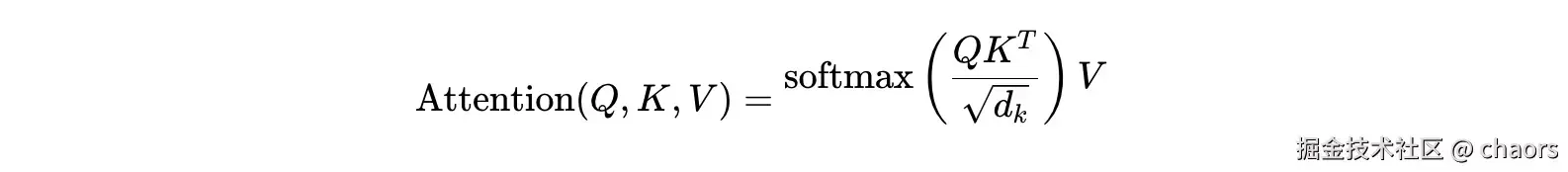
亚士
95.31M · 2026-04-06

前面几篇分别分享了AI大模型是怎么理解人类词汇和语言的,也分析了大模型为啥每次回答得不一样。那么大模型到底是怎么得出答案的呢?
同样,我们回到之前提到的一个经典的Case:
输入:我有一个苹果,它很好...
如果是人,可能怎么续写呢?
这又是为什么呢?
或者我们从另一个角度分析:
那么,AI大模型的思路是否也是如此? 没错,答案是肯定的。AI也是类似的思维(通俗地讲):
AI大模型在之前训练的时候对每个词汇都有相应的向量矩阵
AI在续写时根据每个词汇的向量矩阵之间的相关性理解语义
AI在续写下一个词汇时,分析哪个词汇与整个句子的语义相关性最大,即判为出现概率最大。最终将被选为续写的词汇
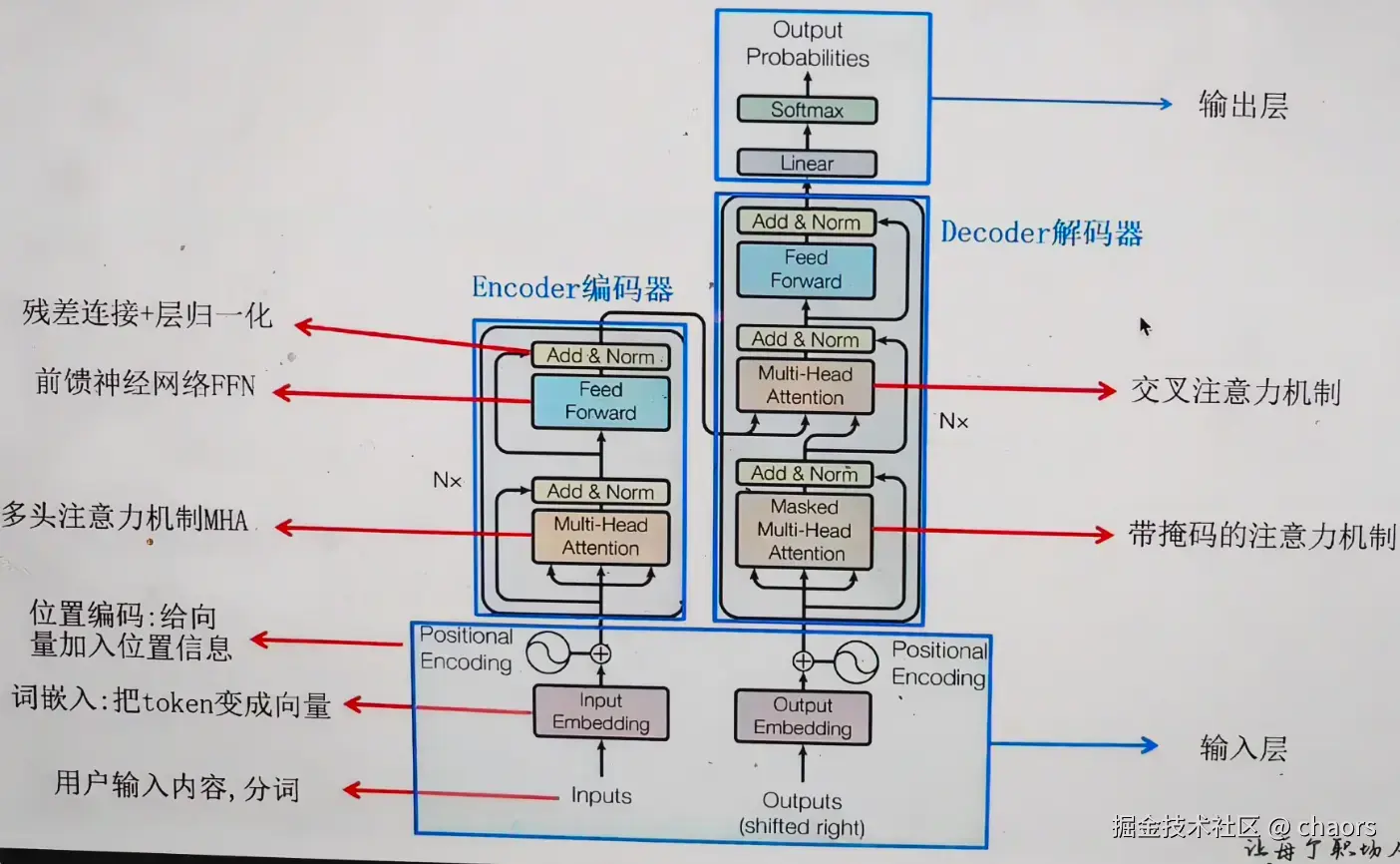
前面讲过词向量和Attention机制, 我们可以再看看Transformer架构中关于AI大模型得出答案的分析。
Input负责信息输入和位置编码,Encoder负责语义理解。Decoder负责答案和续写。
首先再回顾一下之前讲到的注意力机制的概念:
在Transformer架构中,我们发现有3个地方使用到了注意力机制:
Encoder Self-Attention:
Encoder-Decoder Attention/Cross-Attention:
Masked Decoder Self-Attention/Causal Self-Attention:
sequenceDiagram
输入->>Encoder: 0-Embedding + PE
Encoder->>Decoder:1-Self-Attention
Decoder-->>输出: 2-Cross-Attention
输出-->>输入:3-转输入
输入-->>Decoder: 4-Embedding + PE
Decoder-->>输出:4-Causal Self-Attention + 5-Cross-Attention
Add(残差连接) :将子层(如注意力机制或前馈网络)的输入与输出直接相加:输出 = 输入 + 子层(输入)
Norm(层归一化) :对相加后的结果进行标准化处理,使其均值为0,方差为1
一个:100人传话游戏,每人代表一层网络
没有Add:每传一人就失真20%,到最后几乎完全变形(梯度消失)
有Add:每人在传话同时,原始信息也直接传给最后一人,确保核心信息不丢失
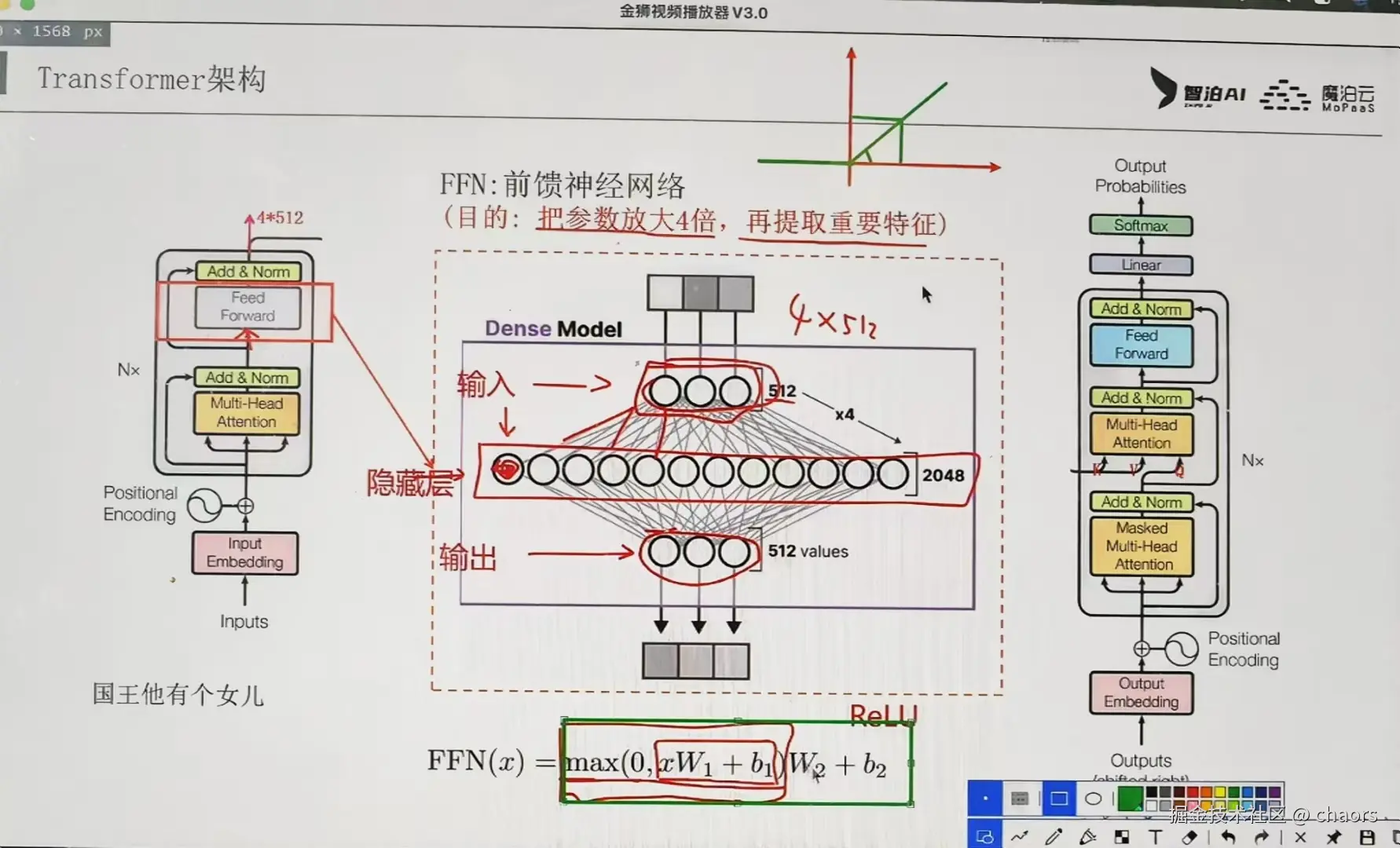
作为大模型“信息聚合”到“信息升华”的关键一步,其核心框架图如下:
Attention就像一个团队会议让AI理解输入,而FFN就像会后的独立思考与加工,对每个词融合了上下文信息后的表示进行深度非线性变换和提升。
【核心】:输入向量先通过一个线性层扩展到更高维度(通常4倍),经过非线性激活函数,再投影回原始维度
【流程】:
【作用】:
自注意力本质是加权求和(线性操作),即使堆叠多层,整体仍近似线性变换。FFN通过激活函数(ReLU/GELU)引入关键非线性,使模型能够拟合复杂函数,强化重要信息(如“电子产品”、“市场需求”),过滤或削弱次要或无关的联想(比如“苹果”的水果属性)。实验表明,移除FFN会导致模型性能下降15-30%。
FFN的“扩展-压缩”策略极具智慧:当维度从512扩展到2048时,模型获得了更大的特征组合空间。
在大语言模型中,FFN通常占据60-70%的参数总量。以GPT-3为例,其FFN层参数规模达到数百亿,成为模型的“知识存储器”。这种参数分布不是偶然,而是设计上的必然选择。
d_model(如1024维)扩展到d_ff(如4096维)时,参数量会急剧增长与自注意力不同,FFN对每个位置独立处理,这种设计实现了极致并行化。在GPU集群上,所有token的FFN计算可以同时进行,极大提升训练效率
Attention是线性变换的, 就像简单的复制粘贴或按比例缩放。比如,把 “苹果” 这个词的信息放大两倍,得到的只是 “苹果苹果”,并没有产生新的、更深刻的理解。自注意力机制本质上就是一种复杂的加权平均(线性组合),它能把“苹果”和“公司”的信息组合起来,但组合方式依然是线性的。
FFN是非线性变换,也正是这种非线性变化给Transformer带来了 创造性。 就好比是烹饪或化学反应。我们把西红柿(信息A)和鸡蛋(信息B)放进锅里(FFN),经过加热(激活函数),生成了一道全新的菜——西红柿炒鸡蛋(新信息C)。这个过程是创造性的,不是简单的线性叠加。

