fnf内鬼
48.17M · 2026-03-22

线上业务系统的性能瓶颈,90%以上都集中在数据库层,而慢SQL是引发数据库雪崩的头号元凶。很多开发者优化SQL时,只会盲目加索引,却不懂执行计划的底层逻辑,最终导致索引滥用、性能越优化越差,甚至引发线上故障。
要读懂执行计划,首先要明确SQL从输入到返回结果的完整执行流程,这是理解执行计划来源的基础: 客户端请求 → 连接器(身份认证、权限校验)→ 解析器(词法解析、语法解析,生成语法树)→ 预处理器(校验表、字段是否存在,权限二次校验)→ 优化器(生成最优执行计划)→ 执行器(调用存储引擎接口执行)→ 存储引擎(InnoDB,返回数据) 注:MySQL 8.0已彻底移除查询缓存模块,生产环境无需关注相关配置。
执行计划是MySQL优化器生成的SQL执行步骤明细,通过EXPLAIN关键字获取,核心用法有3种:
EXPLAIN SELECT * FROM user_info WHERE id = 1;EXPLAIN FORMAT=JSON SELECT * FROM user_info WHERE id = 1; 可查看优化器的成本计算、执行细节EXPLAIN ANALYZE SELECT * FROM user_info WHERE id = 1; 实际执行SQL,返回执行计划+真实执行耗时、扫描行数、循环次数等,是优化的终极利器执行计划的输出有12个核心字段,每个字段都对应SQL执行的关键信息,必须逐个吃透。以下所有实例均基于统一的测试表,MySQL 8.0可直接执行:
CREATE TABLE `user_info` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_no` varchar(32) NOT NULL COMMENT '用户编号',
`user_name` varchar(64) NOT NULL COMMENT '用户姓名',
`age` int NOT NULL DEFAULT '0' COMMENT '年龄',
`gender` tinyint NOT NULL DEFAULT '0' COMMENT '性别 0-未知 1-男 2-女',
`phone` varchar(11) NOT NULL COMMENT '手机号',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_no` (`user_no`),
KEY `idx_age_create_time` (`age`,`create_time`),
KEY `idx_name_phone` (`user_name`,`phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户信息表';
CREATE TABLE `order_info` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`order_no` varchar(32) NOT NULL COMMENT '订单编号',
`user_id` bigint unsigned NOT NULL COMMENT '用户ID',
`order_amount` decimal(10,2) NOT NULL COMMENT '订单金额',
`order_status` tinyint NOT NULL DEFAULT '0' COMMENT '订单状态',
`create_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表';
id值相同,执行顺序从上到下;id值不同,id越大越先执行;id为NULL的行最后执行。用于区分复杂查询(子查询、联表查询)的执行顺序,示例:
EXPLAIN SELECT * FROM user_info WHERE id = (SELECT id FROM user_info WHERE user_no = 'U001');
子查询的id为2,优先执行;外层查询id为1,后执行。
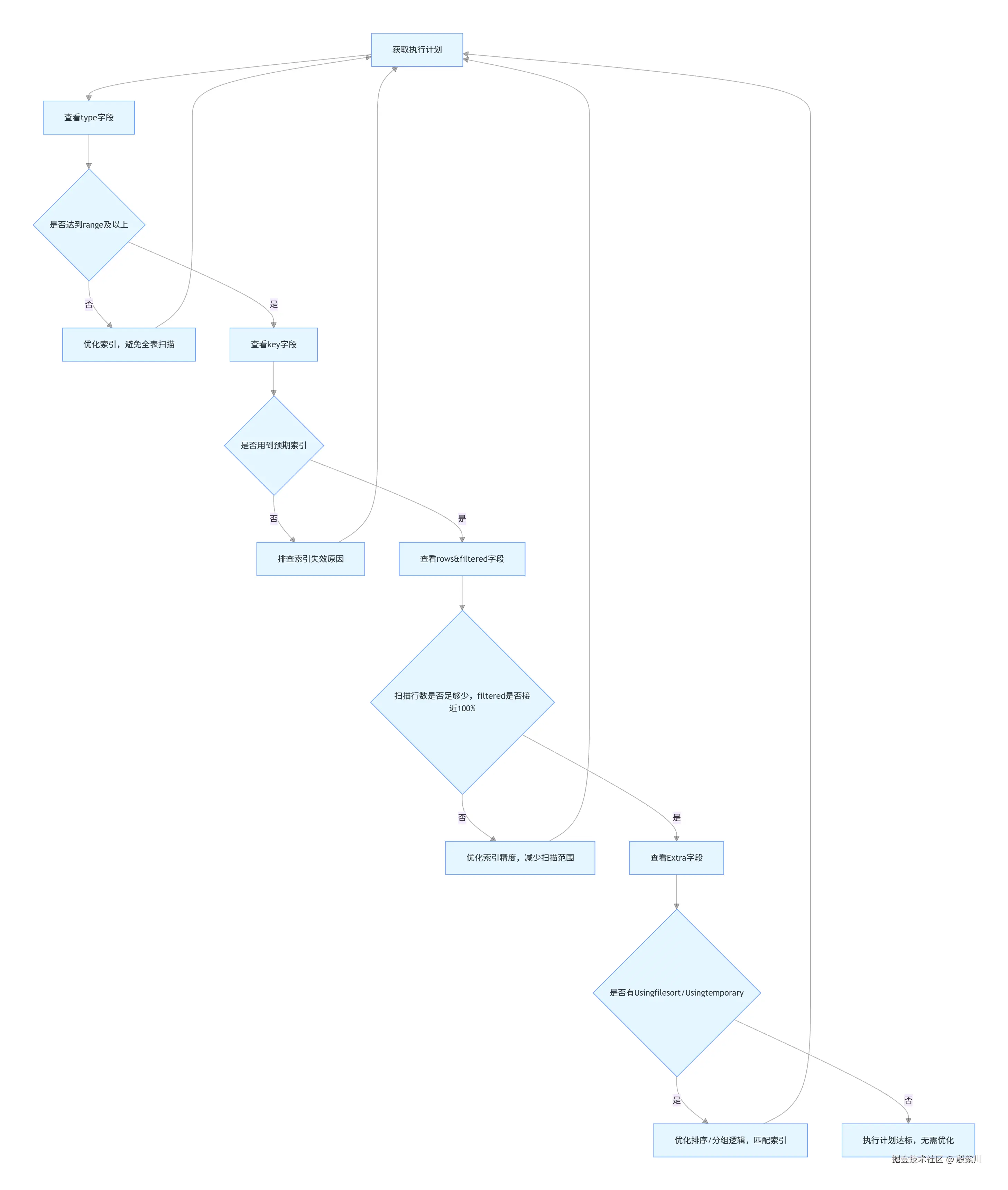
标识当前查询的类型,核心类型及含义:
SIMPLE:简单查询,不包含子查询、UNIONPRIMARY:复杂查询的最外层查询SUBQUERY:SELECT/WHERE中的子查询DERIVED:FROM中的子查询(派生表)UNION:UNION中的第二个及以后的查询UNION RESULT:UNION的结果集标识MySQL找到目标行的方式,是性能最核心的指标,性能从优到劣的顺序为: system > const > eq_ref > ref > range > index > ALL 生产环境核心要求:所有SQL的type必须至少达到range级别,核心查询必须达到ref级别。 逐个拆解核心级别:
system:系统表,只有一行数据,极少出现const:常量查询,通过主键/唯一索引等值查询,最多匹配一行数据,性能最优EXPLAIN SELECT * FROM user_info WHERE id = 1;
EXPLAIN SELECT * FROM user_info WHERE user_no = 'U001';
3. eq_ref:联表查询时,被驱动表通过主键/唯一索引等值关联,每行匹配最多一行数据,是联表查询的最优级别
EXPLAIN SELECT o.* FROM order_info o LEFT JOIN user_info u ON o.user_id = u.id WHERE o.order_no = 'O001';
4. ref:非唯一索引等值查询,匹配多行数据,是普通查询的最优级别
EXPLAIN SELECT * FROM user_info WHERE age = 18;
5. range:范围查询,使用索引进行范围匹配,比如>、<、>=、<=、IN、BETWEEN
EXPLAIN SELECT * FROM user_info WHERE age BETWEEN 18 AND 30;
EXPLAIN SELECT * FROM user_info WHERE id IN (1,2,3);
6. index:遍历整个索引树,比全表扫描略快,因为索引文件比数据文件小
7. ALL:全表扫描,性能最差,必须优化
possible_keys:可能用到的索引,优化器评估的候选索引key:实际用到的索引,为NULL表示没有用到索引 核心注意点:possible_keys有值但key为NULL,说明索引失效,必须优化。标识MySQL使用的索引字节数,可用于判断联合索引的哪些字段被用到。 MySQL 8.0 utf8mb4字符集下的计算规则:
idx_age_create_time(age, create_time),age是INT NOT NULL(4字节),create_time是DATETIME(3) NOT NULL(8字节)。若key_len=4,说明只用到了age字段;若key_len=12,说明两个字段都用到了。标识与索引列进行等值匹配的字段或常量,比如const、u.id等,可判断索引的匹配精度。
rows:MySQL预估的需要扫描的行数,数值越小越好filtered:符合查询条件的行数占扫描行数的比例,数值越接近100%越好,低于10%说明索引选择不合理 示例:rows=10000,filtered=10.00,说明扫描了10000行,只有1000行符合条件,索引效率极低,必须优化。Extra字段包含SQL执行的关键细节,是优化的重中之重,核心项及优化方案如下:
Using index:覆盖索引,查询的所有字段都在索引中,无需回表查询,性能最优,是优化的核心目标EXPLAIN SELECT user_name, phone FROM user_info WHERE user_name = '张三';
2. Using where:通过索引扫描后,再用WHERE条件过滤,通常说明索引覆盖不全
3. Using filesort:无法利用索引完成排序,MySQL对结果集进行额外的排序操作,是核心优化点
-- 反例:无法用到索引排序
EXPLAIN SELECT * FROM user_info WHERE age > 18 ORDER BY create_time;
-- 优化:联合索引匹配查询+排序字段
EXPLAIN SELECT * FROM user_info WHERE age > 18 ORDER BY age, create_time;
核心纠正:Using filesort不是磁盘排序,只要无法用索引排序,无论内存还是磁盘排序,都会显示该标识。只有当排序结果超过sort_buffer_size时,才会触发磁盘临时文件排序。 4. Using temporary:MySQL需要创建临时表存储中间结果,常见于GROUP BY、UNION、DISTINCT,性能极差,必须优化 5. Impossible WHERE:WHERE条件永远为false,比如WHERE 1=2,无数据返回 6. Using join buffer:联表查询时,被驱动表无法用到索引,需要用连接缓存,说明联表关联字段没有加索引,必须优化
很多人拿到执行计划不知道从哪看,正确的解读顺序如下:
MySQL 8.0.18+提供的EXPLAIN ANALYZE,会实际执行SQL,返回执行计划+真实执行数据,包括实际执行时间、实际扫描行数、实际匹配行数、循环执行次数、排序/分组的耗时与内存使用情况,是排查优化效果、定位复杂慢SQL的终极工具,示例:
EXPLAIN ANALYZE SELECT * FROM user_info WHERE age BETWEEN 18 AND 30 ORDER BY create_time;
InnoDB采用B+树索引结构,所有数据都存储在主键索引的叶子节点(聚簇索引),普通索引的叶子节点存储主键值(二级索引),通过二级索引查询需要先查二级索引得到主键,再查主键索引得到数据(回表操作)。
联合索引的匹配必须从左到右依次匹配,遇到范围查询时,右侧的字段会失效,是联合索引设计的核心原则。 示例:联合索引idx_a_b_c(a,b,c)
a=1、a=1 AND b=2、a=1 AND b=2 AND c=3、a=1 AND b BETWEEN 2 AND 3b=2、a=1 AND c=3(跳过b字段)、a=1 AND b>2 AND c=3(c字段失效)以下场景是生产中90%的索引失效原因,每个场景都有明确的原理和优化方案:
-- 反例:索引列使用函数,失效
EXPLAIN SELECT * FROM user_info WHERE YEAR(create_time) = 2024;
-- 正例:范围查询,保留索引列原始值,用到索引
EXPLAIN SELECT * FROM user_info WHERE create_time BETWEEN '2024-01-01 00:00:00' AND '2024-12-31 23:59:59';
2. 隐式类型转换 原理:当查询条件的类型与索引列的类型不一致时,MySQL会对索引列做隐式类型转换,相当于对索引列执行函数,导致索引失效。 核心规则:字符串列与数字常量比较,索引失效;数字列与字符串常量比较,索引有效。
-- 反例:user_no是varchar类型,与数字常量比较,隐式转换,索引失效
EXPLAIN SELECT * FROM user_info WHERE user_no = 123;
-- 正例:类型匹配,用到索引
EXPLAIN SELECT * FROM user_info WHERE user_no = '123';
3. 模糊查询以%开头 原理:B+树的索引排序是按前缀匹配的,以%开头的模糊查询,无法利用索引的前缀排序,导致索引失效。
-- 反例:%开头,索引失效
EXPLAIN SELECT * FROM user_info WHERE user_name LIKE '%张三';
-- 优化方案1:覆盖索引,仅查询索引内的字段,可触发索引扫描
EXPLAIN SELECT user_name, phone FROM user_info WHERE user_name LIKE '%张三';
-- 优化方案2:全文索引,MySQL 8.0支持中文全文索引
ALTER TABLE user_info ADD FULLTEXT INDEX `ft_user_name` (`user_name`);
EXPLAIN SELECT * FROM user_info WHERE MATCH(user_name) AGAINST('张三' IN NATURAL LANGUAGE MODE);
4. OR条件两侧未全部建立索引 原理:OR条件只要有一侧没有索引,MySQL就会放弃索引,执行全表扫描。
-- 反例:gender无索引,全表扫描
EXPLAIN SELECT * FROM user_info WHERE id = 1 OR gender = 1;
-- 正例:UNION ALL拆分,两个查询都用到索引
EXPLAIN SELECT * FROM user_info WHERE id = 1 UNION ALL SELECT * FROM user_info WHERE gender = 1;
5. NOT IN、!=、<> 负向查询 原理:负向查询无法利用B+树的有序性,大部分场景会触发全表扫描,仅当主键/唯一索引的负向查询,可触发range级别扫描。
-- 反例:普通索引负向查询,全表扫描
EXPLAIN SELECT * FROM user_info WHERE age != 18;
-- 优化方案:业务上用正向范围查询替代,或限制主键范围
EXPLAIN SELECT * FROM user_info WHERE age < 18 OR age > 18;
EXPLAIN SELECT * FROM user_info WHERE id NOT IN (1,2,3);
6. JOIN关联字段类型、字符集不一致 原理:联表查询时,关联字段的类型、字符集不一致,会触发隐式类型转换,导致被驱动表的索引失效。
-- 反例:user_info.id是bigint,order_info.user_id是varchar,关联时隐式转换,索引失效
ALTER TABLE order_info MODIFY COLUMN `user_id` varchar(32) NOT NULL COMMENT '用户ID';
EXPLAIN SELECT o.* FROM order_info o LEFT JOIN user_info u ON o.user_id = u.id;
-- 正例:关联字段类型、字符集完全一致,用到索引
ALTER TABLE order_info MODIFY COLUMN `user_id` bigint unsigned NOT NULL COMMENT '用户ID';
EXPLAIN SELECT o.* FROM order_info o LEFT JOIN user_info u ON o.user_id = u.id;
MySQL联表查询的核心算法是Nested-Loop Join(NLJ),驱动表的每一行数据,到被驱动表中匹配符合条件的行,循环次数=驱动表行数×被驱动表单次查询成本。 核心优化原则:小表驱动大表,被驱动表的关联字段必须建立索引
深分页查询是生产中最常见的慢SQL场景,比如LIMIT 100000, 20,MySQL会先扫描100020行数据,然后丢弃前100000行,仅返回后20行,扫描行数随分页深度线性增长,性能急剧下降。
核心优化方案:
-- 反例:深分页全表扫描
EXPLAIN SELECT * FROM user_info ORDER BY id LIMIT 100000, 20;
-- 正例:主键覆盖优化,仅扫描20行
EXPLAIN SELECT * FROM user_info WHERE id >= (SELECT id FROM user_info ORDER BY id LIMIT 100000, 1) LIMIT 20;
2. 延迟关联优化:先通过覆盖索引查询分页所需的主键,再通过主键关联查询完整数据,减少回表次数
-- 正例:延迟关联优化
EXPLAIN SELECT a.* FROM user_info a INNER JOIN (SELECT id FROM user_info ORDER BY id LIMIT 100000, 20) b ON a.id = b.id;
3. 业务限制分页深度:禁止无限制分页,比如最多允许翻页到100页,超过后提示用户缩小查询范围,从根源上避免深分页问题。
GROUP BY和ORDER BY是引发Using temporary、Using filesort的核心原因,优化的核心原则是:让排序/分组的字段与索引的顺序、升降序完全一致,避免额外的排序操作
-- 反例:排序字段与索引顺序不一致,触发Using filesort
EXPLAIN SELECT * FROM user_info WHERE age = 18 ORDER BY create_time DESC, age ASC;
-- 正例:排序字段与索引顺序、升降序一致,无Using filesort
EXPLAIN SELECT * FROM user_info WHERE age = 18 ORDER BY age ASC, create_time DESC;
-- 反例:分组字段无索引,触发Using temporary、Using filesort
EXPLAIN SELECT age, COUNT(*) FROM user_info GROUP BY age;
-- 正例:分组字段有索引,无临时表、无文件排序
EXPLAIN SELECT age, COUNT(*) FROM user_info USE INDEX (idx_age_create_time) GROUP BY age;
常见的聚合函数有COUNT、SUM、MAX、MIN,优化核心是利用索引减少扫描行数。
核心纠正:COUNT( )、COUNT(1)、COUNT(主键)的性能几乎无差异,MySQL优化器会选择最小的辅助索引进行统计,COUNT(非空字段)与COUNT( )等价,COUNT(允许NULL的字段)会忽略NULL值,性能最差。
-- 最优写法:统计总行数
SELECT COUNT(*) FROM user_info;
-- 反例:统计行数却用COUNT(字段),性能差
SELECT COUNT(age) FROM user_info;
-- 优化:判断是否存在符合条件的数据,用LIMIT 1替代COUNT(*)
-- 反例:全表扫描符合条件的行
SELECT COUNT(*) FROM user_info WHERE age > 18 LIMIT 1;
-- 正例:找到第一行就返回,无需扫描全表
SELECT 1 FROM user_info WHERE age > 18 LIMIT 1;
MAX/MIN函数可直接利用B+树的有序性,索引列的MAX/MIN查询只需访问索引树的根节点或叶子节点的首尾,性能最优。
-- 正例:索引列的MAX查询,无需扫描全表
EXPLAIN SELECT MAX(create_time) FROM user_info WHERE age = 18;
批量插入、更新是提升写入性能的核心方案,可大幅减少网络IO、事务开销、锁等待时间。
-- 反例:循环单条插入,性能极差
INSERT INTO user_info (user_no, user_name, age, phone) VALUES ('U001', '张三', 18, '13800138000');
INSERT INTO user_info (user_no, user_name, age, phone) VALUES ('U002', '李四', 20, '13800138001');
-- 正例:批量插入,一次提交
INSERT INTO user_info (user_no, user_name, age, phone)
VALUES ('U001', '张三', 18, '13800138000'), ('U002', '李四', 20, '13800138001');
-- 反例:大表单条更新,锁表时间长,引发锁等待
UPDATE order_info SET order_status = 1 WHERE create_time < '2024-01-01';
-- 正例:分批更新,每次更新1000条,避免锁表
UPDATE order_info SET order_status = 1 WHERE create_time < '2024-01-01' AND id BETWEEN 1 AND 1000;
UPDATE order_info SET order_status = 1 WHERE create_time < '2024-01-01' AND id BETWEEN 1001 AND 2000;
规范是避免慢SQL的第一道防线,以下规范均经过生产环境验证,可直接落地。
BIGINT UNSIGNED AUTO_INCREMENT,禁止使用UUID作为主键,避免InnoDB页分裂,影响写入性能。NOT NULL DEFAULT,NULL值会占用额外存储空间,导致索引、统计、比较运算更复杂。VARCHAR,长度不超过2048,大文本使用TEXT,禁止在TEXT字段上建立索引。DECIMAL,禁止使用FLOAT、DOUBLE,避免精度丢失。DATETIME(3),精度到毫秒,禁止使用VARCHAR、INT存储时间。COMMENT注释,明确业务含义。utf8mb4,排序规则使用utf8mb4_0900_ai_ci,支持emoji和所有中文。pk_字段名,唯一索引uk_字段名,普通索引idx_字段1_字段2_字段3(按最左前缀顺序命名)。COUNT(DISTINCT 字段)/COUNT(*),越接近1区分度越高。idx_a_b(a,b),禁止再建立idx_a(a)。SELECT *,必须指定具体的查询字段,避免返回无用数据,无法使用覆盖索引。基于Spring Boot 3.2.4、JDK 17、MyBatis-Plus 3.5.6实现,符合编码规范,结合SQL优化最佳实践。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.2.4</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.3.0</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.52</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.1.0-jre</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<version>3.2.4</version>
</dependency>
</dependencies>
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.time.LocalDateTime;
/**
* 用户信息实体类
* @author ken
*/
@Data
@TableName("user_info")
@Schema(name = "UserInfo", description = "用户信息实体")
public class UserInfo {
@TableId(type = IdType.AUTO)
@Schema(description = "主键ID", example = "1")
private Long id;
@TableField("user_no")
@Schema(description = "用户编号", example = "U001")
private String userNo;
@TableField("user_name")
@Schema(description = "用户姓名", example = "张三")
private String userName;
@TableField("age")
@Schema(description = "年龄", example = "18")
private Integer age;
@TableField("gender")
@Schema(description = "性别 0-未知 1-男 2-女", example = "1")
private Integer gender;
@TableField("phone")
@Schema(description = "手机号", example = "13800138000")
private String phone;
@TableField("create_time")
@Schema(description = "创建时间")
private LocalDateTime createTime;
@TableField("update_time")
@Schema(description = "更新时间")
private LocalDateTime updateTime;
}
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.jam.demo.entity.UserInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
/**
* 用户信息Mapper接口
* @author ken
*/
@Mapper
public interface UserInfoMapper extends BaseMapper<UserInfo> {
/**
* 延迟关联分页查询用户列表
* @param page 分页参数
* @param minAge 最小年龄
* @param maxAge 最大年龄
* @return 分页结果
*/
IPage<UserInfo> selectUserPageByDelayJoin(Page<UserInfo> page, @Param("minAge") Integer minAge, @Param("maxAge") Integer maxAge);
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jam.demo.mapper.UserInfoMapper">
<resultMap id="BaseResultMap" type="com.jam.demo.entity.UserInfo">
<id column="id" property="id" jdbcType="BIGINT"/>
<result column="user_no" property="userNo" jdbcType="VARCHAR"/>
<result column="user_name" property="userName" jdbcType="VARCHAR"/>
<result column="age" property="age" jdbcType="INTEGER"/>
<result column="gender" property="gender" jdbcType="TINYINT"/>
<result column="phone" property="phone" jdbcType="VARCHAR"/>
<result column="create_time" property="createTime" jdbcType="TIMESTAMP"/>
<result column="update_time" property="updateTime" jdbcType="TIMESTAMP"/>
</resultMap>
<select id="selectUserPageByDelayJoin" resultMap="BaseResultMap">
SELECT a.* FROM user_info a
INNER JOIN (
SELECT id FROM user_info
WHERE age BETWEEN #{minAge} AND #{maxAge}
ORDER BY id
) b ON a.id = b.id
</select>
</mapper>
package com.jam.demo.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.jam.demo.entity.UserInfo;
/**
* 用户信息服务接口
* @author ken
*/
public interface UserInfoService extends IService<UserInfo> {
/**
* 分页查询用户列表
* @param pageNum 页码
* @param pageSize 每页条数
* @param minAge 最小年龄
* @param maxAge 最大年龄
* @return 分页结果
*/
IPage<UserInfo> getUserPage(Integer pageNum, Integer pageSize, Integer minAge, Integer maxAge);
/**
* 批量保存用户信息
* @param userInfoList 用户列表
* @return 保存结果
*/
Boolean batchSaveUserInfo(java.util.List<UserInfo> userInfoList);
}
package com.jam.demo.service.impl;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.google.common.collect.Lists;
import com.jam.demo.entity.UserInfo;
import com.jam.demo.mapper.UserInfoMapper;
import com.jam.demo.service.UserInfoService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallback;
import org.springframework.transaction.support.TransactionTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import jakarta.annotation.Resource;
import java.util.List;
/**
* 用户信息服务实现类
* @author ken
*/
@Slf4j
@Service
public class UserInfoServiceImpl extends ServiceImpl<UserInfoMapper, UserInfo> implements UserInfoService {
@Resource
private UserInfoMapper userInfoMapper;
@Resource
private TransactionTemplate transactionTemplate;
private static final int BATCH_SIZE = 1000;
@Override
public IPage<UserInfo> getUserPage(Integer pageNum, Integer pageSize, Integer minAge, Integer maxAge) {
if (ObjectUtils.isEmpty(pageNum) || pageNum < 1) {
pageNum = 1;
}
if (ObjectUtils.isEmpty(pageSize) || pageSize < 1 || pageSize > 100) {
pageSize = 20;
}
Page<UserInfo> page = new Page<>(pageNum, pageSize);
return userInfoMapper.selectUserPageByDelayJoin(page, minAge, maxAge);
}
@Override
public Boolean batchSaveUserInfo(List<UserInfo> userInfoList) {
if (CollectionUtils.isEmpty(userInfoList)) {
return Boolean.TRUE;
}
return transactionTemplate.execute(new TransactionCallback<Boolean>() {
@Override
public Boolean doInTransaction(TransactionStatus status) {
try {
List<List<UserInfo>> partitionList = Lists.partition(userInfoList, BATCH_SIZE);
for (List<UserInfo> partition : partitionList) {
saveBatch(partition, BATCH_SIZE);
}
return Boolean.TRUE;
} catch (Exception e) {
status.setRollbackOnly();
log.error("批量保存用户信息失败", e);
return Boolean.FALSE;
}
}
});
}
}
package com.jam.demo.controller;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.jam.demo.entity.UserInfo;
import com.jam.demo.service.UserInfoService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import jakarta.annotation.Resource;
import java.util.List;
/**
* 用户信息控制器
* @author ken
*/
@Slf4j
@RestController
@RequestMapping("/user")
@Tag(name = "用户信息管理", description = "用户信息的增删改查接口")
public class UserInfoController {
@Resource
private UserInfoService userInfoService;
@GetMapping("/page")
@Operation(summary = "分页查询用户列表", description = "延迟关联优化的分页查询,支持年龄范围筛选")
public ResponseEntity<IPage<UserInfo>> getUserPage(
@Parameter(description = "页码", example = "1") @RequestParam(defaultValue = "1") Integer pageNum,
@Parameter(description = "每页条数", example = "20") @RequestParam(defaultValue = "20") Integer pageSize,
@Parameter(description = "最小年龄", example = "18") @RequestParam Integer minAge,
@Parameter(description = "最大年龄", example = "30") @RequestParam Integer maxAge
) {
IPage<UserInfo> pageResult = userInfoService.getUserPage(pageNum, pageSize, minAge, maxAge);
return ResponseEntity.ok(pageResult);
}
@PostMapping("/batch/save")
@Operation(summary = "批量保存用户信息", description = "分批批量插入,提升写入性能")
public ResponseEntity<Boolean> batchSaveUserInfo(@RequestBody List<UserInfo> userInfoList) {
Boolean result = userInfoService.batchSaveUserInfo(userInfoList);
return ResponseEntity.ok(result);
}
@GetMapping("/{id}")
@Operation(summary = "根据ID查询用户信息", description = "主键查询,性能最优")
public ResponseEntity<UserInfo> getUserById(@Parameter(description = "用户ID", example = "1") @PathVariable Long id) {
if (id == null || id < 1) {
return ResponseEntity.badRequest().build();
}
UserInfo userInfo = userInfoService.getById(id);
return ResponseEntity.ok(userInfo);
}
}
优化的前提是发现问题,建立完善的慢SQL监控体系,是线上数据库稳定运行的核心保障。
MySQL慢查询日志会记录执行时间超过阈值的SQL,是发现慢SQL的核心手段,MySQL 8.0配置方式:
# my.cnf 配置文件
slow_query_log = ON
long_query_time = 1
log_queries_not_using_indexes = ON
log_output = FILE
slow_query_log_file = /var/log/mysql/slow.log
配置修改后,无需重启MySQL,执行以下命令即可生效:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
SET GLOBAL log_queries_not_using_indexes = 'ON';
# 统计耗时最长的10条SQL
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 统计访问次数最多的10条SQL
mysqldumpslow -s c -t 10 /var/log/mysql/slow.log
2. pt-query-digest:Percona Toolkit提供的慢日志分析工具,功能更强大,可生成详细的分析报告,是生产环境的首选工具。
SQL性能优化的核心,不是盲目加索引,而是理解MySQL的底层执行逻辑,读懂执行计划,从业务场景出发,设计合理的表结构和索引,编写符合规范的SQL。 优化的最高境界,是减少数据库的访问,比如通过缓存、冗余字段、业务逻辑优化,从根源上避免慢SQL的产生。只有把底层逻辑吃透,才能以不变应万变,搞定所有线上SQL性能问题。

