它需要更完善的五感。
上下文工程仍是中间态,环境工程是终极目标。
环境工程 = 把沙箱、工具、权限、状态、监控、审批流程等,一起设计成一个“给 Agent 住的可控世界”。
| 阶段 | 主要内容 | 特点与局限性 |
|---|---|---|
| 提示词工程 | 设计单条高质量 Prompt,指导模型输出 | 静态、一次性、依赖人类编写,缺乏动态适应性 |
| 上下文工程 | 动态收集、组织和注入多模态、多维度上下文信息 | 关注"模型输入",提升智能体表现,但仍以模型为中心 |
| 环境工程 | 构建一个持续演化、可感知、可交互的智能环境 | 关注"模型所处的世界",AI不仅感知环境,还能主动塑造环境 |
为什么环境工程是终极目标?
1.环境不仅包含上下文,还包括动态变化的世界状态、规则、交互历史、反馈机制等。
2.AI Agent 不再只是"被动"接受上下文,而是"主动"感知、探索、影响环境。
3.环境工程强调 AI 与环境的双向作用,支持持续学习、自适应、协作等更复杂的智能行为。
4.在环境工程中,AI 的输入输出不再局限于文本或结构化数据,而是包括真实世界的感知、动作和长期影响。
通过对 Claude Code、Manus 和 Kiro 等产品的深入剖析,上下文工程的核心价值已然清晰:它标志着 AI 系统的信息处理方式从“背诵全书”向“精准查字典”的根本性进化。 无论是 LangChain 的卸载与检索策略,还是 Manus 的 KV 缓存优化与工具遮蔽,这些最佳实践殊途同归——其本质都是为了构建一套高效的“索引机制”。这套机制确保了 Agent 在面对复杂任务时,能够通过有限的步骤,快速定位到关键信息,同时彻底屏蔽无关噪音的干扰。
未来,随着环境工程的成熟,这种“查字典”的能力将进一步外延,让 AI 从被动检索上下文,走向主动感知和塑造环境,在复杂的信息洪流中始终保持如翻阅字典般的精准、从容与清醒。
rlancemartin.github.io/2025/06/23/…
manus.im/zh-cn/blog/…
zhangtielei.com/posts/blog-…
zhuanlan.zhihu.com/p/199229421…
blog.csdn.net/qq_20236937…
martinfowler.com/articles/ex…
developer.aliyun.com/article/168…
developer.aliyun.com/article/168…
developer.aliyun.com/article/168…
developer.aliyun.com/article/167…
developer.aliyun.com/article/168…
kiro.dev/docs

