
庄园咖啡厅
47.60M · 2026-04-08

分页查询在业务中无处不在——后台列表、日志检索、订单查询……ES 提供了最直观的 from + size 分页参数,用法和 MySQL 的 LIMIT offset, size 几乎一模一样。
但当 from 值越来越大时,查询会越来越慢,甚至直接报错:
{
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000]"
}
这就是深分页问题(Deep Pagination)。要搞清楚它,先得理解 from/size 在分布式场景下的真实执行原理。
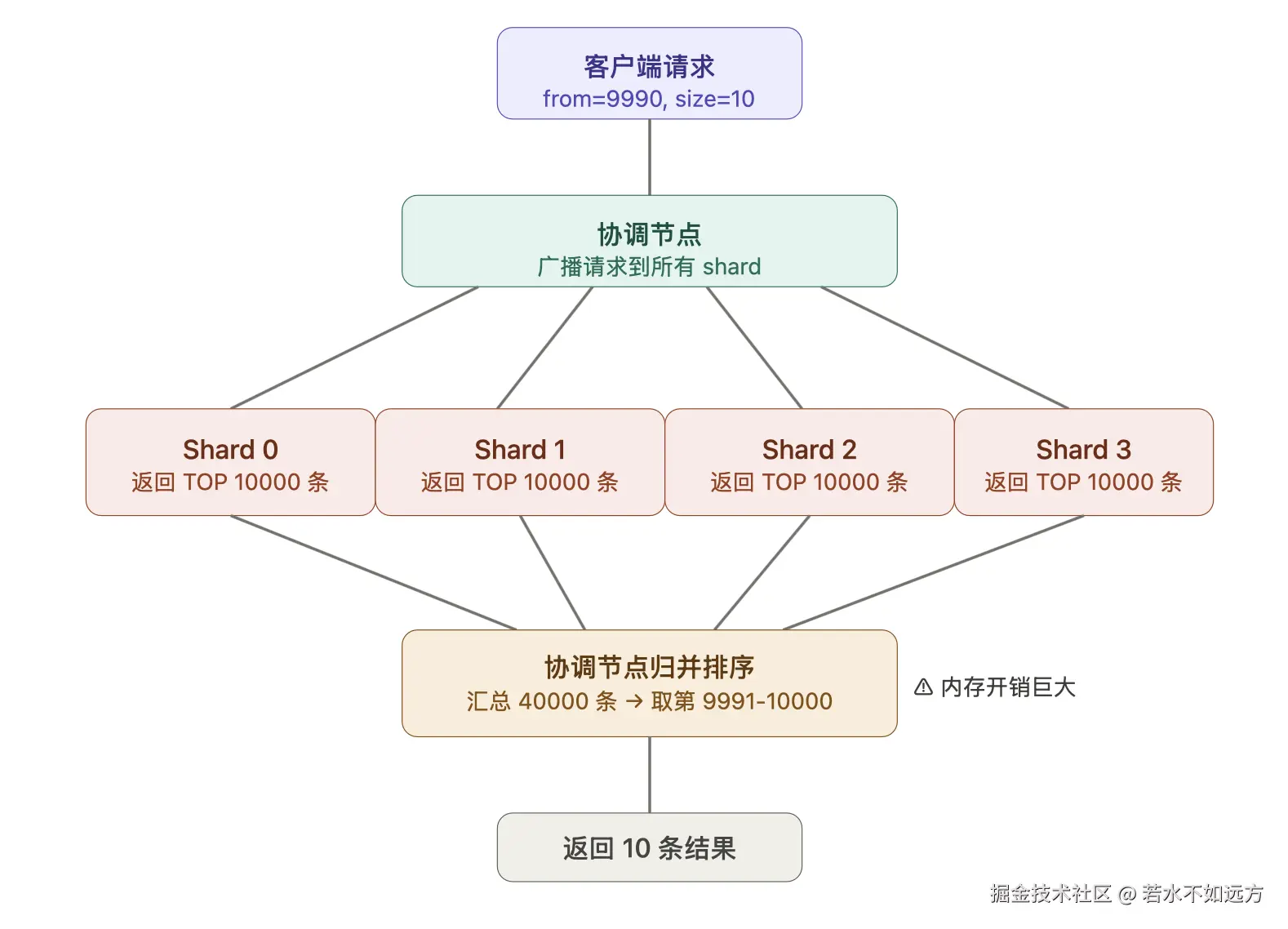
ES 是分布式的,一个索引通常被拆分为多个 shard 分布在不同节点上。执行分页查询时,协调节点(Coordinating Node)需要从所有 shard 收集数据,再统一排序、截取。
下图展示了查询第 1000 页(from=9990, size=10)时,ES 内部发生了什么:
核心逻辑很清楚:每个 shard 都要返回 from + size 条记录,协调节点再把所有 shard 的数据汇总到内存中进行排序,最终只取最后那 10 条给客户端。
这意味着:
from=9990, size=10,4 个 shard 的场景下,协调节点需要在内存中处理 4 × 10000 = 40000 条数据index.max_result_window = 10000 硬限制来保护集群,超出直接报错PUT /my_index/_settings
{
"index.max_result_window": 100000
}
这只是把问题推后,不是解决问题。深分页的内存和性能消耗依然存在,数据量大时极易造成 OOM,生产环境强烈不建议。
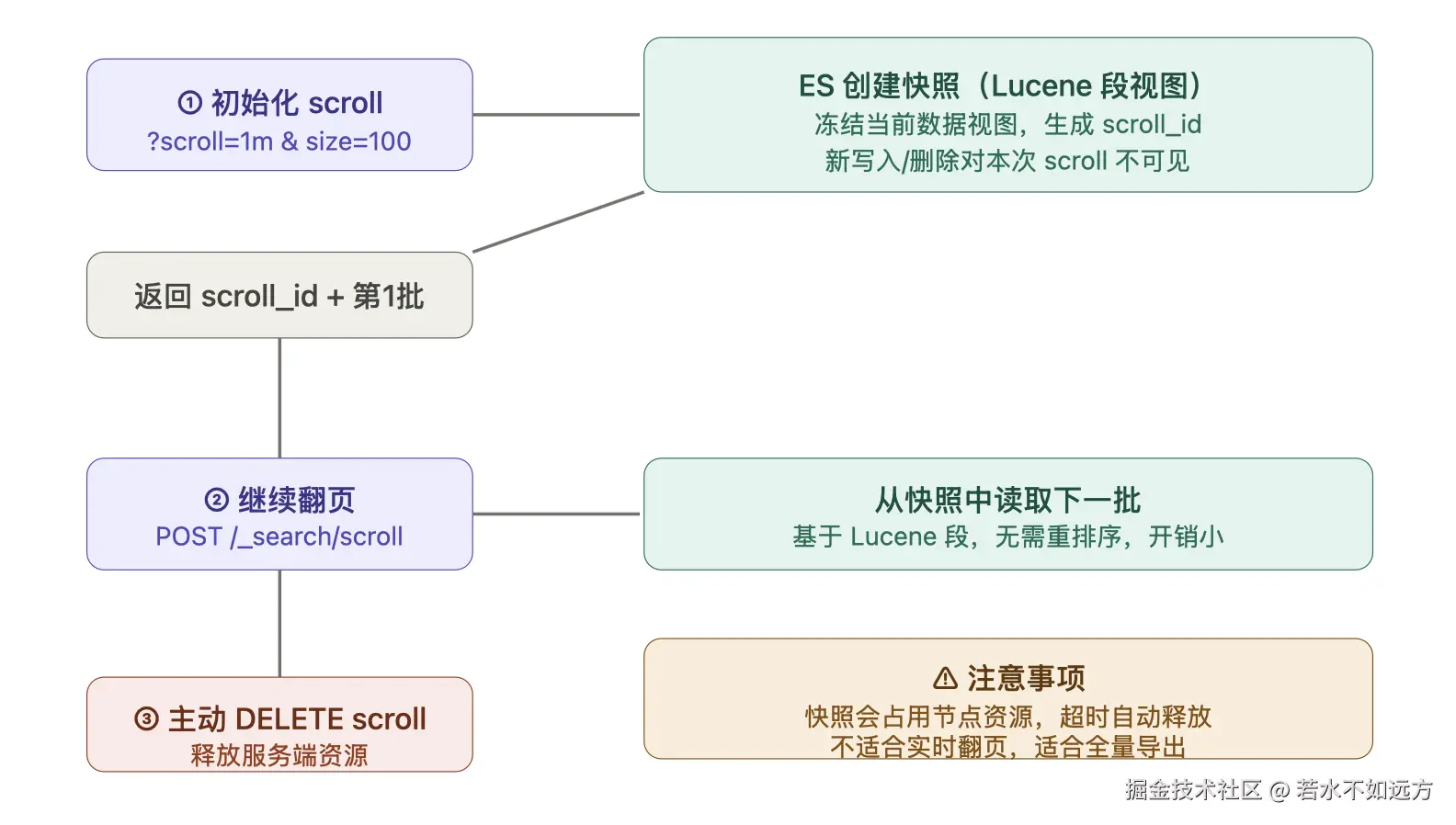
scroll 的思路是:第一次查询时创建一个快照,后续每次通过 scroll_id 取下一批数据,类似游标。
请求示例:
# 第一次:初始化 scroll,保持快照 1 分钟
POST /my_index/_search?scroll=1m
{
"size": 100,
"query": { "match_all": {} },
"sort": ["_doc"]
}
# 后续:用 scroll_id 翻页
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2g..."
}
# 用完后主动释放
DELETE /_search/scroll
{
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2g..."
}
执行原理:
Scroll 的核心缺陷:
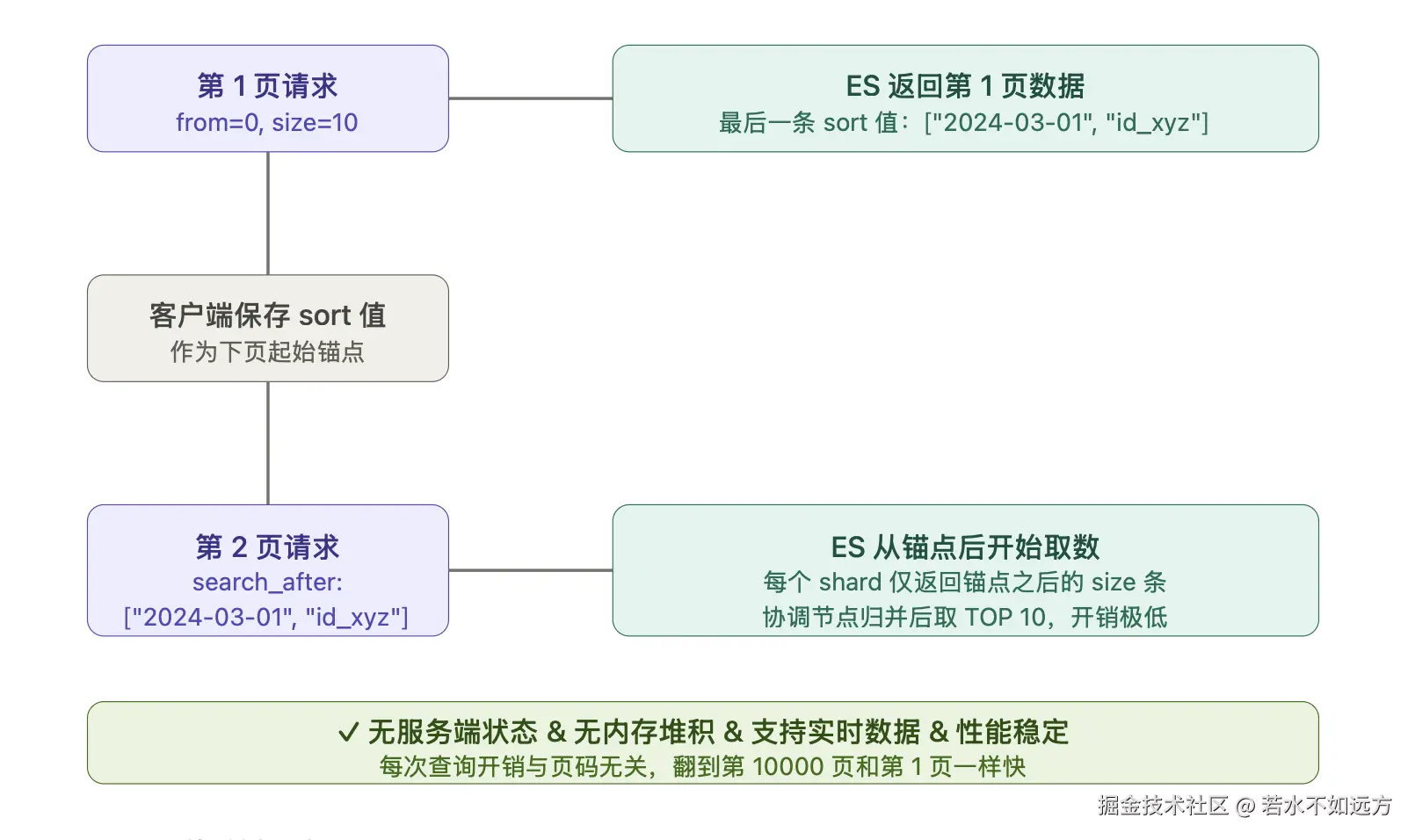
search_after 是目前官方推荐的深分页方案。它的思路非常简单:用上一页最后一条数据的排序值作为起点,查询下一页,完全无状态,不需要服务端维护任何上下文。
请求示例:
# 第一页:正常查询,sort 字段必须唯一或组合唯一
POST /my_index/_search
{
"size": 10,
"query": { "match": { "status": "active" } },
"sort": [
{ "created_at": "desc" },
{ "_id": "asc" }
]
}
# 第二页:取上一页最后一条的 sort 值
POST /my_index/_search
{
"size": 10,
"query": { "match": { "status": "active" } },
"sort": [
{ "created_at": "desc" },
{ "_id": "asc" }
],
"search_after": ["2024-03-01T10:00:00", "doc_id_abc"]
}
执行原理: search_after 的关键要点:
① sort 字段必须能保证全局唯一,否则翻页时会漏数据或重复。常见做法是用业务排序字段 + _id 联合排序。
② 不支持跳页,只能顺序向后翻。如果业务需要"跳到第 500 页",search_after 无法满足。
③ 数据实时性问题:两次请求之间若有新数据写入,可能导致排序变化、结果集漂移。这就引出了终极方案——PIT。
PIT(Point In Time)是 ES 7.10 引入的能力,可以理解为一个轻量级的数据快照 ID。与 scroll 不同,PIT 只创建一个更轻量静态快照,不绑定查询参数,配合 search_after 就能做到:翻页过程中数据视图固定,同时查询参数灵活可变,且无状态。
使用流程:
# Step 1:创建 PIT,保留 5 分钟
POST /my_index/_pit?keep_alive=5m
# 返回 pit.id
# Step 2:使用 PIT + search_after 查询
POST /_search
{
"size": 10,
"query": { "match": { "status": "active" } },
"pit": {
"id": "46ToAwMDaWR5...",
"keep_alive": "5m"
},
"sort": [{ "created_at": "desc" }, { "_shard_doc": "asc" }],
"search_after": ["2024-03-01T10:00:00", 1234]
}
# Step 3:翻页结束后删除 PIT(不手动删除也会自动删除的)
DELETE /_pit
{ "id": "46ToAwMDaWR5..." }
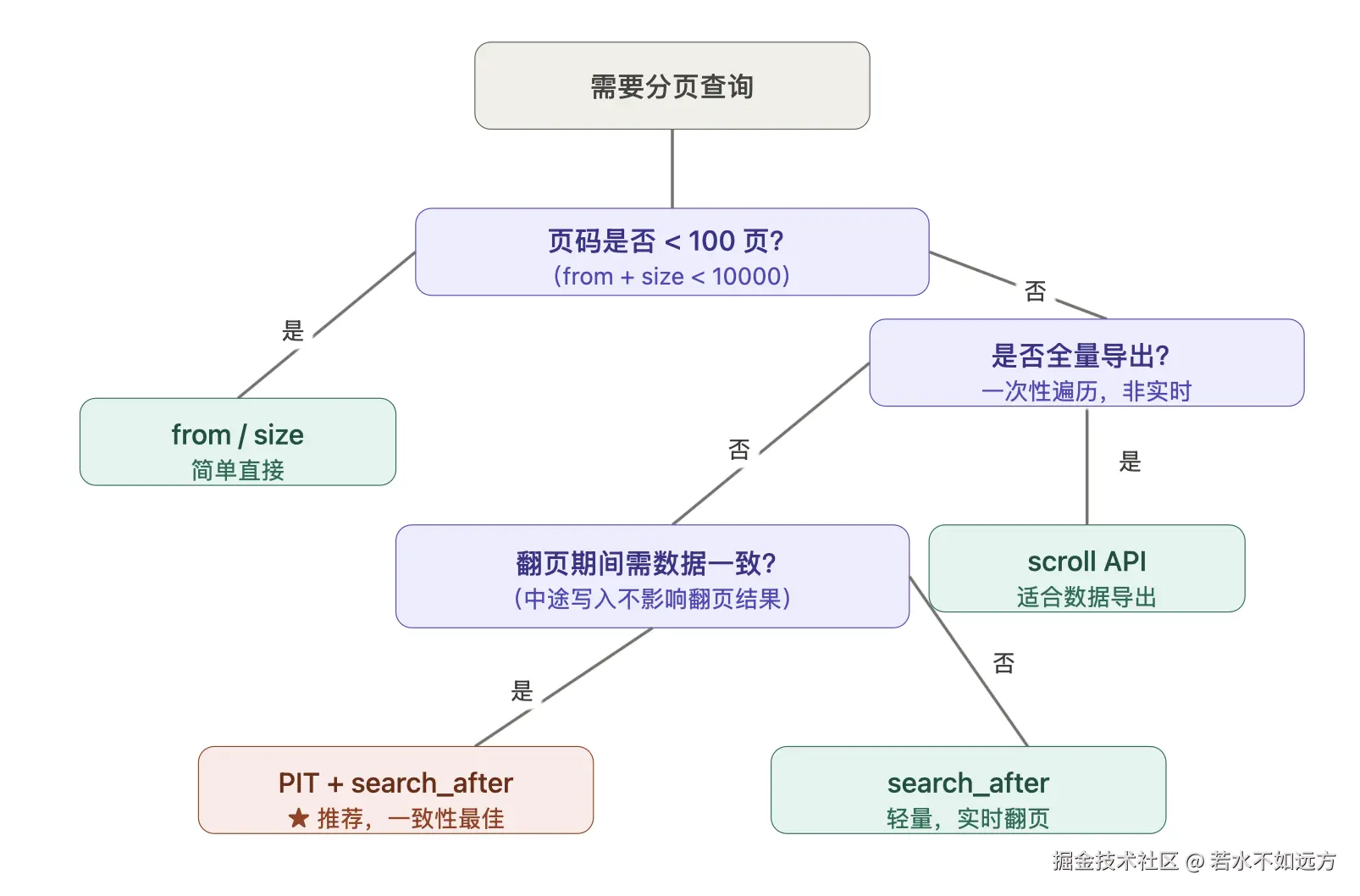
四种种方案对比图:
1. search_after 的 sort 字段设计
sort 字段的组合必须能全局唯一标识一条文档,否则会有漏页或重复:
"sort": [
{ "create_time": "desc" },
{ "_id": "asc" }
]
如果使用 PIT,可以直接用 _shard_doc 替代 _id,性能更好。
2. PIT 的 keep_alive 设置
keep_alive 不是一次性的——每次查询都应该带上它以刷新超时时间。客户端一旦停止翻页,PIT 会在 keep_alive 时间后自动释放。
3. scroll 的资源清理
scroll 上下文在服务端保持 Lucene 段引用,一定要在用完后主动 DELETE,否则大量遗留的 scroll context 会导致内存持续增长。
4. 禁止在生产环境调大 max_result_window
调大 max_result_window 是最危险的做法,既不治本,还可能在某次大查询时直接触发节点 OOM。
5. 跳页妥协
跳页本质是随机访问,最终的目标都是查找数据。解决的思路:
from + size 。深分页的根源是分布式架构的固有约束:每个 shard 只能各自用优先队列选出本地 TOP N 再汇总,页码越深,堆越大,内存压力越高。理解了这一点,选型就没有歧义——from/size 适合浅分页,scroll 适合全量导出,search_after 解决实时深翻页,加上 PIT 保证翻页一致性。调大 max_result_window 不是解决问题,是推迟问题。遇到跳页需求,优先推动产品限制页码上限,分布式场景下任意跳页没有高效解法。
思考题
from/size 的性能问题随页码加深是线性恶化而不是固定开销?Windows + RTX 5090 + ComfyUI 桌面版 安装 SageAttention 完全手册
08-Java工程师的Python第八课-框架入门

