
爱回收
75.46M · 2026-04-05

最近,一篇名为 《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》 的论文提出了一个很有意思的观点:自生成的 Agnet Skills 毫无用处。
这篇论文(arXiv:2602.12670,SkillsBench)在一个专门为「技能是否真的有用」设计的基准上,得到了一个系统性结论:让模型自己写一套“技能/流程指南”,平均并不能提高成功率,甚至略微下降。
首先我们要明确一个基础点,那么就是 Agent Skill 是什么?这里他们把 Agent Skill 定义成一种结构化的“程序性知识包” ,用于在推理/执行时增强 Agent:
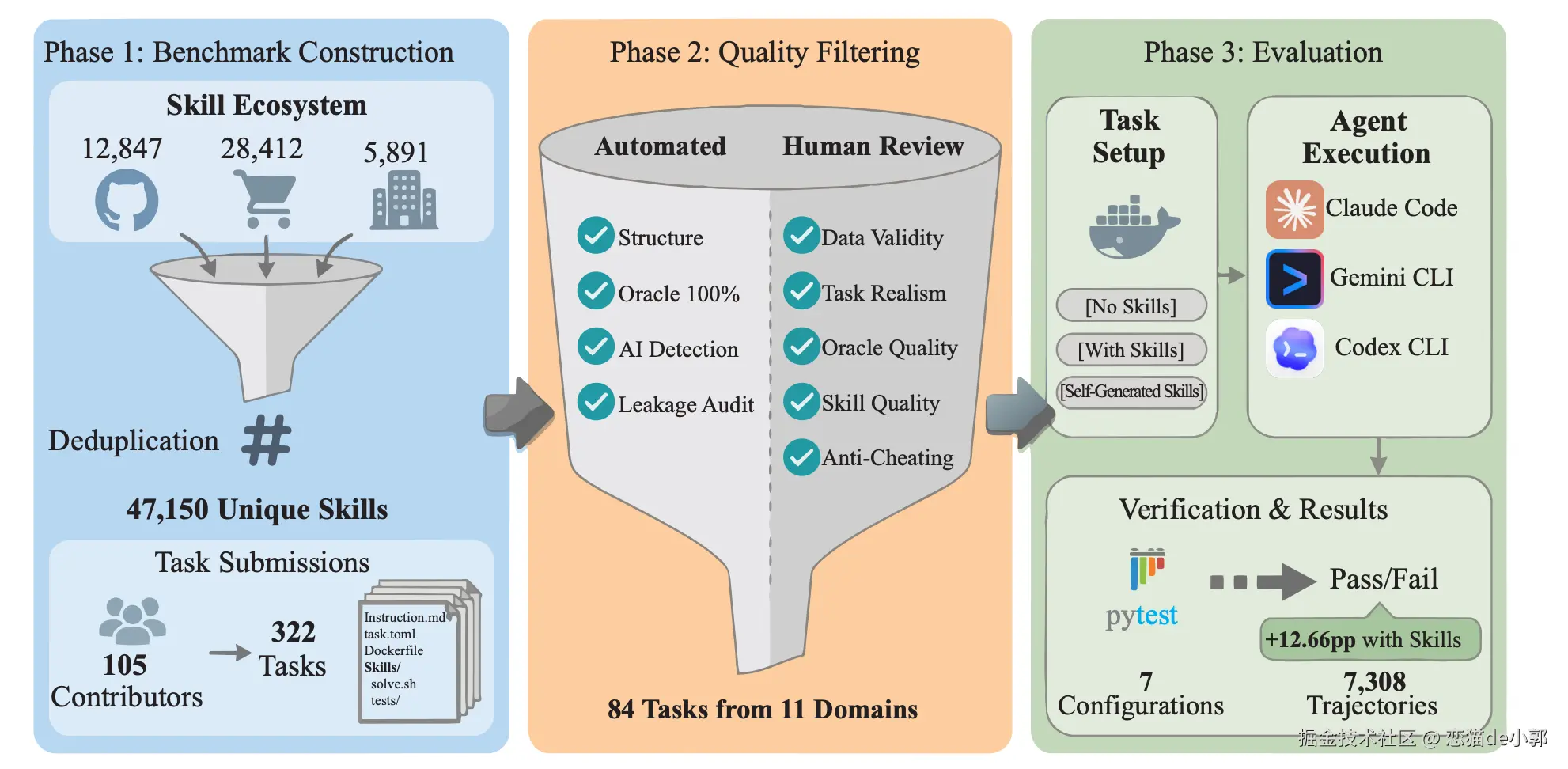
同时论文也明确区分:Skill 不等于普通系统提示词、不等于 few-shot、不等于 RAG 检索、不等于纯工具文档,Skill 更强调可复用的工作流/SOP + 结构化资源,而针对测试场景,论文也区分了 Curated Skills 和 Self-generated Skills:
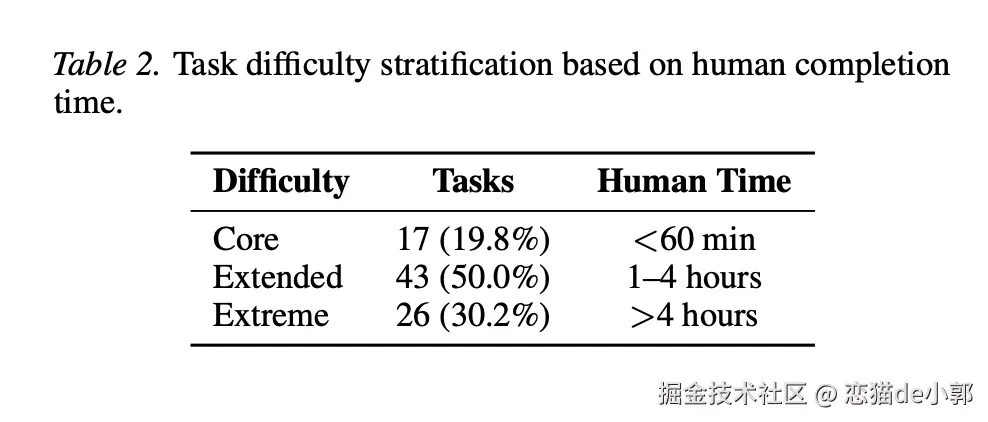
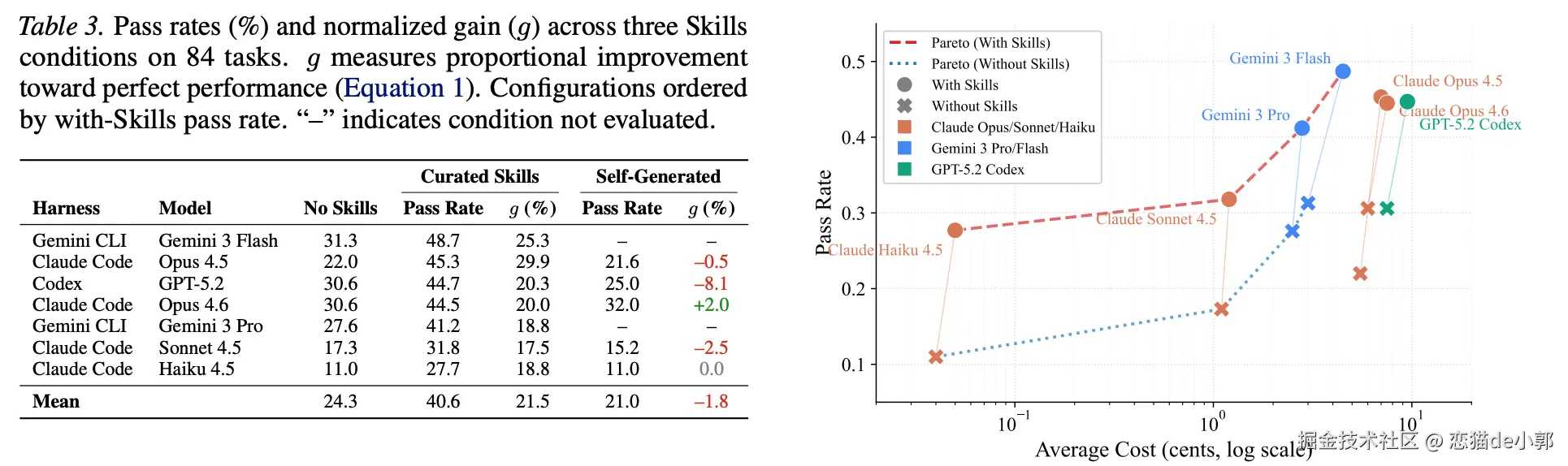
而 SkillsBench 这个 benchmark 做了一个基准:84 个任务、11 个领域,每个任务都有确定性验证场景(跑脚本/单测,给出 pass/fail),并且同一个任务在三种条件下对比:
instruction.md,环境里没有 skills整个 Benchmark 它分成三大阶段:Benchmark Construction 、 Quality Filtering、 Evaluation。
其中 Benchmark Construction 的核心是 Skill 生态收集 ,包括:
总计汇聚后,通过去重得到 47,150 unique skills,有 322 位贡献者提交 105 个候选任务
而 Quality Filtering 是把 105 个候选任务筛成最终基准任务,包括:
自动化检查
人工审查
最终产出:84 个任务,覆盖 11 个领域 。
在 Evaluation 阶段的同一批任务,会在三种场景下运行,同时用三套商业 harness 执行(Claude Code / Gemini CLI / Codex CLI),结果用 pytest 等确定性验证器给出 Pass/Fail :
而对于任务,是用人类完成时间作为难度来变为:
所以从整个配置可以看出来:
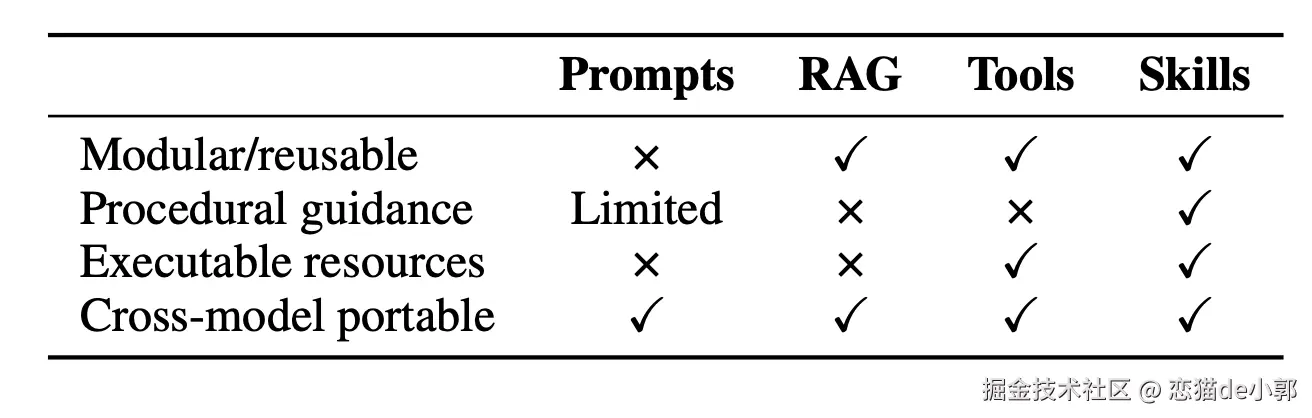
所以整个论文测试,不是只测「加一点上下文有没有用」,而是测「真实世界里那种 skill 」到底能不能稳定带来收益,根据测试结果:
另外论文作者也总结了,对比 no-Skills :
论文把 Self-generated Skills 失败总结为:模型不能可靠地“写出”自己在执行时真正会受益的程序性知识,因此“自生成”平均没有收益,这也是可以理解,目前的 AI 存在概率支持,效果和产出都看它当时的“心情”,论文把 self-generated 失败归因到一个很现实的点:
说人话就是:模型「会做」但「不会写出可复用的程序性知识」,更具体,论文通过轨迹分析提了两个典型失败模式:
总结起来就是: self-gen 往往生成的是“看起来像指南的废话”,或者压根没抓住应该写什么。
到这里,可能有人会好奇,为什么会有 self-generated 这种用法?什么场景会有人让 AI 自己写 Skills ?实际上这种场景还很多,现在很多 Skills 就是懒人直接让 AI 写的,而更典型的代表,是 Claudeception 这种:
所以 Claudeception 的使用场景就无比贴合这个 SkillsBench ,也就是让 AI 长时间维护和迭代 Skill 是否可靠?目前这篇论文给出的结论是:并不可靠。
而对于专业人士写出来的 Curated Skills,通常包括:
特别是 Curated Skills 包含有领域特定知识,比如在 failure analysis 里作者就说过 Self-generated 常见问题是:
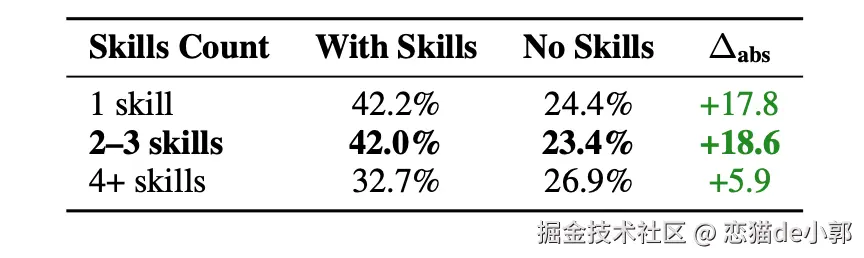
另外,除了“self-gen 不行”,论文还做了技能设计因素分析:
技能数量 2–3 个模块最好,太多反而拖累,按任务提供的 skill 数量分组 2–3 skills 的提升最大(+18.6pp) ,4 个以上提升很小,甚至可能带来认知负担/冲突
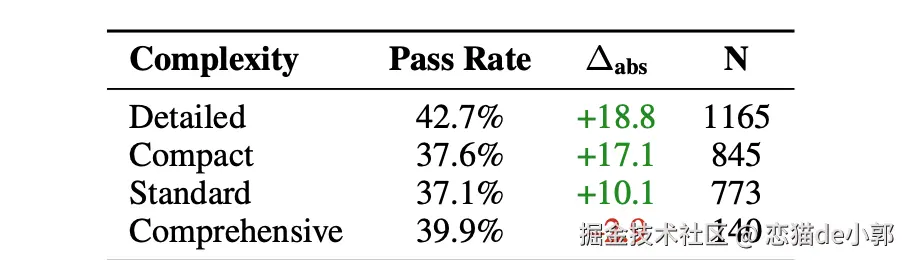
技能“文档复杂度”上,聚焦型胜过“大全型” ,论文把把 Skills 文档分成 detailed/compact/standard/comprehensive,结果是:
所以技能不是越长越好,而是要把 agent 下一步要做什么写清楚(含检查点、命令模板、失败回滚),否则就是噪声。
所以,通过这篇论文可以总结,Agnet Skills 不是几句简单的提示词,系统的的技能包确实能增强 Agent,但是目前 AI 自己维护的 Self-generated Skills 几乎没用,甚至还会拉低效果 ,关键原因是模型很难稳定写出真正可执行、降低搜索空间的程序性知识,同时技能设计比数量也狠重要,技能不是越多越好,也不是越详细越好。
总的来就是,高质量技能 = 搜索空间压缩器,它可以限定决策路径、减少无效探索、提供验证锚点和显式化领域隐性流程,这才是 Skills 能推高 Pareto frontier 的原因,所以,你需要避免百科式技能,它可能带来的更多的噪音。
所以,如果你发现 Skill 用多了,Agent 反而傻了,不要怀疑,是你的 Skill 给你的 Agent 掺了屎。

