
老爹疯狂厨房
125.32M · 2026-03-31

把 MySQL 业务数据实时同步到 StarRocks,看上去只是“做一条同步链路”,实际落地后,难点通常不在传输本身,而在这几个环节:目标端建表是否省力、源表结构变化能否跟上、同步结果怎么验证、链路出现问题后是否便于排查。
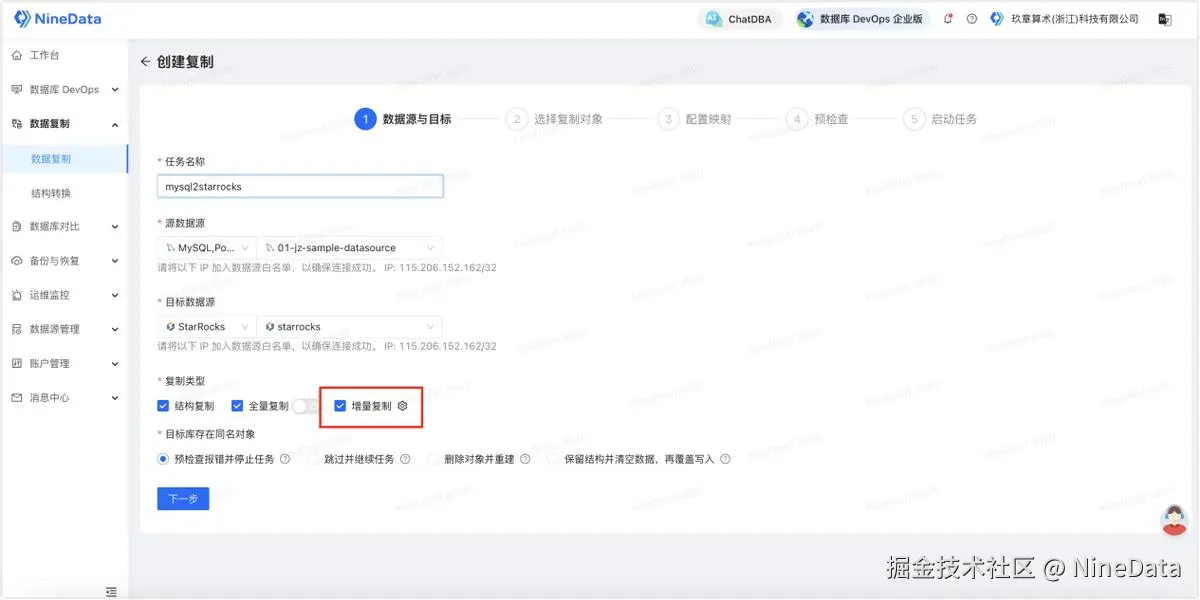
如果从这个角度看,NineData 的价值不只是把 MySQL 数据写进 StarRocks,而是把结构复制、全量初始化、增量同步、DDL 跟随、数据对比和运行治理放进了一条全流程链路里。
这类方案里,常见选择大致有三类:
换句话说,如果团队已经有成熟的 Flink 平台,且需要做复杂 Join、路由、窗口计算,Flink CDC 依然更灵活;但如果目标更明确,就是把业务数据稳定送到 StarRocks 做实时分析,NineData 的优势在于少搭组件、少补监控、少做人工校验。
MySQL→StarRocks 的常见门槛,往往不是增量同步,而是目标端初始化。
NineData 的结构复制能自动完成目标端建表和字段映射,这对 PoC、ODS 承接、批量接入小表比较省力。再配合同名对象处理策略,初始化成本会低不少。
但这件事也要看边界。
自动建表解决的是“把表先建出来”,并不等于“目标端模型已经设计合理”。
对 StarRocks 来说,表模型选型会影响后续写入语义和查询结果:
如果上游 MySQL 表存在频繁 UPDATE/DELETE,目标端却按追加型明细表去建,链路虽然能跑,结果却未必符合预期。
因此较稳妥的做法通常是:
这也是 MySQL→StarRocks 项目里较易被忽视的一步。
很多自建 CDC 链路,前期容易忽略的是 DDL。
数据同步本身不难,更需要关注的是:源端一旦新增列、改字段、改表结构,目标端怎么跟上。如果没有 DDL 跟随能力,链路通常很快就会进入“人工补结构”的状态。
NineData 在这条链路里支持 DDL 捕获与执行,任务侧还能查看结构复制日志和 DDL 记录。它解决的不是“初次接入”,而是“业务表结构持续演进时,这条链路还能不能继续跑”。
当然,DDL 跟随也不意味着所有变更都适合默认自动跟随。
对核心分析表来说,涉及表模型、分区键、分桶设计的变更,仍然更适合人工确认后处理。尤其是 StarRocks 这类分析库,目标端设计本身就是链路的一部分。
如果要把 NineData 这条链路的价值更好发挥出来,目标端不能只停留在“能接收数据”。
一个比较典型的场景是 UPSERT。
如果 MySQL 里的订单、用户、商品快照会持续更新,那么 StarRocks 侧更适合用 Primary Key 或 Unique Key 这类更新模型来承接,而不是简单落成 Duplicate Key。这样做的意义在于,MySQL 的增删改能更自然地映射到目标端“当前状态”语义上,删除操作也更容易按主键语义处理。
另一个容易被忽略的是分区。
如果上游 MySQL 已经按月分表、按租户分库,目标端不必机械照搬。StarRocks 更适合按查询和生命周期来设计分区,比如按时间做分区裁剪,再结合业务键做分桶。否则,上游的分表逻辑很可能被原样复制到下游,最后变成分析查询的负担。
所以,NineData 负责把数据稳定送达,StarRocks 侧负责把数据组织成适合查询的形态。两者配合好了,这条链路才能更好发挥价值。
很多团队发布实时同步后,较需关注的不是任务失败,而是任务没报错、数据却出现偏差。
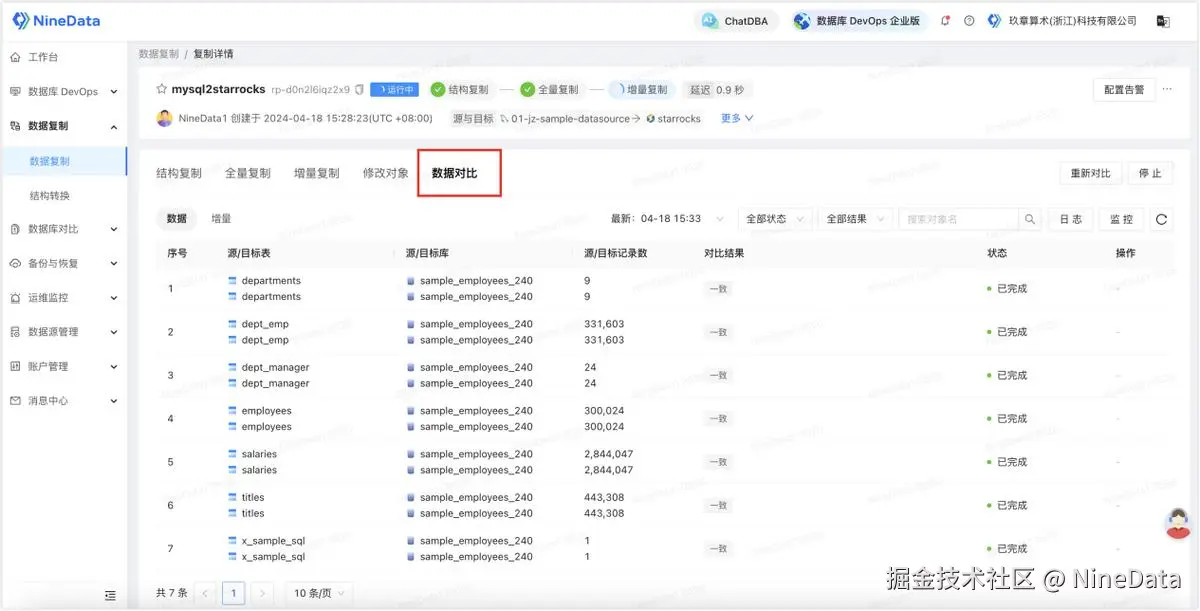
NineData 在这条链路里把数据对比做成了内建能力,这一点比较实用。它支持全量对比、快速对比、不一致复检,还能查看差异详情、生成变更 SQL 或导出结果做修正。
这类能力的意义在于,它把“同步完怎么证明结果可信”这件事,变成了有工具支撑的动作,而不是靠人人工抽查。
对于 MySQL→StarRocks 这种一边承接增量、一边服务查询的链路来说,能比较快发现偏差、定位差异,也很关键。
实际选型时,不能只看功能,还要看链路对源端和目标端的资源影响。
源端 MySQL 这边,全量初始化会带来读压力,增量阶段则依赖 Binlog 持续读取。
目标端 StarRocks 这边,Stream Load 写入、Compaction、BE 节点资源都会影响吞吐和延迟。
NineData 在这部分给了几个比较实用的治理能力:
这意味着它不是只解决“怎么同步”,而是把“怎么运维这条同步链路”也一起考虑进去了。
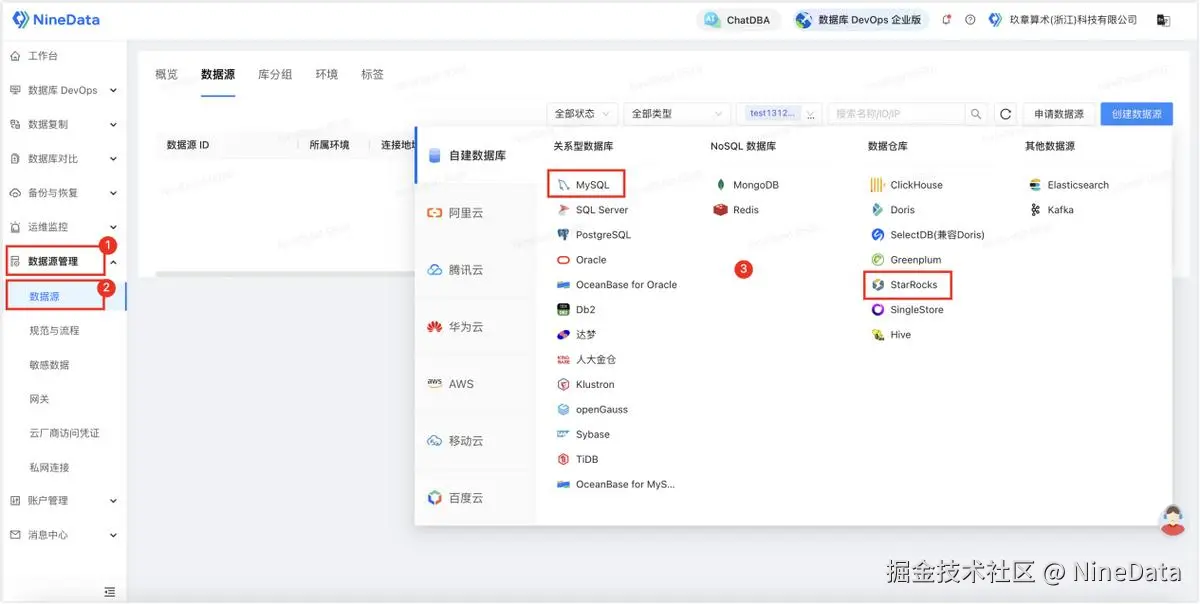
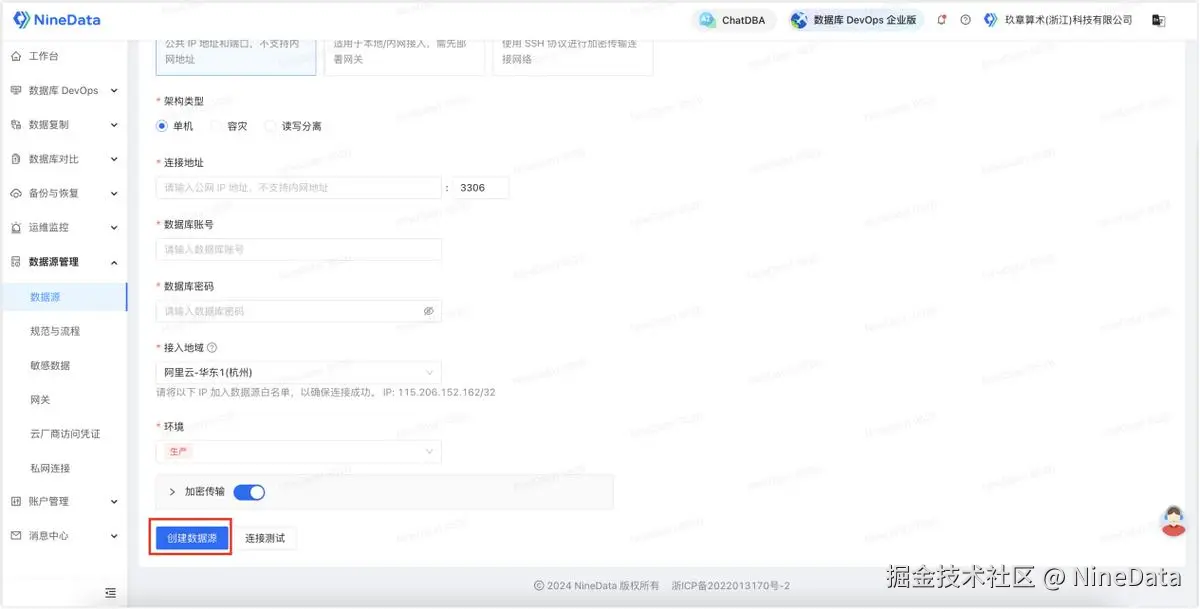
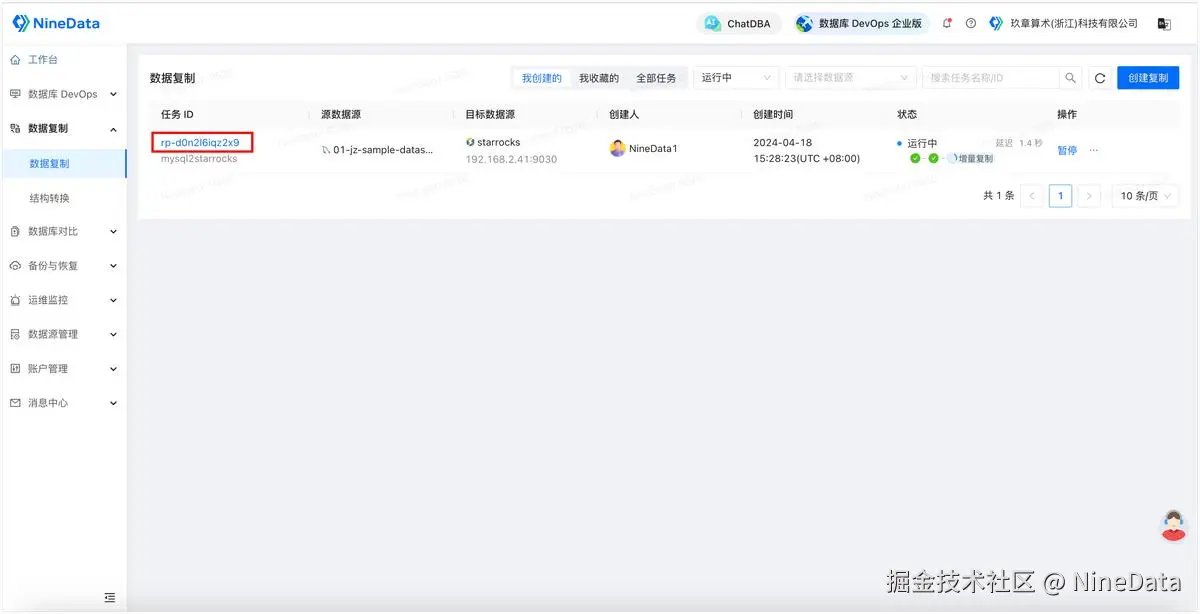
步骤一:录入数据源
步骤二:配置任务
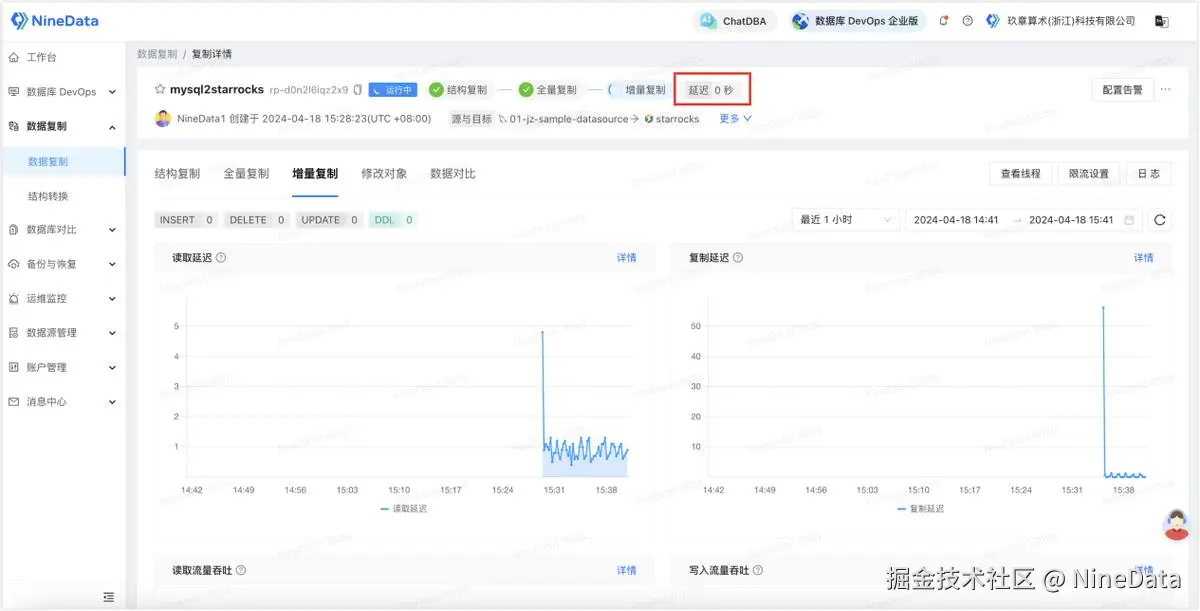
步骤三:数据校验
除了同步功能以外,NineData 还提供了同步后源端和目标端同步数据的对比功能,以确保目标端数据的一致性。
您可以在一段时间后,单击页面中的重新对比,校验后续增量数据的同步结果。
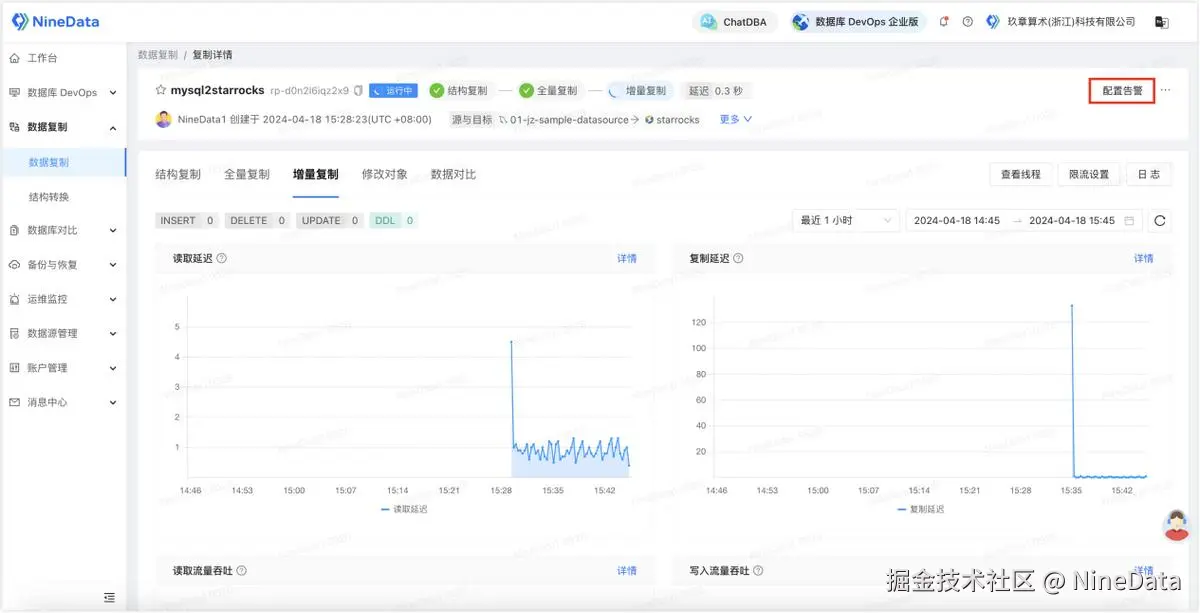
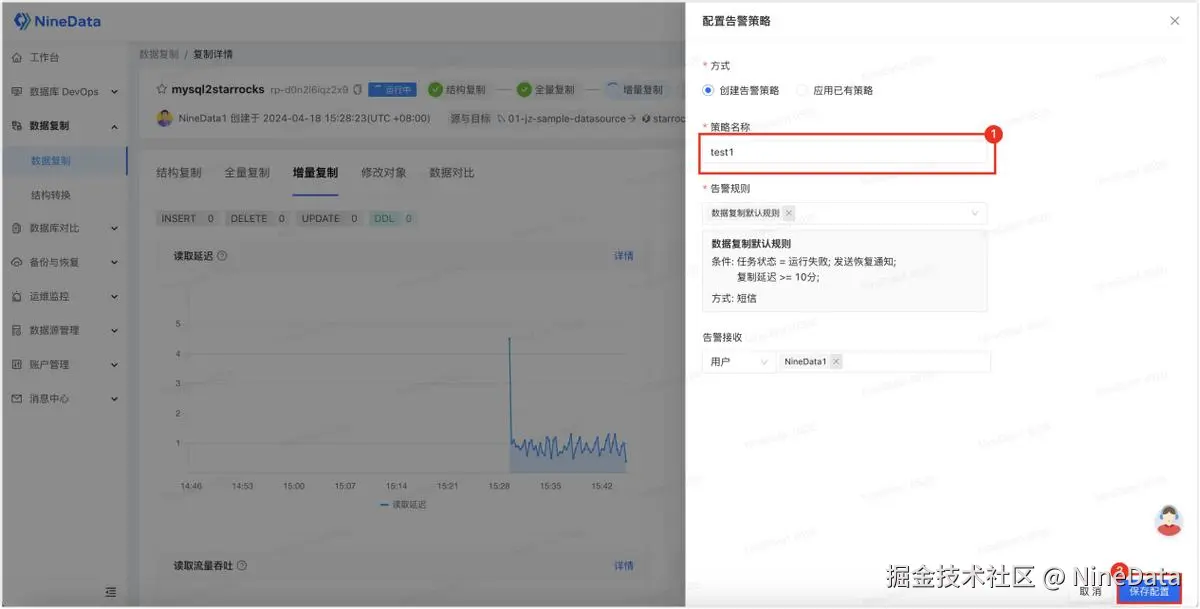
步骤四:告警设置
由于是长期任务,您可能需要系统实时监控任务状态,在任务有异常时即刻通知您。
如果只看“把数据从 MySQL 搬到 StarRocks”,市场上并不缺方案。
NineData 在这个场景里的差异,更接近于把很多团队原本要自己拼装的环节,前置成一条产品化链路:建表初始化、DDL 跟随、全量与增量协同、数据对比、限流、告警、线程视图。
但这条链路要稳定运行,还有一个前提不能省:
核心表的 StarRocks 模型、分区和更新语义,建议先设计清楚,再让同步任务去承接。
对企业和 DBA 来说,这类方案更值得关注的,往往不是初次接入的几小时,而是后续运维和排障的成本。

