
疯狂餐厅
86.88M · 2026-03-21

本文整理自快手高级计算引擎研发工程师 周思闽 在 Doris Summit 2025 中的演讲内容,并以演讲者第一视角进行叙述。
快手是国内日活过亿的短视频平台,其广告投放平台是商业化外部广告主与快手电商商家进行广告投放的主要阵地,支持客户在平台上进行广告物料搭建、物料管理、策略变更、数据查看等操作,这对底层数据系统的存储、计算与查询性能提出了极高要求。
要支撑如此大规模的广告投放与实时分析,底层数据架构面临巨大挑战。当前,快手的广告数据包括:由投放系统产生的物料数据以及用于数据分析的效果数据,这些数据呈现出三个显著特征:
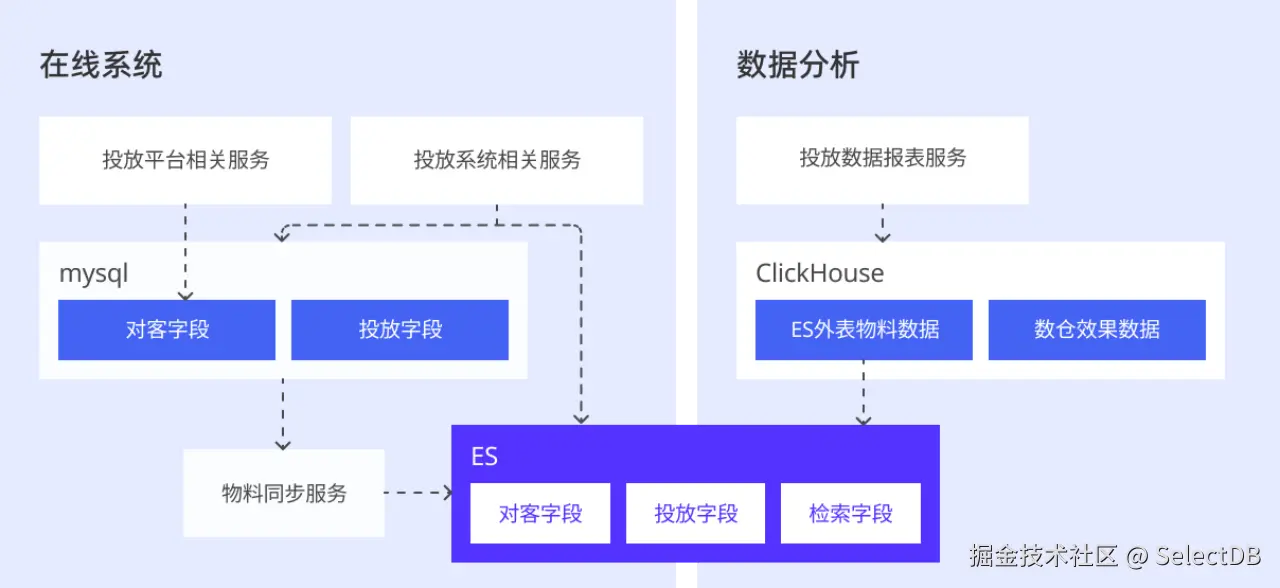
早期存储架构中,物料数据由 MySQL、Elasticsearch 协同存储;效果数据主要存储与 Clickhouse 中。
数据分析时,将分散在 MySQL、Elasticsearch 中的物料数据与 ClickHouse 中的效果数据进行高效关联查询,从而为广告主提供完整、及时的投放效果洞察。
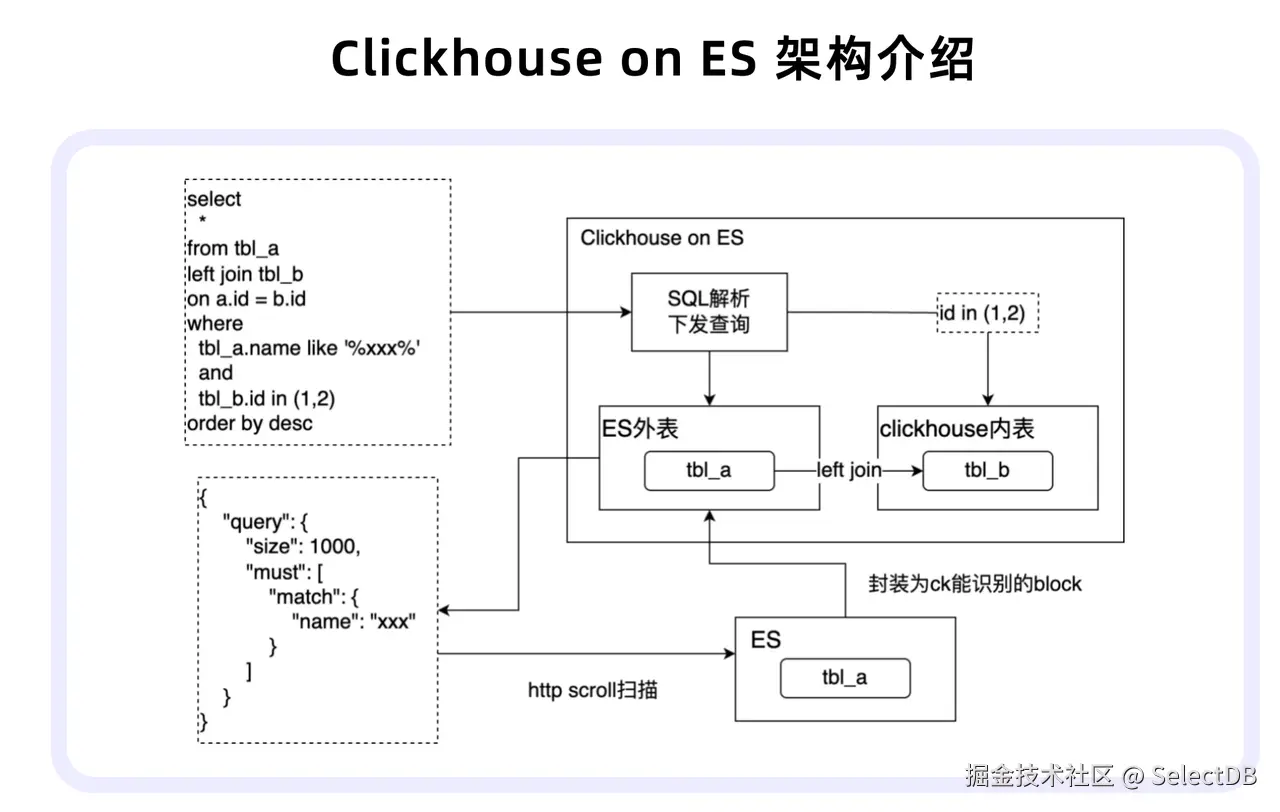
在如上所说的 ClickHouse on ES 架构中,用户提交的查询通常包含 Elasticsearch 外表(a)与 ClickHouse 内表(b)。ClickHouse 会解析查询中外表部分,将其转换为 Elasticsearch 查询语句,通过 HTTP 请求获取数据并封装为 Block,最后在引擎内部完成与内表的关联计算。
然而,随着 Elasticsearch 中数据量持续增长,该架构逐渐暴露诸多问题:
基于上述问题及挑战,我们为新架构设定了明确目标:
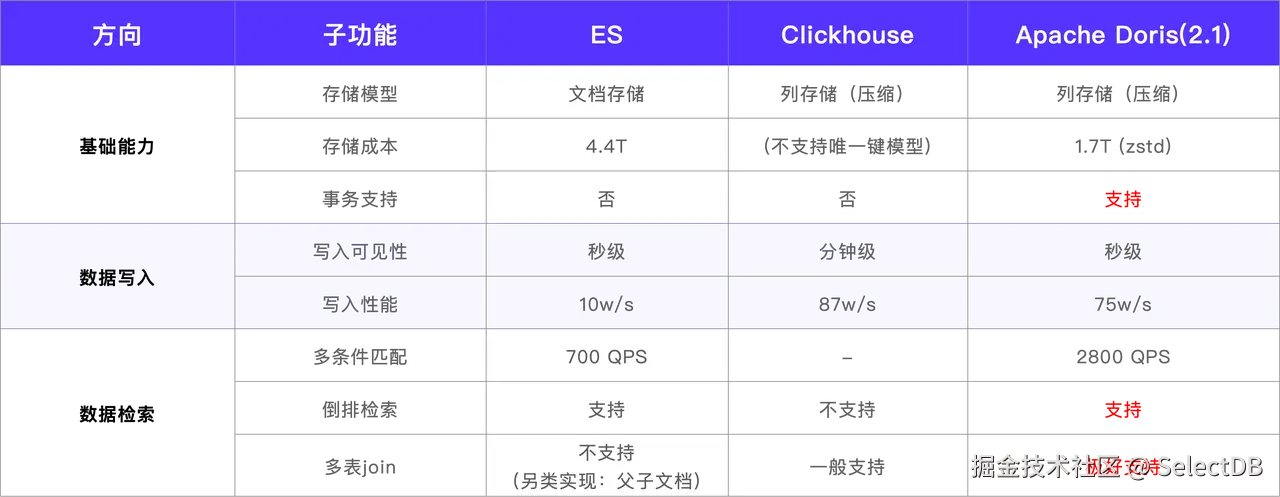
基于以上目标,我们对 Apache Doris、ClickHouse、Elasticsearch 等主流 OLAP 引擎进行了全面的调研与性能压测。测试涵盖了写入吞吐、查询延迟、存储压缩率、全文检索性能等关键维度。
在这过程中,ClickHouse 首先被排除,因其不支持唯一键模型,而广告物料数据存在大量更新场景,要求引擎具备主键更新能力。因此,重点在 Elasticsearch 与 Apache Doris 之间进行对比。
综合测试结果,Apache Doris 在写入性能、查询效率、存储成本及运维复杂度等方面均表现优异,不仅能够满足既定架构目标,还在多个场景下显著优于 Elasticsearch。因此,我们最终选定 Apache Doris 作为下一代广告数据分析引擎。
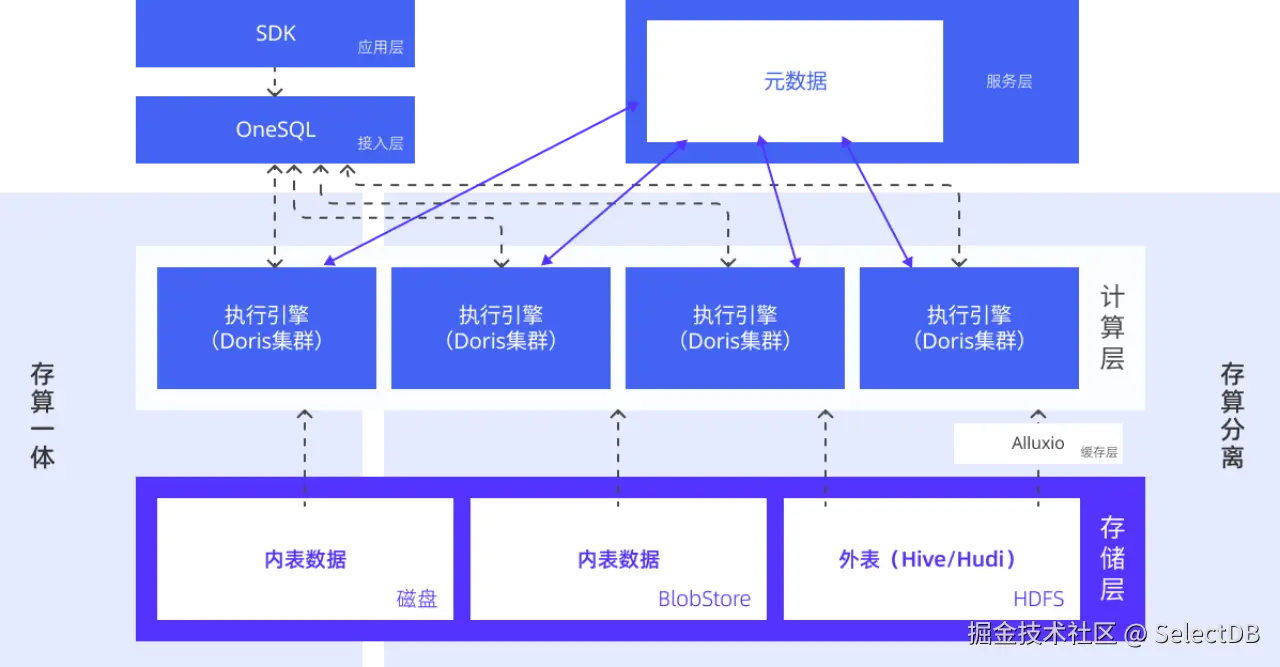
在实际应用中,我们引入 Apache Doris(计算引擎) 替换了原先架构中的 Elasticsearch、ClickHouse,设计了统一分析引擎 Bleem。通过在外部表模块中引入数据缓存层与元数据服务层,有效提升了跨源查询效率,使数据湖外表的查询性能接近内表水平,实现了关键的性能突破。
具体来看,Bleem 架构自下而上分为 5 层:
依托 Doris 强大的 OLAP 计算与湖仓一体能力,将此前分散的数据湖分析、实时 OLAP 查询、在线报表及全文检索等多种场景,统一整合至同一套引擎架构中,实现了技术栈的收敛与提效。该架构在实际落地中已带来显著收益:
整个迁移过程分为三个阶段,稳步推进以确保业务平稳过渡:
在架构升级及迁移过程中,我们收获了许多实践及优化经验,在此逐一分享。
在数据导入层面,我们基于 SeaTunnel 实现流式数据同步,该方式支持批处理场景下的 Overwrite 语义,所有导入均采用两阶段提交机制,以确保数据同步的最终一致性。
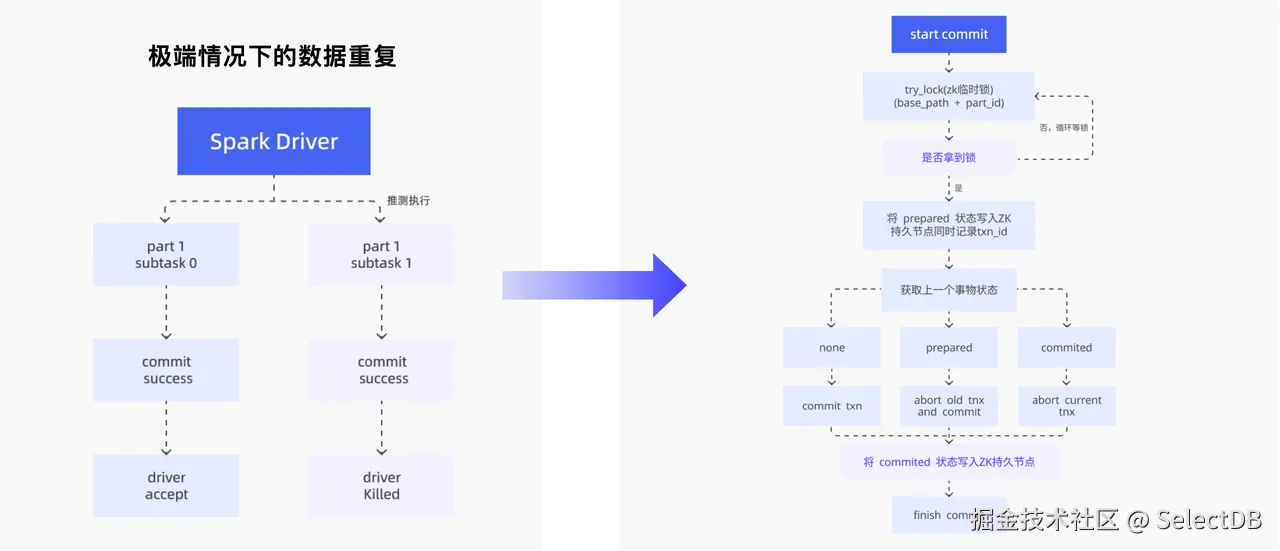
而在基于 SeaTunnel 和 Spark 的数据同步过程中,我们遇到了极端场景下的数据重复问题。主要有两种情况:
为解决该问题,我们在 Doris 的两阶段事务提交环节引入了 ZooKeeper 分布式锁机制,通过记录并校验事务状态来保证批同步的一致性。具体流程如下:
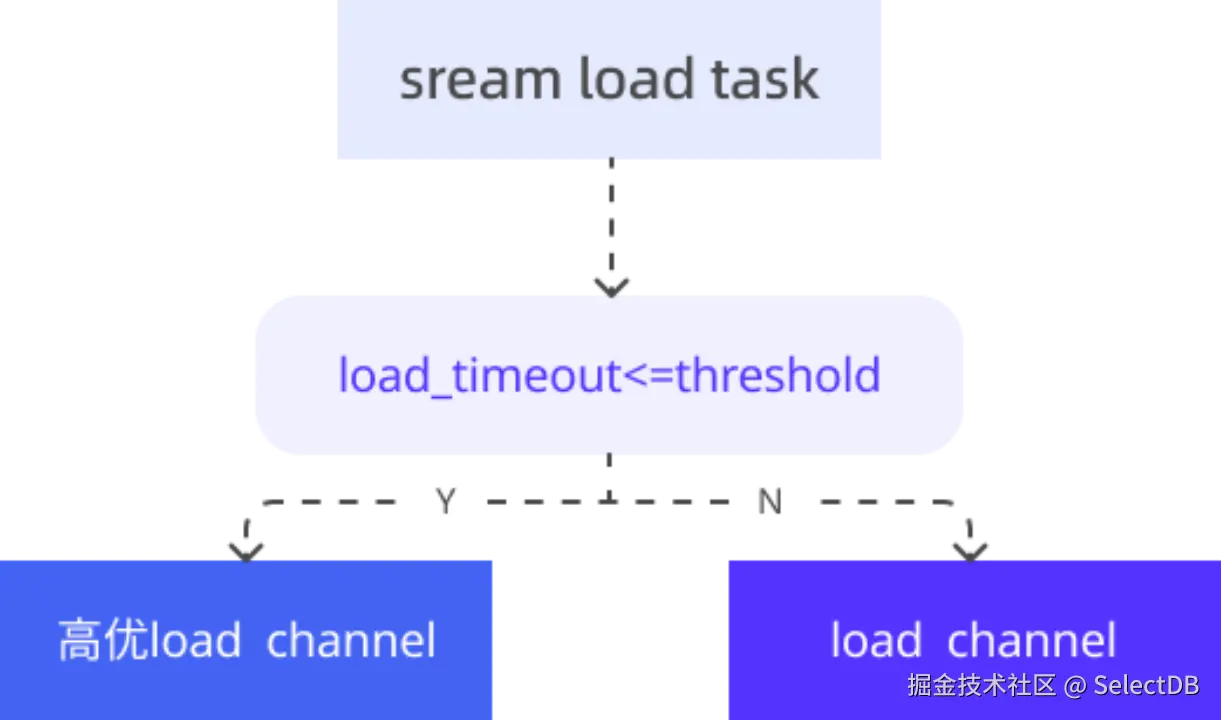
为应对高并发数据导入,我们对 Apache Doris 的 Stream Load 机制进行了调优。通过合理配置任务优先级与合并(Compaction)参数,显著提升了写入吞吐与稳定性。Doris 内部通过 Load Channel 进行任务调度,以区分高优与普通优先级通道。
调优的核心在于合理配置相关参数,例如当 Stream Load 任务指定的 timeout 时间小于 300 秒时,系统会将其判定为高优任务并分配至高优通道。参数优化如下:
load_task_high_priority_threshold_second=300
compaction_task_num_per_fast_disk=16
max_base_compaction_threads=8
max_cumu_compaction_threads=8
OLAP 引擎的查询性能很大程度上取决于表结构设计。因此,我们针对不同业务场景制定了差异化的建表策略:
物料表(高频更新与大规模检索):该表数据量极大且需支持实时更新。业务查询主要基于 account_id 进行过滤,而非原 MySQL 的自增 ID。为充分发挥 Doris 前缀索引与排序键的优势,在保证业务逻辑等价的前提下,我们将 account_id 与 id 组合为联合主键,并将account_id 设为首个排序键及分桶字段,大幅提升查询过滤效率。同时配置倒排索引以支持多维检索,并选用 ZSTD 压缩算法平衡存储与 IO 性能。
-- 建表语句参考
CREATE TABLE ad_core_winfo
(account_id BIGINT NOT NULL,
id BIGINT NOT NULL,
word STRING,
INDEX idx_word (`word`) USING INVERTED...)
UNIQUE KEY(account_id,id)
DISTRIBUTED BY HASH(account_id) BUCKETS 1000;
效果表(多维聚合分析): 相较于物料表,效果表侧重于数仓指标的累加与聚合。因此,我们直接采用聚合模型,并按照“天”或“小时”粒度设置分区。
-- 建表语句参考
CREATE TABLE ad_dsp_report
(__time DATETIME,
account_id BIGINT, ...
`ad_dsp_cost` BIGINT SUM,
...)
AGG KEY(__time,account_id,...)
AUTO PARTITION BY RANGE(date_trunc(`__time`,'hour'))()
DISTRIBUTED BY HASH(account_id) BUCKETS 2;
在数据压测中,我们发现不同 Account ID 对应的数据量差异极大,小至个位数、大至百万级别,导致 BE 节点 CPU 负载严重不均。通过 SHOW DATA SKEW 命令进一步确认,Tablet 存储分布明显倾斜:大 Tablet 占用空间达 3–4 GB,小 Tablet 仅 100-200 MB,且大账户查询延迟较高。为此,我们实施了以下两点优化:
A:按账户范围进行分区
经分析,Account ID 为 5–8 位数字,且未来不会超过 10 位。因此使用 FROM_UNIXTIME 函数将 Account ID 转换为 Datetime 类型,按月对历史数据进行分区,共划分出 33 个历史分区。每个分区可容纳 2,592,000 个 Account ID,后续每新增约 200 多万个 Account ID 才会新增一个月份分区。同时,针对历史分区,根据数据存量进行手动分桶,新分区则默认设置为 256 个分桶。
该方案通过分区裁剪有效过滤了大量无关数据,同时为未来数据膨胀预留了扩展空间(物料表日均增量约 3 亿),显著降低分区增长对查询性能的影响。
B:对 Account ID 进行二次哈希
为缓解单个 Account ID 数据量差异过大导致的分布不均,我们选取与 Account ID 无关的 ID 字段,通过 ID MOD 7 计算得到一个取值在 0~6 之间的 mod 字段。将原本仅基于 account_id 的哈希分桶键调整为 (account_id, mod) 联合键,从而将同一 Account ID 的数据分散到 7 个 BE 节点上。
优化后,各 Tablet 大小基本均衡稳定在 1GB 左右,数据存储与查询负载得以在多个 BE 间均匀分布,有效解决了 此前 CPU 负载不均的问题。
当分区数量达到万级别时,简单点查 SQL 的耗时达到 250 毫秒,远超 100 毫秒的预期。通过分析,耗时主要集中在 Plan 阶段,原因是 Doris(2.1 版本)在分区裁剪时,会遍历所有分区进行匹配,万级分区的顺序遍历开销巨大。
为此,我们将顺序遍历改为二分查找:对万级分区先进行排序,再利用二分查找快速定位目标分区,将时间复杂度从 O(n) 降至 O(log n)。优化后,该查询耗时从 250 毫秒降至 12 毫秒,性能提升超过 20 倍。目前,二分查找已在 Doris 3.1 版本中实现。
在查询优化过程中,我们发现:多数查询经过条件过滤后,实际命中的数据量并不大,即便在大账户场景下,命中数据量也仅在百万级别。然而,Profile 显示这类查询的 Total Instance 数高达 800 个,其默认并发数为 32,存在明显的过度并发。
为此,我们调整以下参数降低并发开销:
set global parallel_exchange_instance_num=5;
set global parallel_pipeline_task_num=2;
调整后,同一查询的 Total Instance 数量降至 17 个,查询耗时也显著缩短。这说明在小数据量点查场景下,适当降低并发可有效减少 RPC 开销,从而降低延迟(220ms 降至 147ms)。同时,这一优化也提升了系统的整体 QPS 承载能力。
经过上述架构迁移与深度优化,我们在三个核心维度取得了显著收益:
未来,我们将深度探索 Apache Doris ,重点围绕两方面展开:
本文完。您还可以阅读来自快手另一篇实践案以及中通快递、小米集团、顺丰科技用户故事来了解湖仓分析。

