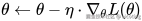
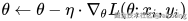
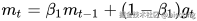
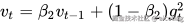


纳铁福
5.78M · 2026-03-26

在神经网络的训练过程中,优化算法(Optimizer) 是决定参数如何更新的关键工具。
它就像是模型学习过程中的导航仪,告诉我们在损失函数的山谷里该往哪个方向走、走多远。
不同的优化算法对应着不同的更新策略,直接影响模型的收敛速度和最终效果。
所有相关文档、源码示例、流程图与面试八股,我也将持续更新在AIHub,欢迎关注收藏!
训练神经网络的核心目标是最小化损失函数 
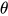
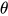

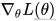
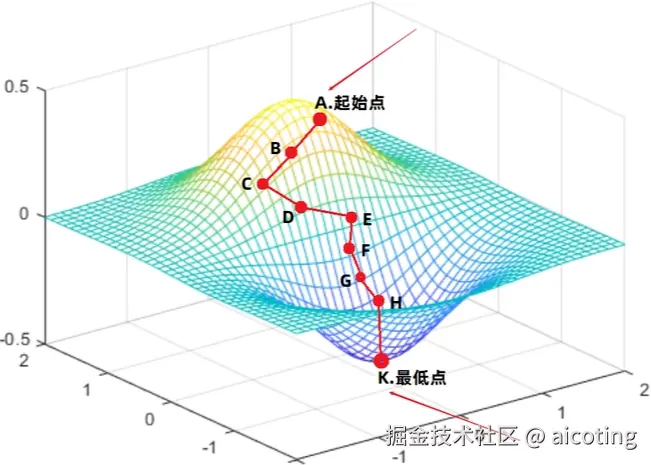
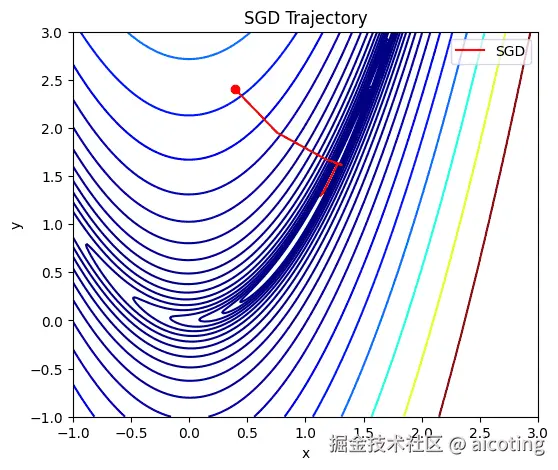
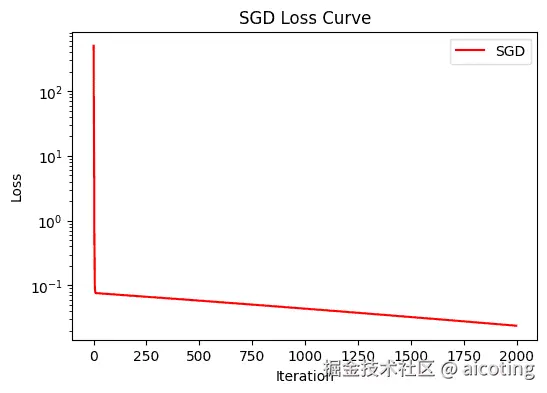
SGD 是所有优化算法的鼻祖,至今依然被广泛应用,尤其在大规模训练里常搭配 动量(Momentum) 使用,加速收敛并减少震荡。
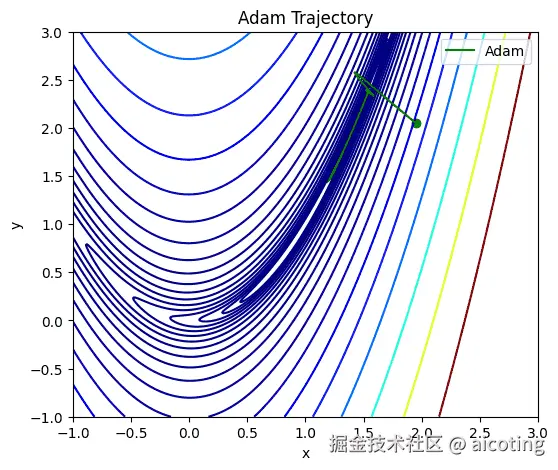
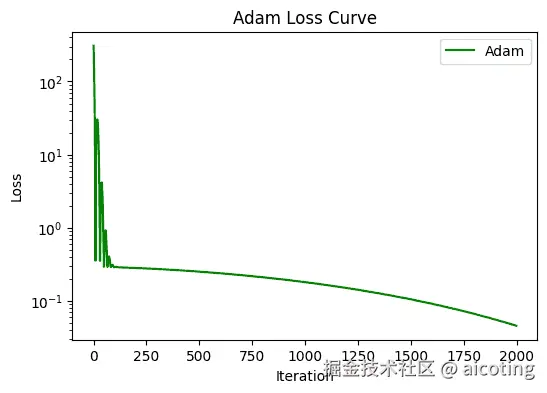
Adam(Adaptive Moment Estimation)可以看作是 Momentum + RMSProp 的结合体,它同时考虑了梯度的一阶动量(均值)和二阶动量(方差),实现了对学习率的自适应调整。
更新公式核心如下:
其中:
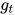 :当前梯度
:当前梯度 :梯度一阶动量,类似“滑动平均”
:梯度一阶动量,类似“滑动平均”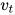 :梯度二阶动量,反映梯度波动大小
:梯度二阶动量,反映梯度波动大小 :经过偏差校正后的估计值
:经过偏差校正后的估计值 :衰减系数,常用值分别是 0.9 和 0.999
:衰减系数,常用值分别是 0.9 和 0.999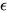 :防止除零的小常数
:防止除零的小常数 :学习率
:学习率Adam 会让每个参数都拥有一个自适应的学习率,通常比纯 SGD 收敛更快、更稳。缺点是有时会导致泛化性能不如 SGD,容易学得太快,最后停在次优解。
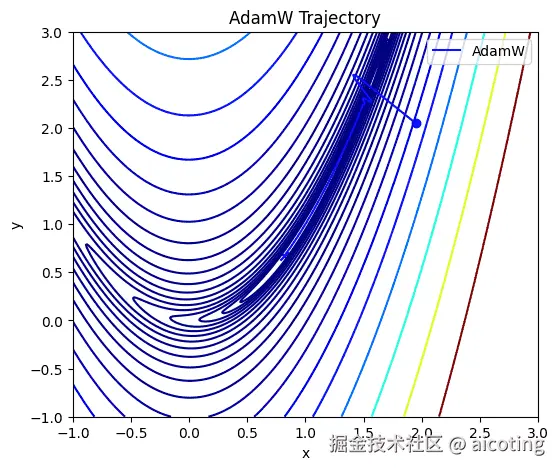
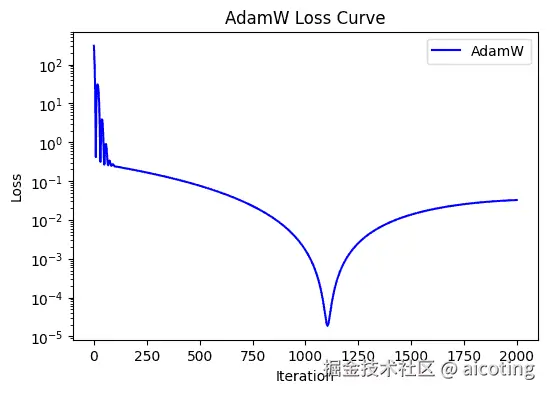
AdamW(Adam with Weight Decay) 是对 Adam 的重要改进,区别主要体现在 正则化方式。
在 Adam 里,如果你加 L2 正则化,它并不是严格意义上的“权重衰减”,而是把正则项混进了梯度更新里,导致效果不稳定。
在 AdamW 里,权重衰减(Weight Decay)被独立出来,更新方式如下:
其中:
:权重衰减系数
其他符号与 Adam 相同
AdamW 保证了真正意义上的权重衰减,从而显著提升泛化性能。特别是在 Transformer、大模型训练中,AdamW 已经成为标配。
可以说,现在只要是用 Adam,大部分场景下都会直接用 AdamW 替代。
LAMB (Layer-wise Adaptive Moments for Batch training)是在 Adam 基础上的进一步升级,专门为 超大规模 batch 训练 设计。它的关键创新点是 Layer-wise 自适应学习率缩放。 在 Adam 中,不同参数的更新幅度可能差异很大,这在大 batch 下会导致训练不稳定。而 LAMB 会对每一层参数的更新做归一化:
其中:
 :当前层的参数向量
:当前层的参数向量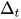 :Adam 更新得到的梯度方向
:Adam 更新得到的梯度方向 :向量范数
:向量范数 :缩放后的更新量
:缩放后的更新量这样,每一层的参数更新大小会和该层参数的规模匹配,避免了大参数小更新,小参数大更新的问题。
LAMB 能让 batch size 成千上万依然稳定训练,非常适合 BERT、GPT 等大规模预训练场景。比如 Google 在训练 BERT-Large 时,用 LAMB 把 batch size 提升到 32K,训练只需 76 分钟就能收敛,而原本用 Adam 要花好几天。
优化算法可以说是深度学习训练中的发动机。从最基础的 SGD,到改进的 Adam、AdamW,再到为大模型量身定制的 LAMB,每一次演进都在解决如何更快更稳地到达最优解这个核心问题。可以说,损失函数决定了目标,而优化算法决定了到达目标的路径。
推荐阅读
一文搞懂深度学习中的通用逼近定理!
一文搞懂深度学习中的表征学习理论!
一文搞懂深度学习中的信息论!
一文搞懂深度学习的反向传播与优化理论!
一文搞懂深度学习中的张量与自动微分!
一文彻底搞懂深度学习和机器学习的区别!
最新的文章都在公众号aicoting更新,别忘记关注哦!!!
作者:aicoting
分享是一种信仰,连接让成长更有温度。
我们下次不见不散!

