魔神公寓
94.55M · 2026-04-07

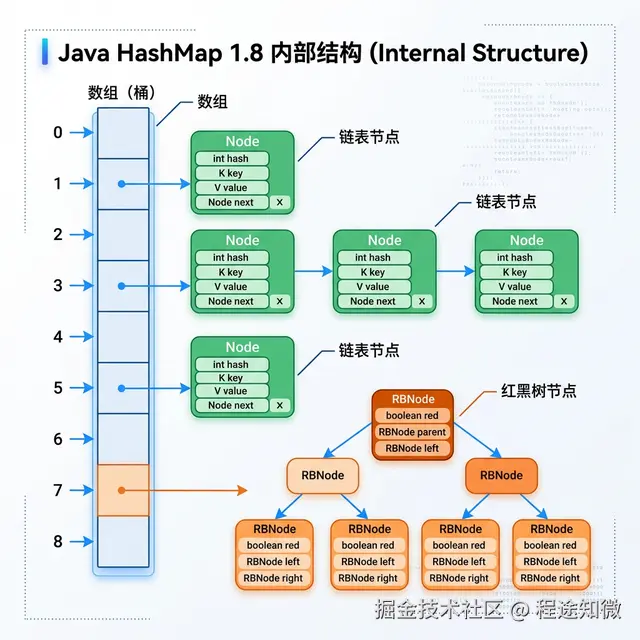
作为 Java 开发者,HashMap 是我们日常工作中最亲密的伙伴,也是面试场上的“常青藤”。每个人都知道它底层是“数组+链表+红黑树”,但如果深究:为什么 Hash 算法要高低位异或?扩容时为什么不再需要重新计算全量 Hash?为什么树化的阈值偏偏是 8?
今天,我们就用资深的视角,一层层揭开 HashMap 那精妙绝伦的设计细节。
在海量数据存储中,我们追求的是 O(1) 的存取速度。然而:
HashMap 的所有设计,都是在空间利用率与时间复杂度之间寻找那个完美的“平衡点”。
在 JDK 1.8 中,Hash 值的计算公式如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
为什么要这样做?
hashCode() 返回的是个 32 位 int 值。如果我们直接拿去对数组长度取模,往往只有低位生效。
通过 (h >>> 16) 让高 16 位也参与异或运算,相当于把高位的特征“混合”到了低位。这样即使低位雷同,只要高位不同,最终结果也会散开。这就是扰动。
HashMap 计算下标用的是 (n - 1) & hash。
当 n 是 2 的次幂(如 16, 32)时,n - 1 的二进制全为 1(如 15 是 1111)。此时进行 & 运算,能够保证结果完美落在 [0, n-1] 范围内,且每一位都有机会参与。如果长度不是 2 的次幂,寻址过程中会出现大量位始终为 0,导致严重的数组位置浪费。
这其实是一个统计学决策。 根据泊松分布(Poisson Distribution),在负载因子 0.75 的情况下,同一个槽位(Bucket)出现 8 个节点的概率约为 千万分之六。这意味着通常链表很短,只有在遭遇极端 Hash 碰撞(如遭受 Hash 攻击)时,为了不让性能雪崩,才会启动红黑树优化。
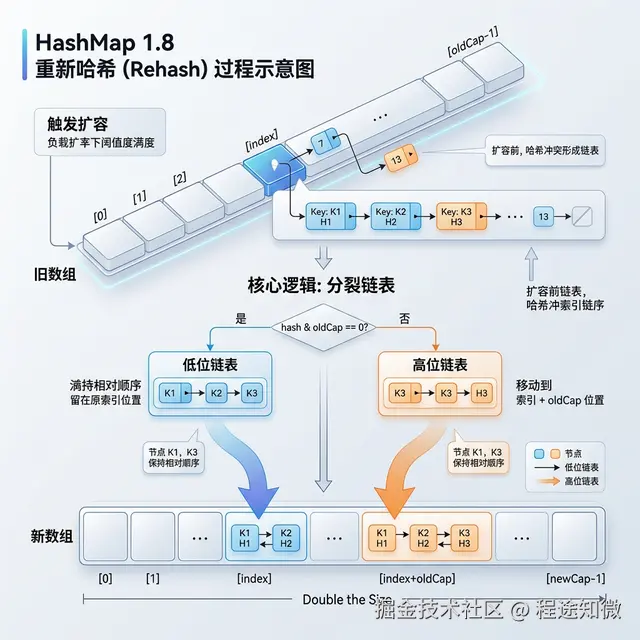
(n - 1) & hash。size > threshold,启动 resize()。传统的扩容需要每个节点重新计算 index = (newCap - 1) & hash,非常低效。
1.8 利用了 2 的次幂特性: 扩容后,原节点的索引位置只会有两种可能:
判断逻辑特别简单:hash & oldCap == 0 的进低位链表(留在原位),否则进高位链表(移动偏移位)。一次遍历,即完成了全量迁移,免去了昂贵的重新 Hash 计算。
为了避免运行时频繁扩容带来的性能停顿,生产环境下我们建议指定初始容量。
import java.util.HashMap;
import java.util.Map;
/**
* 演示:正确预估 HashMap 初始化容量
*/
public class HashMapInitDemo {
public static void main(String[] args) {
// 假设我们要存 100 个元素
int expectedSize = 100;
/*
* 公式:initialCapacity = (expectedSize / loadFactor) + 1
* 若不加此处理,HashMap 会在 100 * 0.75 = 75 个元素时触发第 1 次扩容
*/
int initialCapacity = (int) ((expectedSize / 0.75f) + 1);
// 虽然 HashMap 会自动向上寻找 2 的次幂(此处会转为 256 或更高的 128)
// 但显式计算能最大限度减少扩容带来的 rehash 损耗
Map<String, String> map = new HashMap<>(initialCapacity);
for (int i = 0; i < expectedSize; i++) {
map.put("key_" + i, "value_" + i);
}
System.out.println("数据填充完毕,size: " + map.size());
}
}
纠正:在 treeifyBin 方法中,系统会先检查数组长度。如果 数组长度 < 64,系统会优先选择扩容而不是转红黑树。因为此时数组还比较小,扩容能更有效地分摊节点。
纠正:哪怕是 1.8 解决了 1.7 的死循环问题,HashMap 在多线程 Put 下依然会出现 数据丢失(覆盖写)的情况。并发场景下请务必使用 ConcurrentHashMap。
String 或 Integer,因为它们的 hashCode 是持久化计算并缓存的,且不可变。如果 Key 在存入后变动了其作为 Hash 计算的属性,你将再也找不到原来的 Value。HashMap 的设计充分压榨了位运算的性能,并巧妙利用了统计学规律来应对极端碰撞。理解它的精髓,不仅仅是为了应对面试,更是为了在开发高性能系统时,能够从底层原理出发,写出最优雅、最健壮的代码。

