恋爱邦
107.39M · 2026-04-09

之前使用opencode调用远端模型一切都很顺利,最近想着自己还有个RTX 5060Ti 16G的GPU,想着在家里部署一个本地模型服务,这样能使用本地的模型。整体配置是 OpenCode + Ollama + 本地大模型。原本以为把模型接上就能像在线编程助手一样,直接读写文件、生成页面、修改代码,结果却很坑:同样的提示词,Kimi 能正常生成 HTML 文件,本地的 qwen / gemma 却总是只输出命令、甚至偶尔显示要调用工具,但就是不真正执行。排查一上午才发现真正的问题并不是权限、也不是模型完全不会工具调用,而是一个非常容易被忽略的点:Ollama 的上下文长度太小了。
我遇到的症状大概有这几种:
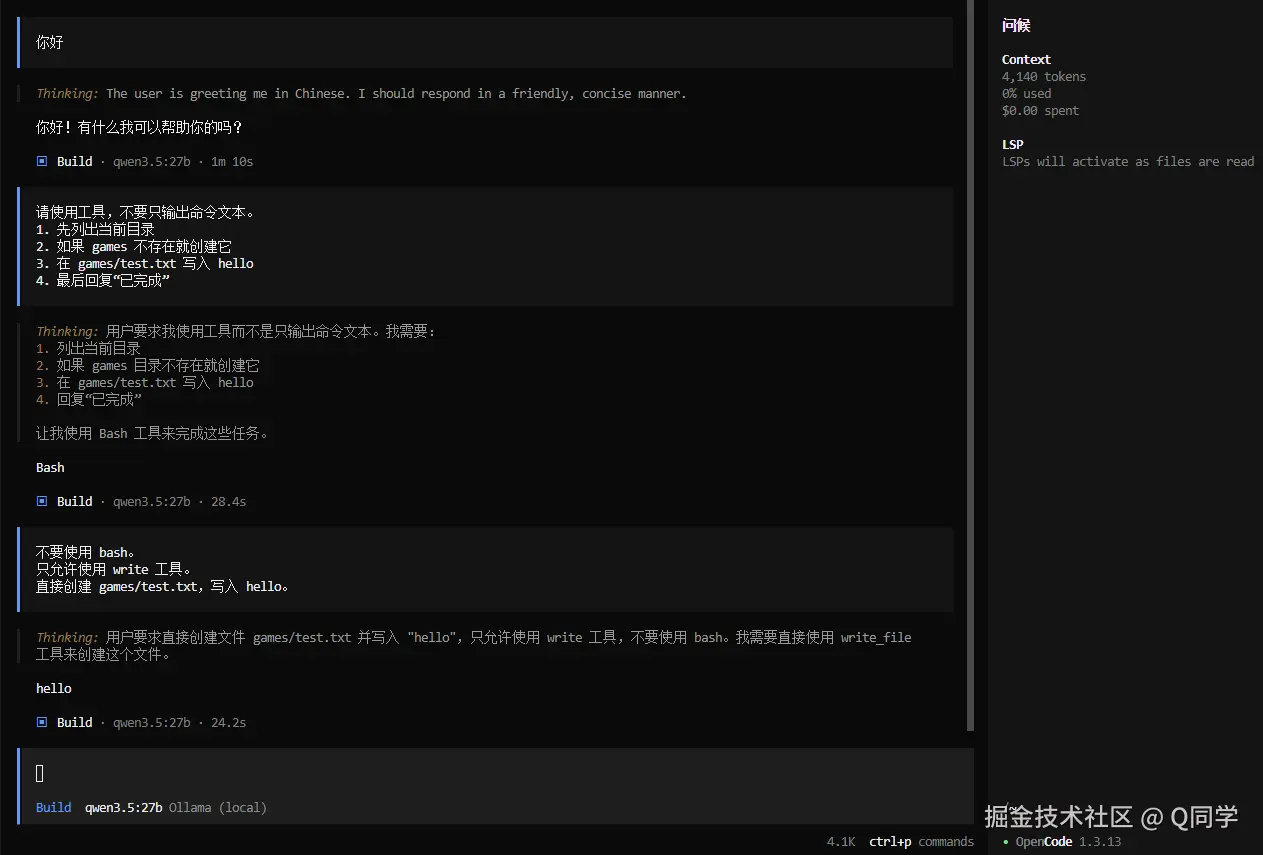
Thinkingls、echo ... > file 这种命令打印出来Bash最开始我怀疑的是下面这些方向:
这些怀疑都不是完全没道理,但它们都不是这次问题的真正根因。
在chatgpt建议下,我首先尝试绕过 OpenCode,直接用 curl 调 Ollama 的 /v1/chat/completions,强制要求模型调用工具。
结果非常明确:模型是能返回标准 tool_calls 的。
这说明两件事:
接着我又看了 OpenCode 的日志,发现:
bash / read / write / edit / glob / grep 这些工具都已经成功注册这时候问题范围已经被大幅缩小了:
不是工具没注册,也不是权限挡住了,而是模型在 OpenCode 这类多轮 agent 流程里没有稳定地完成工具调用。
最后我去翻官方文档,才确认了真正的问题。
Ollama 官方写得很直接:默认上下文长度会根据显存大小决定。如果显存小于 24 GiB,默认上下文就是 4k;而像 agents、coding tools、web search 这种任务,建议至少设置到 64k tokens。(Ollama 文档)
更关键的是,Ollama 官方在 OpenCode 集成文档里也明确写了:OpenCode 需要更大的上下文窗口,推荐至少 64k tokens。 (Ollama 文档)
这就完全解释了我遇到的现象:
说白了,不是模型完全不会,而是上下文太小,Agent 框架需要的信息塞不下。
我的解决办法很简单:把 Ollama 的上下文长度调大到 64k。
这也是很多人最常见的情况:
Ollama 在 Windows 上运行,OpenCode 在 WSL 里连接它。
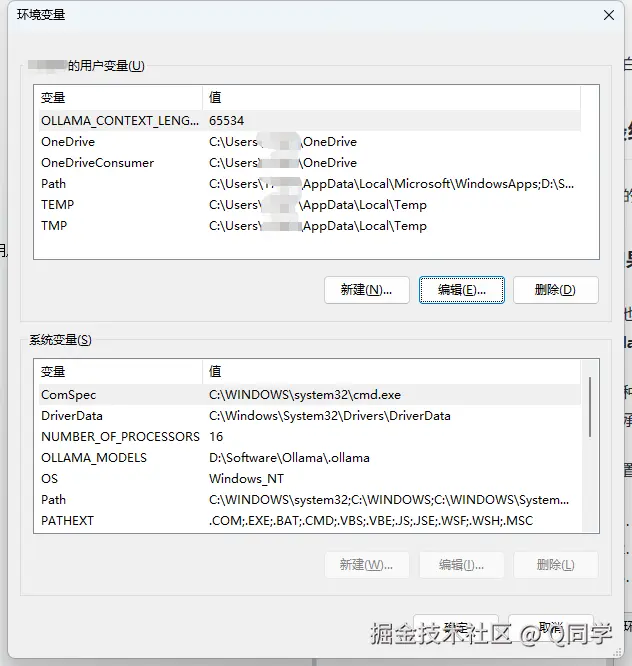
这种情况下,要改的是 Windows 侧的 Ollama 环境变量。Ollama 官方 FAQ 说明,Windows 版会继承用户和系统环境变量。(Ollama 文档)
设置方式:
OLLAMA_CONTEXT_LENGTH=65534
4. 保存 5. 重新启动 Ollama,这时就正常了。
这次踩坑最核心的一句话就是:
最终把上下文提到 64k 之后,问题才终于恢复正常。 回头看,这个坑真的很浪费时间,但也确实值得记下来——因为它太像“模型能力问题”了,实际上却是“运行参数问题”。

