
魔方还原
68.92M · 2026-04-09

如果你正在用 LangGraph 构建多智能体系统,大概率遇到过这些问题:
工具不是问题——LangGraph 的 API 足够强大。真正的难点在于架构决策。
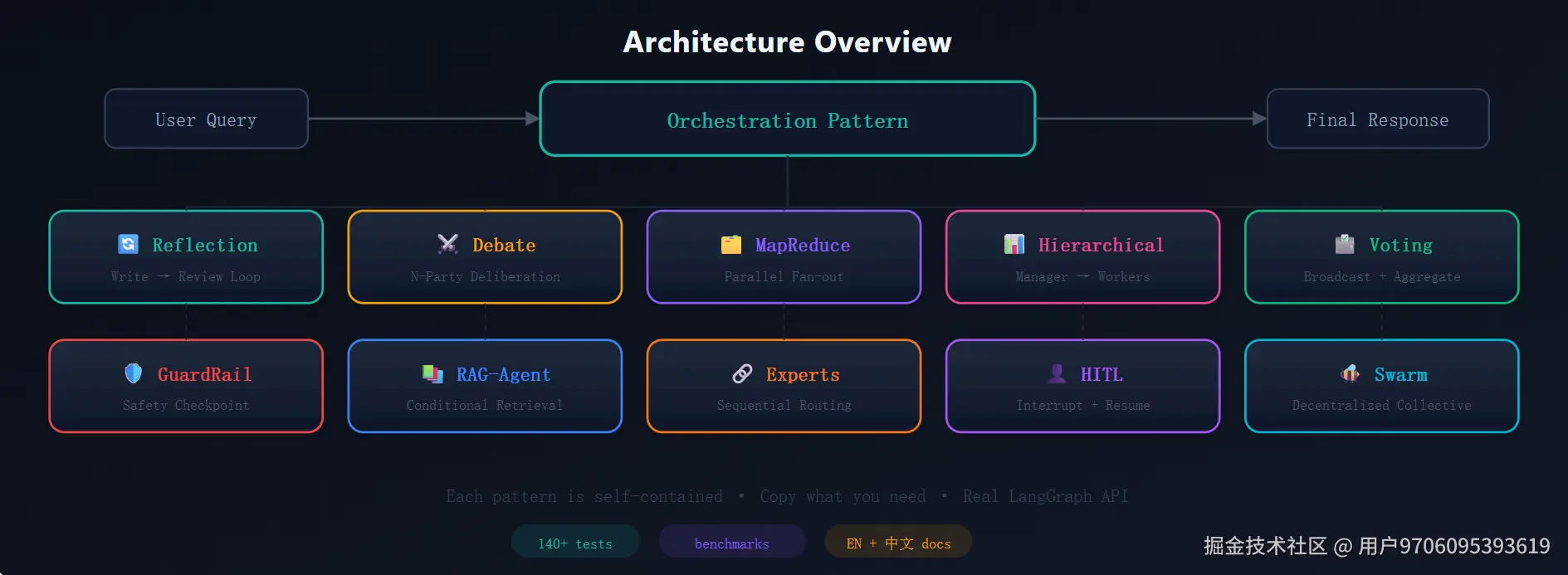
所以我做了 AgentFlow:一本多智能体设计模式的参考手册。不是框架,不是教程合集,而是 10 种经过实战验证的协作模式,每种都包含完整代码、架构图、单元测试和中英双语文档。
先看全景。AgentFlow 包含以下 10 种模式,覆盖了从最简单的自我修正到去中心化群体智能的完整谱系:
| 模式 | 核心思想 | LangGraph 关键技术 |
|---|---|---|
| Reflection | 写 → 审 → 改,循环直到达标 | 条件边 + 状态循环 |
| ️ Debate | N 方辩论 + 主持人裁决 | 异步并发 + 结构化输出解析 |
| ️ MapReduce | 并行分发 → 汇总合成 | Send API 动态扇出 |
| Hierarchical | 经理拆任务 → 员工执行 → 经理汇总 | 嵌套子图 + Send |
| ️ Voting | 多 Agent 独立投票 → 聚合结果 | 广播扇出 + 加权统计 |
| ️ GuardRail | 主 Agent + 安全守门员 | approve/block/redirect 三路由 |
| RAG-Agent | Agent 自主决定是否检索 | 条件检索循环 + 可注入 retriever |
| Chain-of-Experts | 任务流经多个专家节点 | 顺序路由 + 上下文累积 |
| Human-in-the-Loop | 关键节点暂停等人类确认 | interrupt + resume |
| Swarm | 去中心化群体协作 | 异步消息传递 + 聚合器 |
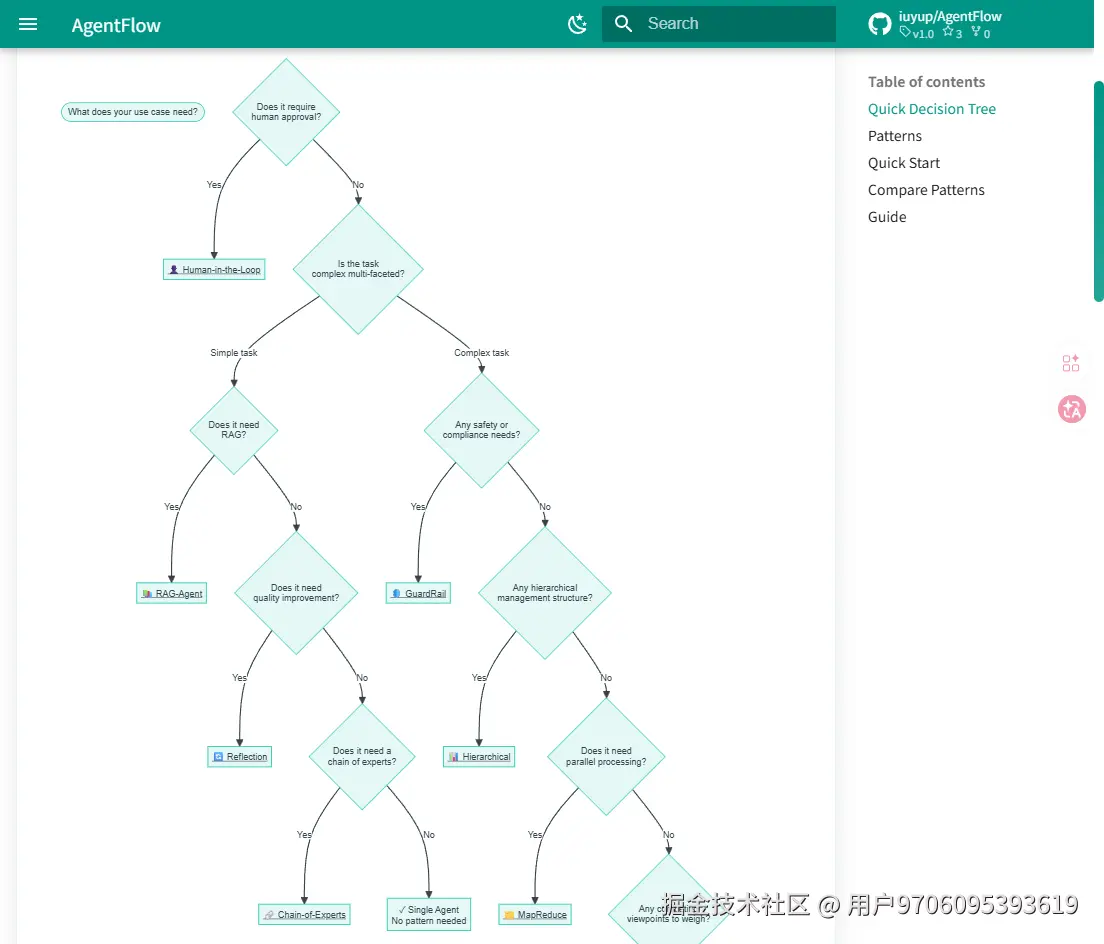
这大概是整个项目最实用的部分。我画了一棵决策树,从你的场景需求出发,4 层二元判断,精确导航到对应模式:
简单总结几条规则:
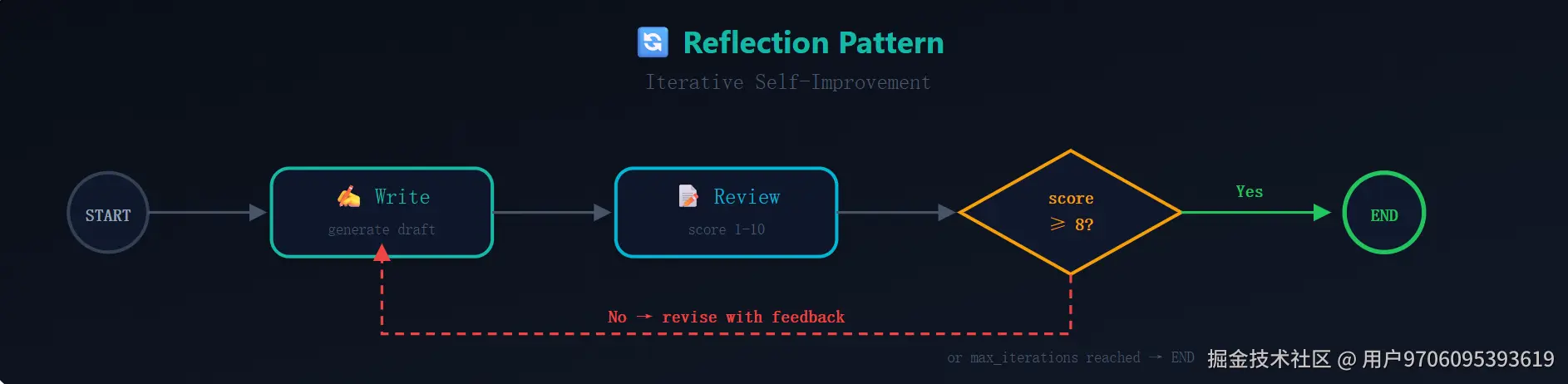
这是最简单的模式,但效果惊人地好。核心思想是人类编辑流程的 Agent 版本:
写手出初稿 → 审稿人打分+反馈 → 写手修改 → 审稿人再打分 → ...直到分数达标或达到最大轮次
核心代码非常简洁。LangGraph 的条件边天然适合这种"满足条件就退出,否则循环"的模式:
class ReflectionPattern:
def build_graph(self) -> StateGraph:
graph = StateGraph(ReflectionState)
graph.add_node("write", self._write_node)
graph.add_node("review", self._review_node)
graph.add_edge(START, "write")
graph.add_edge("write", "review")
graph.add_conditional_edges(
"review",
self._should_continue,
{"continue": "write", "end": END},
)
return graph.compile()
def _should_continue(self, state: ReflectionState) -> str:
if state["score"] >= self.score_threshold:
return "end"
if state["iteration"] >= self.max_iterations:
return "end"
return "continue"
三行条件判断,就实现了一个完整的写作-审阅循环。运行效果是:初稿可能只有 5/10 分,经过 2-3 轮修改,通常能达到 8/10 以上。
适用场景: 文章写作、代码生成后自审、报告迭代优化。
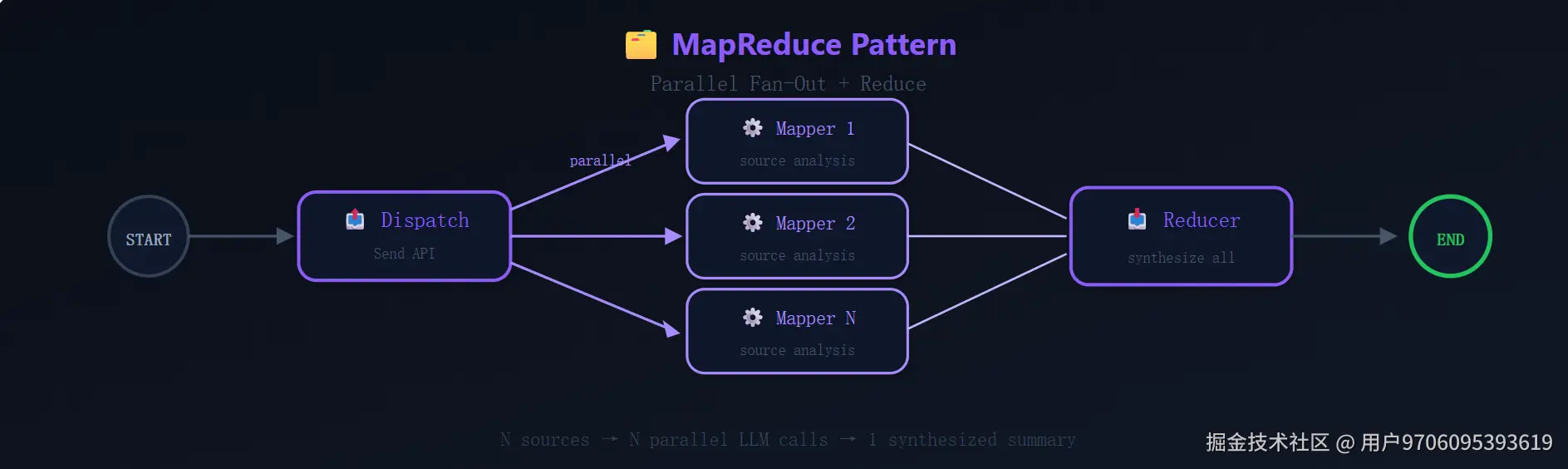
当你需要从 N 个数据源并行收集信息再汇总时,这个模式是最优解。关键在于 LangGraph 的 Send API——能在运行时动态决定并行分支的数量:
class MapReducePattern:
def _dispatch(self, state: MapReduceState) -> list[Send]:
"""运行时动态创建 N 个并行 mapper"""
return [
Send("mapper", {"source": source, "topic": state["topic"]})
for source in state["sources"]
]
def build_graph(self) -> StateGraph:
graph = StateGraph(MapReduceState)
graph.add_node("mapper", self._mapper)
graph.add_node("reducer", self._reducer)
# 关键:用 conditional_edges + Send 实现动态并行
graph.add_conditional_edges(START, self._dispatch, ["mapper"])
graph.add_edge("mapper", "reducer")
graph.add_edge("reducer", END)
return graph.compile()
3 个数据源就并行 3 个 mapper,10 个就并行 10 个——完全由输入数据决定,不需要提前硬编码分支数量。
适用场景: 多源新闻聚合、并行文档摘要、分布式数据提取。
很多"多 Agent"项目看起来是并行,实际上是 for agent in agents: llm.invoke()——串行调用。在 AgentFlow 中,Debate 和 Swarm 使用 asyncio.gather + ainvoke 实现真正的并发:
async def _debate_round(self, state: DebateState) -> dict:
tasks = [
self._call_debater(debater, state["topic"], ...)
for debater in state["debaters"]
]
results = await asyncio.gather(*tasks) # 真正的并发
return {"debate_history": list(results)}
3 个 debater 同时调用 LLM,耗时约等于 1 次调用而不是 3 次。在 Agent 数量多的场景下差异非常明显。
很多 RAG 示例项目都是硬编码 mock 数据,看完 demo 就没法用了。AgentFlow 的 RAG-Agent 把检索函数设计为可注入参数:
RetrieverFunc = Callable[[list[str]], list[dict]]
class RAGAgentPattern:
def __init__(self, retriever: RetrieverFunc | None = None):
self.retriever = retriever or _default_mock_retriever
默认用 mock 跑 demo,但接入真实向量库只需一行:
pattern = RAGAgentPattern(retriever=my_chroma_retriever)
Benchmark 不应该用"估算"。AgentFlow 通过 LangChain 的 CallbackHandler 实现精确计数:
class LLMCallCounterHandler(BaseCallbackHandler):
def on_chat_model_start(self, serialized, messages, **kwargs):
self._count[0] += 1
每个 pattern 的 run() 方法返回值里都包含 llm_call_count 字段,Benchmark 框架直接读取真实数据。
单个 Pattern 已经有用,但真正的威力在于组合。项目的 examples/ 目录包含两个组合案例:
AI Newsroom(AI 新闻编辑部) = MapReduce + Debate + Reflection:
多源并行采集新闻 → 正反方辩论新闻价值 → 编辑循环打磨成稿
整个流程模拟了一个真实新闻编辑部的工作方式:记者分头采访,编辑部讨论角度,主编反复打磨。三种模式各司其职,通过 LangGraph 的状态流串联起来。
Research Team(研究团队) = Hierarchical + Chain-of-Experts:
项目经理拆分子任务 → 各领域专家顺序分析 → 项目经理汇总报告
说几个硬指标:
git clone
cd AgentFlow && uv sync
cp .env.example .env # 填入你的 API key
python -m patterns.reflection.example
这个问题肯定有人会问,直接回答:
AgentFlow 不是框架,是参考手册。 CrewAI 和 AutoGen 是帮你"快速搭建"多 Agent 系统的工具,它们在 LLM 之上加了一层抽象。AgentFlow 的哲学完全不同——直接用 LangGraph 原生 API,不加任何中间层。
这意味着:
用设计模式的类比来说:你不会因为学了"观察者模式"就必须引入一个观察者框架。Pattern 是思想,不是依赖。
如果你觉得这个项目有用,欢迎在 GitHub 上点个 Star:
也欢迎提 Issue 或 PR。如果你有实际项目中遇到的多 Agent 架构问题,评论区聊聊,我可以帮你分析适合哪种模式。

