荣耀文档
80.56M · 2026-04-14

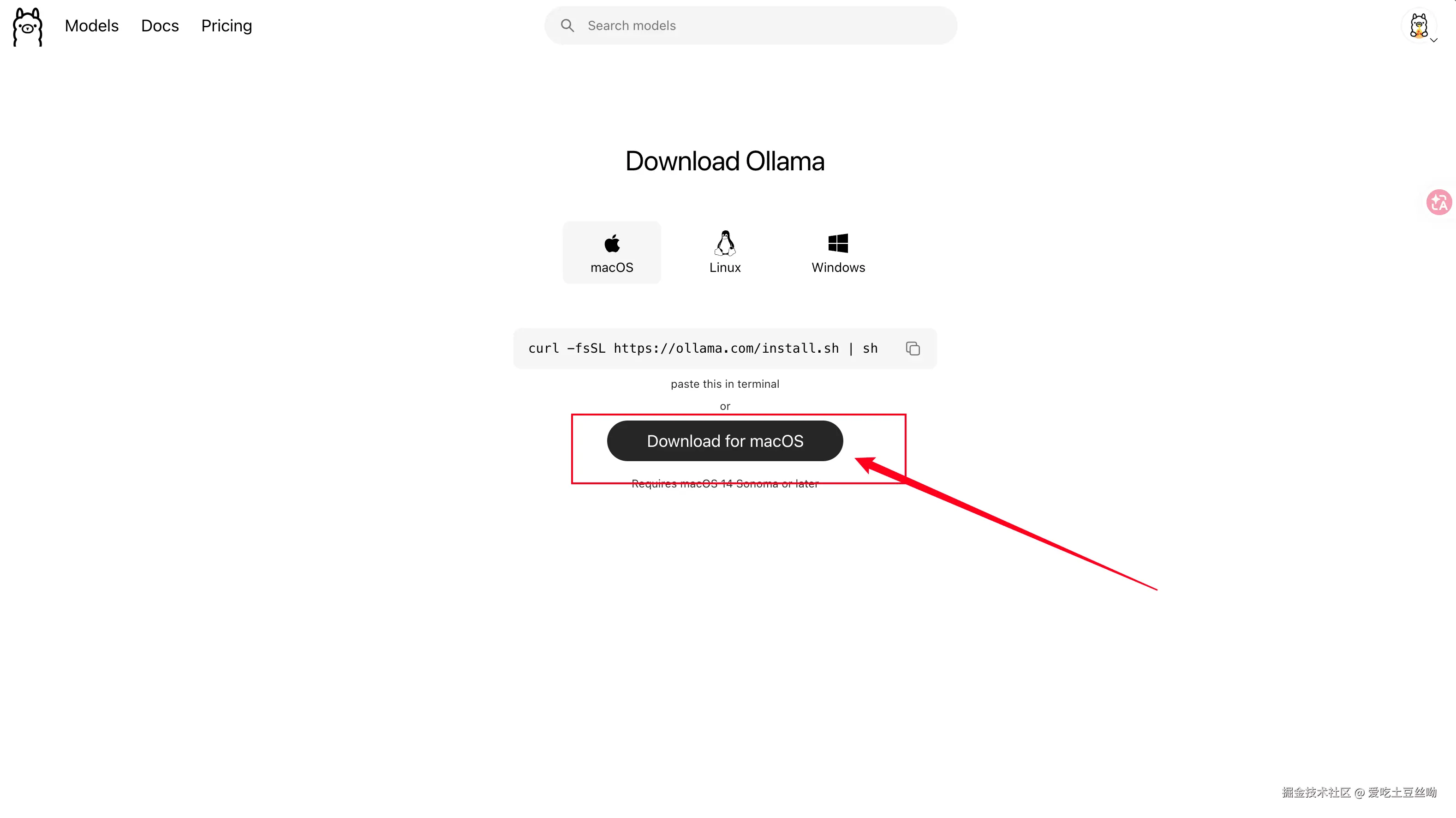
Ollama 是一个本地运行大语言模型的工具,支持 macOS / Linux / Windows。它把模型下载、运行、API 服务全部封装好,一条命令就能跑起来。
Ollama.app 拖入「应用程序」文件夹brew install ollama
安装完成后启动服务:
ollama serve
ollama --version
看到版本号即安装成功。
ollama run gemma4
首次运行会自动下载模型(约 5GB),下载完成后直接进入对话。之后再运行则跳过下载,直接启动。
输入问题即可聊天,输入 /bye 退出。
ollama list
| 命令 | 说明 |
|---|---|
ollama serve | 启动 Ollama 服务(桌面版自动启动) |
ollama pull <模型名> | 下载模型 |
ollama run <模型名> | 运行模型并进入对话 |
ollama list | 查看已下载的模型列表 |
ollama rm <模型名> | 删除模型 |
ollama show <模型名> | 查看模型详细信息 |
ollama ps | 查看当前运行中的模型 |
Ollama 启动后会在 localhost:11434 提供 HTTP API。
curl
返回 Ollama is running 表示正常。
curl -X POST
-H "Content-Type: application/json"
-d '{
"model": "gemma4",
"messages": [{"role": "user", "content": "你好"}],
"stream": false
}'
curl -X POST
-H "Content-Type: application/json"
-d '{
"model": "gemma4",
"messages": [{"role": "user", "content": "介绍一下你自己"}],
"stream": true
}'
curl
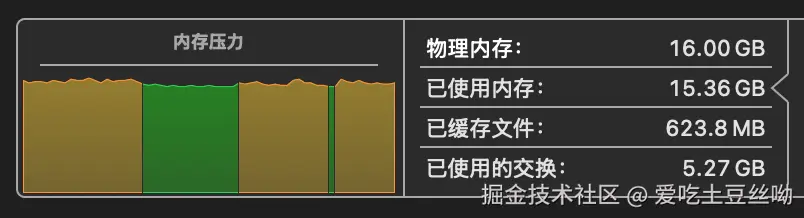
模型非常吃内存,目前一开始回复就会将我的mac内存吃满,我的是16g的macmini

