

泡沫机械
96.43M · 2026-03-24

想象一下,你有一本很厚的书,Python提供了三种不同的阅读方式:
下面咱们一个个详细讲解,配上代码例子,逐一给它击破。
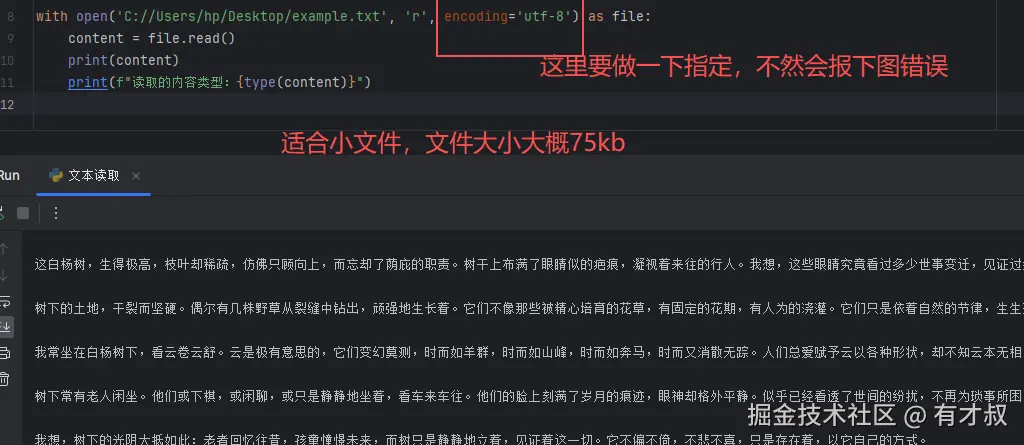
read()方法是最直接的文件读取方式,它会一次性把整个文件内容读取到一个字符串中。
# 示例代码
with open('C://Users/hp/Desktop/example.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
print(f"读取的内容类型:{type(content)}")
特点:
read(100)表示只读取前100个字符注意事项:
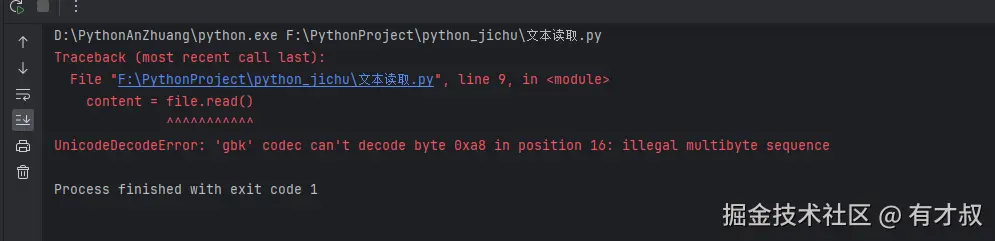
千万别用read()读取大文件!比如几个GB的文件,这样会一下子吃掉你大量内存,可能导致程序崩溃。
readline()方法每次只读取文件的一行内容,非常适合处理大文件。
# 示例代码
with open('C://Users/hp/Desktop/example.txt', 'r', encoding='utf-8') as file:
line = file.readline()
while line:
print(line.strip()) # strip()去除行尾换行符
line = file.readline()
同样也是能够实现读取的。
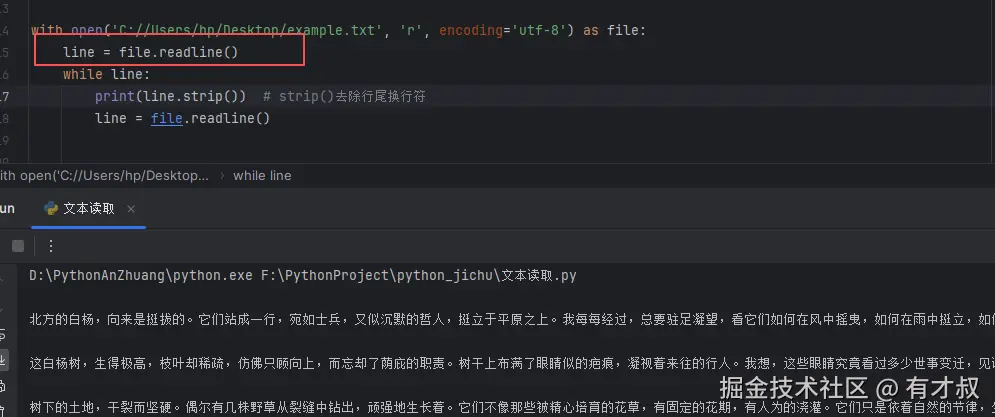
特点:
实用技巧: 你可以结合while循环,逐行处理直到文件结束。
readlines()方法读取整个文件,但返回的是一个列表,其中每个元素都是文件的一行内容。 我们先看看它的这个函数:
# 示例代码
with open('C://Users/hp/Desktop/example.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()
print(f"总行数:{len(lines)}")
for i, line in enumerate(lines, 1):
print(f"第{i}行:{line.strip()}")
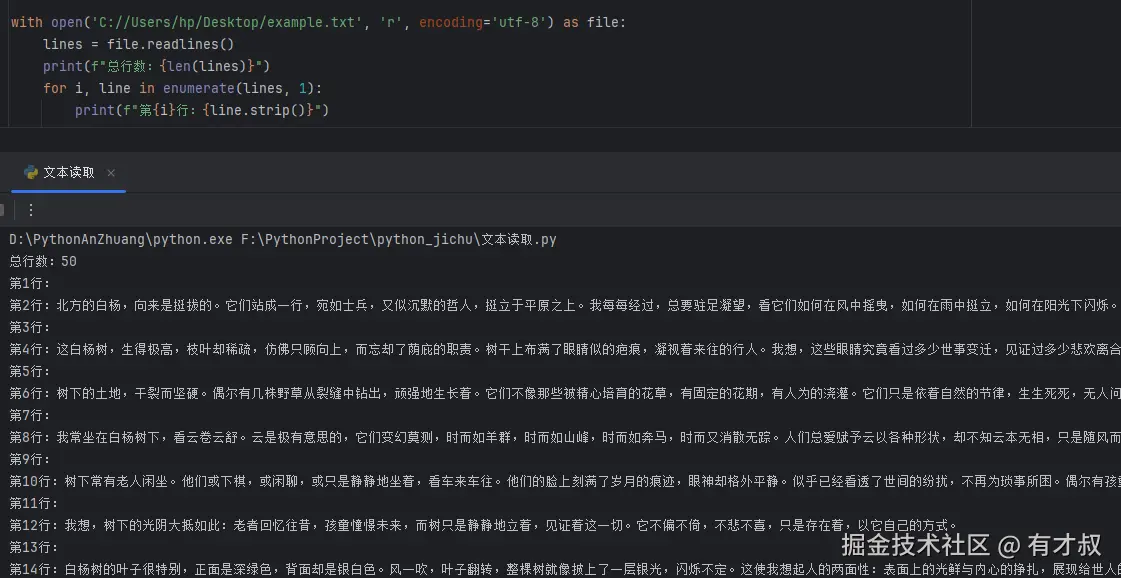
注意事项:
和read()一样,readlines()也会一次性加载整个文件到内存,所以不适合处理非常大的文件。
为了更直观,我整理了一个对比表格:
| 方法 | 返回类型 | 内存占用 | 适用场景 | 特点 |
|---|---|---|---|---|
| read() | 字符串 | 高 | 小文件 | 一次性读取全部内容 |
| readline() | 字符串 | 低 | 大文件 | 逐行读取,内存效率高 |
| readlines() | 列表 | 高 | 中小文件,需要行级操作 | 返回行列表,方便按行访问 |
知道了区别,怎么在实际中选择呢?我给你几个实用建议:
处理大文件(如日志文件):用readline()或者直接遍历文件对象,这样不会撑爆内存
处理小文件:三种都可以,根据需求选择。如果需要整个内容就用read(),如果需要按行处理就用readlines()
需要特定行:用readlines()获取列表后,可以直接通过索引访问特定行
逐行处理同时需要行号:可以用enumerate()函数:
with open('file.txt', 'r') as file:
for line_num, line in enumerate(file, 1):
print(f"第{line_num}行:{line.strip()}")
with语句打开文件,这样可以自动处理文件关闭,避免资源泄露好了这就是ython中这三个文件读取方法的区别和用法。其实只要记住:小文件随便选,大文件用readline(),需要行列表用readlines(),就不会出错啦!

