巨拼门店系统
93.52M · 2026-04-07

第一讲里,我们从高处看了一遍 Claude Code 的整体技术栈。现在开始进入第一块真正会影响日常协作质量的基础能力,也就是记忆系统。
这一讲我想先请你思考一个很具体的问题。
为什么很多人刚开始用 Claude Code 时,会觉得它很聪明,可一旦项目做了几天,就开始觉得它有点不稳定?
表面上看,问题像是出在模型身上。这个会话里答得很好,下个会话里又像换了个人。刚刚才说过项目用 TypeScript strict,转头又给你写出一段松散的 JavaScript。上午刚强调过接口统一走 schema 校验,下午新开一个会话,它又把这一套忘得差不多了。
其实,很多时候问题不在模型突然变笨,而在于你们之间缺了一层长期协作所必需的共同背景。
人和人一起工作,时间久了,会慢慢形成默契。你知道这个团队不喜欢什么写法,知道某些目录为什么不能乱动,知道这类需求大概率该先补测试还是先改 schema。可 Claude Code 默认并不天然拥有这些背景。你不显式提供,它就只能每次从当前对话里临时猜。
这就是为什么记忆系统会成为 Claude Code 工程化使用的起点。
很多人第一次接触 CLAUDE.md,会把它理解成一个提示词文件。这个理解不能算错,但明显不够。
更准确一点说,记忆系统解决的是协作中的重复校准成本。
什么意思呢?
当你和 Claude Code 一起做一个真实项目时,有一批信息会被反复用到。比如项目的技术栈,目录分层,错误处理方式,测试命令,代码风格,甚至你个人的一些固定偏好。它们本身不复杂,但如果每次开新会话都要重新说一遍,协作成本就会越来越高。
所以,记忆系统本质上是在做一件事:把那些反复出现、相对稳定、会影响决策的背景信息,从即时对话里抽离出来,变成长期生效的上下文。
有了这层长期上下文,Claude Code 才更像一个进入过项目、知道基本规则的同事。没有这层东西,它就更像一个每次都临时加入、每次都要重新 brief 的外部顾问。
这两种协作方式,体验差别会非常大。
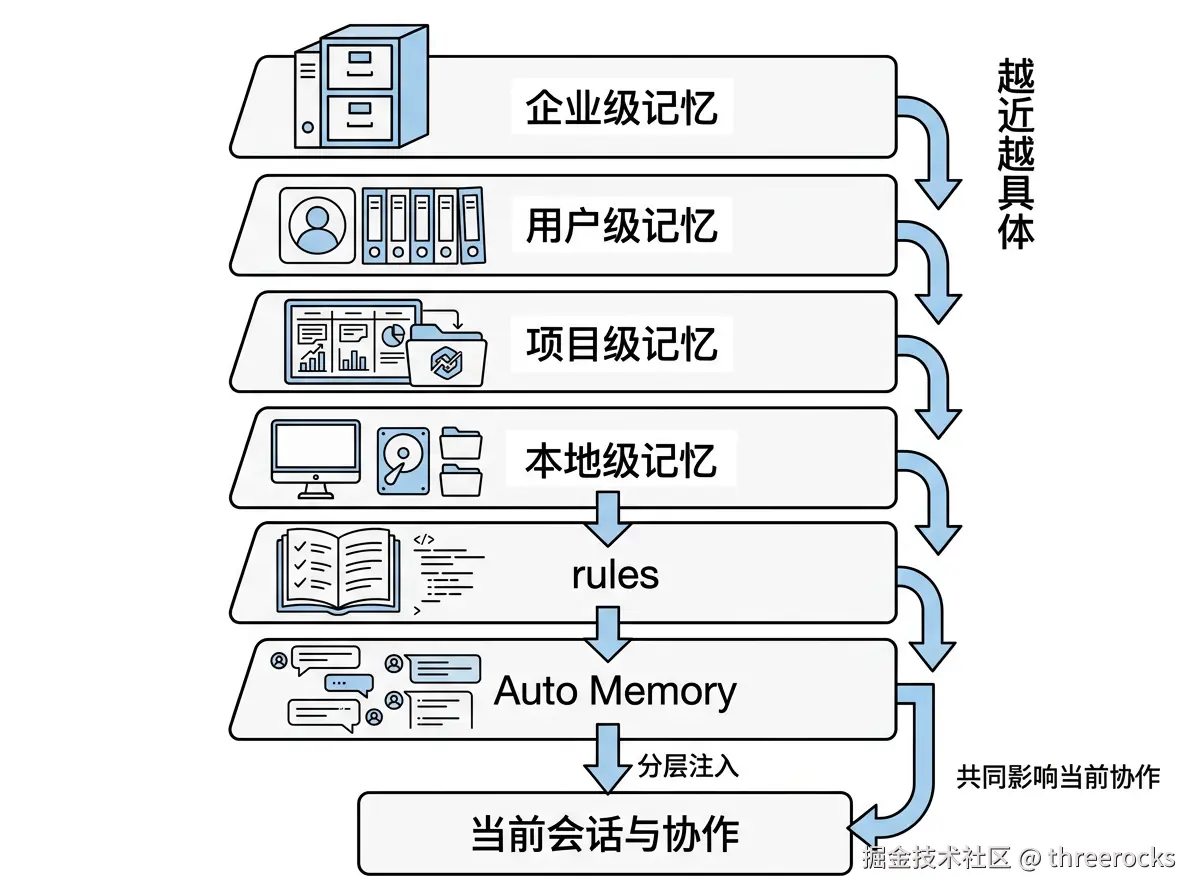
CLAUDE.md如果你把 Claude Code 的记忆理解成项目根目录里那一个 CLAUDE.md,其实只看到了其中一部分。
按照当前官方文档,Claude Code 的长期记忆更像一套分层结构。它既包括你手工写下来的规则文件,也包括系统自己在项目里沉淀出来的 Auto Memory。前者负责定义,后者负责积累。前者告诉 Claude 应该遵守什么,后者让 Claude 在持续协作中慢慢记住一些模式和经验。
所以这一讲,我们不要把视角只盯在一个 Markdown 文件上,而是要把它看成一整套上下文注入机制。
先把这套结构想清楚,后面你才知道什么内容该放哪里,什么内容该长期保留,什么内容根本不值得写。
我们先从最常见的几层作用域开始。
这一层针对的是组织范围内的统一规则。比如安全要求、合规限制、敏感数据处理方式、禁止使用的依赖,或者某些必须执行的审计规范。
官方文档里当前给出的默认位置是:
/Library/Application Support/ClaudeCode/CLAUDE.md/etc/claude-code/CLAUDE.mdC:Program FilesClaudeCodeCLAUDE.md大多数个人开发者碰不到这一层,但在企业环境里,它的意义很大。因为它定义的是组织底线,不是普通项目偏好。项目可以不同,技术栈可以不同,企业级约束通常不能变。
如果你在个人项目里使用 Claude Code,这层了解即可,不是重点。
用户级记忆对应你的长期个人偏好,通常放在 ~/.claude/CLAUDE.md。
它适合记录那些跨项目都大概率成立的习惯。比如你希望默认用中文沟通,注释尽量写英文,常用包管理器是 pnpm,做文档时偏好直接一点的表达,不喜欢太长的铺垫,等等。
它的价值在于让 Claude Code 在不同项目之间,也能保留你的基本工作方式。你不用每开一个新仓库都重新交代一遍。
一个很简单的例子:
# 我的长期偏好
## 沟通
- 默认使用中文
- 注释尽量写英文
- 回答先给结论,再展开
## 编码习惯
- 优先使用 TypeScript
- 优先 async/await
- 默认使用 camelCase
## 常用工具
- 包管理器优先 pnpm
- 编辑器是 VS Code
- 终端使用 zsh
当然,用户级规则并不意味着永远优先。项目规则比它更近,也更具体。你个人偏好 2 空格缩进,但当前仓库明确要求 4 空格,那就应该以项目约定为准。
项目级记忆,才是大多数人最需要认真经营的一层。
官方现在支持把项目记忆放在项目根目录的 CLAUDE.md,也支持放在 .claude/CLAUDE.md。无论选哪种形式,核心都一样,它承载的是团队共享、值得跟着仓库一起演进的项目知识。
这类内容通常包括:
判断标准其实不复杂。只要某件事在这个项目里会被反复提起,而且它会实打实影响 Claude 的行为,就值得写进项目级记忆。
例如一个后端服务项目,可以这样写:
# 项目:订单服务
## 技术栈
- Node.js 20
- TypeScript
- Fastify
- Prisma
- PostgreSQL
- Redis
- Zod
## 目录结构
src/
├── routes/
├── controllers/
├── services/
├── repositories/
├── schemas/
└── types/
## 项目约定
- API 输入统一经过 schema 校验
- 禁止使用 any
- 数据访问集中在 repositories
- 业务错误统一使用自定义错误类型
## 常用命令
- pnpm dev
- pnpm test
- pnpm prisma migrate dev
这里最重要的,是少写正确但空泛的话,多写真正能改变输出结果的项目事实。
比如 写高质量代码、遵循最佳实践、提高可维护性,这类表述人看着都知道没错,但对模型来说过于抽象,很难变成稳定行为。相反,像 所有数据库访问都走 Prisma、controller 不直接写 SQL、API 输入必须先过 schema 这类约束,才是真正有决策意义的内容。
项目越来越大以后,你会发现还有一类信息,其实很重要,但又不适合提交到 Git。这些内容更像是你自己的工作底稿,比如本地环境信息、临时调试技巧、当前正在推进的事项,甚至某些只适合自己保留的测试备注。
这就是 CLAUDE.local.md 的位置。
它通常放在项目根目录,只对当前本地工作空间生效,而且一般应该加入 .gitignore。
例如:
# 本地工作笔记
## 我的环境
- API:
- Redis: localhost:6379
- 调试日志:LOG_LEVEL=debug
## 当前任务
- 正在重构支付模块
- 本周内要补齐集成测试
## 额外备注
- 参考 PR #234 的讨论
这一层很像你写在工位旁边的便利贴。它未必是团队共识,但对你当前这段时间的工作非常有帮助。尤其当你和 Claude Code 长时间协作、经历过多轮压缩之后,这些本地记忆会明显提高接续效率。
前面几层更像固定作用域。rules 则是另一种思路,它解决的是规则不该全量常驻的问题。
当项目开始变复杂时,你很快会遇到一个现实问题。所有规范都塞进主 CLAUDE.md,文件会越来越胖,启动时每次都带着一整坨上下文,真正关键的信息反而被淹没了。
这个时候,正确做法通常是先拆分,再分层管理。
把只在特定场景才需要的规则放进 .claude/rules/。官方文档也支持用户目录 ~/.claude/rules/ 下的规则文件。然后用 paths 把作用范围限定住,让它只在相关文件生效。
比如测试规范:
---
paths:
- "src/**/*.test.ts"
- "tests/**/*.ts"
---
# 测试约定
- 单元测试命名为 `*.test.ts`
- 集成测试命名为 `*.integration.test.ts`
- 优先使用 Arrange-Act-Assert 结构
这样做的好处非常直接。测试规则只会在你处理测试文件时进入上下文,平时写业务代码不会被无关细节占满。
对大型项目来说,rules 很像把团队规范做成按需加载的模块。前端一套,测试一套,接口设计一套,安全一套。主记忆保持稳定和精简,细则按场景触发。
如果前面的内容都属于你主动配置的长期记忆,那么 Auto Memory 则是 Claude Code 自动沉淀出来的项目记忆。
根据当前官方文档,Auto Memory 默认开启。它会在 ~/.claude/projects/<project>/memory/ 目录下为项目维护记忆文件,入口通常是 MEMORY.md,旁边还可以继续拆分出其他主题文件。
这一层的意义是补充 CLAUDE.md,不是替代它。
你可以把它理解成项目合作过程中形成的经验缓存。某个目录历史负担很重,某类错误通常要先查哪个中间件,或者这个仓库里新增接口时习惯先补 schema 再写 route。这些内容未必一开始就会被你写进项目级记忆,但随着协作推进,Claude Code 可以把它们沉淀下来。
不过这里有个判断一定要有。真正稳定、重要、团队需要长期共享的规则,最好还是回写到 CLAUDE.md 或 rules 里。Auto Memory 更适合承接经验,不适合作为团队治理的主入口。
讲到这里,问题就变成了另一个更实际的话题。
到底什么样的内容,才配写进 CLAUDE.md?
我给你一个特别简单的标准。
如果这条信息写进去之后,能够稳定改变 Claude Code 在项目中的行为,那它大概率值得保留。反过来,如果你不写,它多半也会做得八九不离十,那这条内容的价值通常不高。
所以,一份真正有用的记忆文件,最应该回答的其实是三个问题。
第一,为什么这样做。
如果只是告诉它结论,很多时候只能形成机械遵守。把决策背后的背景补上,它在遇到相似问题时才更容易做出一致判断。
例如:
## 为什么使用 Zod
- TypeScript 只覆盖编译期类型检查
- API 输入还需要运行时验证
- Zod 可以统一类型和校验逻辑
第二,边界在哪里。
也就是哪些事情能做,哪些事情不要做,应该在哪一层做。
例如:
## 数据库访问规则
- 所有查询统一走 Prisma
- 复杂查询封装在 repositories
- controller 和 service 中不要直接写 SQL
第三,默认工作流是什么。
当团队内部已经形成稳定步骤时,直接写出来最省事。
## 新增 API 的默认流程
1. 在 schemas 中定义输入输出
2. 在 routes 中注册路由
3. 在 controllers 中处理请求
4. 在 services 中补业务逻辑
5. 在 tests 中补齐测试
这三件事加起来,Claude 的行为会稳定很多。因为它接收到的已经从散乱偏好,变成了一套能指导判断的默认决策模型。
很多人看到这里会有一个冲动,既然记忆这么重要,那我是不是应该把所有东西都写进去?
答案通常是否定的。
原因也很现实。CLAUDE.md 会参与长期上下文构建,体积越大,成本越高。真正有价值的做法,是把它写成默认决策入口,而不是项目百科全书。
更细的内容,应该拆出去。
当前官方文档支持在 CLAUDE.md 里通过 @路径 引入其他 Markdown 文件,甚至可以引入 AGENTS.md。这意味着你完全可以把数据库设计、接口规范、部署文档、测试清单拆到独立文档里,让主记忆保持轻量。
比如:
# 项目核心规范
## 默认规则
- 使用 TypeScript strict
- 输入统一做 schema 校验
- 组件按功能目录组织
## 补充资料
- API 规范:@docs/api.md
- 数据库设计:@docs/database.md
- 发布流程:@docs/deployment.md
这个思路很重要。主文件负责给方向,外部文档负责给细节。真正需要的时候再展开,而不是一上来把所有资料都塞进启动上下文。
如果你现在正准备给一个新项目建立记忆,我建议你按下面的顺序来。
先用 /init 生成初始项目记忆。按照当前官方文档,它会基于代码库帮你起草 CLAUDE.md,如果你启用了更新的交互式初始化体验,它还会顺带协助配置 commands、hooks 或 agents 的初始结构。
然后你做的第一件事,最好不是继续往里加内容,先删掉低价值信息更重要。
把项目里最稳定、最常用、最能改变行为的部分留下。技术栈、目录结构、固定命令、默认工作流、重要约束。先把骨架搭起来。
接着,如果你有个人环境或阶段性任务,再补 CLAUDE.local.md。如果项目规范很复杂,再把测试、前端、接口、安全等规则拆到 rules 里。
这么做的核心好处是,记忆系统从第一天开始就是分层的,而不是等文件膨胀之后再回头返工。
一个常见的危险信号是,CLAUDE.md 明显越来越长,但 Claude Code 的表现并没有更稳定。
你以为自己是在补充知识,实际可能是在稀释重点。
这时候可以用一个很简单的三步法来处理。
先问自己,哪些内容是每次协作都必须知道的。如果不是每次都需要,那它就不一定应该留在主记忆里。
再看这些内容能不能拆分。详细 API 文档、数据库字段说明、部署流程、排障笔记,大多数都更适合独立文档,或者改成规则文件按条件触发。
最后,检查有没有空话。很多写给人的口号,写给模型时几乎没有约束力。与其写 要注意代码质量,不如直接写 新增接口必须补测试。后者虽然更窄,但执行起来更稳定。
记忆文件真正要追求的,是更高的命中率,不是体量感。
/memory 的价值,在于帮你检查现实而不是想象很多时候,我们以为某条规则已经在发挥作用,其实只是自己以为它会生效。
所以我很建议你养成一个习惯。写完记忆之后,直接用 /memory 看看当前会话到底加载了什么。
按官方文档,/memory 会展示当前加载到的项目记忆、用户记忆、本地记忆、rules,以及 Auto Memory 的状态。这个命令最有用的地方,就是帮你把 觉得已经生效 变成 真正确认已生效。
比如你可以拿它排查这些问题:
很多协作问题,最后查下来往往不是模型理解错了,问题出在记忆根本没有按你以为的方式组织进来。
这一点在实际使用里非常重要。
CLAUDE.md 会强烈影响 Claude 的行为,但它本质上仍然属于协作层和提示层。它很适合表达长期规则、偏好和工作约定,却不等于底层权限系统。
真正涉及执行边界、审批要求、工具访问控制时,应该放在对应的设置体系里。当前官方文档也明确把 settings.json、managed settings 和 CLAUDE.md 分开处理。
你可以把这件事理解成两类约束。
一类是 你应该怎么做,这适合写进记忆。
另一类是 你最多能做到哪一步,这属于系统配置和权限控制。
把这两类东西分开,你的协作策略才会更稳。

