

以观书法
108.85M · 2026-02-05

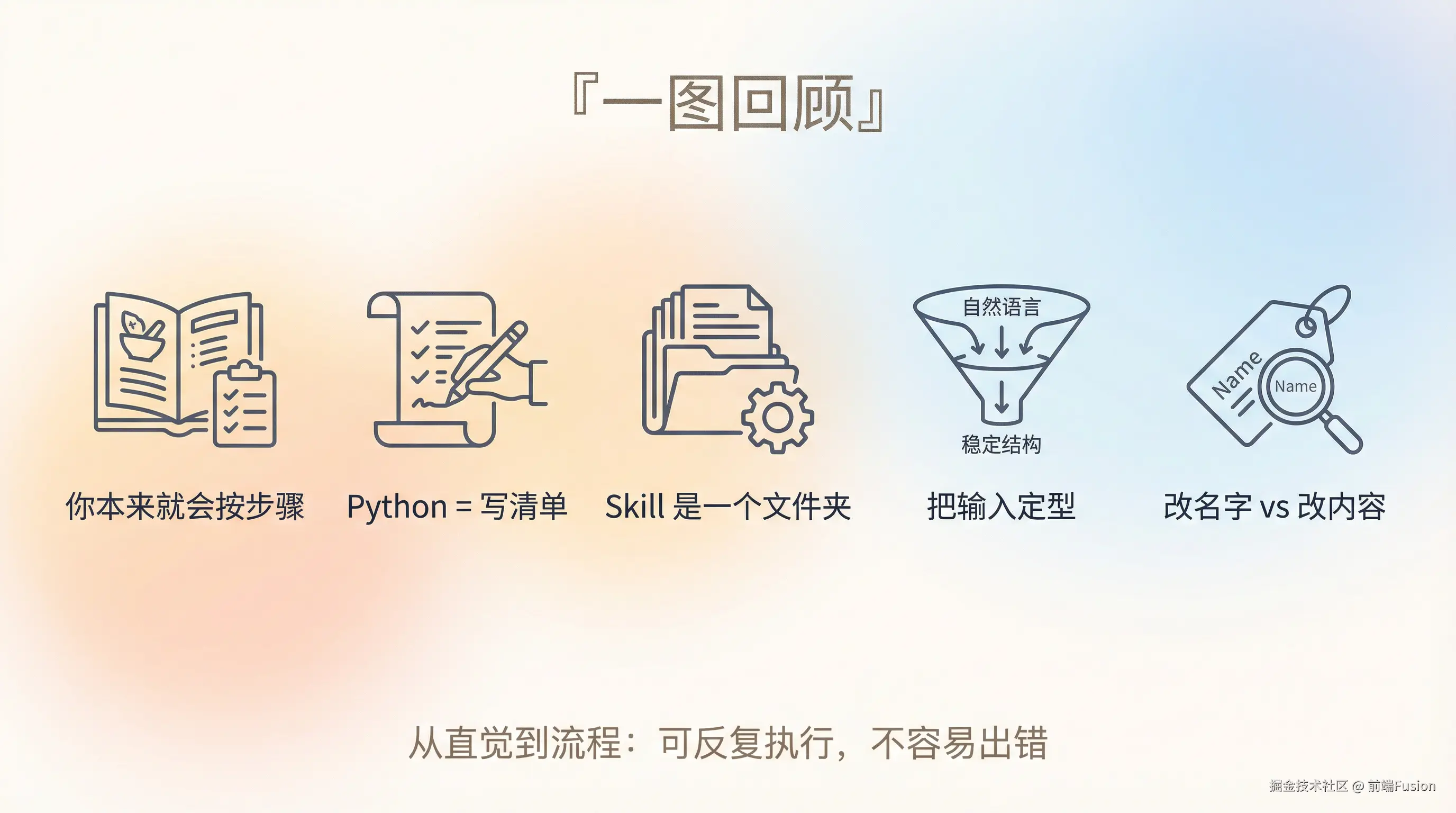
很多人第一次看到 Skill 这个词,都会下意识觉得:
“这是不是给程序员用的?” “是不是要会写很多代码?”
但如果我们把它拆开来看,会发现一件很有意思的事:
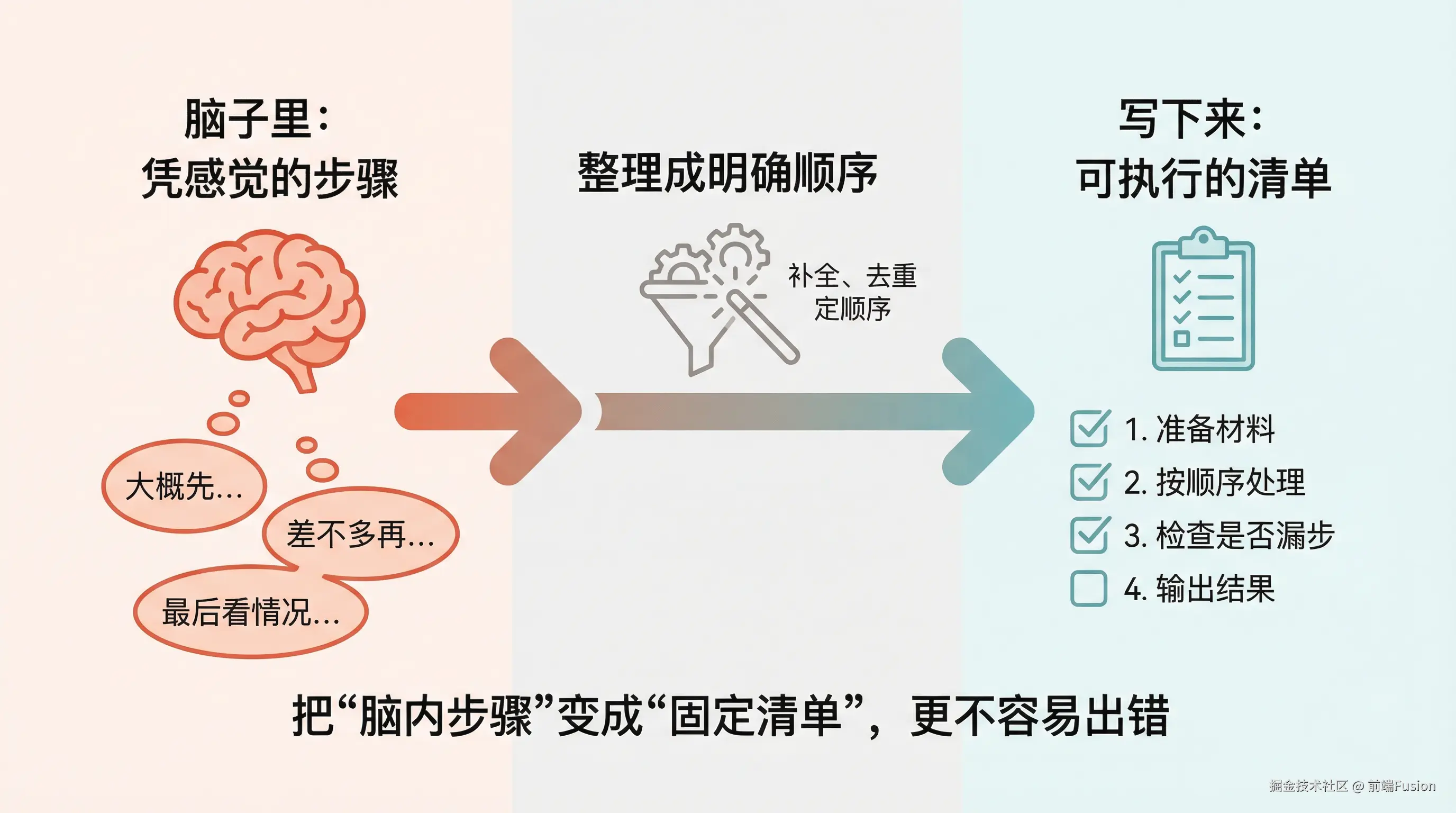
Skill 其实就是把一件你已经会做的事情, 变成一次“可以反复执行、不容易出错的流程”。
这篇文章不要求你有任何技术背景。 我们会一步一步来,慢慢把这件事讲清楚。
先暂时把 Skill 这个词放一边。
想一个非常生活化的场景:
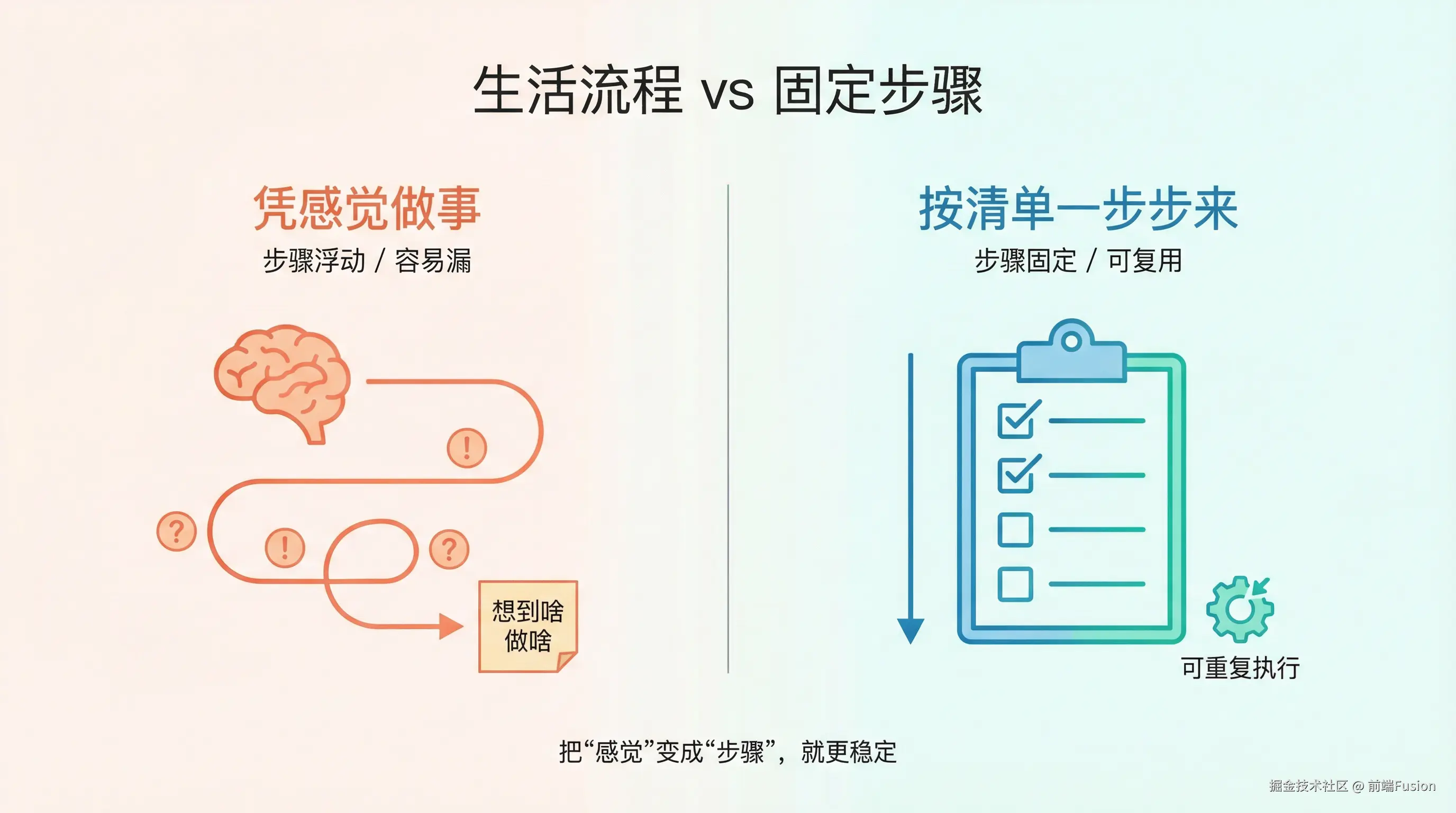
你要做一道固定的菜。
第一次做的时候,你可能会一边看菜谱,一边试探着来; 做多了之后,你会发现流程几乎是固定的:
如果你让别人来帮你做,你大概会说:“你就照这个步骤来,别自己发挥。”
Skill,本质上就是做这件事。
只是对象从「人」变成了「机器」。
在继续说 Skill 之前,我们先认识一下 Python。
如果一定要用一个生活比喻:
它不是用来炫技的,而是用来把事情一步一步写清楚的。
先做什么,再做什么,遇到特殊情况怎么办。
你几乎可以把 Python 写下来的内容,当成一种非常严谨的步骤说明。
你暂时不需要知道语法,只需要知道它常被用在这些地方:
处理文件、做重复的事情、在不同格式之间来回转换、把一些枯燥的步骤自动完成。
这些事情的共同点是:
不需要复杂判断,但非常怕「少一步、多一步」。
而 Python 正好擅长把这种事情写得很清楚。
现在我们再回到 Skill。
Skill 的核心目标是:
而 Python,恰好是一个非常擅长“描述步骤”的语言。
所以在 Skill 里,我们通常会看到:
Skill 用来说明 「这件事是什么」, Python 用来说明 「这件事怎么一步步做」。
这不是唯一选择,但在「容易理解、不容易出错」这件事上, Python 非常合适。
现在,我们可以正式看看 Skill 了。
请记住一句话:
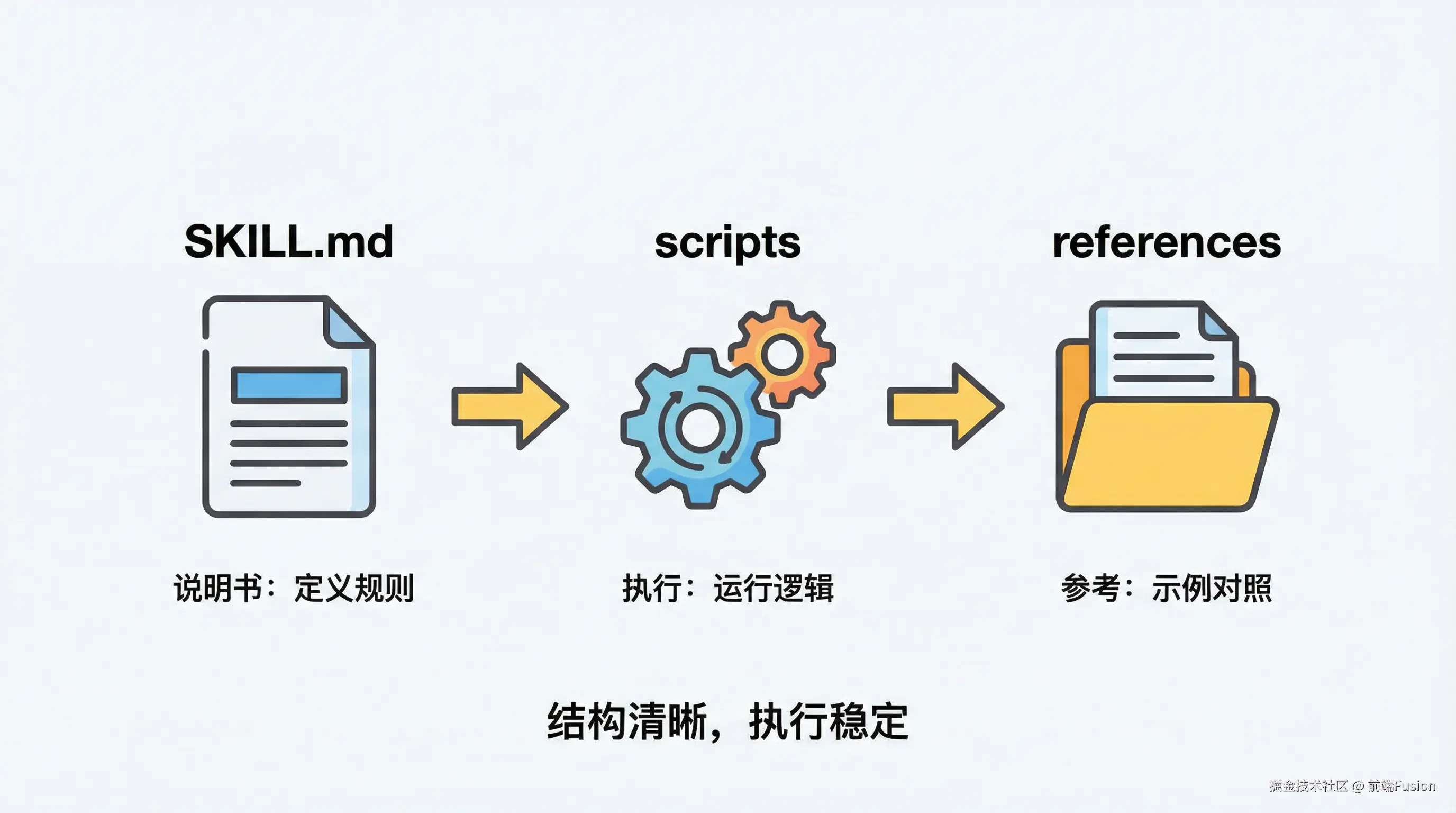
这个文件夹里,最重要的不是代码,而是一份说明。
my-skill/
├─ SKILL.md
├─ scripts/
│ └─ main.py
└─ references/
└─ ...
如果你完全不懂技术,也没关系, 我们一句一句解释。
SKILL.md 里通常会说明三件事:
什么时候用这件事, 输入是什么, 输出会是什么样。
你可以把它当成:
一份「使用说明书 + 注意事项」。
scripts 里面的内容,不是给人看的,
而是让机器真正去执行的步骤。
你可以把它理解成:
把你写在 SKILL.md 里的话,翻译成机器能严格执行的版本。
有时候,只靠文字描述还是容易理解不一致。
这时,就可以提供示例输入、示例输出, 让机器对照着来。
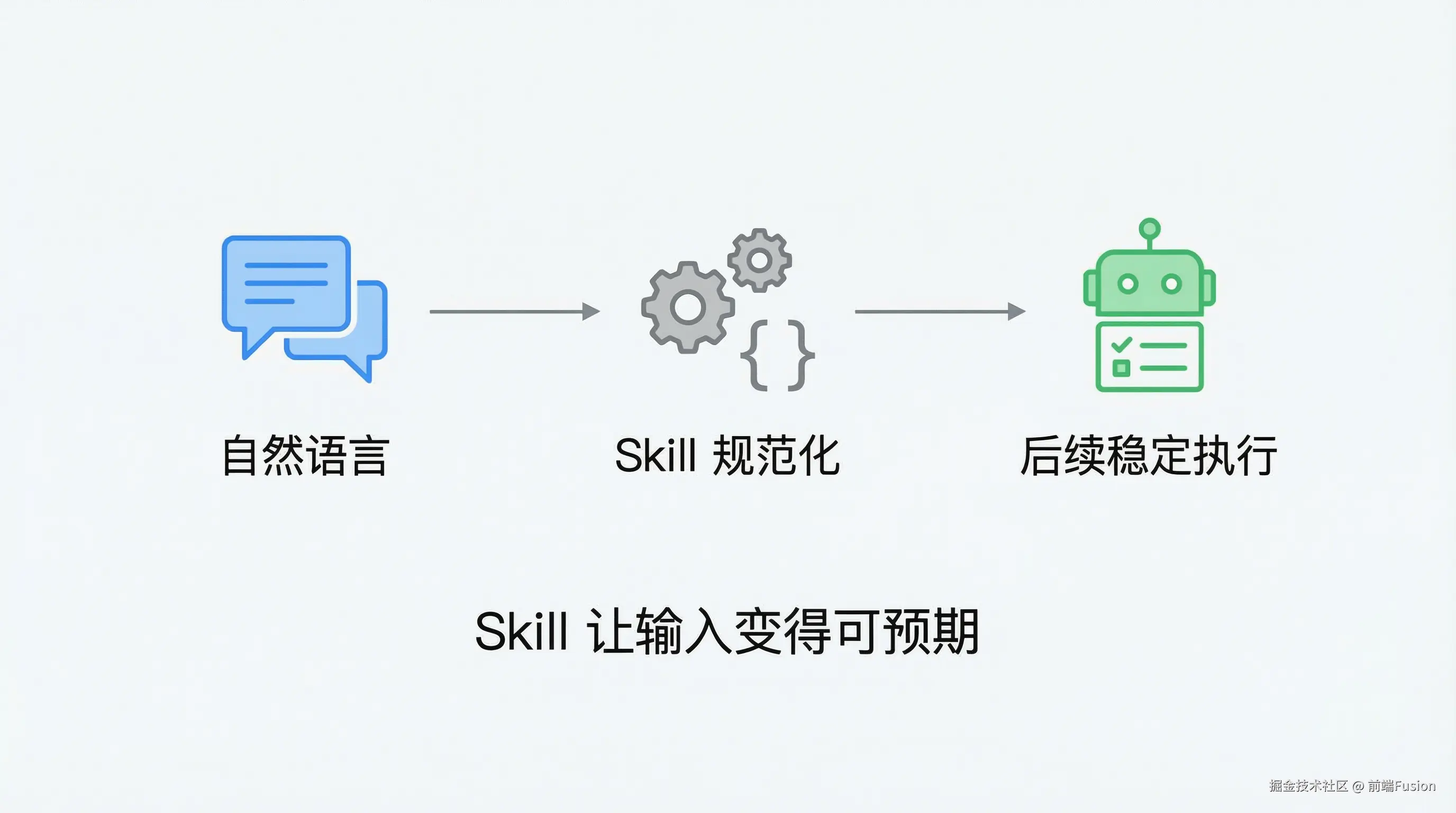
前面我们一直在说,Skill 是给大模型用的外部能力。 现在,我们用一个最贴近真实使用方式的例子,把这件事真正走一遍。
假设用户对大模型说了一句话:
帮我整理一下今天要做的事情:买牛奶,下午三点开会,晚上跑步。
这句话对人来说非常自然, 但对系统来说,却是一个结构不稳定的输入。
如果后面还要继续做规划、提醒、拆解任务,这个输入就需要被「定型」。
这正是 Skill 要做的事情。
我们先把目标说清楚:
用户只说自然语言。 大模型负责理解“这是在描述要做的事情”。 Skill 负责把这段话,整理成一个固定、可复用的结构。
Skill 并不参与理解语义, 它只负责一件事:把结果写成系统后面能稳定使用的形状。
不管用户怎么说,只要意思是「要做的事情」, 这个 Skill 返回的结果都应该长成同一种样子:
{
"tasks": ["买牛奶", "下午三点开会", "晚上跑步"]
}
这里的重点不在于解析得有多聪明, 而在于:这个结构本身是稳定的、可依赖的。
nl-to-tasks/
├─ SKILL.md
└─ scripts/
└─ main.py
这个结构本身,就已经是一个完整的 Skill。
SKILL.md 的作用,不是写给用户看的,
而是写给系统和大模型看的。
它回答的是两个问题: 什么时候该用这个 Skill? 用完之后,能得到什么?
---
name: nl-to-tasks
description: 将自然语言中的待办事项整理为稳定的 tasks 列表结构,供大模型后续使用。
---
# Natural Language to Tasks
当用户用自然语言描述「要做的事情」时,使用这个 Skill。
## Input
- text: 用户的自然语言输入
## Output
- tasks: 待办事项数组,每一项是一个字符串
## Rules
- 输出必须是 JSON 对象,且只包含 tasks 字段
- 如果无法识别任何待办事项,返回空数组
下面这段代码并不追求“智能”, 它只做一件事:把一段话拆成一个稳定的列表结构。
import sys
import json
import re
def extract_tasks(text: str):
# 使用最直观的分隔规则:逗号、顿号、换行
parts = re.split(r"[,,、n]", text)
tasks = [p.strip() for p in parts if p.strip()]
return tasks
if __name__ == "__main__":
text = sys.stdin.read()
result = {
"tasks": extract_tasks(text)
}
print(json.dumps(result, ensure_ascii=False, indent=2))
在真实应用中,这个脚本并不是由用户直接运行的。
而是由大模型在判断“需要整理待办事项”时,在后台调用。
一旦你有了这样一个稳定的结构输出, 后面的能力扩展会非常自然:
tasks 直接变成真正的 TODO 列表而这些升级,都不需要推翻这个 Skill 的基本设计。 你只是不断在这个“稳定结构”之上,往前走。
如果你只是照着示例跑一遍,其实已经足够开心了: 原来 Skill 没那么神秘,也能真的帮我把事情自动化。
但当你想更进一步—— 比如把输入换成你自己的格式、把输出改成你想要的结构、把流程拆成多个步骤复用—— 你会发现问题不再是「会不会写代码」,而是:
你能不能清楚地知道, 哪些地方只是换了一种说法, 哪些地方是真的把内容改了。
这听起来不像编程,更像是一件很日常的事。 你给东西起了名字,但改名字,和改东西本身,并不是一回事。
只要你能分清这一点,你写出来的脚本就会非常稳定。 哪些步骤是在生成新结果, 哪些步骤是在原地处理内容, 你心里会非常清楚。
所以,下一篇我会专门把这种最基础、但非常关键的理解方式讲清楚。 帮你真正掌握开发 Skills 时需要掌握的 Python 基础心智模型。
感谢您的阅读~
我在微信公众号 前端Fusion 中也会持续同步更新关于 AI 与前端开发的相关文章,欢迎大家关注,一起交流学习。

