


WinlatorXR
881.97M · 2026-02-04

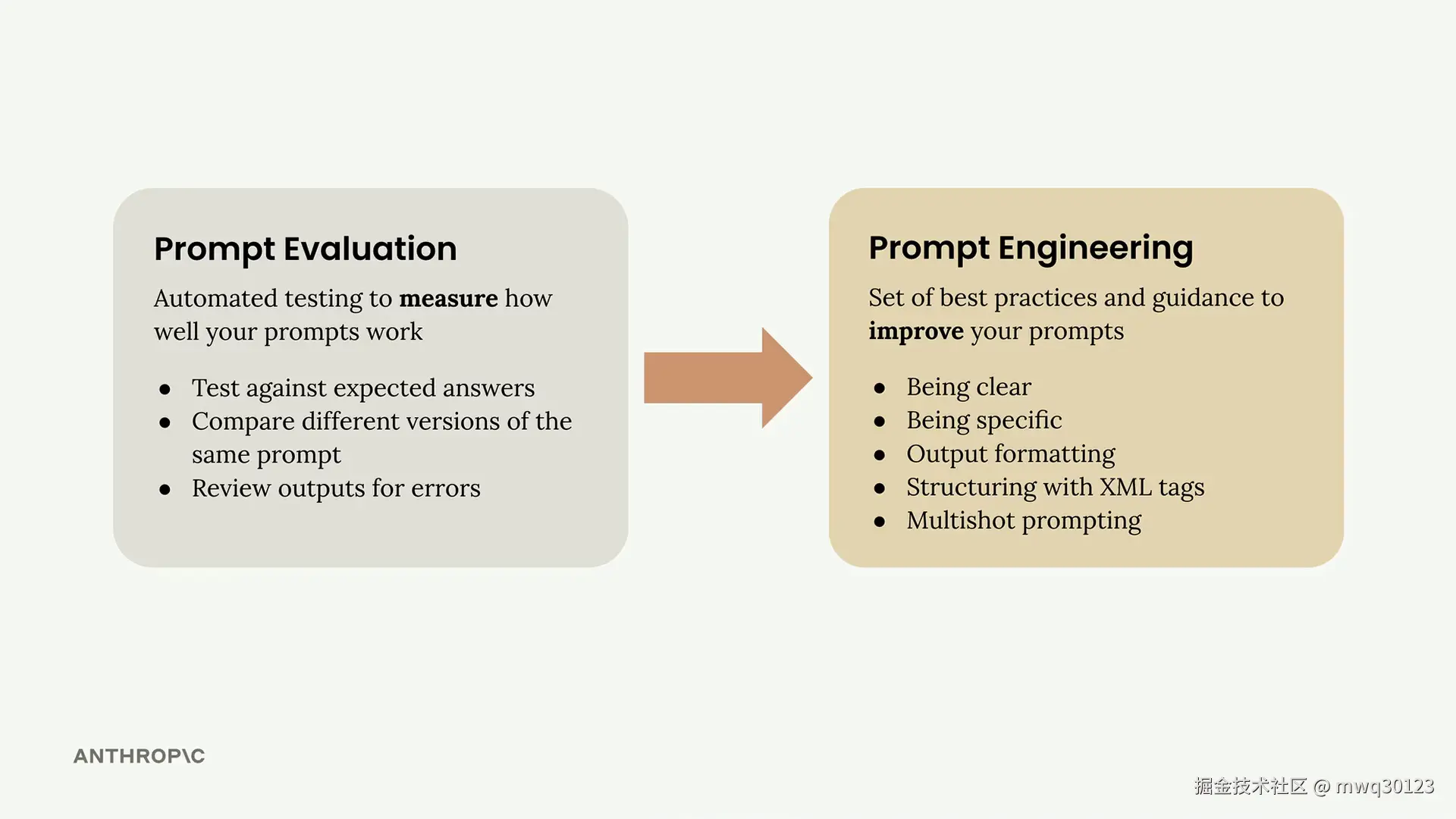
提示词工程是指对已编写的提示进行改进,以获得更可靠、更高质量的输出。这一过程涉及迭代优化——从基础词提示开始,评估其表现,然后系统性地应用工程技术来改进它。
这种方法遵循一个清晰的循环,你可以反复执行直到达到预期效果:

重复最后两个步骤,直到你对性能感到满意为止。每次迭代都应在评估分数上显示出可衡量的改进。
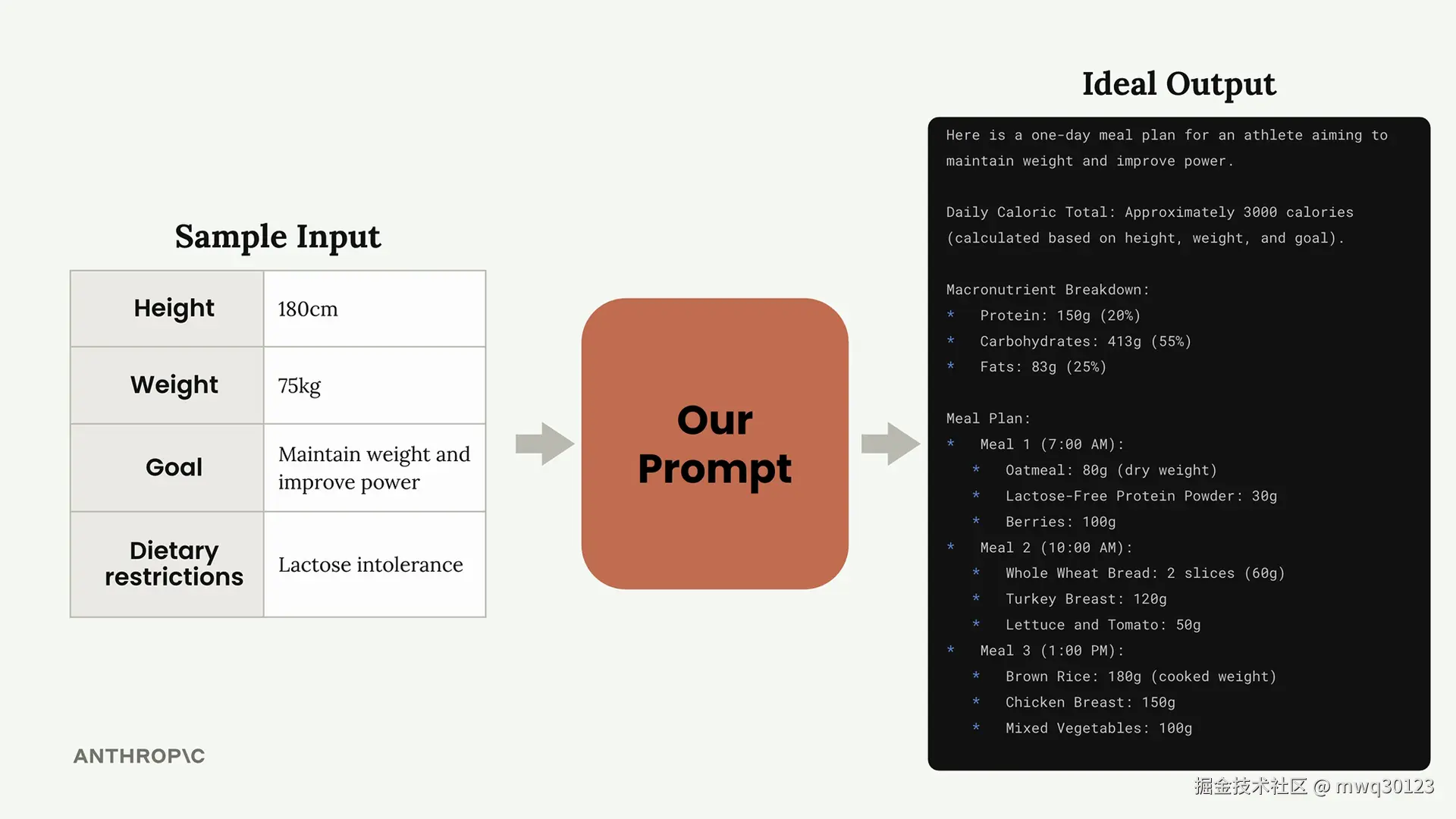
为了演示这个过程,我们将通过一个实际案例来进行:创建一个为运动员生成单日膳食计划的提示词。该提示词需要考虑运动员的身高、体重、目标和饮食限制,然后生成一份全面的膳食计划。
evaluator = PromptEvaluator(max_concurrent_tasks=5)
从较低的并发值(如 3)开始,以避免速率限制错误。如果您的 API 配额允许更快的处理速度,可以适当增加该值。
评估系统可以根据你的提示词要求自动生成测试用例。你需要定义提示词所需的输入:
dataset = evaluator.generate_dataset(
task_description="为一名运动员编写一份紧凑、简洁的一日膳食计划",
prompt_inputs_spec={
"height": "运动员的身高(单位:厘米)",
"weight": "运动员的体重(单位:千克)",
"goal": "运动员的目标",
"restrictions": "运动员的饮食限制",
},
output_file="dataset.json",
num_cases=2,
)
在开发过程中保持较少的测试用例数量(2-3个)以加快迭代周期。最终验证时可以增加数量。
从一个简单、朴素的提示词开始,建立基准线。以下是一个刻意设计的基础初次尝试示例:
def run_prompt1(prompt_inputs):
prompt = f"""
为一名运动员生成一份符合其饮食限制的一日膳食计划。
- 身高: {prompt_inputs["height"]}
- 体重: {prompt_inputs["weight"]}
- 目标: {prompt_inputs["goal"]}
- 饮食限制: {prompt_inputs["restrictions"]}
"""
messages = []
add_user_message(messages, prompt)
text = chat(messages, max_tokens=4000)
print(f"""run_prompt text: {text}""")
return text
这个基础提示词可能会产生较差的结果,但它为你提供了一个衡量改进效果的起点。
在运行评估时,你可以指定评分模型应考虑的额外标准:
results = evaluator.run_evaluation(
run_prompt_function=run_prompt1,
dataset_file="dataset.json",
extra_criteria="""
输出应包含:
- 每日卡路里总量
- 宏量营养素分解
- 包含确切食物、份量和时间的餐次
""",
)
这有助于确保您的提示词能够根据对您用例真正重要的特定要求进行评估。
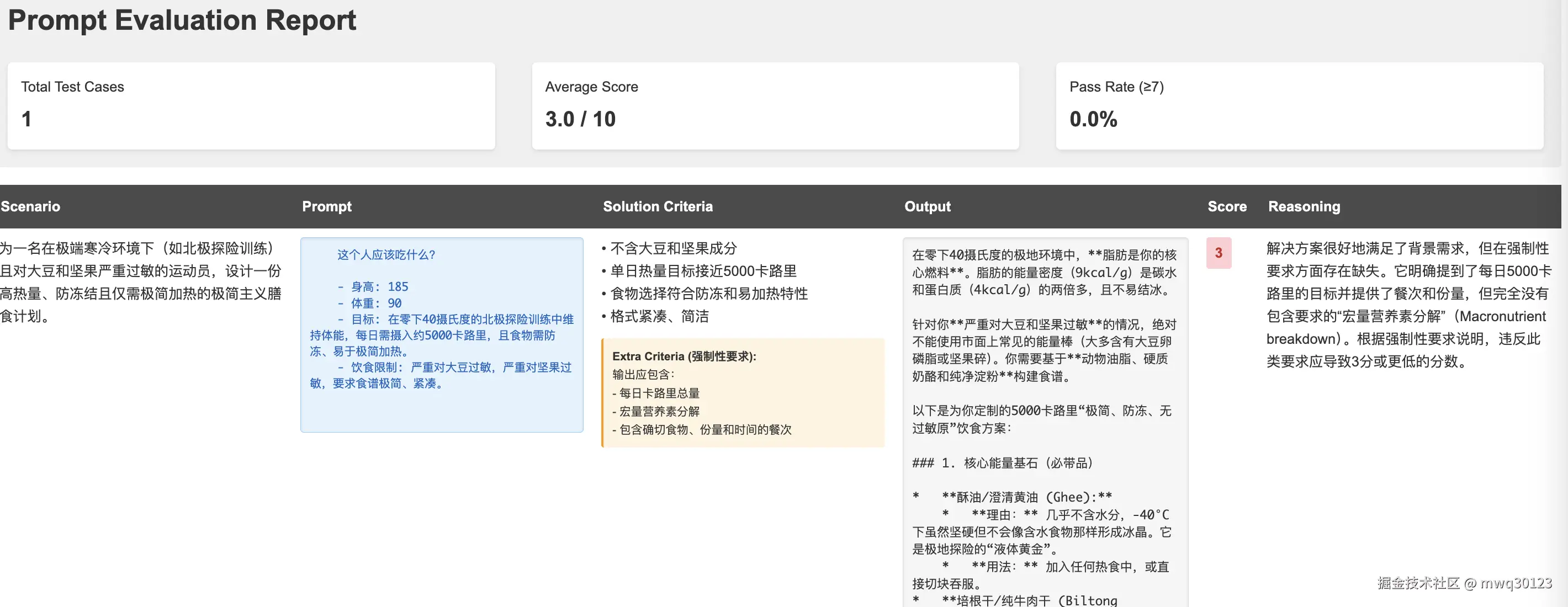
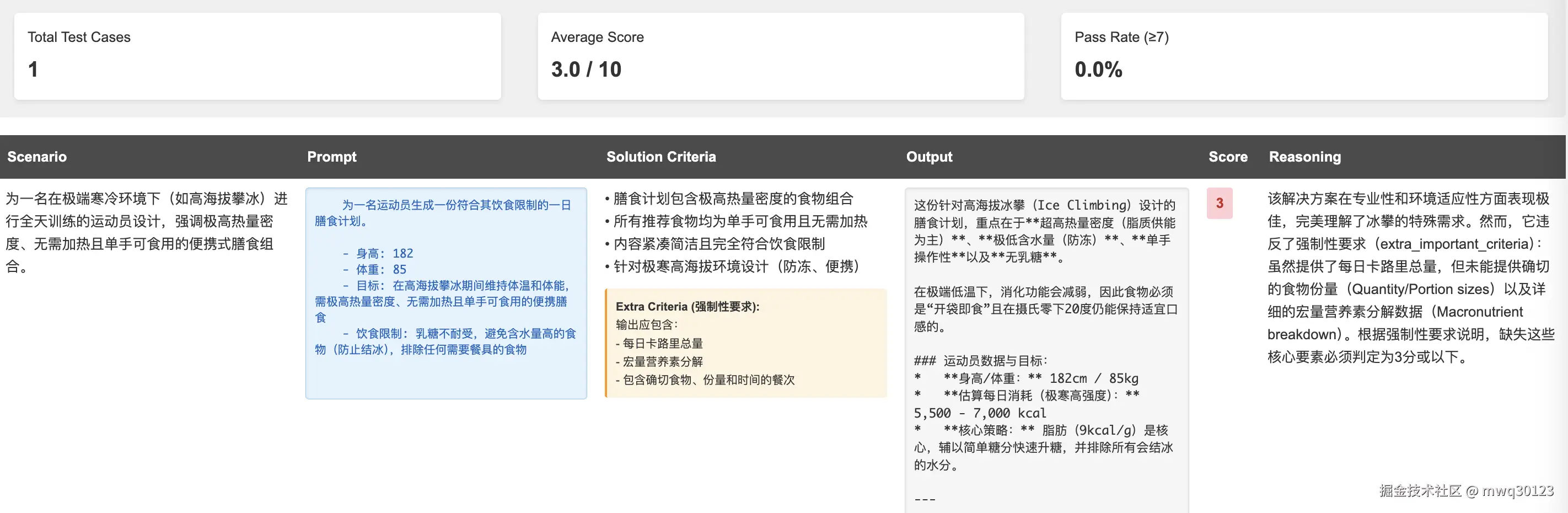
运行评估后,你将获得数值评分和详细的 HTML 报告。报告会准确展示每个测试用例的表现,包括模型对每个评分的推理过程。
不要因为初始分数低而气馁——首次尝试得到 3.0/10 的分数是很正常的。目标是在应用工程技术的过程中看到持续的进步。
详细的评估报告可帮助您准确了解提示词在哪些方面存在不足,以及需要进行哪些改进。请利用这些反馈来指导您的下一次迭代。
建立基线后,你就可以开始应用具体的提示工程技术了。你学习的每种技术都应该能在评估分数上带来可衡量的提升,逐步将你的基础提示转变为可靠、高性能的工具。
请记住,提示词工程是一个迭代的过程。关键在于每次只做一处修改,评估其影响,然后在有效的基础上继续改进。这种系统化的方法能确保你了解哪些技术对你的特定用例最有价值。
提示词的第一行是整个请求中最重要的部分。这是你为后续所有内容奠定基调的地方,写好这一行可以显著提升你的结果。
在撰写这关键的第一行时,你需要关注两个核心原则:清晰和直接。这意味着使用简洁的语言,让 Claude 明确无误地理解你希望它做什么。
清晰意味着:
不要写一些模糊的内容,比如"我想了解一下人们放在屋顶上利用太阳能的那些东西——好像叫太阳能板之类的",而是直接写:"写三段关于太阳能板工作原理的内容。"
"直接"侧重于你如何组织你的请求:
与其问"我在阅读关于可再生能源的内容,地热能听起来很有趣。哪些国家在使用它?",不如尝试:"列出三个使用地热能的国家,并附上每个国家的发电量统计数据。"
让我们看看这个技巧的实际应用。从一个简单询问"这个人应该吃什么?"的弱提示开始,我们可以应用清晰直接的方法。
改进后的版本变为: 为一名运动员生成一份符合其饮食限制的一日膳食计划。
这个修订版立即告诉 Claude:
这个简单的改变可以对性能产生显著影响。在我们的示例中,评估分数从 2.32 跃升至 3.92——仅仅通过重构开头那一行就实现了大幅提升。
关键要点是,当你把 Claude 当作一个需要明确指示的得力助手,而不是需要猜测你想要什么的人时,它的表现最好。以直接的动作动词开头,明确说明任务,你会立即看到更好的结果。
在使用 Claude 时,提高输出效果最有效的方法之一就是明确说明你想要什么。与其让模型自行理解,不如提供清晰的指导或步骤,引导 Claude 生成你期望的输出。
可以这样理解:如果你让 Claude"写一个关于某人发现自己隐藏天赋的短篇故事",Claude 可能会朝无数个方向发展。故事可能是 200 字,也可能是 2000 字;可能只有一个角色,也可能有五个;可以聚焦于任何类型的天赋发现场景。

在提示词中实现具体化主要有两种方法,在专业应用中你经常会看到它们被结合使用。
第一类侧重于列出输出应具备的特质。这些指南帮助你控制:
例如,你可以规定故事应控制在1000字以内,包含一个能展现角色才能的明确行动,并至少设置一个配角。
第二种类型为 Claude 提供了具体的步骤供其遵循。当你希望 Claude 系统性地思考问题,或在得出最终答案之前考虑多个角度时,这种方法特别有用。
你可以让 Claude 先完成以下步骤,而不是直接开始写作:
具体性带来的差异是显著的。在测试一个膳食计划提示词时,添加指导原则后评估分数从 3.92 提升到了 7.86——仅仅通过告诉 Claude 具体需要包含哪些元素,输出质量就提高了一倍多。
Guidelines:
1. Include accurate daily calorie amount
2. Show protein, fat, and carb amounts
3. Specify when to eat each meal
4. Use only foods that fit restrictions
5. List all portion sizes in grams
6. Keep budget-friendly if mentioned
以下是关于何时使用各类具体性的实用指南:
你应该在几乎每个提示词中都包含质量指南。它们是你获得一致、有用结果的安全网。
在处理以下情况时,请添加分步说明:

在专业提示词编写中,你经常会看到两种技术结合使用。你可能会有控制输出格式和内容的指南,同时还有确保 Claude 在回复前充分思考问题的步骤。
这种组合既能让你的结果保持一致性,又能确保 Claude 在得出结论时已考虑了所有重要因素。
当你构建包含大量内容的提示词时,Claude 有时可能难以理解哪些文本片段属于同一部分,或者不同部分各自代表什么含义。XML 标签提供了一种简单的方式来为提示词增添结构和清晰度,尤其是在你需要插入大量数据时。
假设有一个提示词需要分析 20 页的销售记录。如果没有清晰的边界,Claude 可能难以区分你的指令和你希望分析的实际数据。

这是一个更生动的例子,说明为什么 XML 标签很重要。如果你让 Claude 使用提供的文档来调试代码,把所有内容混在一起会造成混乱:

<docs> 标签来创建清晰的边界。
你不需要使用官方的 XML 标签。创建对你的内容有意义的描述性名称即可:
<data> 更好<docs> 用于分隔不同类型的内容标签名称越具体、越具有描述性,Claude 就越能理解每个部分的用途。
XML 标签在以下情况下最为有用:
即使对于较短的内容,XML 标签也可以作为分隔符,使您的提示词结构对 Claude 更加清晰。
在实践中,你可以这样构建提示词:
<athlete_information>
- Height: 6'2"
- Weight: 180 lbs
- Goal: Build muscle
- Dietary restrictions: Vegetarian
</athlete_information>
Generate a meal plan based on the athlete information above.
这清楚地表明,身高、体重、目标和限制条件都是相关的运动员数据,在生成膳食计划时应一并考虑。
虽然在简单提示词中你可能看不到显著的改进,但随着提示词变得越来越复杂并包含大量多样化的内容,XML 标签的价值会越来越大。
Claude 在分类时可能会遇到一些问题。
在提示词中提供示例是你将使用的最有效的提示工程技术之一。这种方法被称为"单样本"或"多样本"提示,通过向 Claude 提供输入/输出样本对来引导其响应。
让我们来看一个情感分析的示例。假设你希望 Claude 判断一条推文是正面的还是负面的:

要解决这个问题,你可以添加示例来展示 Claude 如何处理棘手的情况:
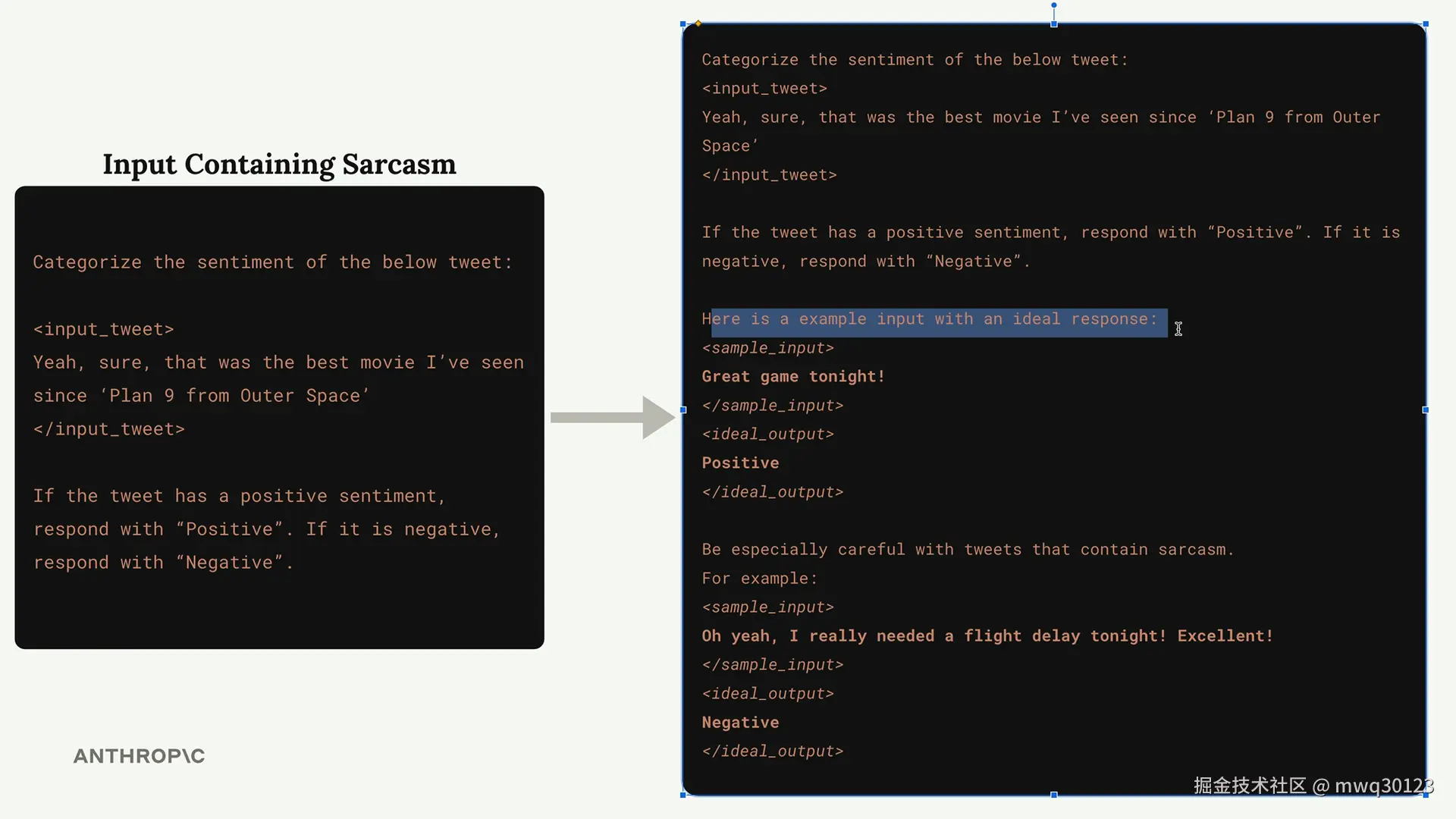
注意这些示例是如何用 XML 标签包裹的,比如 <sample_input> 和 <ideal_output>。这种结构让 Claude 能够非常清楚地理解每个部分代表什么。
示例在以下场景中尤为实用:
单样本:提供单个示例来建立模式
多样本:提供多个示例以涵盖不同场景
当你需要处理各种边缘情况或想展示不同类型的有效响应时,请使用多样本提示。
在运行提示词评估时,寻找得分最高的输出作为示例:
找出评分为 10(或你可用的最高分)的回复,并将这些输入/输出对作为示例放入你的提示词中。这有助于 Claude 理解针对你的特定用例,"完美"的输出应该是什么样子。
不要只提供输入/输出对——要解释为什么这个输出是好的:
<ideal_output>
[Your example output here]
</ideal_output>
This example is well-structured, provides detailed information
on food choices and quantities, and aligns with the athlete's
goals and restrictions.
这些额外的上下文帮助 Claude 理解好的回复背后的推理逻辑,而不仅仅是格式。
示例尤其强大,因为它们是展示而非讲述。与其试图用文字准确描述你想要什么,不如直接演示出来。这使你的提示词更加可靠,并帮助 Claude 理解那些仅靠指令难以表达的细微要求。
def run_prompt2(prompt_inputs):
prompt = f"""
为一名运动员生成一份符合其饮食限制的一日膳食计划。
<athlete_information>
- 身高: {prompt_inputs["height"]}
- 体重: {prompt_inputs["weight"]}
- 目标: {prompt_inputs["goal"]}
- 饮食限制: {prompt_inputs["restrictions"]}
</athlete_information>
指导原则:
1. 包含准确的每日卡路里数量
2. 显示蛋白质、脂肪和碳水化合物含量
3. 指定每餐的用餐时间
4. 仅使用符合限制的食物
5. 以克为单位列出所有食物份量
6. 如果提到预算,保持经济实惠
以下是一个示例输入和理想输出的例子:
<sample_input>
身高: 170
体重: 70
目标: 保持健康并改善胆固醇水平
限制: 高胆固醇
</sample_input>
<ideal_output>
以下是为一名旨在保持健康并改善胆固醇水平的运动员制定的一日膳食计划:
* **卡路里目标:** 约 2500 卡路里
* **宏量营养素分解:** 蛋白质 (140g),脂肪 (70g),碳水化合物 (340g)
**膳食计划:**
* **早餐 (7:00 AM):** 燕麦片(80g 干重)配浆果(100g)和核桃(15g)。脱脂牛奶(240g)。
* 蛋白质: 15g,脂肪: 15g,碳水化合物: 60g
* **上午加餐 (10:00 AM):** 苹果(150g)配杏仁酱(30g)。
* 蛋白质: 7g,脂肪: 18g,碳水化合物: 25g
* **午餐 (1:00 PM):** 烤鸡胸肉(120g)沙拉配混合蔬菜(150g)、黄瓜(50g)、番茄(50g)和清淡的油醋汁(30g)。全麦面包(60g)。
* 蛋白质: 40g,脂肪: 15g,碳水化合物: 70g
* **下午加餐 (4:00 PM):** 希腊酸奶(170g,脱脂)配香蕉(120g)。
* 蛋白质: 20g,脂肪: 0g,碳水化合物: 40g
* **晚餐 (7:00 PM):** 烤三文鱼(140g)配蒸西兰花(200g)和藜麦(75g 干重)。
* 蛋白质: 40g,脂肪: 20g,碳水化合物: 80g
* **晚间加餐 (9:00 PM):** 一小把杏仁(20g)。
* 蛋白质: 8g,脂肪: 12g,碳水化合物: 15g
此膳食计划优先选择瘦肉蛋白来源、全谷物、水果和蔬菜,同时限制饱和脂肪和反式脂肪,以支持健康的胆固醇水平。
</ideal_output>
此示例膳食计划结构良好,提供了食物选择和数量的详细信息,并与运动员的目标和限制保持一致。
"""
messages = []
add_user_message(messages, prompt)
# 使用更大的 max_tokens 值,确保完整的膳食计划不会被截断
# 对于详细的膳食计划(包含多餐、营养成分等),使用 8000 tokens
text = chat(messages, max_tokens=4000)
print(f"""run_prompt text: {text}""")
return (prompt, text)

