疯狂餐厅
86.88M · 2026-03-21


欢迎来到 Apache SeaTunnel 的世界!这份文档旨在帮助新手快速了解 SeaTunnel 的核心功能、基本架构,并完成第一个数据同步任务。
Apache SeaTunnel 是一个非常易于使用、高性能、支持实时流式和离线批处理的海量数据集成平台。它的目标是解决常见的数据集成问题,如数据源多样性、同步场景复杂性以及资源消耗高的问题。
SeaTunnel 采用了解耦的设计架构,Source、Transform、Sink 插件与具体的执行引擎(Engine)是分离的。
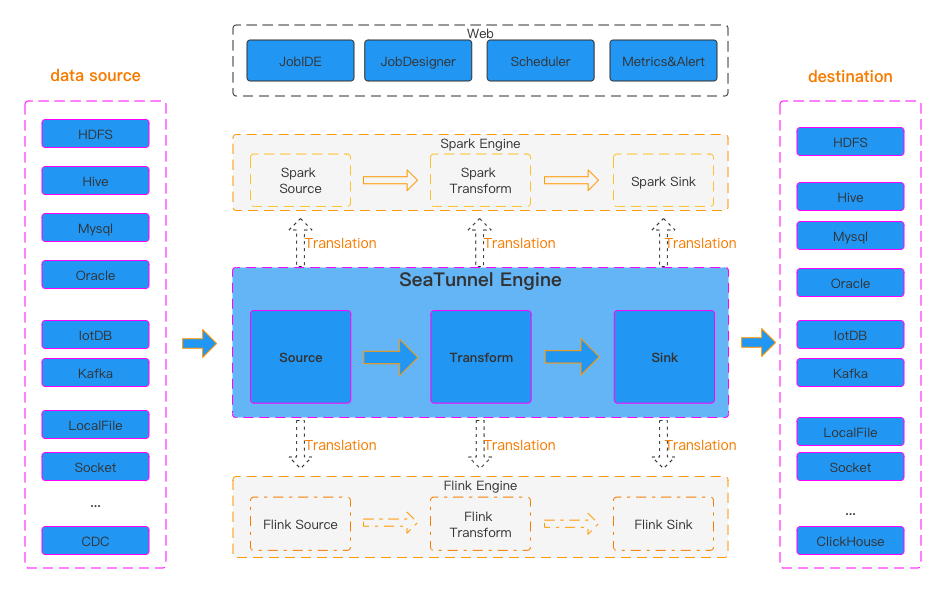
SeaTunnel 基于 Java 开发,理论上支持所有安装了 JDK 的操作系统。
| 操作系统 | 适用场景 | 说明 |
|---|---|---|
| Linux (CentOS, Ubuntu, etc.) | 生产环境 (推荐) | 稳定性高,适合长期运行服务。 |
| macOS | 开发/测试 | 适合开发者本地调试和编写 Config。 |
在开始安装 SeaTunnel 之前,请确保你的环境满足以下要求:
java -version 检查。JAVA_HOME 环境变量。在使用 SeaTunnel 之前,深入理解其核心组件的内部机制有助于你更好地调优和排查问题。
Source 负责从外部系统读取数据,并将其转换为 SeaTunnel 内部的行格式(SeaTunnelRow)。
partition_column 的最大值和最小值计算出多个查询范围(Splits)。Transform 负责在数据从 Source 流向 Sink 的过程中对数据进行处理。
Sql, Filter, Replace)是无状态的,即处理当前行不需要依赖其他行的数据。Sink 负责将 SeaTunnel 处理后的数据写入到外部系统。
Reader -> Transform -> Writer。SeaTunnel 支持超过 100 种 Connector,以下是几类最常用的 Connector 及其特性分析:
支持列表: MySQL, PostgreSQL, Oracle, SQLServer, DB2, Teradata, Dameng(达梦), OceanBase, TiDB 等。
partition_column 切分)、Exactly-Once(取决于实现)。fetch_size)。支持列表: Kafka, Pulsar, RocketMQ, Amazon DynamoDB Streams 等。
支持列表: MySQL-CDC, PostgreSQL-CDC, Oracle-CDC, MongoDB-CDC, SQLServer-CDC, TiDB-CDC 等。
支持列表: LocalFile, HDFS, S3, OSS, GCS, FTP, SFTP 等。
支持列表: Elasticsearch, Redis, MongoDB, Cassandra, HBase, InfluxDB, ClickHouse, Doris, StarRocks 等。
Transform 插件用于在 Source 和 Sink 之间处理数据。以下是几个常用 Transform 的配置示例。
使用 SQL 语法对数据进行处理,支持重命名、计算、常量添加、过滤等。
transform {
Sql {
# 输入表名,必须与 Source 的 result_table_name 一致
plugin_input = "fake"
# 输出表名,供后续 Transform 或 Sink 使用
plugin_output = "fake_sql"
# SQL 查询语句
# 1. name as full_name: 字段重命名
# 2. age + 1: 数值计算
# 3. 'US' as country: 增加常量列
# 4. where age > 10: 数据过滤
query = "select name as full_name, age + 1 as next_year_age, 'US' as country from fake where age > 10"
}
}
用于删除或保留指定字段(注意:不是过滤行,是过滤列/字段)。
transform {
Filter {
plugin_input = "fake"
plugin_output = "fake_filter"
# 仅保留 name 和 age 字段,其他字段会被丢弃
include_fields = ["name", "age"]
# 或者使用 exclude_fields 删除指定字段
# exclude_fields = ["card"]
}
}
用于字符串替换,支持正则表达式。
transform {
Replace {
plugin_input = "fake"
plugin_output = "fake_replace"
# 需要替换的字段名
replace_field = "name"
# 匹配模式(旧字符串)
pattern = " "
# 替换后的字符串(新字符串)
replacement = "_"
# 是否使用正则表达式,这里设为 true,表示 pattern 是一个正则
is_regex = true
# 是否只替换第一个匹配项
replace_first = true
}
}
将一个字符串字段拆分为多个字段。
transform {
Split {
plugin_input = "fake"
plugin_output = "fake_split"
# 分隔符,这里使用空格
separator = " "
# 需要拆分的源字段
split_field = "name"
# 拆分后生成的新字段名列表
output_fields = ["first_name", "last_name"]
}
}
对于新手,推荐直接下载编译好的二进制发行包进行体验。
前往 SeaTunnel 下载页面 下载最新版本的二进制包(例如 apache-seatunnel-2.3.x-bin.tar.gz)。
tar -xzvf apache-seatunnel-2.3.x-bin.tar.gz
cd apache-seatunnel-2.3.x
SeaTunnel 的 Connector 是插件化的。首次使用需要下载插件:
sh bin/install-plugin.sh
注意:该命令会根据 config/plugin_config 文件中的配置,从 Maven 中央仓库下载常用插件(如 connector-fake, connector-console 等)。如果下载速度慢,请耐心等待或配置 Maven 镜像。
如果遇到下载速度极慢或超时失败的情况,建议配置 Maven 阿里云镜像。
~/.m2/settings.xml (Windows 下为 C:Users你的用户名.m2settings.xml)。<settings>
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url></url>
</mirror>
</mirrors>
</settings>
保存后再次运行 sh bin/install-plugin.sh 即可享受高速下载。
我们将创建一个简单的任务:生成一些随机数据(FakeSource),并将其打印到控制台(Console Sink)。
在 config 目录下创建一个名为 hello_world.conf 的文件,内容如下:
env {
# 并行度设置:决定了有多少个线程同时执行任务。
# 设置为 1 表示单线程执行,适合测试;生产环境可根据资源调大。
parallelism = 1
# 作业模式:
# BATCH (批处理):一次性处理完数据后结束(如离线同步)。
# STREAMING (流处理):持续运行,实时处理数据(如实时同步)。
job.mode = "BATCH"
}
source {
# FakeSource 是一个虚拟数据源,用于生成测试数据
FakeSource {
# result_table_name: 将此数据源产生的数据注册为一个临时表,表名为 "fake"
# 后续的 Transform 或 Sink 可以通过这个名字引用这份数据
result_table_name = "fake"
# row.num: 指定生成数据的总行数,这里生成 16 行数据
row.num = 16
# schema: 定义数据的结构(字段名和类型)
schema = {
fields {
name = "string" # 定义一个名为 name 的字符串字段
age = "int" # 定义一个名为 age 的整型字段
}
}
}
}
transform {
# Sql Transform: 使用 SQL 语句对数据进行处理
Sql {
# plugin_input: 指定输入数据来源,这里引用了 Source 中定义的 "fake" 表
plugin_input = "fake"
# plugin_output: 指定处理后的结果表名,命名为 "fake_transformed"
# 下游的 Sink 将使用这个名字来获取处理后的数据
plugin_output = "fake_transformed"
# query: 执行的 SQL 查询语句
# 这里演示了选择 name 和 age 字段,并新增一个常量字段 new_field
query = "select name, age, 'new_field_val' as new_field from fake"
}
}
sink {
# Console Sink: 将数据输出打印到控制台(标准输出)
Console {
# plugin_input: 指定要输出的数据来源,这里引用了 Transform 输出的 "fake_transformed" 表
plugin_input = "fake_transformed"
}
}
使用 SeaTunnel 自带的 Zeta 引擎运行该任务。
执行命令:
./bin/seatunnel.sh --config ./config/hello_world.conf -e local
命令详解:
./bin/seatunnel.sh: 启动脚本,默认使用 Zeta 引擎。--config (或 -c): 指定配置文件的路径。这里我们指定了刚才创建的 hello_world.conf。-e local (或 -m local): 指定执行模式。
local: 本地模式。SeaTunnel 会在当前进程中启动一个轻量级的 Zeta 引擎集群来运行任务,任务结束后集群关闭。适合开发和测试。cluster: 集群模式。任务会提交到已经运行的 SeaTunnel 集群中执行。适合生产环境。任务启动后,终端会输出大量日志。我们需要关注以下关键信息:
任务提交成功:
看到 Job execution started 表示配置文件解析通过,任务已提交给引擎。
数据处理过程:
由于我们使用的是 Console Sink,数据会直接打印在日志中。你应能看到类似如下的输出:
...
INFO ...ConsoleSinkWriter - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CpiOd, 12345, new_field_val
INFO ...ConsoleSinkWriter - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: eQqTs, 67890, new_field_val
...
subtaskIndex: 并行任务的编号。rowIndex: 当前处理的行号。SeaTunnelRow: 打印出的具体数据内容。任务结束:
最后看到 Job Execution Status: FINISHED 表示任务执行成功结束。
如果在运行过程中遇到报错,请参考以下常见问题进行排查:
command not found: java 或 JAVA_HOME is not setjava -version 确认 Java 8 或 11 已安装。export JAVA_HOME=/path/to/your/java (建议写入 ~/.bashrc 或 ~/.zshrc)。Exception in thread "main" ... ClassNotFoundExceptionClassNotFoundException: org.apache.seatunnel.connectors.seatunnel.fake.source.FakeSourceFactory。sh bin/install-plugin.sh。connectors/seatunnel 目录下是否有对应的 jar 包(例如 connector-fake-*.jar)。Config file not valid 或 HOCONSyntaxErrorhello_world.conf 中的括号 {} 不匹配,或者关键字拼写错误。{ 和 } 都是成对出现的。
