
刮个爽
184.81M · 2026-03-22

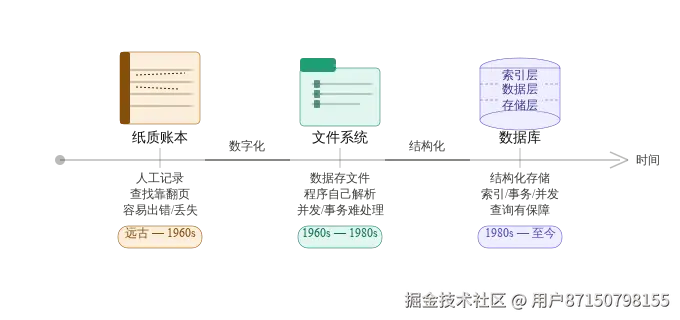
在关系型数据库诞生之前(1970 年代以前),企业存储数据的方式极为原始。数据被写进一个个文本文件、CSV 表格,甚至是纸质账本。随着业务规模扩大,问题接踵而至。
想象一个场景:你是一家连锁超市的 IT 员工,老板问你:
如果没有数据库,你会怎么做?
| 步骤 | 你要做的事 | 痛点 |
|---|---|---|
| 1 | 找到华东所有门店的销售文件 | 文件散落在各个服务器目录里 |
| 2 | 打开每一个文件,手动筛选"牛奶"关键字 | 文件格式不统一,有的是 .txt,有的是 .csv |
| 3 | 把每家门店的数量加在一起 | 字段名不一样,有叫 count,有叫 数量,有叫 qty |
| 4 | 汇总结果 | 你可能已经花了半天时间 |
这就是没有数据库时,查数据的真实痛苦:
1970 年,Edgar F. Codd 在 IBM 发表论文 "A Relational Model of Data for Large Shared Data Banks" ,提出关系模型,现代数据库的基础由此奠定。
数据库解决的核心问题可以总结为四个字:统一管理。
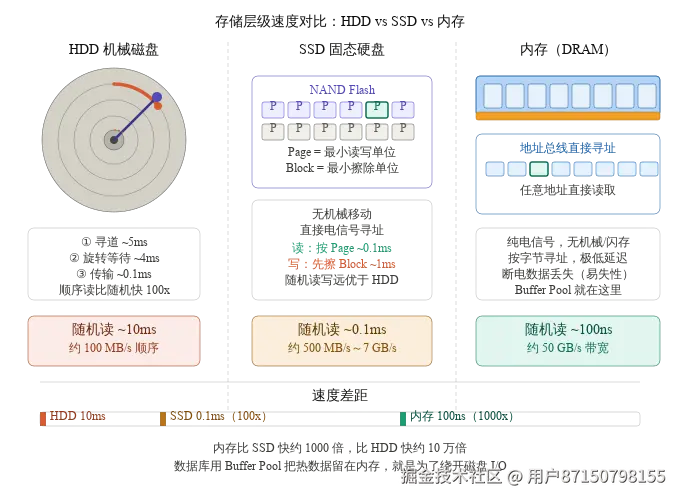
不管上层的 SQL 有多优雅,数据最终都需要持久化到磁盘上。这里有一个关键的物理约束:
磁盘读取数据的方式和内存完全不同:
既然每次 I/O 都有固定开销,那最合理的设计就是:
每次 I/O 尽量多搬一点数据,把开销摊薄。
这个"每次搬运的固定大小的数据块",就是 Page(页) 。
磁盘 I/O 的本质:
不是读 1 行数据 → 而是读 1 个 Page(通常 4KB 或 16KB)
不是写 1 行数据 → 而是写 1 个 Page
Page 的大小通常是操作系统页大小的整数倍:
| 数据库 | 默认 Page 大小 |
|---|---|
| MySQL InnoDB | 16 KB |
| PostgreSQL | 8 KB |
| SQLite | 4 KB(可配置) |
| Oracle | 8 KB(可配置至 32 KB) |
| SQL Server | 8 KB |
一个 Page 在物理上是一块连续的字节序列,逻辑上分为几个固定区域。以 MySQL InnoDB 的 16KB Page 为例:
这是 Page 的"身份证",记录了 Page 在整个文件中的位置信息和类型:
| 字段 | 大小 | 含义 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM | 4 字节 | 校验和(新版)或 Space ID |
FIL_PAGE_OFFSET | 4 字节 | 当前 Page 的页号(从 0 开始) |
FIL_PAGE_PREV | 4 字节 | 上一个 Page 的页号(双向链表) |
FIL_PAGE_NEXT | 4 字节 | 下一个 Page 的页号(双向链表) |
FIL_PAGE_LSN | 8 字节 | 最后修改该 Page 的 LSN(日志序列号) |
FIL_PAGE_TYPE | 2 字节 | Page 的类型(数据页、索引页、Undo 页等) |
记录当前 Page 的状态信息,核心字段:
PAGE_N_DIR_SLOTS:Page Directory 中槽的数量PAGE_HEAP_TOP:Free Space 的起始偏移量(即下一条记录应该插入的位置)PAGE_N_RECS:当前 Page 中的记录数量PAGE_FREE:已删除记录组成的链表头(用于空间复用)这是真正存放数据行的地方。每条记录并非随意排列,而是通过单向链表按主键顺序串联:
Infimum → Record_1 → Record_2 → Record_3 → Supremum
(最小) (最大)
每条记录头部包含:
delete_mask:是否被标记删除(逻辑删除)heap_no:在堆中的位置编号next_record:下一条记录的相对偏移量Page Directory 是 Page 内部的二级索引,用于加速页内查找。
如果没有 Page Directory,在一个 16KB 的页里查找一条记录,需要从 Infimum 顺序遍历链表,最坏情况是 O(n)。
Page Directory 把记录分组,每组的最大记录放入一个"槽(Slot)",槽存储的是该记录在 Page 内的偏移量。查找时先二分槽,再在槽对应的小组内顺序查找,复杂度降为 O(log n + 小常数) 。
Page Directory(从页尾往上):
Slot[0] → Supremum 的偏移
Slot[1] → 第 8 条记录的偏移
Slot[2] → 第 4 条记录的偏移
Slot[3] → Infimum 的偏移
Page 不只用来存数据行,不同类型的 Page 承担不同职责:
| Page 类型 | 常量 | 用途 |
|---|---|---|
FIL_PAGE_INDEX | 0x45BF | B+ Tree 的节点(数据页或索引页) |
FIL_PAGE_UNDO_LOG | 0x0002 | Undo Log,用于事务回滚和 MVCC |
FIL_PAGE_INODE | 0x0003 | 段(Segment)信息 |
FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer 的空闲列表 |
FIL_PAGE_TYPE_SYS | 0x000B | 系统页 |
FIL_PAGE_TYPE_FSP_HDR | 0x0008 | 表空间头页 |
FIL_PAGE_TYPE_XDES | 0x0009 | 区(Extent)描述页 |
Page 不是孤立存在的,它处于数据库存储体系的中间层,连接着上层的逻辑结构和下层的物理存储。
逻辑层(用户视角)
Table(表)
↓
Index(索引 / B+ Tree)
↓
Segment(段:叶子段 + 非叶子段)
↓
Extent(区:64 个连续 Page = 1MB)
↓
► Page(页:16KB) ◄ ← 我们今天的主角
↓
Row(行:Page 内的记录)
↓
物理层(磁盘视角)
.ibd 文件(表空间文件)
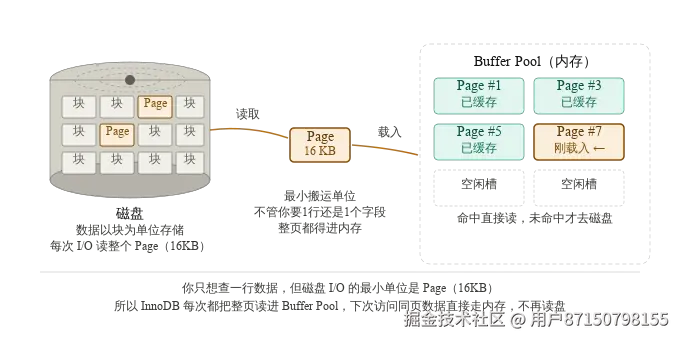
Buffer Pool 是数据库的内存缓存层,所有对 Page 的读写都先经过它。
工作流程:
① SQL 执行 → 需要读取某行数据
② 计算该行所在的 Page 编号
③ 查询 Buffer Pool 的哈希表:Page 是否已在内存?
├── 命中(Cache Hit):直接返回内存中的 Page,无 I/O
└── 未命中(Cache Miss):从磁盘读取该 Page 载入 Buffer Pool,再返回
④ 修改 Page → Page 变为 Dirty Page(脏页)
⑤ Checkpoint 或 LRU 淘汰时 → 将 Dirty Page 刷回磁盘
关键数据结构:
InnoDB 的每张表(聚簇索引)和每个二级索引,都是一棵 B+ Tree。B+ Tree 的每个节点就是一个 Page:
[根节点 Page]
/
[内节点 Page] [内节点 Page]
/ /
[叶子 Page] [叶子 Page] [叶子 Page] [叶子 Page]
↔ ↔ ↔ ↔
(叶子层的 Page 通过 File Header 中的 PREV/NEXT 形成双向链表)
为了保证崩溃后数据不丢失(Durability),InnoDB 使用 WAL(Write-Ahead Logging) 机制:
① 事务修改一行数据
② 先写 Redo Log(顺序写,极快)
③ 再修改 Buffer Pool 中的 Page(内存操作)
④ 返回事务提交成功
⑤ 异步将 Dirty Page 刷回磁盘
崩溃恢复时:
读取 Redo Log → 重放所有已提交但未刷盘的 Page 修改 → 恢复完毕
Page Header 中的 LSN(Log Sequence Number) 字段,记录了该 Page 最后一次被修改时对应的 Redo Log 位置,这是崩溃恢复的核心依据。
从一个简单的"查数据很痛苦"的问题出发,我们一路推导到了数据库最核心的存储单位——Page。
痛点 → 数据库 → 磁盘 I/O 瓶颈 → Page 设计 → Page 内部结构 → 与上下游的协作
| 组件 | 与 Page 的关系 |
|---|---|
| Buffer Pool | Page 的内存缓存,所有读写必经之路 |
| B+ Tree | 用 Page 作为节点,构建索引结构 |
| Redo Log / WAL | 通过 LSN 追踪 Page 的修改,保障崩溃恢复 |
| Extent / Segment | Page 的上级管理单位,负责磁盘空间分配 |
| Undo Log | 特殊类型的 Page,支持事务回滚和 MVCC |
理解 Page,就是理解数据库存储引擎的基础。后续无论是深入研究索引、事务、锁,还是调优 innodb_buffer_pool_size,都会不断回到这个最小单位。

