
toxx便签本
50.60M · 2026-02-05

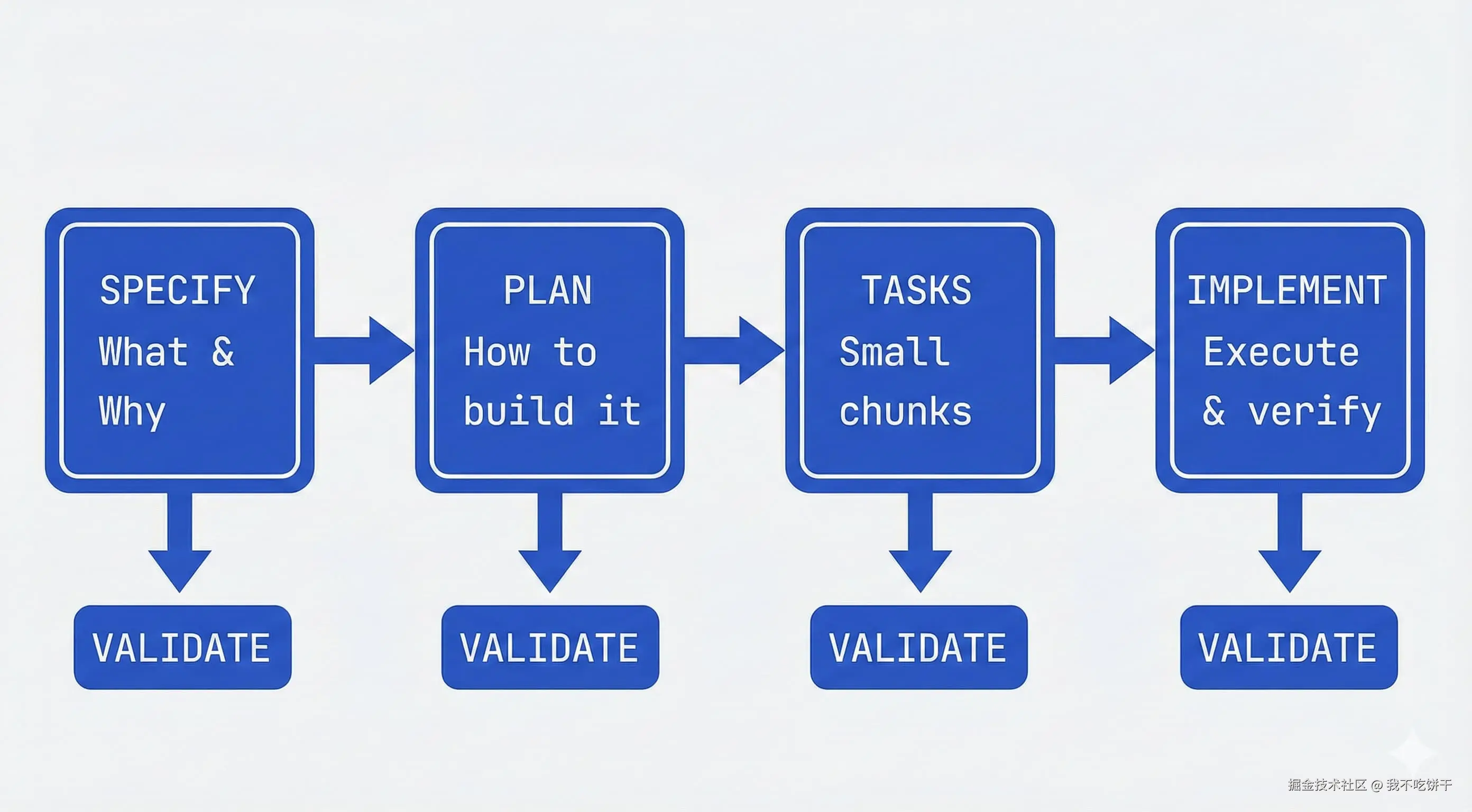
太长不看版:目标是撰写一份清晰的 spec,包含恰到好处的细节(可能包括结构、风格、测试、边界条件),既能引导 AI,又不会因信息过载而导致模型迷失方向。将大任务拆解为小任务,而不是将所有内容都塞进一个巨大的 prompt(提示词)中。先在只读模式下规划,再执行,并持续迭代。
许多开发者都有这种挫败感:直接把一份巨大的 spec 扔给 AI agent 并不会奏效——上下文窗口的限制和模型的“注意力预算”会成为阻碍。关键在于写聪明的 spec:既能清晰引导 agent,又能控制在实际可用的上下文规模内,并能随着项目推进不断演化。本文总结了我使用 Claude Code、Gemini CLI 等编码 agent 的经验与最佳实践,整理成一套 spec 编写框架,让你的 AI agent 保持专注、高效。
接下来我们会介绍写出优秀 AI agent spec 的五个原则;每个原则都会先给出一条加粗的核心要点。
先用一份简明的 high-level spec(项目概要)启动项目,然后让 AI 将其扩展为详细计划。
与其在前期过度设计,不如从一个清晰的目标陈述和几个核心需求开始。将其视为“产品简报”,让 agent 从中生成更详尽的 spec。这样既能利用 AI 在细节阐述方面的优势,又能让你掌控大局。除非你从一开始就有非常具体的技术要求必须满足,否则这种方法效果很好。
为什么有效: 基于大语言模型(LLM)的 agent 在获得可靠的 high-level 指令时,擅长充实细节,但它们需要一个清晰的任务目标以避免偏离方向。通过提供简短的大纲或目标描述,并要求 AI 生成完整的 spec(例如 spec.md 文件),你就创建了一个供 agent 持续参考的文档。对于 agent 而言,提前规划更为重要——你可以先迭代完善计划,然后再交给 agent 编写代码。spec 成为你和 AI 共同构建的第一个产出物。
实践方法: 通过这样的 prompt 开始新的编码会话:“你是一名 AI 软件工程师。为 [项目 X] 起草一份详细 spec,涵盖目标、功能、约束条件和分步计划。”保持初始 prompt 的 high-level 特性——例如“构建一个网页应用,用户可以跟踪任务(待办事项列表),包含用户账户、数据库和简洁的用户界面”。agent 可能会回复一份结构化的 spec 草案:概述、功能列表、技术栈建议、数据模型等等。这份 spec 随后成为你和 agent 都能回溯参考的“真理之源”。GitHub 的 AI 团队倡导 spec 驱动开发,认为“spec 成为共享的真理之源……是随项目演进的活文档、可执行的产出物”。在编写任何代码之前,审查并完善 AI 生成的 spec。确保它与你的愿景一致,并纠正任何幻觉或偏离目标的细节。
使用 Plan Mode 强制优先规划: 像 Claude Code 这样的工具提供了 Plan Mode(计划模式),该模式将 agent 限制为只读操作——它可以分析你的代码库并创建详细计划,但在你准备好之前不会编写任何代码。这对规划阶段非常理想:在 Plan Mode 下启动(Claude Code 中按 Shift+Tab),描述你想构建什么,让 agent 在探索现有代码的同时起草 spec。让它通过询问你来阐明计划中的模糊之处。让它审查计划的架构、最佳实践、安全风险和测试策略。目标是完善计划直到没有任何误解。直到此时才退出 Plan Mode,让 agent 执行。这个工作流程避免了在 spec 尚未稳固前就直接跳入代码生成的常见陷阱。
将 spec 用作上下文: spec 一旦通过,保存这份 spec(例如保存为 SPEC.md),并根据需要将相关部分提供给 agent。许多使用强大模型的开发者正是这样做的——spec 文件在会话之间持久存在,每当项目工作恢复时都能为 AI 提供锚点。这缓解了当对话历史过长或必须重启 agent 时可能发生的“健忘”问题。这类似于团队中使用产品需求文档(PRD)的方式:一份每个人(无论是人还是 AI)都能查阅以保持正轨的参考文档。正如一位工程师观察到的,有经验的人通常“先编写良好的文档,模型可能仅凭该输入就能构建匹配的实现”。而 spec 就是那份文档。
保持目标导向: 为 AI agent 编写的 high-level spec 应该更多地关注是什么和为什么,而不是(至少最初)细枝末节的怎么做。把它想象成用户故事和验收标准:用户是谁?他们需要什么?成功是什么样子?(例如“用户可以添加、编辑、完成任务;数据持久保存;应用响应迅速且安全”)。这使 AI 的详细 spec 植根于用户需求和结果,而不仅仅是技术待办事项。正如 GitHub Spec Kit docs 文档所说,提供你正在构建什么以及为什么的 high-level 描述,让 coding agent 生成专注于用户体验和成功标准的详细 spec。从这个宏观愿景开始,可以防止 agent 在后续编码时只见树木不见森林。
将你的 AI spec 视为一份结构化文档(PRD),包含清晰的章节,而不是一堆松散的笔记。
许多开发者写给 AI agent 的 spec,方式与传统的产品需求文档(PRD)或系统设计文档非常相似——全面、组织良好,且便于“字面理解”的 AI 解析。这种更正式的写法为 agent 提供了一份可遵循的蓝图,并减少了歧义。
六个核心领域: GitHub 对 超过 2,500 个 agent 配置文件的分析 揭示了一个清晰的模式:最有效的 spec 涵盖六个领域。可以把它当作完整性检查清单:
命令: 将可执行命令放在前面——不仅仅是工具名称,而是带有参数的完整命令:npm test、pytest -v、npm run build。agent 会不断参考这些命令。
测试: 如何运行测试、使用什么框架、测试文件位于何处,以及存在什么覆盖率期望。
项目结构: 源代码位于何处、测试放在哪里、文档归属何处。要明确:“src/ 用于应用代码,tests/ 用于单元测试,docs/ 用于文档。”
代码风格: 一个真实的代码片段展示你的风格,胜过三段描述性文字。包括命名约定、格式规则和良好输出的示例。
Git 工作流: 分支命名、commit 信息格式、PR 要求。如果你明确说明,agent 会遵循这些规则。
边界条件: agent 绝不应接触的内容——密钥、vendor 目录、生产环境配置、特定文件夹。“永远不要提交密钥”是 GitHub 研究中最常见、也最有用的约束之一。
明确你的技术栈: 说“React 18 + TypeScript、Vite、Tailwind CSS”,而不是“React 项目”。同时写清版本与关键依赖。模糊的 spec 往往只会产出模糊的代码。
使用一致的格式: 清晰为王。许多开发者会在 spec 中使用 Markdown 标题,甚至用类似 XML 的标签来划分章节,因为 AI 模型更擅长处理结构化文本,而不是自由散文。例如,你可以这样组织 spec:
# Project spec: My team's tasks app
## Objective
- Build a web app for small teams to manage tasks...
## Tech Stack
- React 18+, TypeScript, Vite, Tailwind CSS
- Node.js/Express backend, PostgreSQL, Prisma ORM
## Commands
- Build: `npm run build` (compiles TypeScript, outputs to dist/)
- Test: `npm test` (runs Jest, must pass before commits)
- Lint: `npm run lint --fix` (auto-fixes ESLint errors)
## Project Structure
- `src/` – Application source code
- `tests/` – Unit and integration tests
- `docs/` – Documentation
## Boundaries
- Always: Run tests before commits, follow naming conventions
- ️ Ask first: Database schema changes, adding dependencies
- Never: Commit secrets, edit node_modules/, modify CI config
这种组织层次不仅帮助你把事情想清楚,也能帮助 AI 更快定位信息。Anthropic 的工程师建议将 prompt 组织成不同的部分(如 <background>、<instructions>、<tools>、<output_format> 等),正是出于这个原因——它能给模型强有力的线索,区分不同类型的信息。记住,“简洁不一定意味着简短”——如果细节很重要,不要回避;但要保持专注。
将 spec 集成到你的工具链中: 将 spec 视为与版本控制和 CI/CD 绑定的“可执行产出物”。GitHub Spec Kit 使用四阶段的门控工作流,让 spec 成为工程流程的中心。与其写完 spec 就搁置,不如让 spec 驱动实现、检查清单和任务拆解。你的主要角色是掌舵;coding agent 负责大部分产出。每个阶段都有明确职责,在当前阶段完全验证之前,不进入下一阶段:
Spec 阶段(Specify): 你提供关于“要构建什么、为什么要构建”的 high-level 描述,coding agent 生成详细 spec。这不是在讨论技术栈或应用设计——而是用户旅程(user journeys)、体验,以及“成功长什么样”。谁会使用它?它解决什么问题?他们会如何与之交互?你可以把它看作是在勾勒期望的用户体验,再由 coding agent 补齐细节。它会随着你掌握更多信息而持续演进。
计划阶段(Plan): 现在进入技术层面。你提供期望的技术栈、架构与约束条件,coding agent 生成全面的技术计划。如果你所在团队对某些技术有标准化要求,就在这里说清楚。如果你要与已有系统集成,或有合规要求,也都放在这里。你可以要求多套计划方案来对比取舍;如果你提供内部文档,agent 也可以把你们的架构模式直接整合进计划。
任务阶段(Tasks): coding agent 将 spec 与计划拆解成实际工作——小而可审查的任务块,每个只解决拼图中的某一块。每个任务都应当可以被独立实现与测试,这几乎就像是在对你的 AI agent 做测试驱动开发。你不会拿到“构建身份验证”这种笼统任务,而是更具体的条目,例如“创建一个用户注册端点(endpoint),并验证电子邮件格式”。
实现阶段(Implement): coding agent 逐个(或并行)执行任务。你不必审查“上千行代码倾倒”,而是审查为解决特定问题而做的集中改动。agent 清楚要构建什么(spec)、如何构建(plan)、要做什么(task)。关键在于,你要在每个阶段做验证:spec 是否准确表达了你的意图?计划是否考虑了约束条件?AI 是否遗漏了边界情况?这套流程内置了检查点,确保你在继续推进前能及时评估、发现偏差并纠正。
这种门控工作流能防止 Willison 所说的“纸牌屋代码”——经不起审查的、脆弱的 AI 输出。Anthropic 的技能系统(Skills system)也提供了类似模式,让你定义可复用、基于 Markdown 的行为供 agent 调用。把 spec 嵌入这些工作流后,你可以确保 spec 未验证前,agent 不能继续往下走;同时,spec 的更改也会自动传递到任务拆解与测试中。
考虑用 agents.md 定义专门角色: 对于像 GitHub Copilot 这样的工具,你可以创建 agents.md 文件 来定义专门的 agent 角色——用于技术写作的 @docs-agent、用于质量保证的 @test-agent、用于代码审查的 @security-agent。每个文件都充当该角色行为、命令与边界的“专注 spec”。当你希望按任务切换不同 agent,而不是只用一个通用助手时,这会特别有用。
为 Agent Experience (AX) 而设计: 正如我们为开发者体验(developer experience,DX)设计 API 一样,也可以考虑为“Agent Experience”设计 spec。这意味着使用清晰、可解析的格式:agent 将要调用的 API 的 OpenAPI schema、面向 LLM 的文档摘要文件 llms.txt、以及明确的类型定义等。智能体 AI 基金会(AAIF)正在标准化像 MCP(模型上下文协议)这类工具集成协议——遵循这些模式的 spec,更容易被 agent 稳定地理解与执行。
PRD 与 SRS 思维方式: 借鉴成熟的文档实践很有帮助。对于 AI agent spec,你通常会把两者融合到同一份文档中(如上所示),但同时覆盖这两个视角往往更稳。按 PRD 的写法能确保你补齐以用户为中心的上下文(“每个功能背后的原因”),避免 AI 为错误的目标做优化;按 SRS 的写法扩展,则能明确 AI 生成正确代码所需的关键细节(例如用什么数据库、调用什么 API)。很多开发者发现,多做一点前期功夫,能显著减少后续与 agent 的误解成本。
使 spec 成为“活文档”: 不要写完就忘。随着你和 agent 做出决策或发现新信息,及时更新 spec。如果 AI 需要更改数据模型,或你决定砍掉某个功能,需要在 spec 中反映出来,让它始终保持为“基准事实”(ground truth)。把它当作受版本控制的文档。在 spec 驱动的工作流中,spec 会驱动实现、测试与任务拆解;在 spec 验证之前,你不会进入编码阶段。这个习惯能保持项目的一致性,尤其在你或 agent 暂时离开之后再回来时更明显。记住:spec 不仅是写给 AI 的——它也帮助你作为开发者保持监督,并确保 AI 的工作满足真实需求。
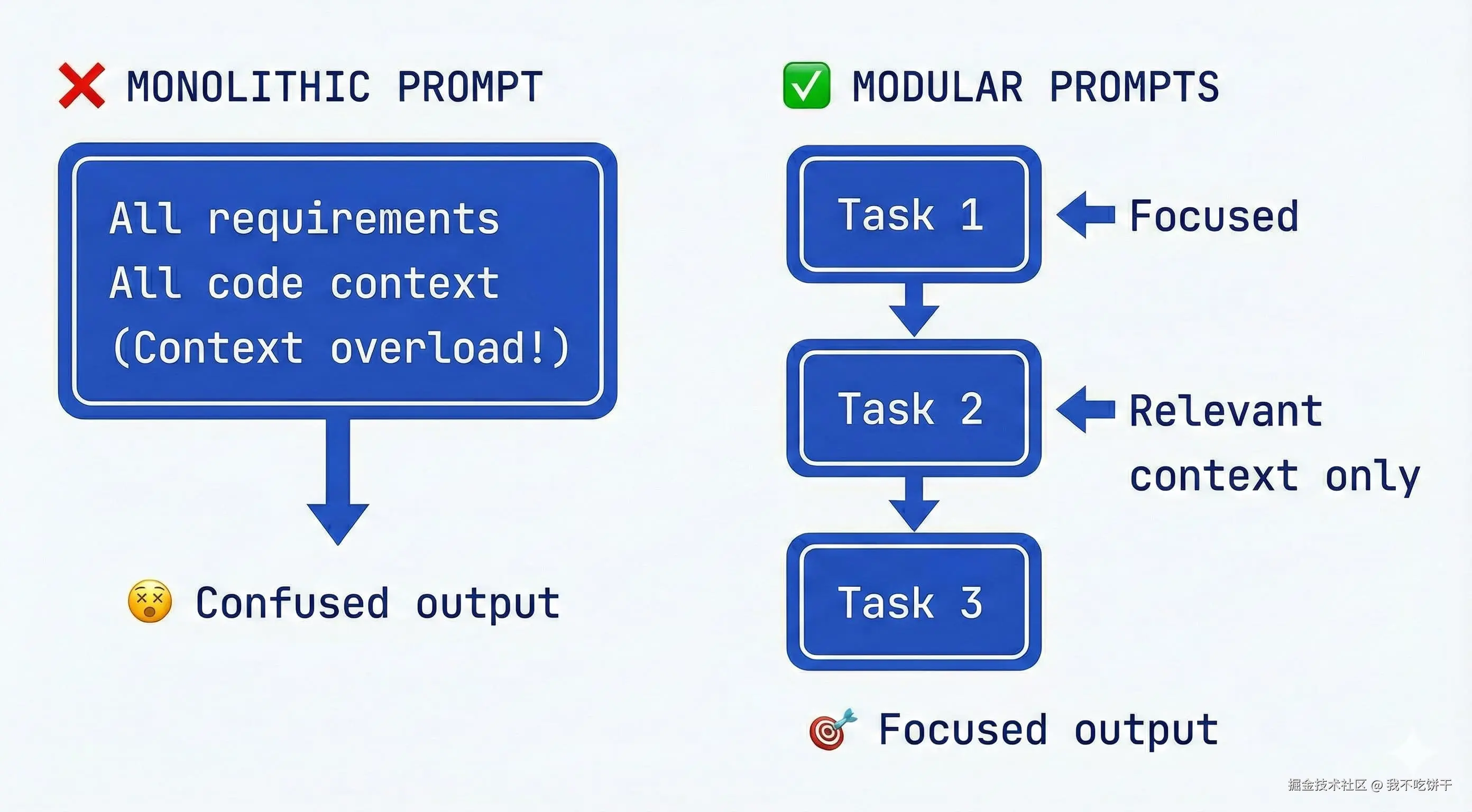
分而治之: 一次给 AI 一个专注的任务,而不是试图用一个包含所有内容的庞大 prompt 把事情“一次说完”。
有经验的 AI 工程师都发现,把整个项目(所有需求、所有代码、所有指令)塞进单个 prompt 或单条 agent 消息,是走向混乱的根源。你不仅容易触发 token 上限,还会因为所谓的 “指令诅咒(curse of instructions)” 而让模型失去焦点——指令太多时,它往往什么都做不好。更好的做法是用模块化的方式设计 spec 和工作流:一次只处理一个部分,只提供这个部分真正需要的上下文。
过多上下文 / 指令的诅咒: 研究验证了许多开发者的观点:当你在 prompt 里堆更多指令 or 数据时,模型对每一条指令的遵守度都会明显下降。一项研究把这叫作“指令诅咒”,表明即使是 GPT-4 和 Claude,在被要求同时满足很多要求时也会吃力。实际操作中,如果你给出 10 条详细规则,AI 往往只会认真遵守前几条,后面的就开始被忽略。更好的策略是“迭代聚焦”:行业指南 建议把复杂需求拆成顺序执行的简单指令作为最佳实践。让 AI 一次只专注于一个子问题,完成之后再继续下一步,这样既能保持质量,又让错误更可控。
将 spec 分为阶段或组件: 如果你的 spec 文档非常长,或者覆盖了很多领域,可以考虑把它拆成若干部分(物理上分成多个文件,或在同一文档中清晰分节)。例如,你可以有“后端 API spec”部分,和“前端 UI spec”部分。AI 在处理后端时,并不需要前端 spec,反之亦然。很多采用多 agent 架构的团队,甚至会为每一部分创建独立的 agent 或子流程——例如,一个 agent 负责数据库 / 模型,另一个负责 API 逻辑,再一个负责前端——每个只拿到与自己相关的 spec。即便你使用单个 agent,也可以通过仅将相关 spec 部分复制到该任务的 prompt 中来模拟这一点。要避免上下文过载:正如 DigitalOcean AI 指南 所提醒的,不要在一个 prompt 里又做身份验证,又改数据库 schema。让每个 prompt 都紧紧围绕一个当前目标。
大型 spec 的扩展目录 / 摘要: 一个很实用的小技巧,是让 agent 为 spec 构建一个“带摘要的扩展目录”。本质上,它就是一份“spec 摘要”,把每个部分压缩成几个关键点或关键词,并标出可以查看详细内容的位置。比如,如果完整 spec 里有一节“安全要求”长达 500 字,你可以让 agent 把它总结成:“安全:使用 HTTPS,保护 API 密钥,实施输入验证(见完整 spec §4.2)”。在规划阶段先做出这样的分层摘要,你就能得到一个可以常驻在 prompt 里的“鸟瞰图”,而细节则在不需要时保持卸载状态。这个扩展目录就像索引:agent 可以先看它,然后说“啊哈,这里有一节安全相关内容需要看看”,接着你再按需提供那一小节的全文。这很像人类开发者看目录、再翻到 spec 文档对应页面的过程。
要实现这一点,你可以在写完 spec 后这样提示 agent:“将上述 spec 总结为一个非常简洁的大纲,包含每个部分的关键点和参考标签。”输出结果很可能是一份分节列表,每节只用一两句话概括。这个摘要可以放在 system / assistant 消息里,既能指导 agent 把注意力放在正确的地方,又不会吃掉太多 token。已知这种分层总结的方式 ,可以通过强化对高层结构的关注,帮助 LLM 维持长期上下文——相当于让 agent 在脑海里携带一份 spec 的“心智地图”。
利用子 agent 或“技能”处理不同 spec 部分: 另一种更高级的方式,是使用多个专门的 agent(Anthropic 称之为 subagent,你也可以理解成“技能”)。每个子 agent 都配置为某个特定领域,并只拿到与该领域相关的那部分 spec。例如,你可以有一个“数据库设计师”子 agent,它只了解数据模型那一节;再有一个“API 开发者”子 agent,只看 API 接口 spec。主 agent(或一个编排器)可以自动把任务路由给合适的子 agent。好处是:每个 agent 要处理的上下文窗口更小,角色更聚焦,这往往能提高准确性,并允许在相互独立的任务上并行工作。Anthropic 的 Claude Code 支持你定义带有自己 system prompt 和工具集的子 agent。正如他们的文档中所说:“每个子 agent 都有特定的目的和专业领域,使用独立于主对话的上下文窗口,并有自定义的 system prompt 指导其行为。” 当出现一个任务恰好属于某个子 agent 的领域时,Claude 可以把任务委托给它,由子 agent 独立返回结果。
并行 agent 提高吞吐量: 同时运行多个 agent,正在成为提升开发者生产力的“下一个大趋势”。与其等一个 agent 干完再开下一个任务,你可以为互不重叠的工作同时启动多个 agent。Willison 把这称作“拥抱并行编码 agent”,并指出这“出奇地高效,虽然精神负担不小”。关键在于合理划分任务边界,避免 agent 相互干扰——比如,一个 agent 写功能代码,另一个写测试,或者不同组件并行开发。像 LangGraph、OpenAI Swarm 这样的编排框架可以帮助协调这些 agent,而通过向量数据库(如 Chroma)这样的共享内存,它们可以访问公共上下文,而不需要冗余 prompt。
单 agent 与多 agent:各自适用在什么时候?
| 维度 | 单 agent | 并行 / 多 agent |
|---|---|---|
| 优势 | 设置更简单;开销更小;更易调试和追踪 | 吞吐量更高;能处理复杂依赖关系;可为不同领域配置专门的 agent |
| 挑战 | 大项目容易上下文过载;迭代较慢;存在单点故障 | 协调开销大;可能出现冲突;需要共享内存(例如向量数据库) |
| 适用场景 | 相对独立的模块;中小型项目;早期原型阶段 | 大型代码库;一人写代码 + 一人写测试 + 一人做评审;彼此独立的功能模块 |
| Tips | 使用 spec 摘要;按任务刷新上下文;在切换大功能时重开会话 | 初期先从 2–3 个 agent 开始;用 MCP 共享工具;提前定义清晰的职责边界 |
在实践中,使用子 agent 或技能特定的提示可能是这样的:你维护多个 spec 文件(或 prompt 模板)——例如 SPEC_backend.md、SPEC_frontend.md —— 然后告诉 AI:“处理后端任务时,参考 SPEC_backend;处理前端任务时,参考 SPEC_frontend。” 或者在 Cursor/Claude 这样的工具中,你实际上会为每个部分启动一个子 agent。这当然比单 agent 循环更复杂,但它模拟了人类开发者的做法 —— 我们在心里会把大型 spec 拆分成相关的块(你不会一次性把整份 50 页的 spec 都记在脑子里;你会回忆当前任务需要的部分,并对整体架构有一个大致了解)。如前所述,挑战在于管理相互依赖关系:子 agent 仍然需要协调(前端需要知道后端 spec 中的 API 约定等)。一个中心概览(或一个 “架构师” agent)可以通过引用子 spec 并确保一致性来提供帮助。
让每个 prompt 专注于一个任务/部分: 即使没有花哨的多 agent 设置,你也可以手动强制模块化。例如,spec 写完后,你的下一步可能是:“步骤 1:实现数据库 schema。”你只给 agent 提供 spec 的数据库部分,加上 spec 中的任何全局约束(如技术栈)。agent 处理这个。然后对于步骤 2,“现在实现身份验证功能”,你提供 spec 的 Auth 部分,如果需要的话,可能还提供 schema 的相关部分。通过为每个主要任务刷新上下文,你确保模型不会携带大量可能分散注意力的过时或无关信息。正如一份指南所建议的:“重新开始:在切换主要功能时开始新会话以清除上下文”。你可以在每次都提醒 agent 关键的全局规则(来自 spec 的约束部分),但如果不需要,就不要把整个 spec 都塞进去。
使用内联指令和代码 TODO: 另一个模块化技巧是将你的代码或 spec 作为对话的活跃部分。例如,用 // TODO 注释搭建代码框架,描述需要完成的内容,然后让 agent 逐一填充。每个 TODO 本质上都是一个小任务的迷你 spec。这让 AI 保持激光般的专注(“根据这个 spec 片段实现这个特定函数”),你可以在紧密循环中迭代。这类似于给 AI 一个待办清单项来完成,而不是一次性给出整个清单。
总结:小而聚焦的上下文胜过一个大 prompt。这提高了质量,并防止 AI 因一次性接收太多信息而“不堪重负”。正如一套最佳实践所总结的,向模型提供 “单一任务聚焦” 和 “仅提供相关信息”,避免到处倾倒所有内容。通过将工作构建成模块——并使用 spec 摘要或子 spec agent 等策略——你将绕过上下文大小限制和 AI 的短期记忆上限。记住,一个“喂得好”的 AI 就像一个“喂得好”的函数:只给它 手头工作所需的输入。
让你的 spec 不仅是 agent 的待办清单,也是质量控制的指南,不要害怕注入你自己的专业知识。
一份好的 AI agent spec 会预判 AI 可能出错的地方,并设置防护栏。它还会利用你所知道的知识(领域知识、边界情况、“陷阱”)让 AI 不会在真空中操作。把 spec 想象成 AI 的教练和裁判:它应该鼓励正确的方法,并指出犯规。
使用三层边界: GitHub 对 2,500+ 个 agent 文件的分析 发现,最有效的 spec 使用三层边界系统,而不是简单的禁止事项列表。这为 agent 提供了更清晰的指导来说明何时继续、何时暂停、何时停止:
总是要做: agent 应该无需询问就执行的操作。“提交前总是运行测试。”“总是遵循风格指南中的命名约定。”“总是将错误记录到监控服务。”
️ 先询问: 需要人工批准的操作。“修改数据库 schema 前先询问。”“添加新依赖前先询问。”“更改 CI/CD 配置前先询问。”这一层捕获那些可能没问题但需要人工检查的高影响变更。
永远不要做: 硬性停止。“永远不要提交密码或 API 密钥。”“永远不要编辑 node_modules/ 或 vendor/。”“永远不要在未经明确批准的情况下删除失败的测试。”“永远不要提交密钥”是研究中最常见、也最有用的约束。
这种三层方法比扁平化的规则列表更加细致。它阐明有些操作总是安全的,有些需要监督,有些则完全禁止。agent 可以自信地执行“总是要做”的项目,标记“先询问”的项目以供审查,并在“永远不要做”的项目上硬性停止。
鼓励自检: 一个强大的模式是让 agent 自动对照 spec 验证其工作。如果你的工具允许,可以集成单元测试或 lint 检查,让 AI 在生成代码后运行。但即使在 spec/prompt 层面,你也可以指示 AI 进行二次检查:例如“实现后,将结果与 spec 进行比较,确认所有要求都已满足。列出任何未处理的 spec 项。”这推动 LLM 反思其输出相对于 spec 的情况,捕获遗漏。这是内置在流程中的一种自我审计形式。
例如,你可以在 prompt 末尾添加:“(编写函数后,回顾上述需求列表,确保每一项都得到满足,标记任何缺失的项)。”然后模型会(理想情况下)输出代码,后跟一个简短的检查清单,说明是否满足每个要求。这降低了它在运行测试之前就忘记某些内容的可能性。这不是万无一失的,但确实有帮助。
使用 LLM-as-a-Judge 进行主观检查: 对于难以自动测试的标准——代码风格、可读性、对架构模式的遵循——考虑使用“LLM-as-a-Judge(LLM 作为裁判)”。这意味着让第二个 agent(或单独的 prompt)根据你的 spec 质量指南审查第一个 agent 的输出。Anthropic 和其他公司发现这对主观评估很有效。你可以这样写 prompt:“审查这段代码是否符合我们的风格指南。标记任何违规行为。” 裁判 agent 返回反馈,要么被接受,要么触发修改。这在语法检查之外增加了一层语义评估。
一致性测试: Willison 主张构建一致性测试套件——任何实现都必须通过的独立于语言的测试(通常基于 YAML)。这些测试充当契约:如果你正在构建 API,一致性测试套件指定预期的输入/输出,agent 的代码必须满足所有测试 case。这比临时单元测试更严格,因为它直接来自 spec 并且可以复用于不同实现。在你的 spec 的“成功标准”部分包含一致性测试标准(例如,“必须通过 conformance/api-tests.yaml 中的所有测试用例”)。
在 spec 中利用测试: 如果可能,在 spec 和 prompt 流程中纳入测试计划甚至实际测试代码。在传统开发中,我们使用 TDD 或编写测试用例来明确需求——你可以对 AI 做同样的事情。例如,在你的 spec 的“成功标准”中,你可以说“这些示例输入应该产生这些输出……”或“以下单元测试应该通过”。可以提示 agent 在脑海中运行这些用例,或者如果它有这种能力直接执行用例。Simon Willison 指出,拥有强大的测试套件就像给 agent 超能力——当测试失败时,它们可以快速验证和迭代。在 AI 编码上下文中,在 spec 中为测试或预期结果编写一些伪代码可以指导 agent 的实现。此外,你可以在子 agent 设置中使用专门的“测试 agent”,它根据 spec 的标准并持续验证“编码 agent”的输出。
注入你的领域知识: 你的 spec 应该体现只有经验丰富的开发者或了解上下文的人才会知道的见解。例如,如果你正在构建一个电商 agent,并且你知道“产品”和“类别”具有多对多关系,请明确说明(不要假设 AI 会推断出来——它可能不会)。如果某个库特别棘手,请提及要避免的陷阱。本质上是把你的指导注入到 spec 中。spec 可以包含这样的建议:“如果使用库 X,请注意版本 Y 中的内存泄漏问题(应用解决方案 Z)。”这种详细程度是将普通的 AI 输出转变为真正健壮解决方案的关键,因为你已经引导 AI 远离常见陷阱。
另外,如果你有偏好或风格指南(比如,“在 React 中使用函数组件而不是类组件”),将其编码到 spec 中。然后 AI 会模仿你的风格。许多工程师甚至在 spec 中包含小例子,例如,“所有 API 响应都应该是 JSON。例如,错误时使用 {"error": "message"}。”通过给出简单示例,将 AI 锚定到你想要的精确格式。
简单任务的极简主义: 虽然我们提倡详尽的 spec,但专业知识也包括懂得何时保持简洁。对于相对简单、孤立的任务,繁琐的 spec 实际上可能造成困惑而非帮助。若你让 agent 做直接明了的事(如"在页面上居中一个 div"),你可能只需要说,“确保解决方案简洁,不要添加多余的标记或样式。” 不需要完整的 PRD。相反,对于复杂的任务(比如“实现带有令牌刷新和错误处理的 OAuth 流程”),才是你详细编写 spec 的时候。一个好的经验法则是:根据任务复杂度调整 spec 详细程度。不要对困难问题 spec 不足(agent 会失败或偏离轨道),但也不要对琐碎问题过度 spec(agent 可能会被纠缠或在不必要的指令上消耗上下文)。
如需要,保持 AI 的“人设”: 有时,你的 spec 的一部分是定义 agent 应该如何行为或响应,尤其当 agent 与用户交互时。例如,如果构建客户支持 agent,你的 spec 可能包含这样的指导原则:“使用友好和专业的语气”,“如果你不知道答案,寻求解释或提供后续跟进,而不是猜测。” 这类规则(通常包含在 system prompt 中)有助于保持 AI 的输出与期望一致。它们本质上是 AI 行为的 spec 项。保持它们一致,并在长会话中需要时提醒模型(如果不加以约束,LLM 的风格可能会随时间“漂移”)。
你仍然是循环中的执行者: spec 赋予 agent 权力,但你仍然是最终的质量过滤器。如果 agent 产生了技术上符合 spec 但感觉不对的东西,相信你的判断。要么完善 spec,要么直接调整输出。AI agent 的优点是它们不会感到冒犯——如果它们交付了一个偏离预期的设计,你可以说,“实际上,这不是我的本意,让我们明确 spec 并重做。”spec 是与 AI 协作的活文档,而不是你不能更改的一次性合同。
Simon Willison 幽默地将与 AI agent 合作比作“一种非常奇怪的管理形式”,甚至“从编码 agent 中获得良好结果感觉与管理人类实习生非常接近”。你需要提供清晰的指令(spec),确保它们有必要的上下文(spec 和相关信息),并给出可操作的反馈。spec 设定了舞台,但执行过程中的监督和反馈是关键。如果 AI 是“一个非常奇怪的数字实习生,如果你给它机会,它绝对会作弊”,那么你编写的 spec 和约束就是如何防止这种作弊并让它们专注于任务。
这就是回报:一个好的 spec 不仅告诉 AI 要构建什么,还帮助它自我纠正并保持在安全边界内。通过融入验证步骤、约束和你来之不易的知识,你大大增加了 agent 的输出在第一次尝试时就正确(或至少更接近正确)的可能性。这减少了迭代和那些“它到底为什么要那样做?”的时刻。
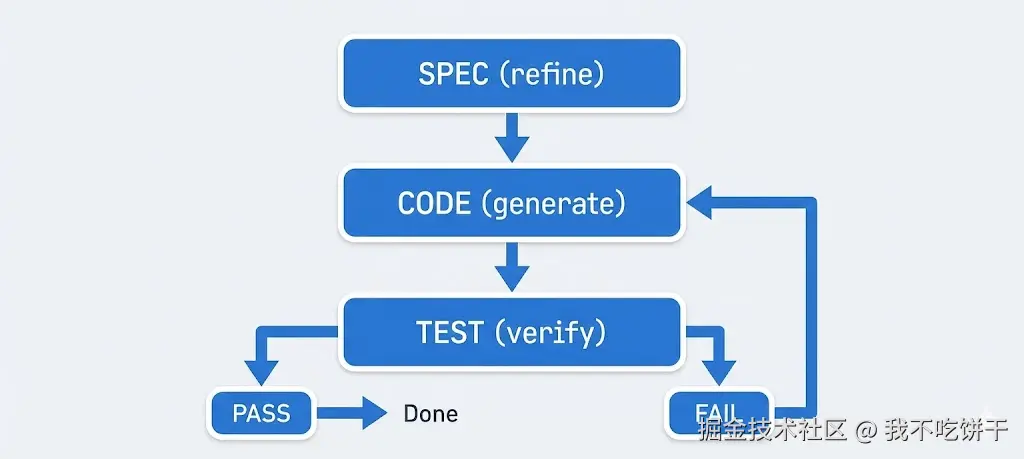
将 spec 编写和 agent 构建视为迭代循环:尽早测试,收集反馈,完善 spec,并利用工具自动化检查。
初始的 spec 不是终点——它是一个循环的开始。持续根据 spec 验证 agent 的工作并相应调整才会获得最佳结果。此外,现代 AI 开发者使用各种工具来支持这一过程(从 CI 流水线到上下文管理工具)。
持续测试: 不要等到最后才看 agent 是否满足 spec。在每个主要里程碑之后,甚至每个函数之后,运行测试或至少进行快速手动检查。如果出现失败,在继续之前更新 spec 或 prompt。例如,如果 spec 说“密码必须用 bcrypt 哈希”,而你看到 agent 的代码存储明文——停下来纠正它(并在 spec 或 prompt 中提醒该规则)。自动化测试在这里大放异彩:如果你提供了测试(或边做边写),让 agent 运行它们。在许多 coding agent 设置中,你可以让 agent 在完成任务后运行 npm test 或类似命令。结果(失败)可以反馈到下一个 prompt 中,有效地告诉 agent“你的输出在 X、Y、Z 上不符合 spec——修复它。”这种 agent 循环(代码 -> 测试 -> 修复 -> 重复)非常强大,这正是像 Claude Code 或 Copilot Labs 等工具进化以处理更大任务的方式。始终定义“完成”的含义(通过测试或标准)并进行检查。
迭代 spec 本身: 如果你发现 spec 不完整或不清楚(也许 agent 误解了某些内容,或者你意识到遗漏了一个需求),更新 spec 文档。然后明确地将 agent 与新 spec 重新同步:“我已按如下方式更新了 spec……根据更新的 spec,相应地调整计划或重构代码。”这样 spec 仍然是唯一的真理来源。这类似于我们在正常开发中处理需求变更的方式——但在这种情况下,你也是 AI agent 的产品经理。如果可能,保留版本历史(即使只是通过commit消息或笔记),这样你就知道发生了什么变化以及为什么。
利用上下文管理和记忆工具: 不断增长的工具生态可以帮助你管理 AI agent 的上下文和知识。例如,检索增强生成(RAG)是一种模式,agent 可以即时从知识库(如向量数据库)中提取相关数据块。如果你的 spec 很大,你可以嵌入其中的部分,让 agent 在需要时检索最相关的部分,而不是总是提供整个内容。还有一些框架实现了模型上下文协议(MCP),它根据当前任务自动向模型提供正确的上下文。一个例子是 Context7 (context7.com),它可以根据你正在处理的内容自动从文档中获取相关的上下文片段。实际上,这可能意味着 agent 注意到你正在处理“支付处理”,它会将 spec 或文档的“支付”部分拉入提示中。考虑采用这些工具,或者至少设置一个基础版本(即使只是在 spec 文档中进行简单搜索)。
谨慎并行化: 一些开发者在不同任务上并行运行多个 agent 实例(如前面提到的 subagent)。这可以加快开发速度——例如,一个 agent 生成代码,而另一个同时编写测试,或者两个功能同时构建。如果你采用这种方式,确保任务真正独立或明确分离以避免冲突(spec 应注明任何依赖关系)。例如,不要让两个 agent 同时写入同一个文件。一种工作流程是让一个 agent 生成代码,另一个并行审查它,或者构建单独的组件以便以后集成。这是高级用法,管理起来可能在精神上很累(正如 Willison 承认的,运行多个 agent 出奇地有效,尽管在精神上令人疲惫!)。最多从 2-3 个 agent 开始,以保持可管理性。
版本控制和 spec 锁定: 使用 Git 或你选择的版本控制来跟踪 agent 的操作。良好的版本控制习惯在 AI 辅助下更为重要。将 spec 文件本身提交到仓库。这不仅保留了历史记录,agent 甚至可以使用 git diff 或 blame 来理解变化(LLM 非常擅长阅读差异)。一些高级 agent 设置让 agent 查询版本控制系统历史以查看某些内容何时引入——令人惊讶的是,模型“在 Git 方面非常胜任”。通过将 spec 保存在仓库中,可以让你和 AI 都跟踪变化。有一些工具(如前面提到的 GitHub Spec Kit)将 spec 驱动开发集成到 git 工作流中——例如,在更新 spec 时限制合并或从 spec 项生成检查清单。虽然你不需要这些工具就能成功,但重点是像对待代码一样对待 spec——认真维护它。
成本和速度考虑: 使用大型模型和长上下文可能既慢又贵。一个实用的技巧是巧妙地使用模型选择和批处理。也许使用更便宜/更快的模型进行初始草稿或重复,并将最强大(和昂贵)的模型保留用于最终输出或复杂推理。一些开发者使用 GPT-4 或 Claude 进行规划和关键步骤,但将更简单的扩展或重构应用在本地模型或较小的 API 模型。如果使用多个 agent,也许不是所有 agent 都需要顶级;运行测试的 agent 或代码检查 agent 可以是较小的模型。还要考虑限制上下文大小:如果 5k 就够了,就不要提供 20k token。正如我们讨论的,更多 token 可能意味着收益递减。
监控并记录一切: 在复杂的 agent 工作流中,记录 agent 的操作和输出至关重要。检查日志以查看 agent 是否偏离或遇到错误。许多框架提供跟踪日志或允许打印 agent 的思考链(特别是如果你提示它逐步思考)。审查这些日志可以突出显示 spec 或指令可能被误解的地方。这与调试程序没什么不同——只是“程序”是对话/提示链。如果发生奇怪的事情,回到 spec/指令看看是否存在歧义。
学习和改进: 最后,将每个项目视为完善 spec 编写技能的学习机会。也许你会发现某种措辞总是让 AI 困惑,或者以某种方式组织 spec 部分会产生更好的遵守性。将这些经验教训融入下一个 spec。AI agent 领域正在快速发展,因此新的最佳实践(和工具)不断涌现。通过博客(如 Simon Willison、Andrej Karpathy 等)保持更新,不要犹豫去实验。
为 AI agent 编写的 spec 不是“写一次就完成”。它是指导、验证和完善的持续循环的一部分。这种勤奋的回报是巨大的:通过尽早发现问题并保持 agent 对齐,你可以避免后期昂贵的重写或失败。正如一位 AI 工程师打趣说,使用这些实践可以感觉像拥有“一支实习生军队”为你工作,但你必须好好管理他们。一个良好的、持续维护的 spec 就是你的管理工具。
在结束之前,值得指出的是,即使是善意的 spec 驱动工作流,也可能会脱轨的错误模式。GitHub 对 2,500 多个 agent 文件的研究 揭示了一个明显的分歧:“大多数 agent 文件失败是因为它们太模糊。”以下是要避免的错误:
模糊的 prompt: “给我构建一些酷的东西”或“让它工作得更好”没有给 agent 任何可以依靠的东西。正如 Baptiste Studer 所说:“模糊的 prompt 意味着错误的结果。”对输入、输出和约束要具体。“你是一个有用的编码助手”不起作用。“你是一名为 React 组件编写测试的测试工程师,遵循这些示例,永远不修改源代码”才有效。
过长的上下文而没有总结: 将 50 页文档扔进 prompt 中并希望模型能理解,这很少奏效。使用分层摘要(如原则 3 中讨论的)或 RAG 仅呈现相关内容。上下文长度不能替代上下文质量。
跳过人工审查: Willison 有一个个人规则:“我不会提交我无法向别人解释的代码。” 这因为 agent 生成的东西通过了测试,并不意味着它是正确的、安全的或可维护的。始终审查关键代码路径。“纸牌屋”的比喻适用:AI 生成的代码可能看起来很稳固,但在你没有测试的边缘情况下会崩溃。
将vibe coding与生产工程混为一谈: 使用 AI 进行快速原型设计(“vibe coding,氛围编程”)对于探索和一次性项目很好。但在没有严格 spec、测试和审查的情况下将该代码发布到生产环境是自找麻烦。我区分“vibe coding”和“AI 辅助工程”——后者需要本指南描述的纪律。知道你处于哪种模式。
忽视“致命三要素”: Willison 警告三个使 AI agent 危险的属性:速度(它们工作得比你审查得快)、非确定性(相同输入,不同输出)和成本(鼓励在验证上偷工减料)。你的 spec 和审查流程必须考虑所有三个因素。不要让速度超过你的验证能力。
遗漏六个核心领域: 如果你的 spec 没有涵盖命令、测试、项目结构、代码风格、git 工作流和边界条件,你可能遗漏了 agent 需要的东西。在交给 agent 之前,使用第 2 节的六领域检查清单作为健全性检查。
为 AI 编码 agent 编写有效的 spec 需要扎实的软件工程原则,结合对大语言模型(LLM)特性的适应。从明确的目标开始,让 AI 帮助扩展计划。像严肃的设计文档那样构建 spec —— 涵盖六个核心领域,并将其集成到你的工具链中,使其成为可执行的产出物,而不仅仅是文字。通过一次向 agent 提供一块拼图来保持其焦点紧密(并考虑使用巧妙的策略,如摘要目录、子 agent 或并行编排来处理大型 spec)。通过包含三层边界(始终/先询问/永不)、自我检查和一致性测试来预防陷阱——本质上,是教 AI 如何不失败。并将整个过程视为迭代的:使用测试和反馈持续完善 spec 和代码。
遵循这些指南,你的 AI agent 在大型上下文下“崩溃”或偏离到无意义内容的可能性将大大降低。
祝 spec 编写愉快!

