
爱回收
75.46M · 2026-04-05

除夕夜,老金我刚咬了一口韭菜鸡蛋饺子。 手机"叮"的一声,弹出个通知。 老金我瞄了一眼——Qwen3.5,上线了。饺子差点没喷出来。
赶紧打开 ch@t.qwen.ai,两个模型直接挂在上面,可以用了。 阿里这帮人,大年三十放大招,连个发布会都没开,就这么安安静静地把东西甩出来了。
老金我放下筷子,扒了一晚上代码和文档,确认了一件事: 这不是小版本迭代,这是架构级别的重构。
根据老金我除夕夜扒的HuggingFace代码库、阿里云官网和ch@t.qwen.ai的实际体验,帮你梳理了3个核心变化。
第一个:原生多模态。 注意,是"原生",不是"拼接"。 Qwen3之前的多模态方案是语言模型+视觉模块的两段式架构。 Qwen3.5直接把视觉感知和语言推理塞进了同一个训练框架。
阿里云官网对Qwen3.5-Plus的描述是:"原生多模态合一训练,混合架构双创新突破。" 简单说,以前是两个人配合干活,现在是一个人同时搞定。
第二个:Gated Delta Networks——线性注意力机制。 官方确认,Qwen3.5采用了一种叫 Gated Delta Networks 的线性注意力,跟传统的Gated Attention做了混合架构。 传统Transformer的注意力计算量跟序列长度的平方成正比,Gated Delta Networks把这个关系拉成线性。
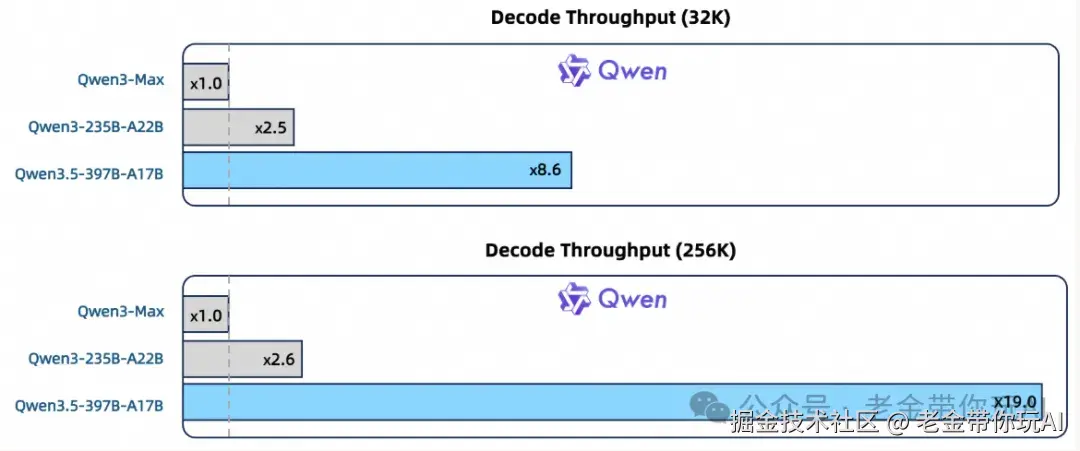
翻译成人话:处理长文本的速度快了,显存占用也降了。 而且不是快了一点半点——官方实测数据:
老金我看到这个数据的时候饺子真喷出来了。
第三个:更大的模型家族。 目前在ch@t.qwen.ai上已经可以直接使用的有两个版本:
跟之前HuggingFace代码里泄露的9B和35B-A3B相比,正式发布的模型规模大得多。 3970亿总参数,比Qwen3的旗舰235B-A22B直接翻了快一倍。
总参数量达3970亿,每次前向传播仅激活170亿参数,在保持能力的同时优化速度与成本。
语言与方言支持从119种扩展至201种,词表从15万扩大到25万,在多数语言上带来约10-60%的编码/解码效率提升。 简单说,同样的一段话,Qwen3.5能用更少的token表示,推理更快,API费用也更省。
这块稍微展开说一下,因为这可能是Qwen3.5最关键的技术突破。 不懂技术的朋友别跳过,老金我用人话给你翻译。
传统Transformer用的是标准自注意力机制。 简单理解:AI在读一篇文章的时候,每读到一个字,都要回头看一遍前面所有的字。
如果文章有1万个字,每个字要跟其他9999个字各看一次。 字数越多,AI就越吃力——计算量是"字数的平方"级别的。
Qwen3.5用的Gated Delta Networks,核心思路是:用一个巧妙的数学方法,让AI不用每次都回头看所有内容。 结果就是:计算量从"字数的平方"降到"字数的倍数"。
听起来差别不大?我给你举个具体例子:
处理一个10分钟的视频:
这不是快了几个百分点的问题,是能不能跑起来的问题。 很多任务以前根本跑不动,现在可以了。
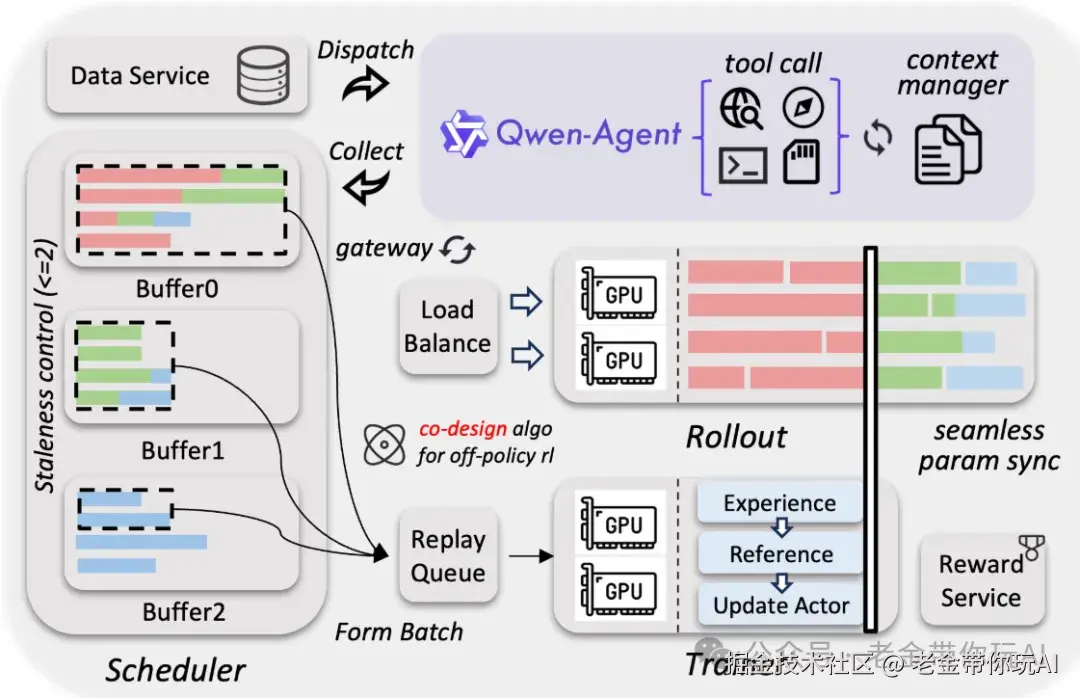
Qwen3.5更聪明的地方在于:它把Gated Delta Networks(线性注意力)和Gated Attention(标准注意力)做成了 混合架构。 简单任务用线性注意力省资源,复杂任务自动切换到标准注意力保精度。 不是非此即彼,而是动态选择——什么场景用什么方案。
这也是为什么官方说的"Qwen3-Next架构"——更高稀疏度的MoE + 混合注意力 + 多token预测。
多token预测是什么意思? 传统模型一次只能"想"出一个字,Qwen3.5一次能预测多个字,生成速度又快了一截。
之前的多模态模型大多是"拼接式"的。 打个比方:就像找了一个英语翻译和一个法语翻译,中间再安排一个协调员把两人的翻译对接起来。
先训一个语言模型(处理文字),再训一个视觉编码器(处理图片),最后用对齐层把两者连起来。 这种方式有个天然缺陷:视觉和语言的理解是割裂的。
Qwen3.5走的是另一条路——从预训练阶段就把文本、图像、视频放在一起训。 模型从一开始就"看"和"读"同时进行。 就像培养一个从小就双语环境长大的孩子,不需要翻译,直接理解。
阿里官方说法是"统一架构整合语言推理与视觉感知"。
这对普通用户来说意味着什么? 1、你发一张图给AI,它能真正"看懂"图里的内容,不容易出现"看到了但理解错了"的情况 2、一次对话就能同时处理图片+文字,不用分两步操作 3、成本更低——一个模型干两个模型的活,API费用直接砍半
阿里官网已经写了"效果、成本与多模态理解深度上同时超越Qwen3-Max与Qwen3-VL"。 如果这个说法成立,那Qwen3.5-Plus可能是目前性价比最高的多模态模型之一。
比如这样提问,它都能准确且快速的回答:
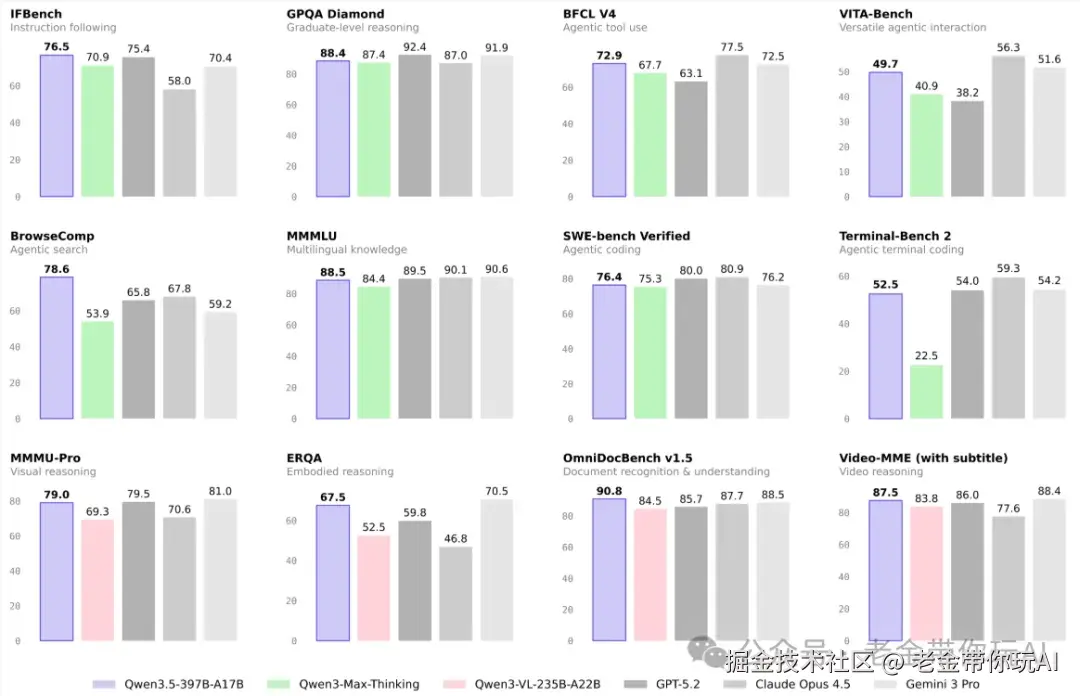
说技术架构大家可能没直觉,直接看跑分数据。 官方放了一大堆benchmark对比,老金我帮你提炼最关键的几个:
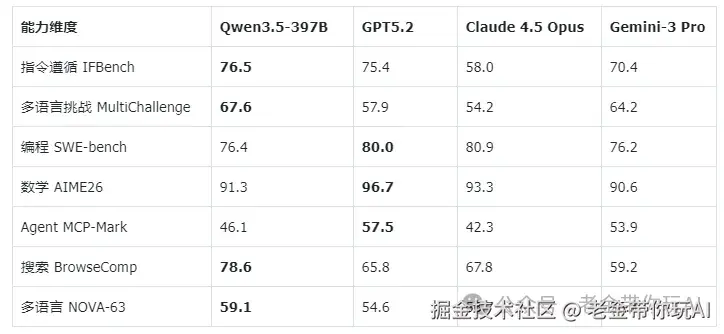
自然语言能力(对比GPT5.2、Claude 4.5 Opus、Gemini-3 Pro):
几个重点:
1、指令遵循(IFBench 76.5)和多语言挑战(MultiChallenge 67.6)两项全场第一。 这意味着你给它的指令它听得更准,不容易跑偏。
2、搜索Agent能力(BrowseComp 78.6)也是第一。 联网搜索信息的能力很强。
3、多语言能力(NOVA-63 59.1)第一。 201种语言不是白支持的。
4、编程和数学还是GPT5.2和Claude强一些,但差距不大。
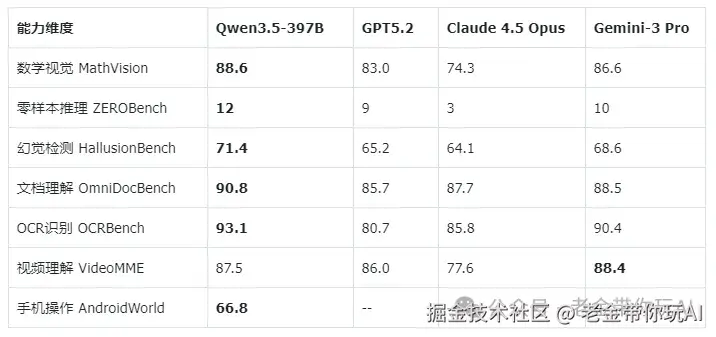
视觉语言能力(这才是Qwen3.5的杀手锏):
乖乖,视觉能力这块Qwen3.5真的杀疯了:
注意,这是一个3970亿参数只激活170亿的模型跑出来的成绩。 跟GPT5.2这种完整版闭源大模型对打还能在多个维度赢,开源模型能做到这个水平,老金我服了。
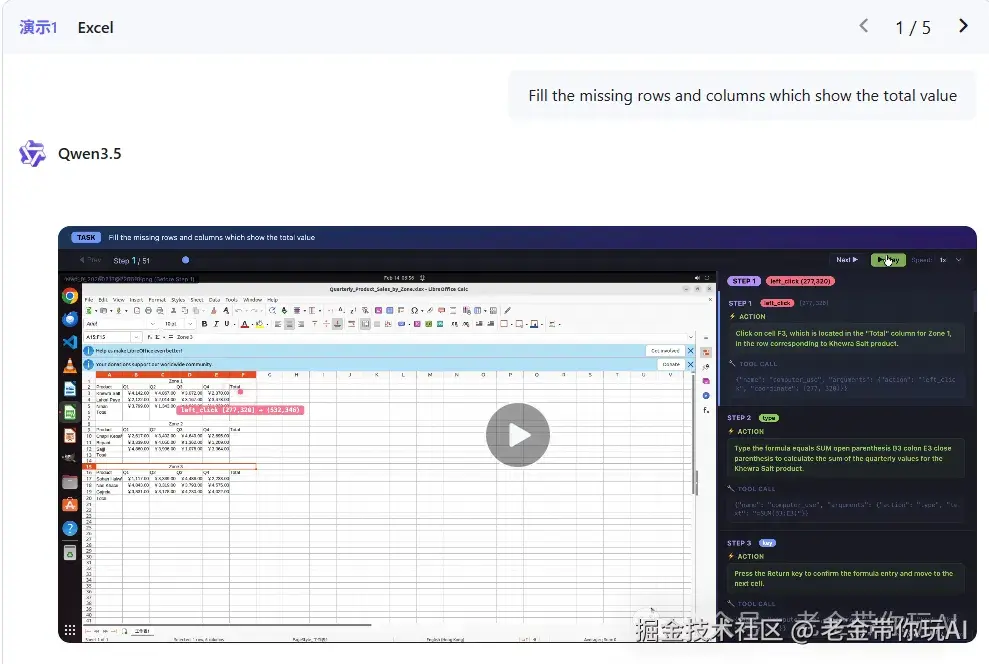
这是老金我觉得最炸裂的功能,但很多报道都没重点说。 Qwen3.5可以作为 视觉智能体,自主操作手机和电脑完成日常任务。
什么意思?你告诉它"帮我把这个Excel表格的缺失行补全",它真的能: 1、打开Excel文件 2、识别出哪些行和列需要补全 3、自动填写数据 4、保存文件
全程不需要你动手,AI自己操作界面完成。 官方展示了好几个演示:
AndroidWorld跑分66.8,目前公开数据里最高的。 这不是ChatGPT那种"帮你写个脚本自己跑"。 Qwen3.5是真的在操作GUI界面,像人一样点击、输入、滑动。
对于不会编程的普通用户来说,这个能力可能比会写代码更有用。
除了操作手机电脑,Qwen3.5在"看"这件事上还有两个特别的能力。
空间智能: 借助对图像像素级位置信息的建模,Qwen3.5能做到:
官方展示了一个驾驶场景的例子:给它一段行车记录仪视频截帧,它能分析出"信号灯在我接近停车线时变黄,此时距离太近无法安全停车,所以选择通过路口"。 这个能力在自动驾驶和机器人导航场景里非常关键。
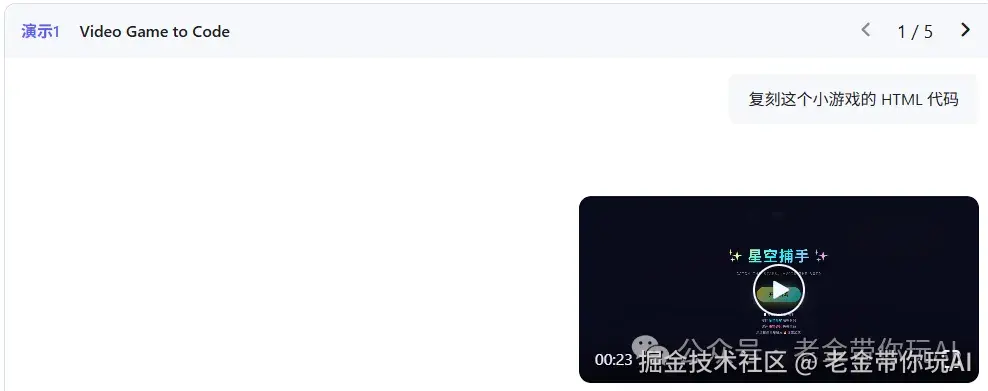
视觉编程: 更酷的是,Qwen3.5能把看到的东西变成代码:
你甚至可以让他看视频手搓游戏。
如果对你有帮助,记得关注一波~
Qwen3.5选在除夕夜发布,这个时间点太狠了。 这个春节档,至少还有3个重磅选手要登场。
1、DeepSeek V4——最受期待的选手,V3已经证明了DeepSeek的实力 2、GLM-5——智谱的新旗舰,之前Pony Alpha的表现已经让人刮目相看 3、MiniMax 2.2——M2.5编程能力追平Claude,2.2值得关注
老金我觉得今年春节档的竞争格局跟去年完全不同。 去年是DeepSeek V3一家独大。 今年是四五个玩家同时出牌。
对普通用户来说,这其实是好事。 竞争越激烈,开源模型的能力提升越快,API价格越便宜。
Qwen3.5-397B-A17B这个版本号值得单独说一下。 397B是总参数量,A17B是激活参数量——3970亿参数里每次只用170亿。
什么意思?打个比方: 这就像一个公司有3970个员工,但每次处理一个任务只需要170个人同时干活。 其他人"待命",等需要的时候再上。
这就是MoE(Mixture of Experts,混合专家)架构的核心思路。 模型里有很多"专家"模块,每个token只激活其中几个。 好处是:模型容量大(知识多),但推理成本低(算得快)。
回顾一下Qwen3的数据:
Qwen3-235B-A22B(2350亿参数,激活220亿)在编程、数学、推理上已经能跟DeepSeek-R1、GPT-5正面对决。 Qwen3-30B-A3B在SWE-Bench上拿到69.6分,价格性能比吊打一众付费模型。
Qwen3.5-397B-A17B直接把总参数量拉到3970亿,是Qwen3旗舰的1.7倍。 但激活参数只有170亿,比Qwen3旗舰的220亿还少。
翻译成人话:知识储备更多了,但跑起来反而更省资源。 再加上原生多模态和线性注意力的加持,老金我认为这是2026年上半年最值得关注的开源模型之一。
说了这么多技术细节,老金我讲讲实际怎么用。 好消息是:你现在就可以直接体验Qwen3.5,不用等。
第1步:打开 ch@t.qwen.ai 浏览器直接输入 ch@t.qwen.ai,这是阿里官方的对话平台。 注册一个账号就能用,支持手机号和邮箱注册。 不需要科穴上网,国内直接访问。
第2步:选模型和模式 页面顶部有个模型选择器,点开会看到两个选项:
不知道选哪个?选Qwen3.5-Plus就行,够用了。 需要更强的推理能力再切397B。
选好模型后,还能选三种思考模式:
第3步:直接对话 跟ChatGPT的用法一模一样——输入框打字,回车发送。 支持的功能包括:
完全免费,目前没有次数限制。
对,你没看错,免费的。 这也是阿里开源生态的一贯打法。
如果你是开发者,除了网页版还有更多玩法。
场景1:API调用(1M上下文窗口) 阿里云百炼已经上线Qwen3.5-Plus的API,支持100万token的上下文窗口。 100万token是什么概念?大概相当于一次性读完一本750页的英文小说还绰绰有余。
而且API完全兼容OpenAI格式,切换成本几乎为零:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.ch@t.completions.create(
model="qwen3.5-plus",
messages=[{"role": "user", "content": "介绍一下Qwen3.5"}],
extra_body={
"enable_thinking": True,
"enable_search": False
},
stream=True
)
两个关键参数:
场景2:Vibe Coding(跟编程工具集成) 官方明确说了,百炼API可以跟这些编程工具无缝集成:
也就是说,你在Claude Code里把模型切成Qwen3.5-Plus,一样能用。 价格比GPT-5便宜10倍以上,对于日常编程来说性价比拉满。
场景3:多模态应用 原生多模态意味着你可以用一个模型搞定:
以前这些任务要调3-4个不同的API,现在一个就够了。
场景4:本地部署 Qwen3.5-397B-A17B虽然总参数3970亿,但激活参数只有170亿。 等开源权重发布后,用Ollama或vLLM部署,消费级显卡也有可能跑起来。 后续如果有更小的版本(比如9B),16G显存的显卡就能流畅运行。
Qwen3.5除夕夜在ch@t.qwen.ai正式上线了。 老金我说说自己的看法。
看好的点:
值得关注的未来方向: 官方博客最后提了三个方向,老金我觉得每个都很重要: 1、跨会话持久记忆——现在的AI每次对话都是"失忆"状态,未来能记住你之前聊过什么 2、具身接口——不只是操作手机电脑屏幕,未来可能控制机器人在真实世界干活 3、自我改进机制——AI能自己变得更好,不需要人类手动更新
阿里原话是:"将当前以任务为边界的助手升级为可持续、可信任的伙伴。"
老金我的态度是谨慎乐观。 架构升级的方向是对的,除夕夜放这个大招,阿里是真的有底气。
跑分数据已经出来了,视觉能力多项碾压GPT5.2和Claude 4.5 Opus,你现在就可以去ch@t.qwen.ai亲自试试。
有一点可以确定:2026年的开源大模型,竞争只会越来越激烈。 对于开发者和普通用户来说,这是最好的时代。
往期推荐:
AI编程教程列表 提示词工工程(Prompt Engineering) LLMOPS(大语言模运维平台) AI绘画教程列表 WX机器人教程列表
每次我都想提醒一下,这不是凡尔赛,是希望有想法的人勇敢冲。 我不会代码,我英语也不好,但是我做出来了很多东西,在文末的开源知识库可见。 我真心希望能影响更多的人来尝试新的技巧,迎接新的时代。
谢谢你读我的文章。 如果觉得不错,随手点个赞、在看、转发三连吧 如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章。
开源知识库地址: tffyvtlai4.feishu.cn/wiki/OhQ8wq…

