

星脉血压
77.50M · 2026-04-15

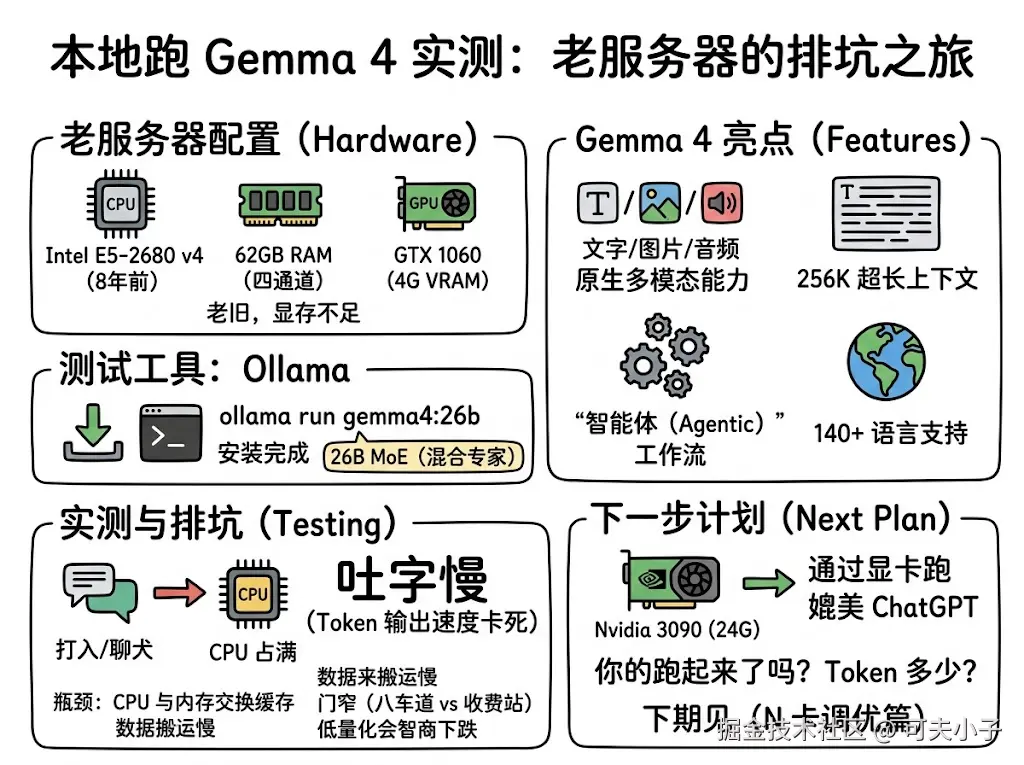
被 Google 称为“同等参数量下最强大的开源模型” Gemma 4 终于发布了!社交媒体上热度直接炸裂。它基于与 Gemini 3 相同的研究架构打造。
看着每个月雷打不动的 Claude 和 ChatGPT 订阅账单,我冒出一个大胆的想法:如果能把这个性能怪兽跑在本地,是不是就能彻底实现 Token 自由了?
今天,我翻出了压箱底的一台老款 Ubuntu 服务器,带大家实测一把。看看在老硬件上,到底能不能体验到媲美顶尖闭源模型的快感。
在动手之前,先来看看这次 Gemma 4 为什么被圈内奉为“神明”。它最大的特点是对设备的性能要求低,能够在一些嵌入式设备比如手机上跑,最近也是在社交媒体上也有很多案例。那么我们能否自己跑起来这样的模型,实现 OpenClaw 的 Token 自由呢?我们再过一下它的官方亮点:
在安装之前先看一下电脑的配置,我的 Ubuntu 服务器是早些年进行 Android BSP 开发时购入的,配置如下:
CPU: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz (56 cores)
Total RAM: 62.78 GB
Available RAM: 60.59 GB
Backend: Vulkan
GPU: GeForce GTX 1060 5GB (4.00 GB VRAM, Vulkan)
那么针对这样的电脑配置,能跑什么尺寸的模型呢?先安装llmfit,测试系统能跑多大模型
curl -fsSL | sh
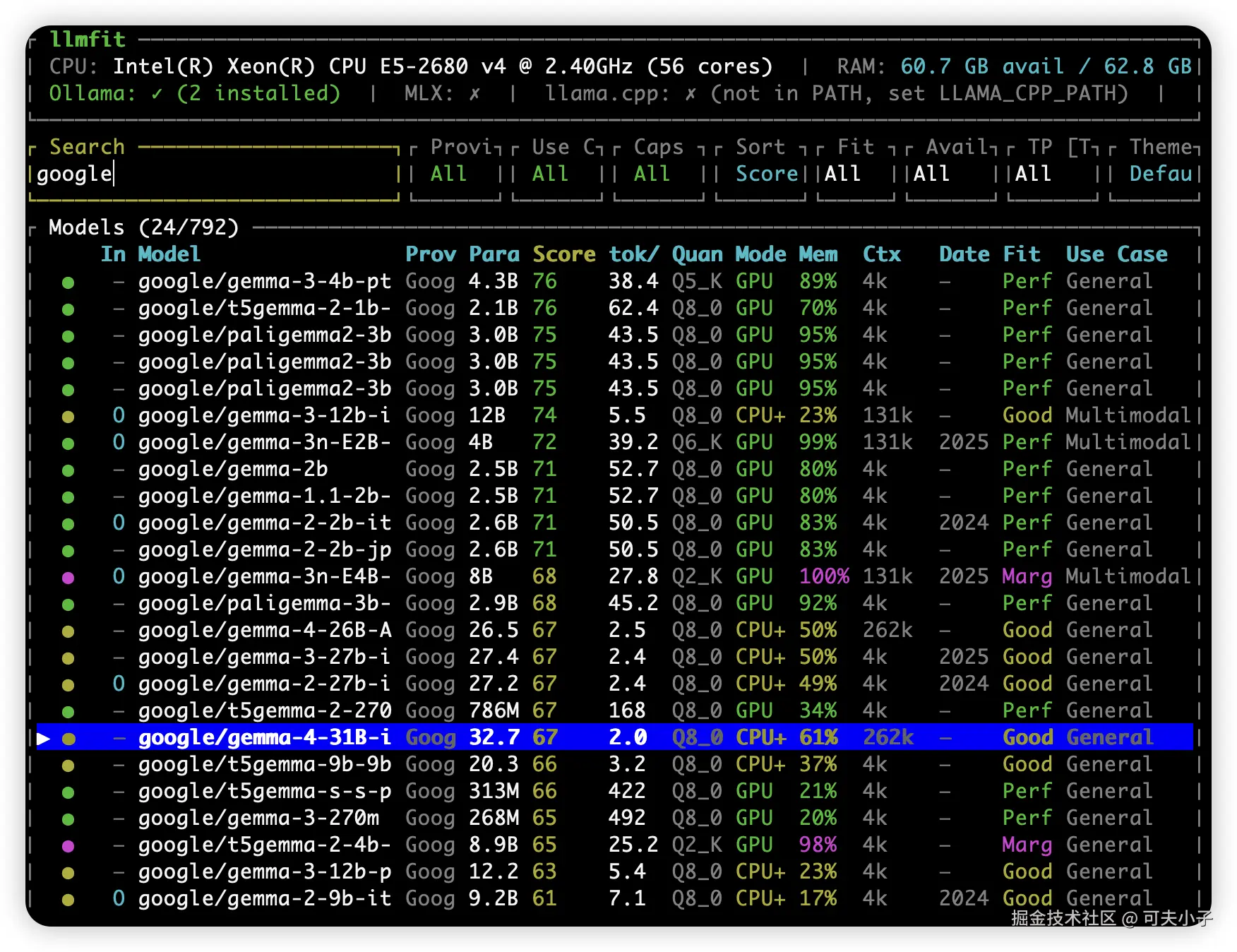
安装完成之后,输入 llmfit 启动检测,输入 / 然后再输入 google,就可以查看能跑 Gemma 4哪个模型合适?
从截图可以看到,我的电脑适合安装31B 和26B 两个模型,那到底选哪个呢?
为了适应从手机到大型服务器的不同硬件,Gemma 4 划分为四个主要的尺寸(在 llmfit 截图里也能看到它们的影子):
google/gemma-4-31B-i)。它是该系列中用来硬扛复杂任务的主力,在多项数学和编程基准测试中,表现甚至超越了许多比它大几十倍的模型。
综上,这次我们以26B这个版本,综合性能和速度最佳版本。要想媲美 ChatGPT,至少要26B 以上。Ollama 是现在最流行的大模型运行工具,我之前的文章也介绍了 Ubuntu 系统的安装,我这边再贴一下。
Untitled
安装完之后,查看版本
ollama -v
能正常打印就说明安装成功。
Ollama 安装好了,就可以使用 Ollama 来安装我们选择的 Gemma 4 26b 模型
ollama run gemma4:26b
模型大概有17G,稍等一会,就下载完成了。
下载完,我输入一个 hi,等了半天,完全没有56 core + 64G 内存配置的速度,我接着问了“你能做什么”,大家来感受一下他的输出速度(视频未加速)
吐字的速度确实比较慢,我通过 ps 查询了一下,CPU 已经占满了。
查询了一下,真正的资源瓶颈不是在 CPU,是 CPU 与内存交换的缓存。我的服务器 CPU 是Intel Xeon E5-2680 v4,毕竟这是一个8年前的芯片。在理想的四通道配置下,理论带宽约为 76.8 GB/s。推理速度限制:对于 26B 的模型,即使使用 4-bit 量化,模型权重也占用约 16-18GB。推理时每生成一个字(token),CPU 都需要把这 18GB 数据从内存搬运一次。
换句话说,你的 CPU 算力再强、内存容量再大都没用,连接它们的“门”太窄了。 这就像是一个八车道的高速公路,收费站却只开了一个口,Token 输出速度自然被卡得死死的。
虽然可以通过更低位数的量化来妥协,但这会导致模型“智商”断崖式下跌,失去了我们部署强力模型的初衷。
这次用纯 CPU + 老旧内存架构跑 26B 模型,算是一次非常典型的硬核排坑。它验证了一个真理:玩本地大模型,显存带宽才是王道。
接下来,我打算着手折腾一下服务器上安装 Nvidia 3090 24G显卡,再通过显卡来跑大模型,看能否让这台服务器完成我了我的 Android BSP 开发之后,焕发我的 AI 第二春。
你的 Gemma 4跑起来了吗?效果如何,评论区讨论一下。
你的电脑跑起 Gemma 4 了吗?速度能达到每秒多少 Token?
咱们下期 N 卡硬核调优篇见!

