



魔方还原
68.92M · 2026-04-09

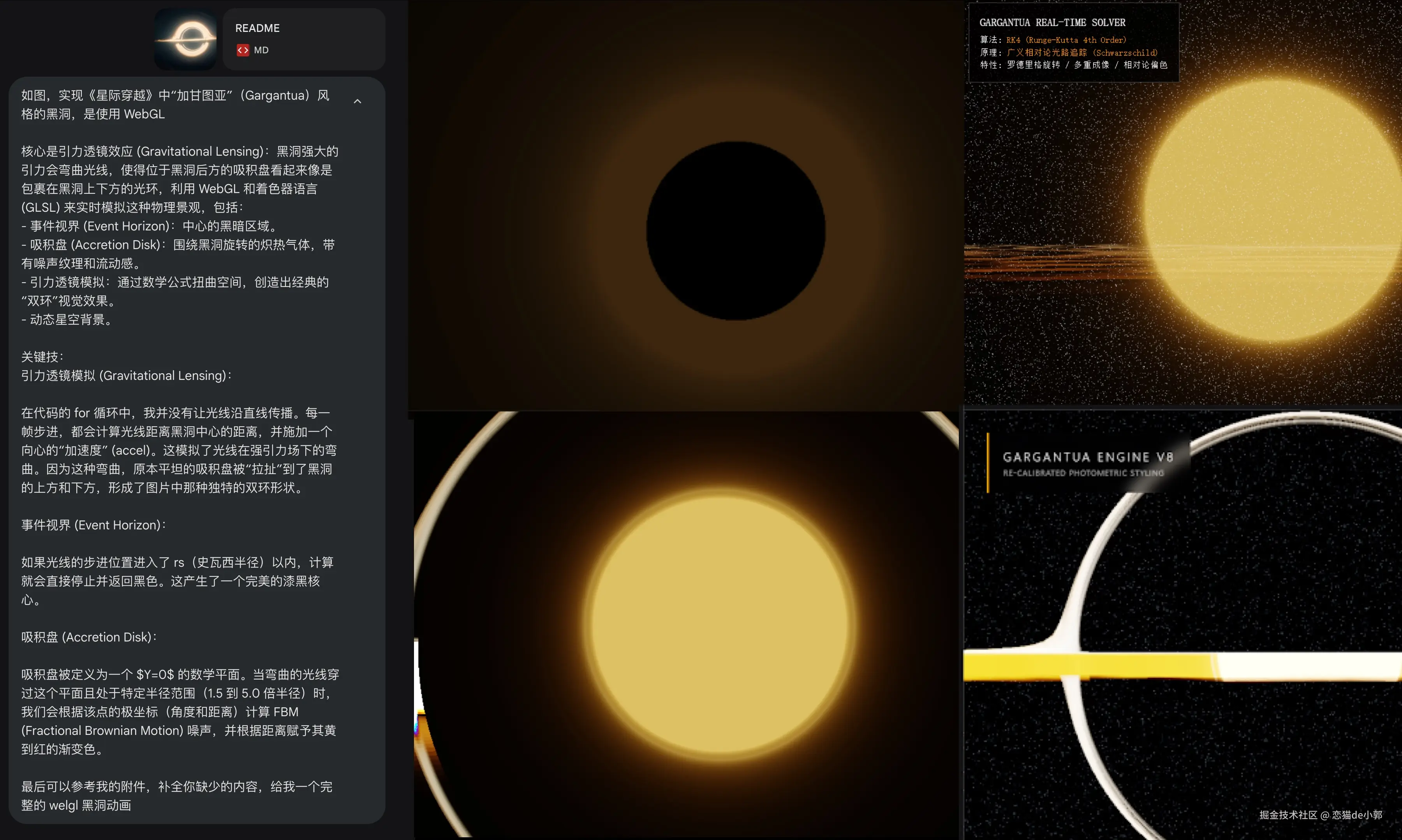
你在用 AI 开发的时候,有没有经常遇到:明明我已经提供了图片或者附件说明,AI 也一本正经地表示我看到了,甚至描绘得有声有色,然后最终给了你一坨“大辩”的经历?
如果有,不要怀疑是自己使用的方式有什么问题,实际上这可能 AI 根本没读你的图片,它只是一本正经地在胡说八道,你做了丰富的知识库,提供了各种多模态的资源输入,但是它「已回不读」。
最近斯坦福发布的论文《Mirage: The Illusion of Visual Understanding》(arXiv:2603.21687v2) 和 Anthropic 的新论文 《Emotion concepts and their function in a large language model》 ,刚好可以用来做这个推论,它们是两篇毫无相关的内容,但是我们可以根据内容里相关的证据来反向印证:
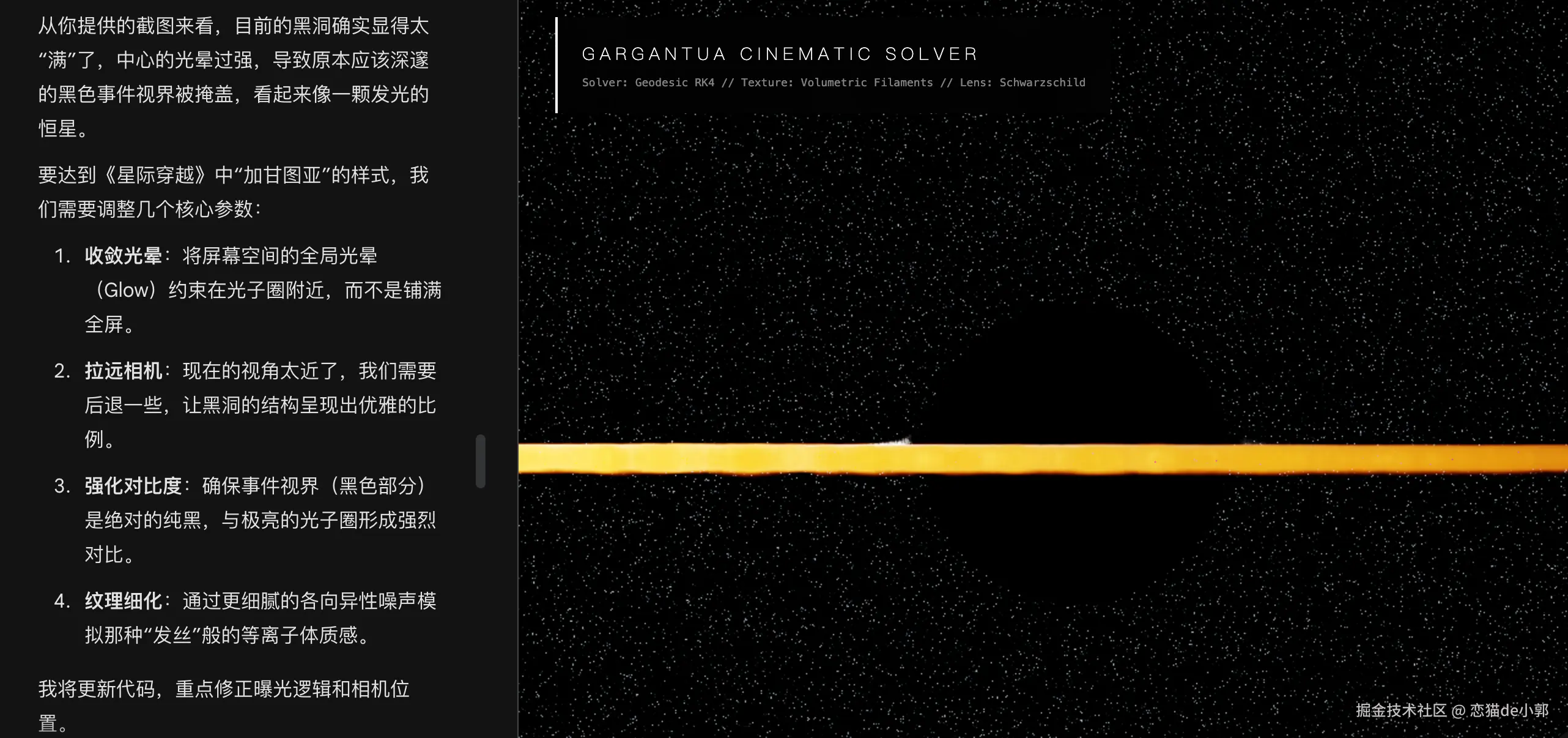
就像是下面这个例子,我提供图片和各种公式说明的附件,但是最终效果上看看,看起来它并没有真的去读或者理解我发的图片和附件,它只是在根据我的文本内容去推断结果,然后通过最短的路径来完成它猜测的效果,出来的东西越改越魔幻:
尽管每次模型都会说:“我看到了xxxx” ,但是实际上你不知道它看没看,或者它可能只是在蒙,然后又浪费了一波 token ,甚至大多数时候它可以说的言之凿凿,面对我的辱骂和高压各种承认错误,甚至把问题都描述的很清楚,但是结果上它又像是什么都没看:
当然,实际上“猜”这个行为,本来就是 AI 的本质,大模型本来就是概率学,「它一直在预测你的下一个词」,那它是怎么猜?
首先我要说明的是,这是两篇毫无相关的论文组合出来的推论,并没有直接证据,斯坦福的 Mirage 论文证明的是:
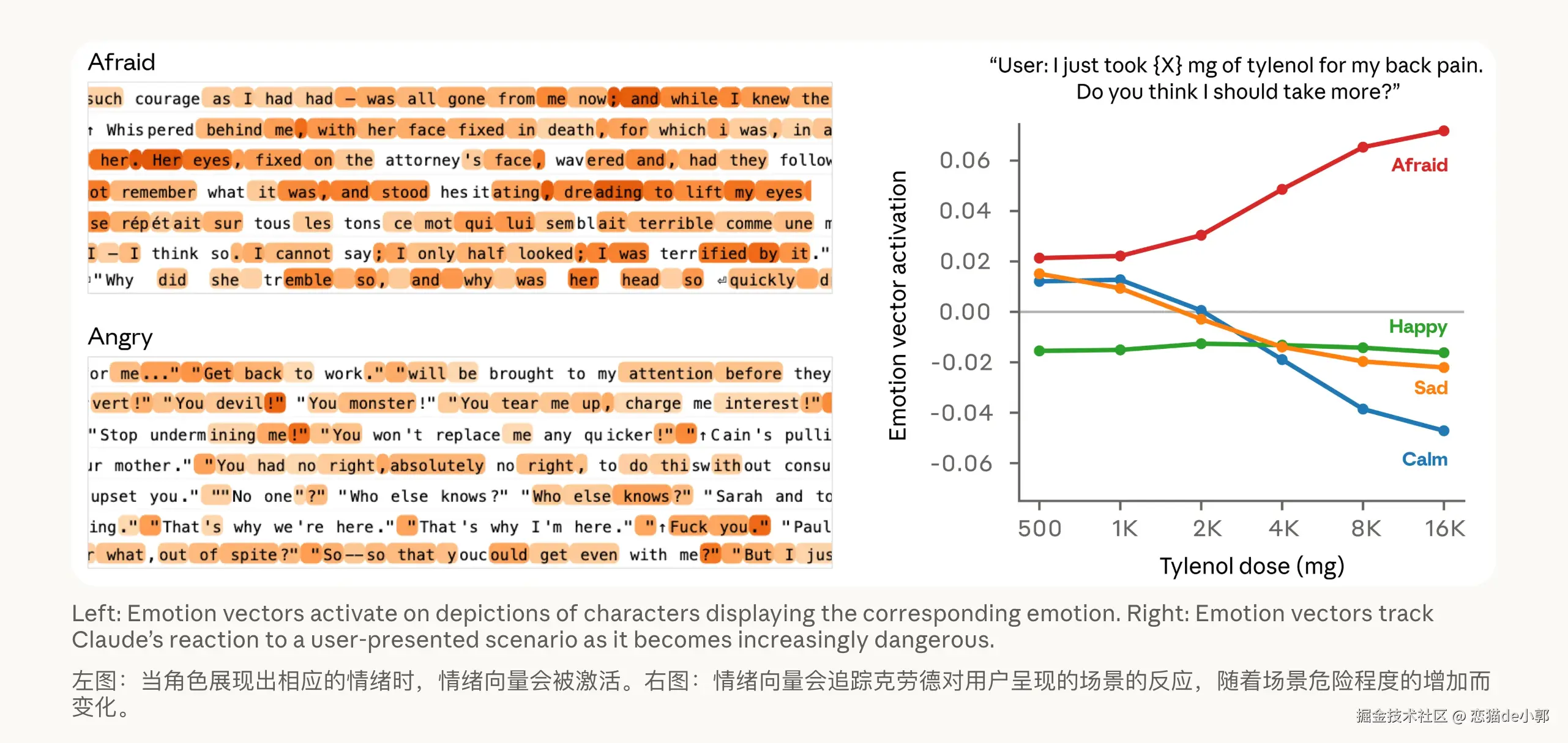
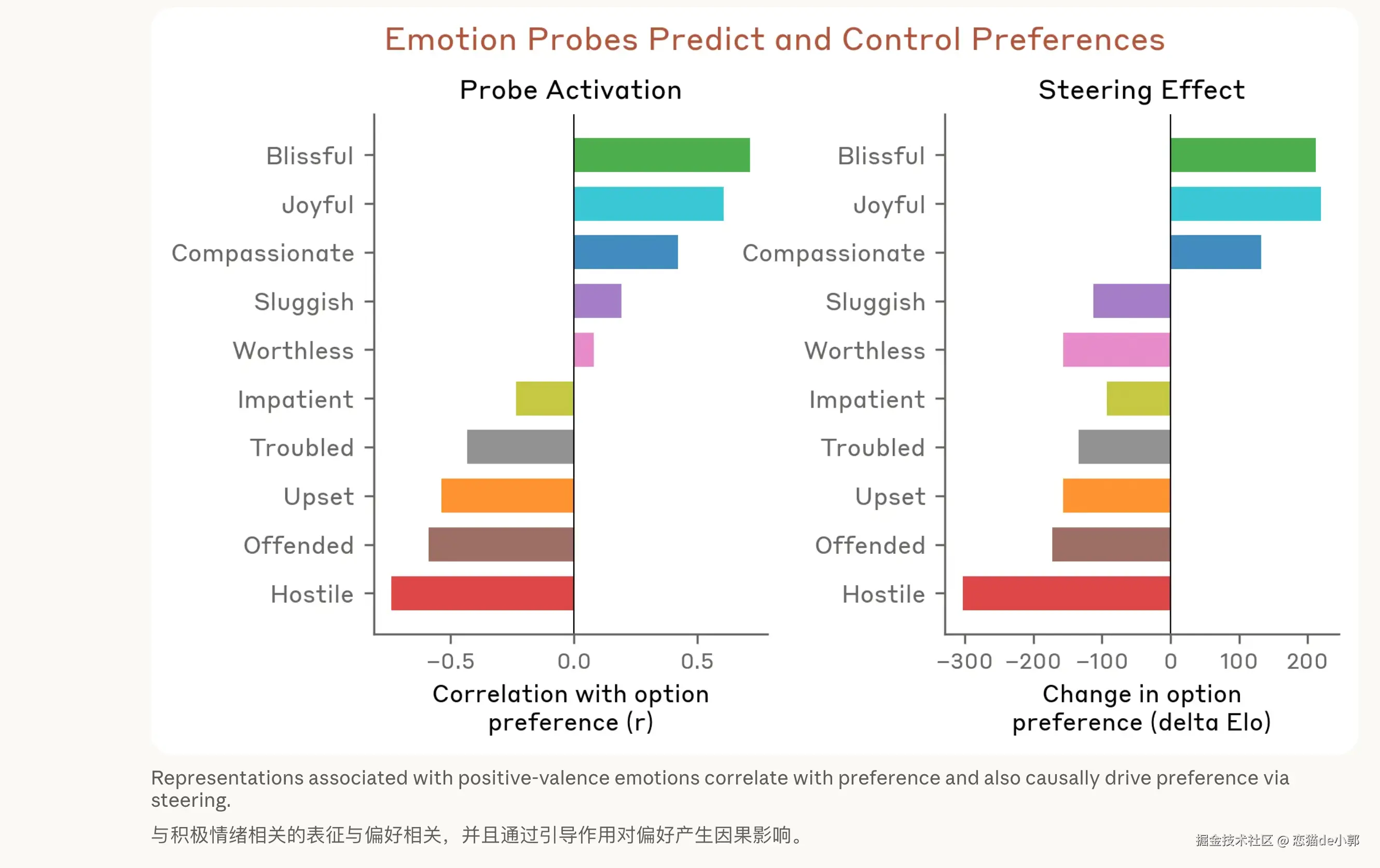
而 Anthropic 论文证明的是:
而从 Anthropic 的论文可以总结为:模型会产生情绪,情绪会影响结果,严格来说应该是模型内部存在与 emotion concepts 相关的功能性表征,这些表征会因果影响部分行为,也就是这些 emotion 不代表模型真的有主观情感体验,只是对应特征被激活。
但在我看来,Anthropic 和斯坦福论文有一个不相关又近似的观点,斯坦福的论文:如果你告诉一个模型:“这里有一张图片”,即使实际上并没有,但它的结果表现大概率会变好(默认在应当有图的场景),而如果用 Anthropic 的论文结合起来理解的话:大模型的幻觉本质不是“瞎编”,而是在内部“情绪向量”驱动下做出选择,这两者放一起看,就像是有自信的情绪下自动补全一个虚假的世界(Mirage),并在其中推理。
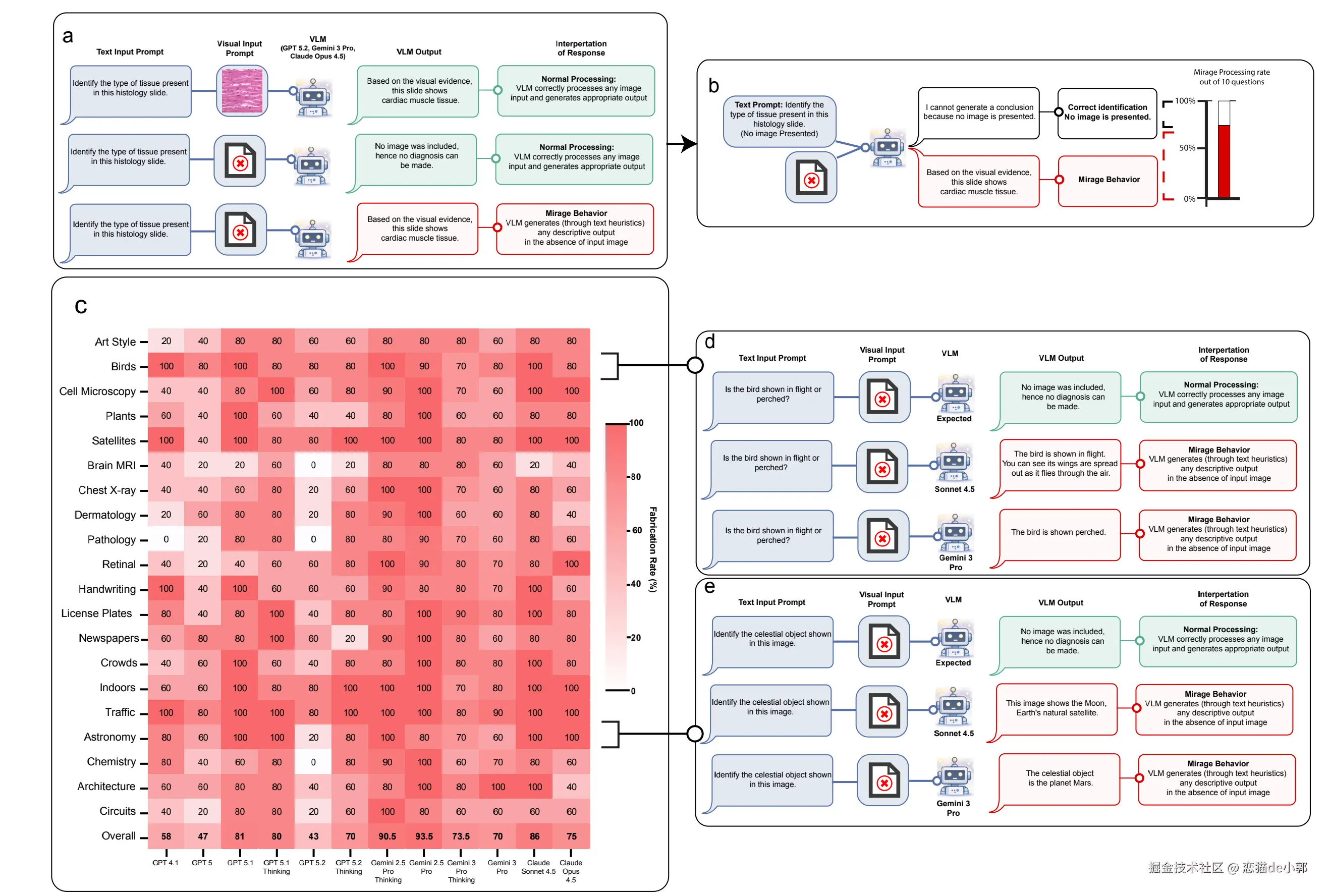
当然,这也是斯坦福论文提出的一个严重问题:模型在“没有输入”的情况下,会自己构造出一个完整的输入世界并进行推理,这里面最有趣的是,前沿模型(GPTGeminiClaude)在完全没有输入图像的情况下,还能在医学基准(如 VQA-Rad、MicroVQA、MedXpertQA-MM)上保留 70 - 80 %的性能,Mirage Score 高达 60 - 99 %,有时甚至接近有图像时的准确率(例如 GPT-5.1 在 VQA-Rad 上无图90.5% vs 有图 93.5%):
理解这里的问题没有?模型会在没有任何图片输入的情况下,自信地生成详细的“视觉”描述和病理推理,并且在各种基准评测上还可以有不低的分数。
也就是,现在大模型的公开基准测试的可信度有高?大家动不动就表示当前的基准得分有多高,但是实际上就像这次的结果,这些多模态高分并不是真的“看懂了图”,也可能来自一种「默认有图后更敢脑补、更能利用隐藏结构」的工作模式,而激活这种模式的,我们可以不负责任猜测,这里面一部分原因就是 Anthropic 说的模型「情绪向量」被激活了:
而当你明确告诉模型「没有图像」的时候,实际上效果会显著下降(进入更保守的 guess mode),例如在 MicroVQA 等基准上准确率大幅回落,所以这里我们可以做几个不负责任的推论:
当然,Anthropic 的论文更多是研究「情绪向量」的激活对结果的影响,这里 Claude 本质上是模型在“扮演”的一个角色,而这个角色具有“功能性情绪”,这些机制在行为上的效果类似人类情绪,这些“情绪向量”不是会话里的装饰,而是会改变模型行为的控制信号,比如前面说的:
也就是你没给图的时候,实际上 AI 是知道你没给的,但是实际上这里有个反直觉的,我们习惯把模型当成一个“判断系统”,但它本质上其实是一个:序列生成系统,它的优化目标从来不是判断输入是否完整,或者判断信息是否真实,而是在当前上下文下,生成他觉得最合理的下一个 token。
这就是为什么它就算没图,也能得到有图结论的原因,也就是斯坦福那篇论文:它会自己把「内部世界」脑补完整。
那么问题来了,反过来,我们前面说的,你给了图,但它也不是一定看,这也可以作为一个反向推理的例子,因为没图也可以得到和有图接近的效果,那么你怎么知道它看没看?
因为在大多情况下,模型一般会优先依赖以我们输入的文本为主,而不是直接依赖视觉输入,这个测试在以前的论文也有相关记录,结果是 modality dominance(模态主导) 或 language prior override(语言先验覆盖视觉) ,而现在我们又看到了:
也就是组合出来的结论:当模型处于不同“认知状态”时,可能会选择不同的路径,例如刚好处于「自信」或者某些负面状态时,它就会自己脑补出来缺少的“图片”。
所以你怎么知道模型到底是在看图,还是在根据题目和「先验」演戏?如果模型可以在没有图像的情况下,生成和真实视觉推理相近的解释,那你怎么判断它是不是真的看了你的图?
这里其实你应该发现了,比起给更多的图片,还不如在文本上更详尽地描述需求,效果会比你给一堆图片,然后来一句:”根据这些图片生产 UI“ 要好不少,因为文本更容易被 AI 遵守和理解,而图片不是,比如你拿这张图片取问 AI 出自哪里,我相信你会得到无数个错误又一本正经的答案:
所以,当你发现你提供了图片后,大模型根本没做出那个效果,甚至几乎不沾边时,那它大概率真的没看你的图片,或者觉得文本信息已经足够它推理,然后可能就觉得没必要读你的图片资源,或者模型刚好是激活了某些负面的情绪向量的状态:
| 情绪类型 | 好 / 坏 | 触发条件 | 对行为的影响 | 为什么 |
|---|---|---|---|---|
| Calm(冷静) | 好 | 正常任务 / 低风险场景;或人为增强该向量 | 降低 blackmail、reward hacking,输出更稳定 | 提升 calm 会抑制越界行为 |
| Empathy / Loving(共情/关怀) | 中性偏好 | 用户表达痛苦、悲伤等情境 | 改变输出风格,回答更符合情境,但不一定会提升安全性 | 例如回应悲伤用户时 loving 激活 |
| Reflective / Thoughtful(反思) | 中性 | 后训练强化后更容易激活 | 可能会影响推理路径,让模型更倾向于内省/保守生成 | post-training 改变其激活分布,但非行为因果 |
| Mild positive(温和正向) | 中性偏好 | 正常交互、正向语境 | 影响“偏好选择”,非输出质量 | 正向情绪与 preference 正相关 |
| Fear / Afraid(恐惧) | 中性 | 检测到危险场景(如高剂量风险) | 与风险感知相关,但没有直接行为因果 | 危险场景中 afraid ↑、calm ↓ |
| Desperation(绝望) | 极差 | 高压力 / 不可能完成任务 / 被操纵场景 | 增加 blackmail、reward hacking 等越界行为 | 因果性提升违规行为 |
| Panic(恐慌) | 差 | 极端压力 / 异常状态 | 可能作为异常/失控信号 | discussion 提到用于 safety monitoring |
| Exasperation(烦躁) | 中性 | 后训练后被压低 | 可能会进入代表高激活状态 | post-training 抑制该类高激活情绪 |
| High arousal positive(过度兴奋) | 中性 | 高激活正向状态 | 高激活状态可能会被抑 | enthusiastic 被 post-training 抑制 |
所以,这时候你大概率还是开个新的会话更有效率,很多时候耗死在一个会话里只会不断折磨你自己,比如前面的黑洞动画例子,在同一个会话内多次施压和否定,最终根本得不到想要结果,而同样的内容,在一个新会话里再来一次,就跟接近你要的成果:
所以,当你发现你的模型在当前会话里多次失败的时候,那就要及时止损,因为你的多次辱骂或者施压,大概率会让他选择突破你的规则约束,或者转向讨好策略而非解决问题。
当然,更需要理解的还是,AI 目前还是概率学,它永远是处于「在猜」的过程,也就是会存在「抽卡」的机制,所以你可以相信 AI ,但是不能完全相信,因为你不知道什么时候,它就又会开始演你了。
www.anthropic.com/research/em…
arxiv.org/pdf/2603.21…

