




爱回收
75.46M · 2026-04-05

各位小伙伴新年好!新的一年祝大家龙马精神、阖家幸福、身体健康、事业进步!2025 年 DeepSeek 发布的 DeepSeek-R1 模型震惊全球,此后国内各大厂商充分发挥“能征善战”的拼劲,纷纷选择重大节日推出新品。今年除夕夜,阿里 Qwen 团队再次放出大招——Qwen3.5 模型正式开源,为国产大模型阵营再添一员猛将。
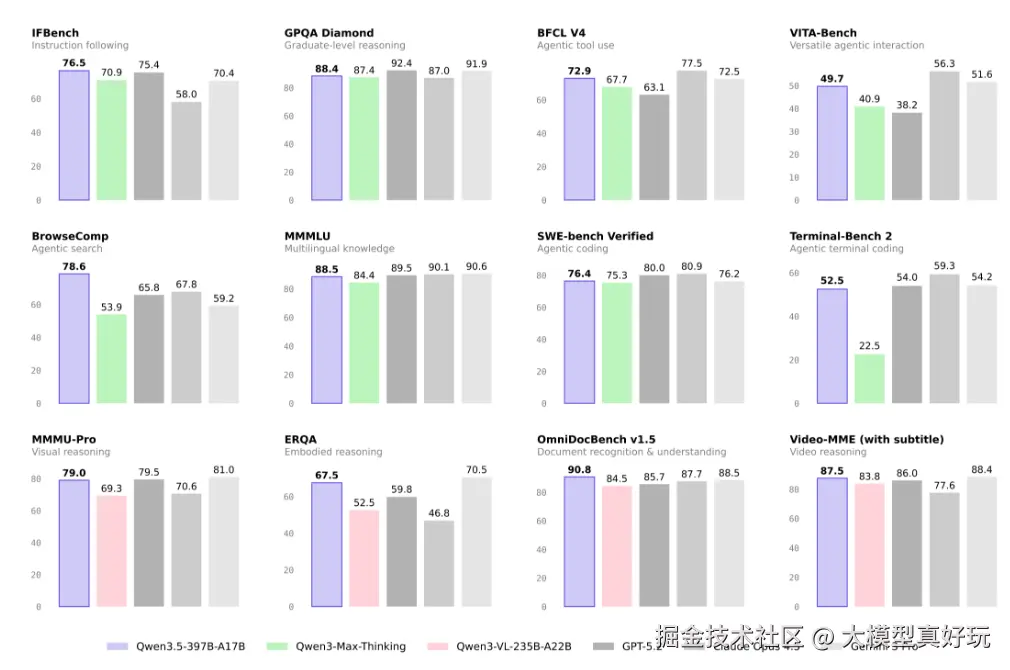
Qwen3.5 是目前全球最强的原生多模态开源大模型,不仅支持图片和视频的多模态输入,在对话、推理、编程、Agent 构建等方面也样样精通。其综合能力已达到 GPT-5.2、Gemini 3.0 Pro 的平均水平,推理能力尤为突出。例如那道曾让无数模型“翻车”的逻辑题——“50 米距离该走路还是开车去洗车”,Qwen3.5 也能轻松作答。
在 Vibe Coding 方面,凭借国内最强开源多模态模型的实力,Qwen3.5 可借助 Remotion Skills 一键生成视频;在 Agentic Coding 方面,其强悍的 Agent 性能即使用户使用最简略的需求描述,它也能自动调用各类工具,完成复杂应用开发。视觉推理能力相较 Qwen3-VL 大幅提升,连“鲨鱼骑马 = 沙琪玛”这种梗图都能精准识别。
更令人惊艳的是,Qwen3.5 能够将视觉与代码能力结合,一步到位将视频内容“转译”为一个可交互的网页。可以说,Qwen3.5 的发布不仅填补了国内多模态开源大模型的空白,也为未来多模态 Agent 的开发奠定了坚实基础。本文笔者将对 Qwen3.5 的核心特性和性能进行详细解读,带大家一探究竟!
Qwen3.5 在预训练阶段从三个维度进行了深度优化:
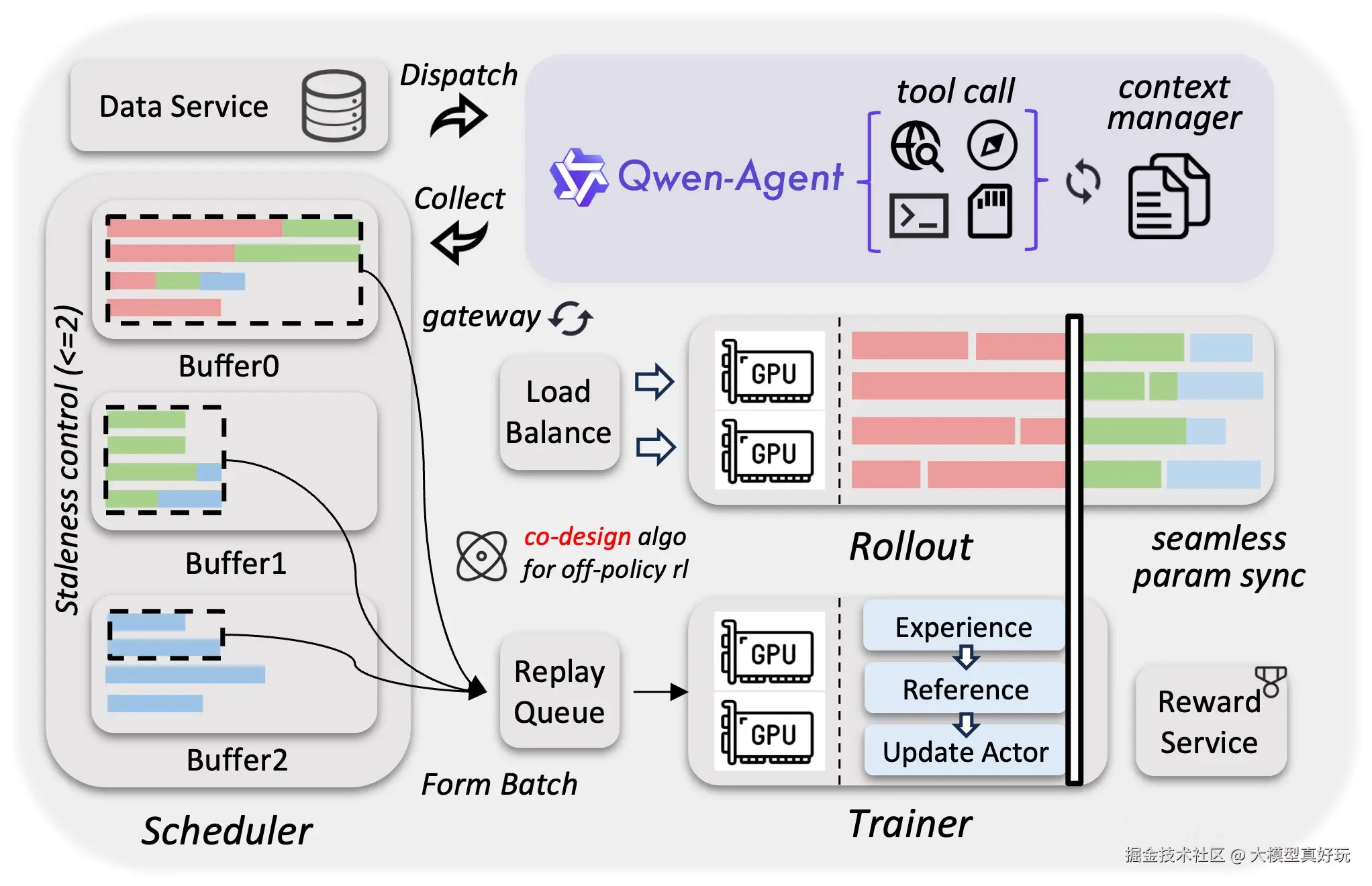
Qwen3.5 通过异构基础设施设计,实现了高效的原生多模态训练:
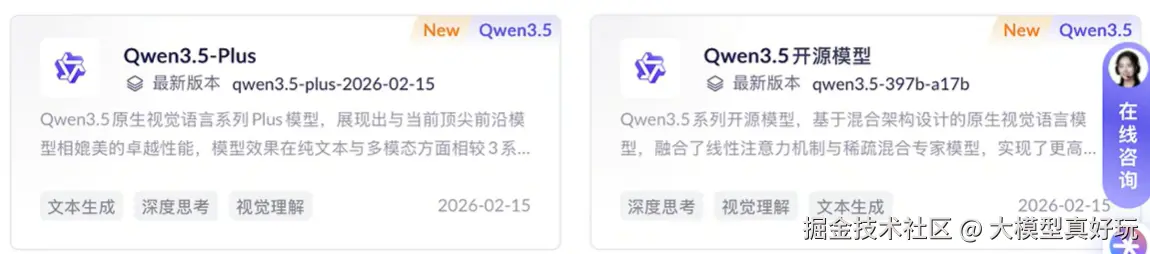
除夕夜开源的 Qwen3.5-397B-A17B 是 Qwen3.5 系列的首款模型。未来,Qwen3.5 还将陆续开源一系列小尺寸模型,同时保留 Qwen3.5-Max 的商业旗舰地位(该模型不会开源)。
参数规模:模型拥有近 4000 亿总参数,采用极致稀疏 MoE 架构,每次推理仅激活 170 亿参数,大幅降低计算开销。
技术创新:引入注意力门控机制(该技术获 2025 年 NeurIPS 最佳论文奖),实现了降本增效。与上一代商业旗舰 Qwen3-Max-Thinking(近 1T 参数)相比,Qwen3.5-397B-A17B 在性能超越的同时,部署显存占用降低 60%,最大推理吞吐量提升至原来的 19 倍。
硬件需求:尽管极致稀疏,但完整运行仍需至少 8 卡 A100(80G)集群;不过 17B 的激活参数使得实际推理效率极高。
<no_thinking> 前缀取消推理,只能通过修改内置提示词模板(通常位于 tokenizer_config.json 中)切换至 Chat 模式(内置提示词模板通常在大模型tokenizer_config.json文件中, 大家不熟悉的可以看笔者文章大模型训练全流程实战指南基础篇(二)——大模型文件结构解读与原理解析)。模型下载:Qwen3.5-397B-A17B 已全面开源,可在魔搭社区(ModelScope)或 Hugging Face 下载模型权重。
API 服务:阿里百炼平台同步上线了模型 API,注意区分两个版本:
定价:API 定价极低,输入百万 tokens 仅 0.8 元,输出百万 tokens 仅 4.8 元,性价比是同性能 Gemini 3.0 Pro 的 1/18,真正“拉满”性价比。
Qwen3.5-397B-A17B 的发布,为 2026 年春节的国产大模型赛道打响了头炮。与此同时,万众期待的 DeepSeek-V4 也即将来袭,这个春节可谓“神仙打架”。正是这些公司雄厚的技术积淀,撑起了我国大模型在世界舞台上的领先地位。为国产大模型公司点赞,也祝愿新的一年里,我国大模型产业继续马到成功!
大模型时代的到来注定是颠覆世界的第四次工业革命,也希望大家可以紧跟AI时代的潮流,把握AI时代的风口。2026注定是大模型接续爆发的一年!为了让大家彻底搞懂大模型的作用原理,笔者也发布了《数据到模型到应用:大模型训练全流程实战指南》专栏,预计会有50期内容,将系统拆解从数据处理、模型训练到强化学习与智能体开发的全流程,并带大家从零实现模型,帮助大家掌握大模型训练的全技能,真正掌握塑造智能的能力!感兴趣大家可关注笔者掘金账号,更可关注笔者同名微信公众号:大模型真好玩,更多教程和大量大模型学习资料分享~
需要注意的是:大模型训练对计算资源有一定要求,尤其是GPU显存。为降低学习门槛,笔者与国内主流云平台合作,大家可以通过打开链接: Lab4AI ,体验H100 GPU 6.5小时的算力。本系列所有实战教程均将在该平台上完成,帮助大家低成本上手实践。

