新月图床
2.56M · 2026-04-06

在使用 Claude 的工具调用功能时,你可能会注意到 Claude 可以在单个助手消息中包含多个工具使用块。这使得 Claude 能够并行运行多个工具,而不是为每个工具分别发起请求。然而,在实践中让 Claude 始终如一地做到这一点可能具有挑战性。

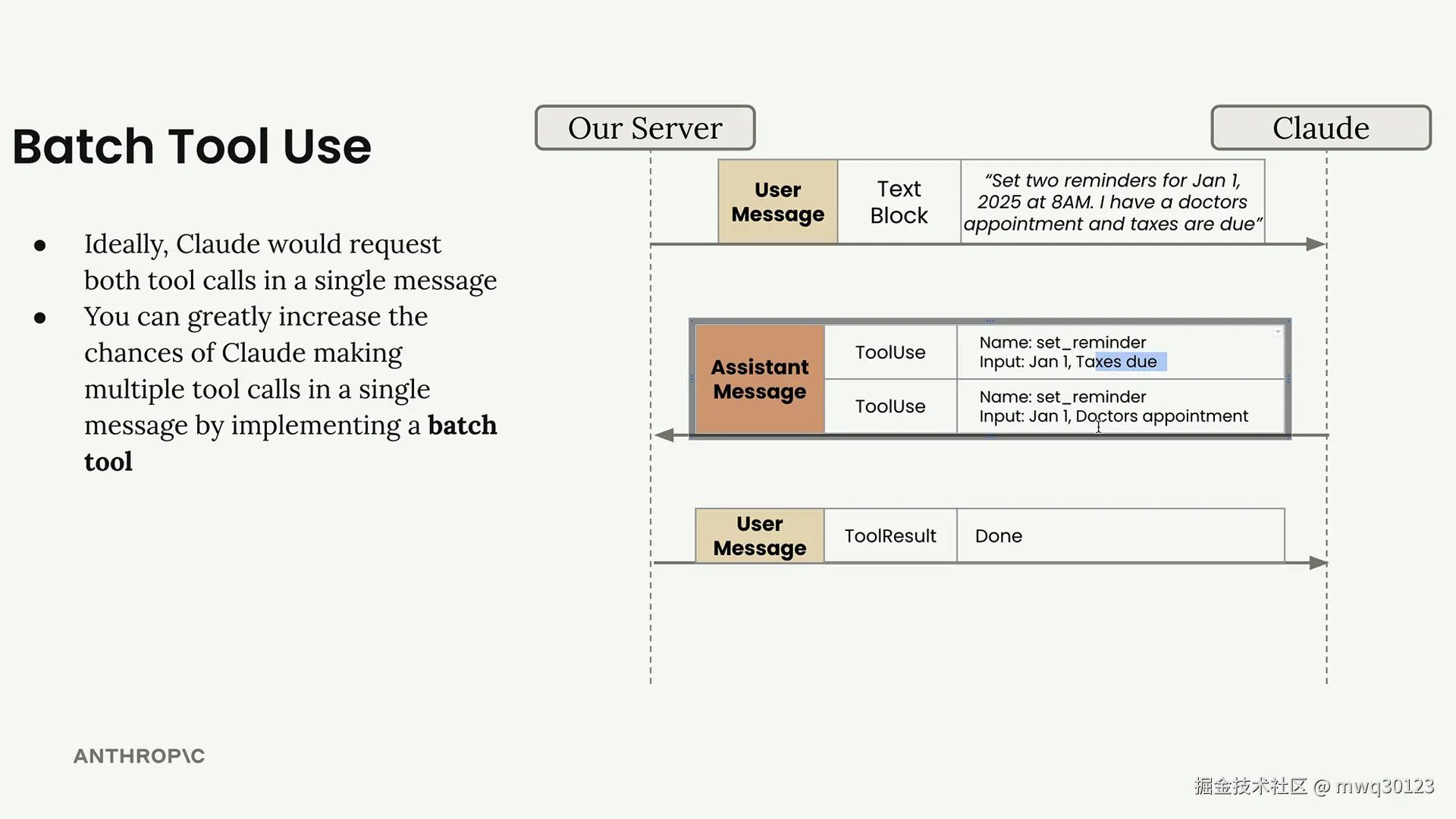
批量工具是一个额外的工具,它接受对其他工具的调用列表。Claude 不是直接调用多个工具,而是调用批量工具并提供描述它想要运行哪些工具的参数。

当你收到批量工具调用时,你的代码会遍历调用列表并执行每个请求的工具调用。
首先,你需要定义批处理工具的架构。结构如下:
batch_tool_schema = {
"name": "batch_tool",
"description": "Invoke multiple other tool calls simultaneously",
"input_schema": {
"type": "object",
"properties": {
"invocations": {
"type": "array",
"description": "The tool calls to invoke",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The name of the tool to invoke"
},
"arguments": {
"type": "object",
"description": "The arguments to pass to the tool"
}
}
}
}
}
}
}
接下来,你需要创建处理批量工具调用的函数:
def run_batch(invocations=[]):
batch_output = []
for invocation in invocations:
name = invocation["name"]
args = json.loads(invocation["arguments"])
tool_output = run_tool(name, args)
batch_output.append({
"tool_name": name,
"output": tool_output
})
return batch_output
这个函数:
run_tool 函数调用相应的工具你还需要更新主工具路由函数以处理批量工具:
def run_tool(tool_name, tool_input):
if tool_name == "get_current_datetime":
return get_current_datetime(**tool_input)
elif tool_name == "add_duration_to_datetime":
return add_duration_to_datetime(**tool_input)
elif tool_name == "set_reminder":
return set_reminder(**tool_input)
elif tool_name == "batch_tool":
return run_batch(**tool_input)
实现后,当 Claude 识别到可以并行执行多个操作时,它将更倾向于使用批量工具。Claude 不会发起单独的请求,而是会调用批量工具并传入它想要执行的所有操作列表。
批量工具本质上是一种变通方法,为 Claude 提供了更高层次的并行工具执行抽象。虽然这种方法看起来可能有些不寻常,但它是一种有效的技术,可以鼓励 Claude 将相关操作批量处理,减少 API 往返次数并提高整体效率。
run_tool: get_current_datetime, {'date_format': '%Y-%m-%d %H:%M:%S'}
run_tool: batch_tool, {'invocations': [{'name': 'add_duration_to_datetime', 'arguments': '{"datetime_str": "2026-02-13 10:46:40", "duration": 2000, "input_format": "%Y-%m-%d %H:%M:%S", "unit": "days"}'}, {'arguments': '{"datetime_str": "2026-02-13 10:46:40", "duration": 3, "input_format": "%Y-%m-%d %H:%M:%S", "unit": "hours"}', 'name': 'add_duration_to_datetime'}, {'name': 'add_duration_to_datetime', 'arguments': '{"datetime_str": "2026-02-13 10:46:40", "duration": 30, "input_format": "%Y-%m-%d %H:%M:%S", "unit": "minutes"}'}]}
run_tool: add_duration_to_datetime, {'datetime_str': '2026-02-13 10:46:40', 'duration': 2000, 'input_format': '%Y-%m-%d %H:%M:%S', 'unit': 'days'}
run_tool: add_duration_to_datetime, {'datetime_str': '2026-02-13 10:46:40', 'duration': 3, 'input_format': '%Y-%m-%d %H:%M:%S', 'unit': 'hours'}
run_tool: add_duration_to_datetime, {'datetime_str': '2026-02-13 10:46:40', 'duration': 30, 'input_format': '%Y-%m-%d %H:%M:%S', 'unit': 'minutes'}
run_tool: batch_tool, {'invocations': [{'arguments': '{"content": "医生预约", "timestamp": "2031-08-06T10:46:40"}', 'name': 'set_reminder'}, {'name': 'set_reminder', 'arguments': '{"content": "吃药", "timestamp": "2026-02-13T13:46:40"}'}, {'name': 'set_reminder', 'arguments': '{"content": "去超市", "timestamp": "2026-02-13T11:16:40"}'}]}
run_tool: set_reminder, {'content': '医生预约', 'timestamp': '2031-08-06T10:46:40'}
run_tool: set_reminder, {'content': '吃药', 'timestamp': '2026-02-13T13:46:40'}
run_tool: set_reminder, {'content': '去超市', 'timestamp': '2026-02-13T11:16:40'}
好的,已为您成功设置以下三个提醒:
1. **医生预约**:已设定在 **2031年8月6日 10:46:40**(当前时间2000天后)。
2. **吃药**:已设定在 **2026年2月13日 13:46:40**(当前时间3小时后)。
3. **去超市**:已设定在 **2026年2月13日 11:16:40**(当前时间30分钟后)。
{
"max_tokens": 4000,
"messages": [
{
"role": "user",
"content": "1.请为我的医生预约设置一个提醒,当前时间之后的第2000天; n 2.请为我吃药预约设置一个提醒,当前时间之后的3小时后n 3.请为我去超市设置一个提醒,当前时间之后的30分钟后n "
},
{
"role": "assistant",
"content": [
{
"id": "get_current_datetime-wJDgBEbf",
"input": {
"date_format": "%Y-%m-%d %H:%M:%S"
},
"name": "get_current_datetime",
"type": "tool_use"
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "get_current_datetime-wJDgBEbf",
"content": ""2026-02-13 10:46:40"",
"is_error": false
}
]
},
{
"role": "assistant",
"content": [
{
"id": "batch_tool-PYSUDwxJ",
"input": {
"invocations": [
{
"name": "add_duration_to_datetime",
"arguments": "{"datetime_str": "2026-02-13 10:46:40", "duration": 2000, "input_format": "%Y-%m-%d %H:%M:%S", "unit": "days"}"
},
{
"arguments": "{"datetime_str": "2026-02-13 10:46:40", "duration": 3, "input_format": "%Y-%m-%d %H:%M:%S", "unit": "hours"}",
"name": "add_duration_to_datetime"
},
{
"name": "add_duration_to_datetime",
"arguments": "{"datetime_str": "2026-02-13 10:46:40", "duration": 30, "input_format": "%Y-%m-%d %H:%M:%S", "unit": "minutes"}"
}
]
},
"name": "batch_tool",
"type": "tool_use"
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "batch_tool-PYSUDwxJ",
"content": "[{"tool_name": "add_duration_to_datetime", "output": "Wednesday, August 06, 2031 10:46:40 AM"}, {"tool_name": "add_duration_to_datetime", "output": "Friday, February 13, 2026 01:46:40 PM"}, {"tool_name": "add_duration_to_datetime", "output": "Friday, February 13, 2026 11:16:40 AM"}]",
"is_error": false
}
]
},
{
"role": "assistant",
"content": [
{
"id": "batch_tool-Orfp2e5h",
"input": {
"invocations": [
{
"arguments": "{"content": "医生预约", "timestamp": "2031-08-06T10:46:40"}",
"name": "set_reminder"
},
{
"name": "set_reminder",
"arguments": "{"content": "吃药", "timestamp": "2026-02-13T13:46:40"}"
},
{
"name": "set_reminder",
"arguments": "{"content": "去超市", "timestamp": "2026-02-13T11:16:40"}"
}
]
},
"name": "batch_tool",
"type": "tool_use"
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "batch_tool-Orfp2e5h",
"content": "[{"tool_name": "set_reminder", "output": null}, {"tool_name": "set_reminder", "output": null}, {"tool_name": "set_reminder", "output": null}]",
"is_error": false
}
]
}
],
"model": "gemini-3-flash",
"stop_sequences": [],
"temperature": 1,
"tools": [
{
"name": "get_current_datetime",
"description": "根据指定格式返回当前日期和时间。n 此工具提供格式化的系统时间字符串,适用于时间戳记录、时间差计算或向用户显示当前时间。n 默认格式为 YYYY-MM-DD HH:MM:SS。",
"input_schema": {
"type": "object",
"properties": {
"date_format": {
"type": "string",
"description": "指定返回日期时间格式的字符串,使用 Python 的 strftime 格式代码。n 例如:'%Y-%m-%d' 返回日期(YYYY-MM-DD),'%H:%M:%S' 返回时间(HH:MM:SS),'%B %d, %Y' 返回如 'May 07, 2025' 的日期。n 默认为 '%Y-%m-%d %H:%M:%S',返回完整时间戳如 '2025-05-07 14:32:15'。.",
"default": "%Y-%m-%d %H:%M:%S"
}
},
"required": []
}
},
{
"name": "add_duration_to_datetime",
"description": "n 将指定的时间长度添加到日期时间字符串,并以详细格式返回结果日期时间。n 此工具将输入的日期时间字符串转换为 Python datetime 对象,n 在请求的时间单位中添加指定的时间长度,并返回格式化后的结果日期时间字符串。n 它处理各种时间单位,包括秒、分钟、小时、天、周、月和年,对月份和年份的计算进行特殊处理,以考虑不同月份长度和闰年。n 输出始终以详细格式返回,包括星期几、月份名称、日期、年份和带 AM/PM 指示符的时间(n 例如,'Thursday, April 03, 2025 10:30:00 AM')。n ",
"input_schema": {
"type": "object",
"properties": {
"datetime_str": {
"type": "string",
"description": "要添加时间长度的输入日期时间字符串。应根据 input_format 参数进行格式化。"
},
"duration": {
"type": "number",
"description": "要添加到日期时间的时间量。可以是正数(用于未来日期)或负数(用于过去日期)。默认为 0。"
},
"unit": {
"type": "string",
"description": "时间长度的单位。必须是以下之一:'seconds'、'minutes'、'hours'、'days'、'weeks'、'months' 或 'years'。默认为 'days'。"
},
"input_format": {
"type": "string",
"description": "用于解析输入 datetime_str 的格式字符串,使用 Python 的 strptime 格式代码。例如,'%Y-%m-%d' 用于 ISO 格式日期,如 '2025-04-03'。默认为 '%Y-%m-%d'。"
}
},
"required": [
"datetime_str"
]
}
},
{
"name": "set_reminder",
"description": "创建一个定时提醒,将在指定时间使用提供的内容通知用户。n 此工具安排在提供的精确时间戳向用户发送通知。n 当用户希望在未来的某个时间点被提醒某事时,应使用此工具。n 提醒系统将存储内容和时间戳,然后在指定时间到达时通过用户首选的通知渠道(移动设备提醒、电子邮件等)触发通知。n 即使应用程序关闭或设备重启,提醒也会持久保存。n 用户可以依赖此功能来处理重要的时间敏感通知,如会议、任务、药物时间表或任何其他有时间限制的活动。n ",
"input_schema": {
"type": "object",
"properties": {
"content": {
"type": "string",
"description": "将在提醒通知中显示的消息文本。应包含用户希望被提醒的具体信息,例如'服药'、'加入团队视频通话'或'支付水电费'。"
},
"timestamp": {
"type": "string",
"description": "应触发提醒的确切日期和时间,格式为 ISO 8601 时间戳(YYYY-MM-DDTHH:MM:SS)或 Unix 时间戳。n 系统在内部处理所有时区处理,确保无论用户位于何处,提醒都会在正确的时间触发。n 用户可以简单地指定所需时间,而无需担心时区配置。"
}
},
"required": [
"content",
"timestamp"
]
}
},
{
"name": "batch_tool",
"description": "同时调用多个其他工具",
"input_schema": {
"type": "object",
"properties": {
"invocations": {
"type": "array",
"description": "要调用的工具调用列表",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "要调用的工具名称"
},
"arguments": {
"type": "string",
"description": "传递给工具的参数,编码为 JSON 字符串"
}
},
"required": [
"name",
"arguments"
]
}
}
},
"required": [
"invocations"
]
}
}
]
}
当你需要从 Claude 获取结构化数据时,有两种主要方法:使用消息预填充和停止序列的提示词技术,或使用工具的更稳健方法。虽然基于提示词的方法设置更简单,但工具能提供更可靠的输出,代价是增加了复杂性。
基于工具的方法通过创建 JSON schema 来定义你想要提取的数据的确切结构。你不是寄希望于 Claude 正确格式化其响应,而是本质上给 Claude 提供一个函数来调用,该函数带有与你期望的输出结构匹配的特定参数。

tool_choice 参数强制 Claude 使用工具例如,如果你想从财务报表中提取余额和关键见解,你的 schema 会分别将它们定义为整数和字符串数组。
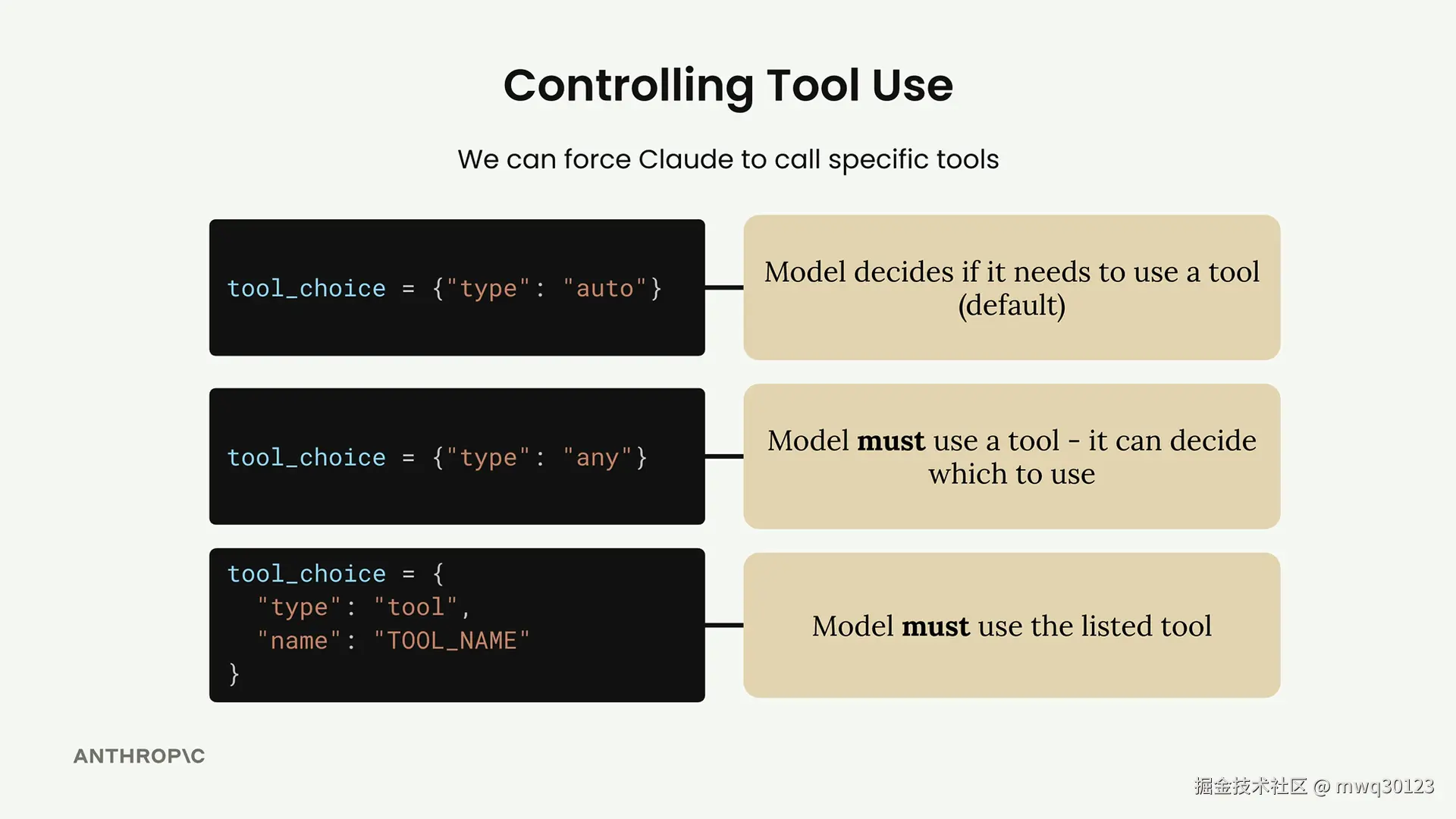
这项技术的关键部分是确保 Claude 实际调用你的工具。你可以使用 tool_choice 参数来控制此行为:
{"type": "auto"} - 模型决定是否需要使用工具(默认){"type": "any"} - 模型必须使用工具,但可以选择使用哪一个{"type": "tool", "name": "TOOL_NAME"} - 模型必须使用指定的工具对于结构化数据提取,你通常需要第三个选项来保证 Claude 调用你的特定 schema 工具。
假设你想从文章中提取标题、作者和关键见解。首先,你需要创建一个工具 schema:
article_summary_schema = {
"name": "article_summary",
"description": "Extracts structured data from articles",
"input_schema": {
"type": "object",
"properties": {
"title": {"type": "string"},
"author": {"type": "string"},
"key_insights": {
"type": "array",
"items": {"type": "string"}
}
}
}
}
然后你使用工具调用 Claude 并强制其使用:
response = chat(
messages,
tools=[article_summary_schema],
tool_choice={"type": "tool", "name": "article_summary"}
)
响应将包含一个工具使用块,其中 input 字段包含你的结构化数据。你可以直接访问它:
structured_data = response.content[0].input
当你需要快速简单的解决方案时,选择基于提示词的结构化输出。当你需要保证可靠性并能处理额外的设置复杂性时,使用工具。根据你的具体用例和需求,这两种技术都很有价值。
当你在 Claude 中结合工具使用和流式传输时,AI 在生成工具参数时会实时更新。这创造了更具响应性的用户体验,但关于其幕后工作原理,有一些重要细节需要理解。
启用流式传输后,Claude 在处理您的请求时会发送不同类型的事件。您已经熟悉用于常规文本生成的 ContentBlockDelta 等事件。对于工具使用,您还需要处理一种名为 InputJsonEvent 的新事件类型。
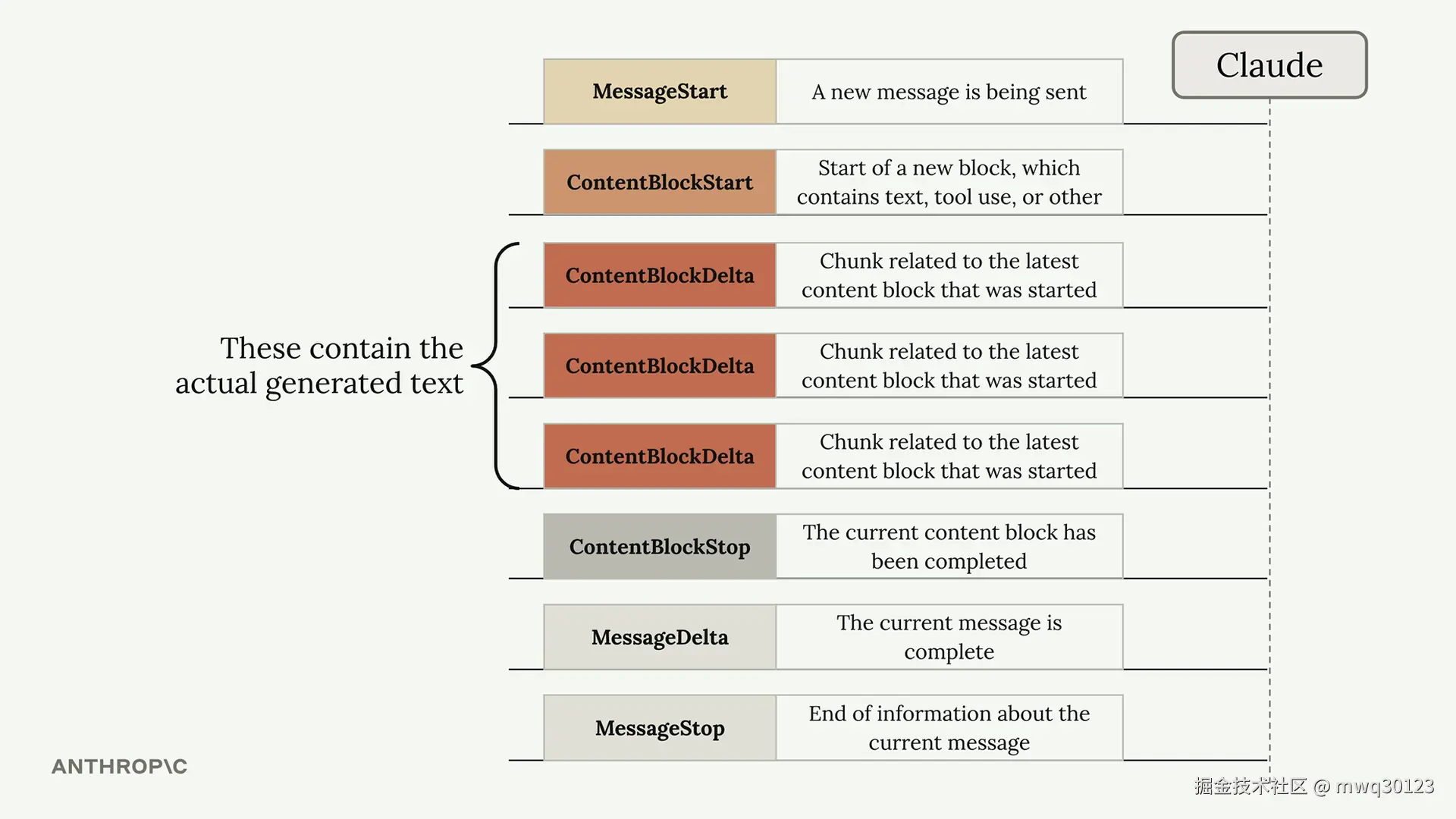
InputJsonEvent 包含两个关键属性:
以下是你在流式处理管道中处理这些事件的方式:
for chunk in stream:
if chunk.type == "input_json":
# Process the partial JSON chunk
print(chunk.partial_json)
# Or use the complete snapshot so far
current_args = chunk.snapshot
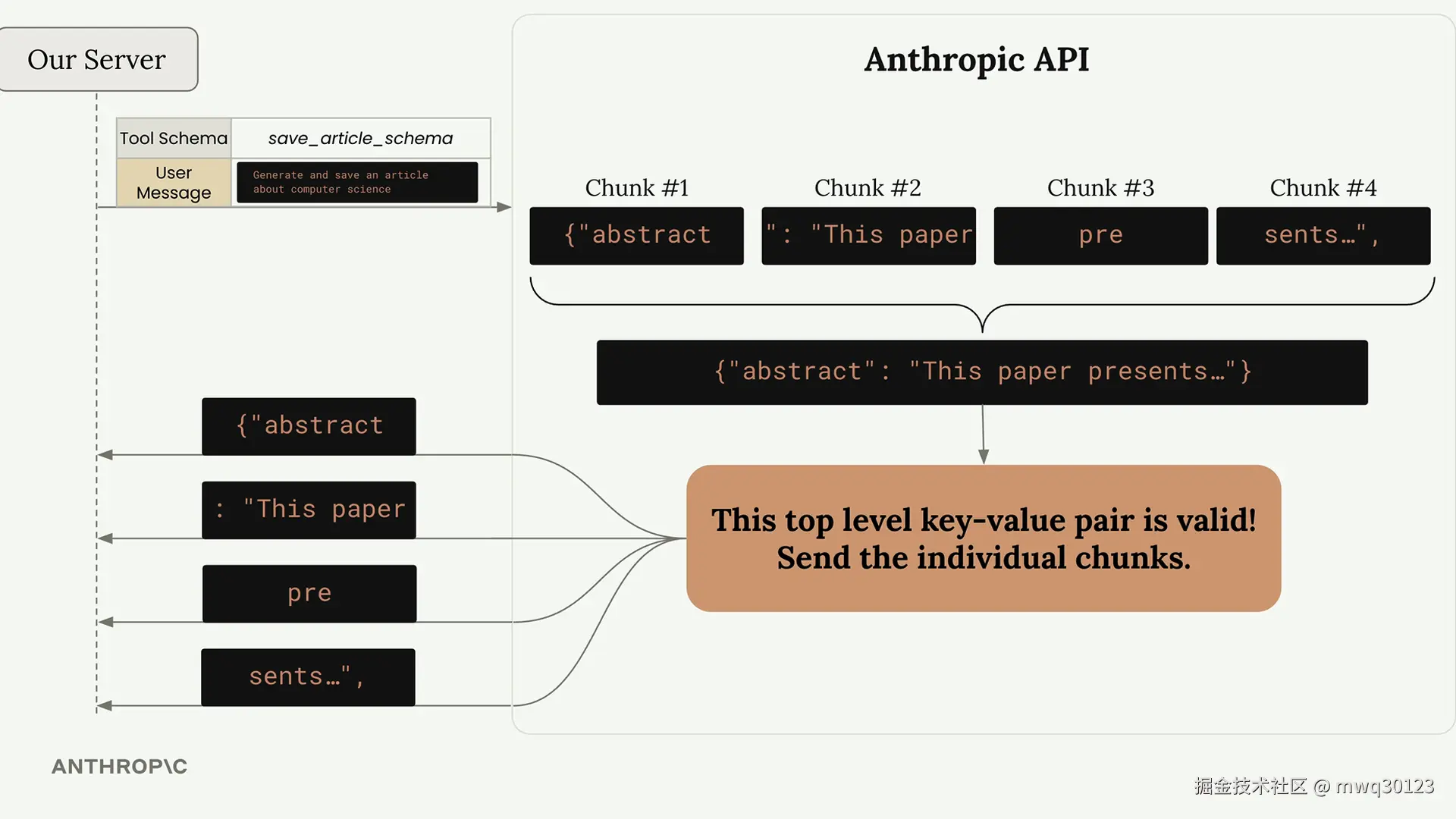
有趣的地方来了。Anthropic API 不会在 Claude 生成时立即发送每个数据块。相反,它会先缓冲数据块并进行验证。

{
"abstract": "This paper presents a novel...",
"meta": {
"word_count": 847,
"review": "This paper introduces QuanNet..."
}
}
API 将:
abstract 值完成abstract 的所有缓冲块meta 对象重复此过程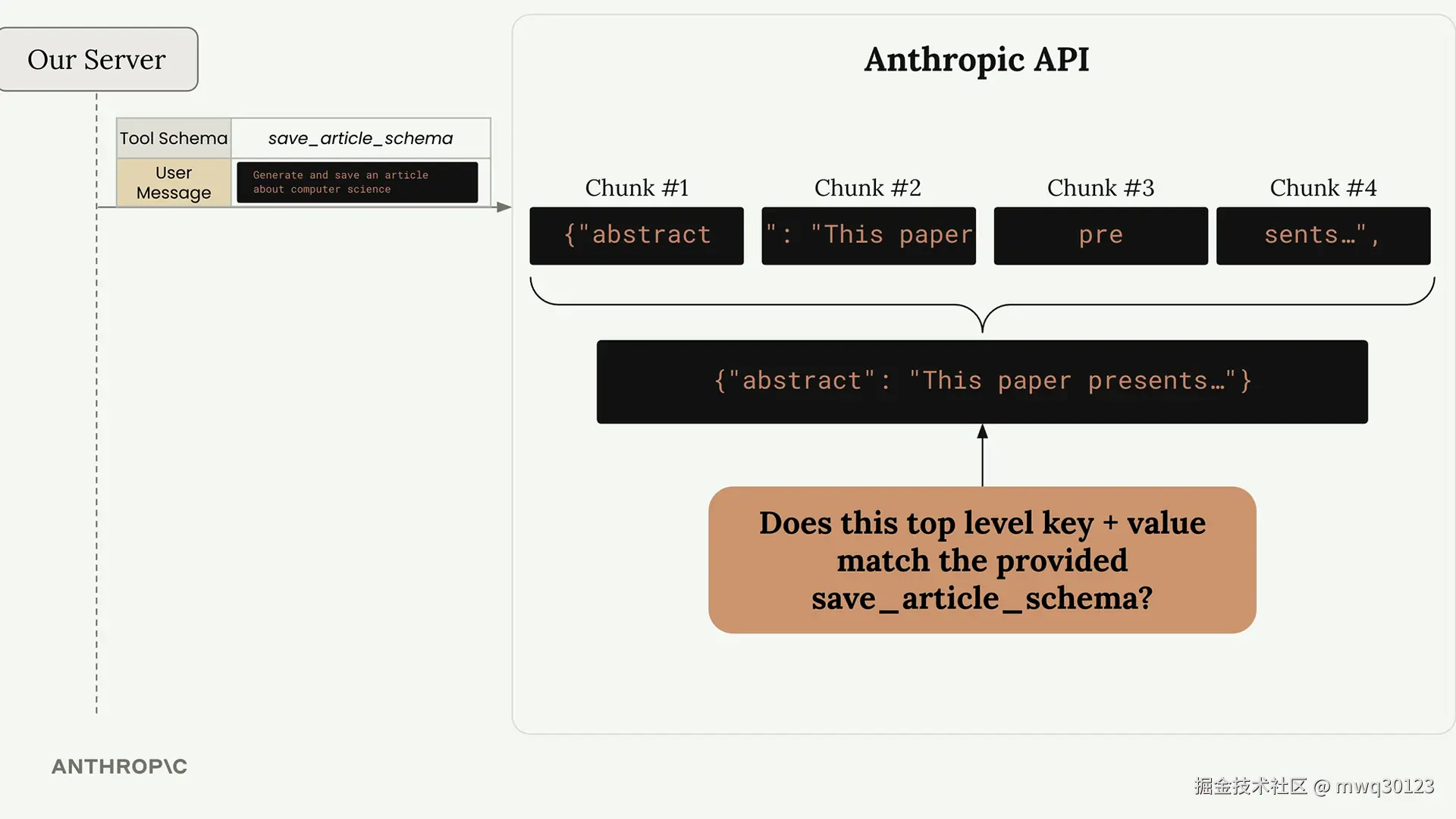
如果你需要更快、更细粒度的流式传输——也许是为了向用户显示即时更新或快速开始处理部分结果——你可以启用细粒度工具调用。

通过在 API 调用中添加 fine_grained=True 来启用它:
run_conversation(
messages,
tools=[save_article_schema],
fine_grained=True
)
使用细粒度工具调用,你可能在流中更早地收到 word_count 值,而无需等待整个 meta 对象完成。
使用细粒度工具调用时,Claude 可能会生成无效的 JSON,如 "word_count": undefined 而不是正确的数字。你的应用程序需要优雅地处理这些情况:
try:
parsed_args = json.loads(chunk.snapshot)
except json.JSONDecodeError:
# Handle invalid JSON appropriately
print("Received invalid JSON, continuing...")
如果没有细粒度工具调用,API 的验证会捕获此错误,并可能将有问题的值包装在字符串中,这可能与你的预期 schema 不匹配。
在以下情况下考虑启用细粒度工具调用:
对于大多数应用程序,带验证的默认行为是完全足够的。但当你需要额外的响应性时,细粒度工具调用为你提供了控制,让你能够以 Claude 生成的速度获得数据块。
Claude 带有一个内置工具,你不需要从头创建:文本编辑器工具。此工具使 Claude 能够像在标准文本编辑器中一样处理文件和目录。
文本编辑器工具为 Claude 提供了一套全面的文件操作功能:
这大大扩展了 Claude 的能力,本质上使其能够立即充当软件工程师。
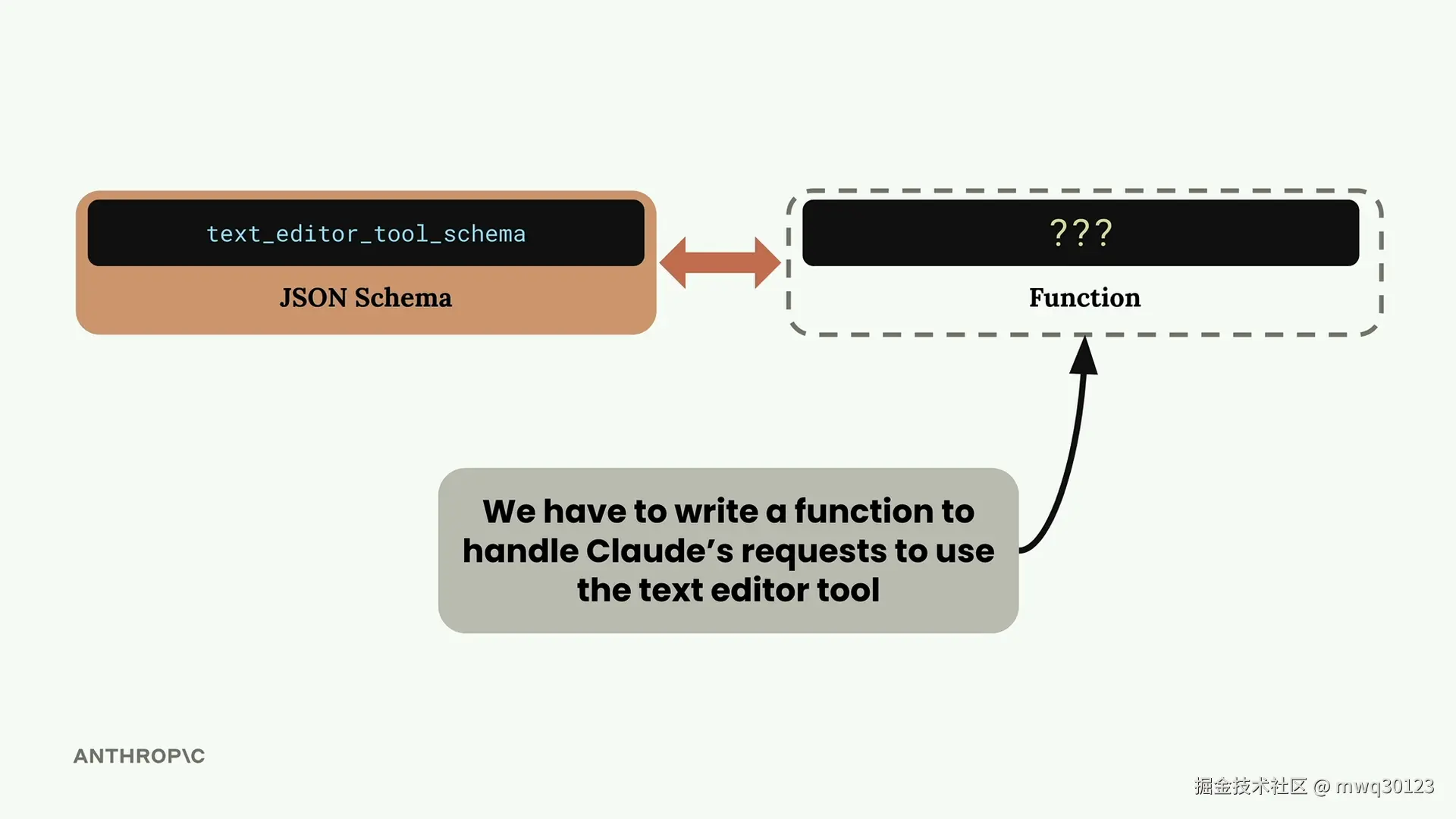
这里有点令人困惑:虽然工具 schema 内置在 Claude 中,但你仍然需要提供实际的实现。这样想——Claude 知道如何请求文件操作,但你需要编写实际执行这些操作的代码。
当你使用其他工具时,你需要编写 JSON schema 和函数实现。对于文本编辑器工具,Claude 提供 schema 知识,但你必须编写函数来处理 Claude 创建文件、读取目录、替换文本等请求。
虽然主 schema 内置在 Claude 中,但在发出请求时你确实需要包含一个小的 schema 存根。确切的 schema 取决于你使用的 Claude 模型:
def get_text_edit_schema(model):
if model.startswith("claude-3-7-sonnet"):
return {
"type": "text_editor_20250124",
"name": "str_replace_editor",
}
elif model.startswith("claude-3-5-sonnet"):
return {
"type": "text_editor_20241022",
"name": "str_replace_editor",
}
Claude 看到这个小的 schema 并自动在幕后将其扩展为完整的文本编辑器工具规范。
让我们看看文本编辑器工具的实际应用。当你要求 Claude 处理文件时,它将使用该工具根据需要读取、修改和创建文件。
例如,如果你要求 Claude "打开 ./main.py 文件并总结其内容",Claude 将:
你可以通过要求 Claude 修改文件来进一步扩展。例如:"打开 ./main.py 文件并编写一个计算 pi 到第 5 位数字的函数。然后创建一个 ./test.py 文件来测试你的实现。"
Claude 将:
当现代代码编辑器已经内置 AI 助手时,你可能想知道为什么这个工具存在。文本编辑器工具在以下场景中变得有价值:
本质上,文本编辑器工具让你在自己的应用程序中复制许多功能强大的 AI 驱动代码编辑器的功能,让你能够精细控制 Claude 如何与你的文件系统交互。
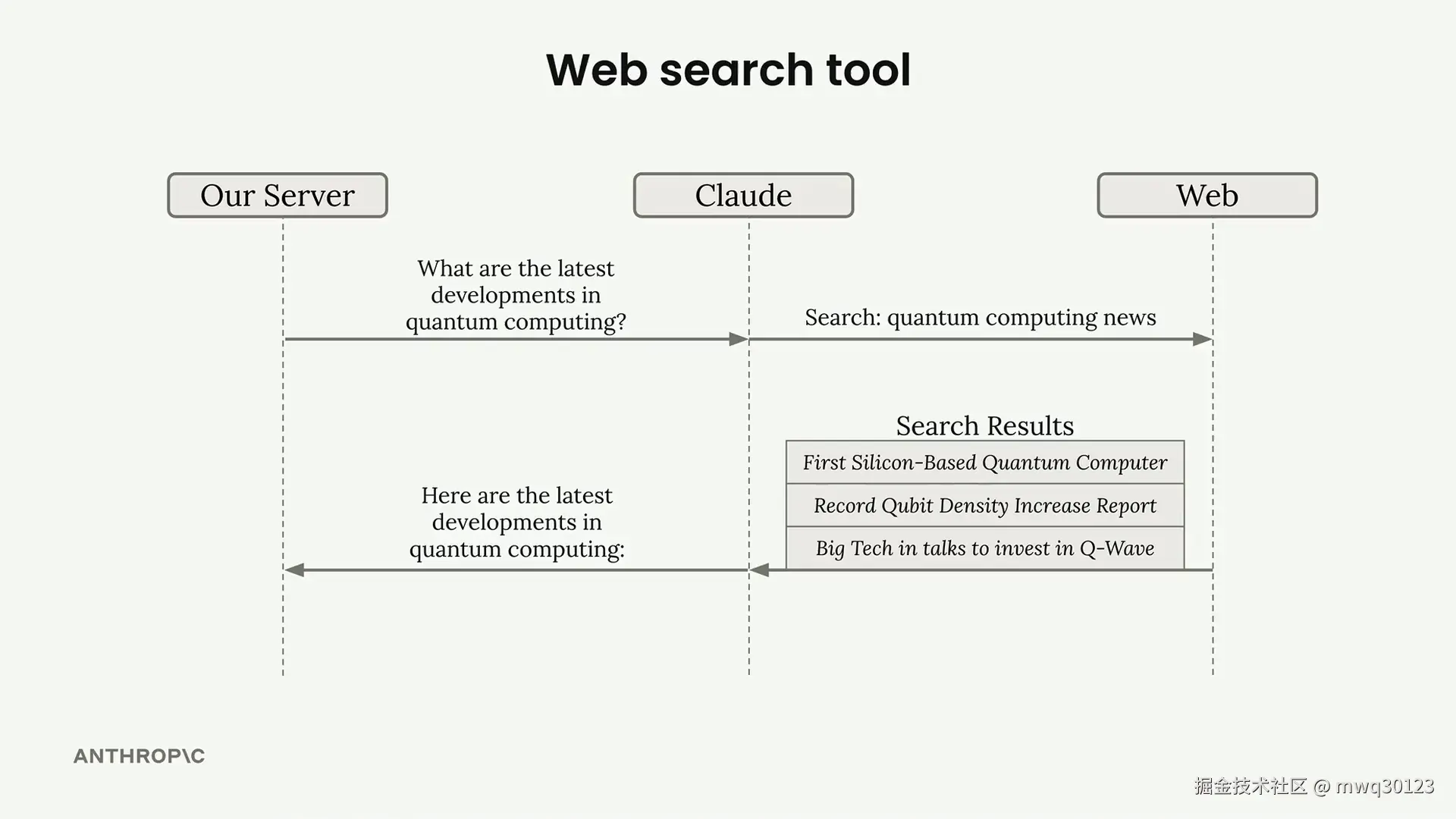
Claude 包含一个内置的网络搜索工具,可以让它在互联网上搜索当前或专业信息来回答用户问题。与其他需要你提供实现的工具不同,Claude 会自动处理整个搜索过程——你只需要提供一个简单的架构来启用它。
要使用网络搜索工具,你需要创建一个包含以下必填字段的架构对象:
web_search_schema = {
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}
max_uses 字段限制了 Claude 可以执行的搜索次数。Claude 可能会根据初始结果进行后续搜索,因此这可以防止过多的 API 调用。单次搜索会返回多个结果,但 Claude 可能会决定需要进行额外的搜索。
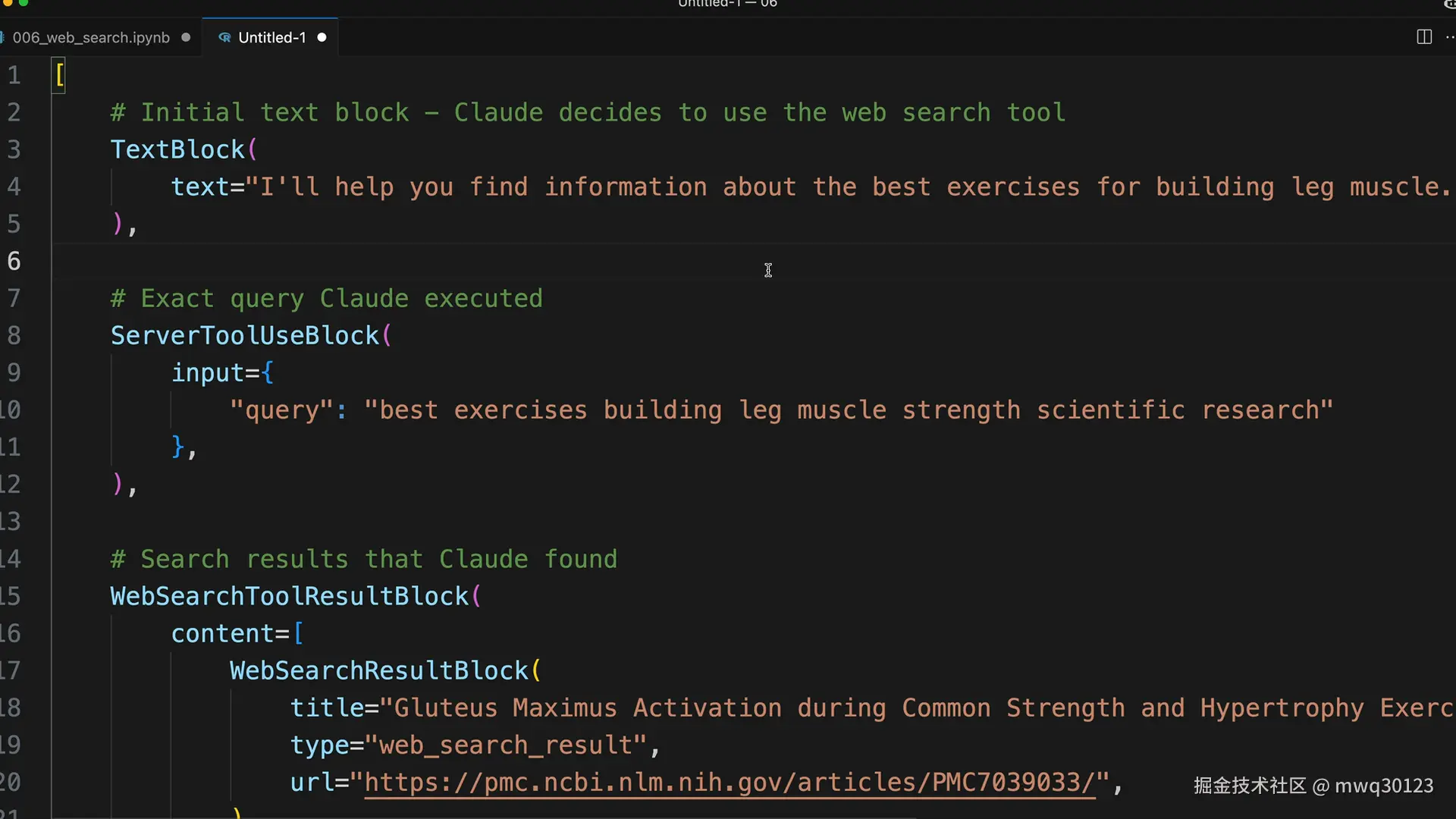
当 Claude 使用网络搜索工具时,响应包含几种类型的块:
响应结构让你能够准确看到 Claude 搜索了什么以及找到了哪些来源。引用包括 Claude 用来支持其答案的具体文本,以及来源 URL。
你可以使用 allowed_domains 字段将搜索限制在特定域名。当你需要可靠的权威来源时,这特别有用:
web_search_schema = {
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": ["nih.gov"]
}
例如,在询问医疗或运动建议时,限制到 PubMed (nih.gov) 等域名可以确保你获得基于证据的信息,而不是随机的博客内容。
响应中的不同块类型是为特定的 UI 渲染设计的:
这种结构帮助用户理解 Claude 如何得出答案,并提供关于所使用来源的透明度。引用格式清楚地表明哪些具体信息来自哪些来源,从而建立对 AI 回答的信任。
网络搜索工具最适合用于:
只需在进行 API 调用时将该模式包含在工具数组中,Claude 就会自动决定何时进行网络搜索以帮助回答用户的问题。

