魔物公寓
45.13M · 2026-03-13


PostgreSQL 采用经典的多进程架构,每个客户端连接对应一个独立的操作系统进程。
每个客户端连接对应一个独立的后端进程,包含完整的查询处理上下文:
// 进程上下文结构示意
typedef struct {
Port *port; // 连接端口信息
MemoryContext top_memory; // 顶级内存上下文
TransactionState s_cur; // 当前事务状态
List *parse_trees; // 解析树列表
QueryDesc *query_desc; // 查询描述符
TupleTableSlot *slot; // 元组槽
ResourceOwner resowner; // 资源所有者
} BackendProcess;
| 进程名称 | 主要职责 | 触发条件 | 关键参数 |
|---|---|---|---|
| Writer | 将脏页刷回磁盘 | 后台定期或缓冲区满 | bgwriter_delay, bgwriter_lru_maxpages |
| WAL Writer | 刷写WAL缓冲区 | 事务提交或缓冲区满 | wal_writer_delay, wal_writer_flush_after |
| Checkpointer | 执行检查点 | 定期或手动CHECKPOINT | checkpoint_timeout, checkpoint_completion_target |
| Autovacuum Launcher | 启动自动清理工作进程 | 定期检查需要清理的表 | autovacuum_naptime, autovacuum_max_workers |
| Autovacuum Worker | 执行实际的VACUUM/ANALYZE | 由Launcher启动 | autovacuum_vacuum_threshold |
| Archiver | 归档WAL日志 | WAL段文件切换 | archive_mode, archive_command |
| Stats Collector | 收集统计信息 | 定期或DDL操作后 | stats_temp_directory |
| Logical Replication Launcher | 启动逻辑复制工作进程 | 配置了逻辑复制时 | max_logical_replication_workers |
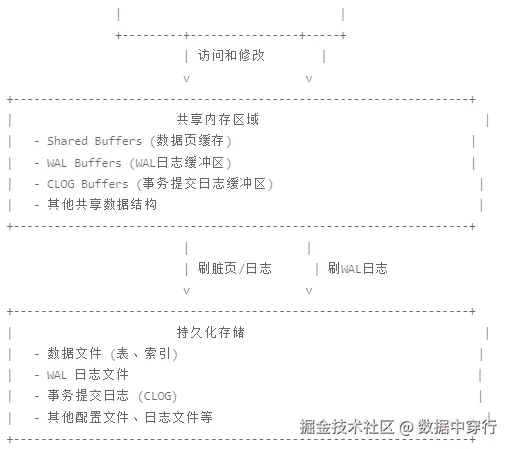
在数据库启动时一次性分配,所有进程共享访问:
// 共享内存主要区域
typedef struct {
shmem_startup_hdr *shim; // 启动头信息
PGShmemHeader *header; // 共享内存头
BufferDescriptors *buf_desc; // 缓冲区描述符数组
BufferBlocks *buf_blocks; // 实际数据缓冲区
LWLockArray *lock_array; // 轻量级锁数组
ProcArray *proc_array; // 进程状态数组
XLogCtlData *xlog_ctl; // WAL控制结构
CLogCtlData *clog_ctl; // 提交日志控制
MultiXactState *multi_state; // 多事务状态
// ... 其他共享数据结构
} SharedMemoryArea;
关键共享区域:
每个后端进程独立分配,用于查询执行:
| 内存上下文 | 用途 | 生命周期 |
|---|---|---|
| TopMemoryContext | 进程生命周期内存 | 进程存活期间 |
| CacheMemoryContext | 系统缓存(如relcache) | 长期存在 |
| MessageContext | 客户端消息处理 | 每个消息 |
| TupleContext | 元组处理临时内存 | 每个元组处理 |
| ExprContext | 表达式求值 | 每个表达式 |
| WorkMem | 排序、哈希操作 | 每个操作 |
| MaintenanceWorkMem | VACUUM、CREATE INDEX等 | 维护操作期间 |
-- 示例:SELECT * FROM users WHERE id = 1;
解析器生成原始解析树:
typedef struct SelectStmt {
NodeTag type;
List *targetList; // 目标列列表
List *fromClause; // FROM子句
Node *whereClause; // WHERE条件
List *groupClause; // GROUP BY
Node *havingClause; // HAVING
List *windowClause; // WINDOW
// ... 其他字段
} SelectStmt;
typedef struct Query {
NodeTag type;
CmdType commandType; // SELECT/INSERT/UPDATE/DELETE
List *rtable; // 范围表
List *jointree; // 连接树
List *targetList; // 目标列表
List *returningList; // RETURNING列表
// ... 其他字段
} Query;
基于成本的优化器(CBO)工作流程:
子查询处理:扁平化子查询,转换为连接
预处理表达式:常量折叠、函数内联
生成路径:
成本估算:基于统计信息计算I/O、CPU成本
路径选择:选择成本最低的执行路径
// 路径成本估算
typedef struct Path {
NodeTag type;
NodeTag pathtype; // 路径类型
RelOptInfo *parent; // 父关系
PathTarget *pathtarget; // 路径输出
ParamPathInfo *param_info;
List *pathkeys; // 路径排序
double rows; // 预估行数
Cost startup_cost; // 启动成本
Cost total_cost; // 总成本
} Path;
采用火山模型(Volcano Model) 的迭代器模式:
// 执行器状态机
typedef struct PlanState {
NodeTag type;
Plan *plan; // 对应的计划节点
EState *state; // 执行状态
TupleTableSlot *ps_ResultTupleSlot; // 结果元组槽
// 迭代器接口
TupleTableSlot *(*ExecProcNode)(struct PlanState *pstate);
// 子节点
List *child_ps;
} PlanState;
主要执行节点类型:
$PGDATA/
├── base/ # 默认表空间
│ ├── 1/ # 数据库OID
│ │ ├── 12345 # 关系文件(表/索引)
│ │ ├── 12345_fsm # 空闲空间映射
│ │ ├── 12345_vm # 可见性映射
│ │ └── 12345_init # 初始化分支
├── pg_tblspc/ # 表空间链接
├── pg_wal/ # WAL日志
├── pg_xact/ # 提交日志
└── pg_stat/ # 统计信息
页面结构(8KB默认):
+-----------------------+
| PageHeaderData (24B) |
+-----------------------+
| LinePointer1 (4B) |
| LinePointer2 (4B) |
| ... |
+-----------------------+
| Free Space |
+-----------------------+
| Tuple1 |
| Tuple2 |
| ... |
+-----------------------+
| Special Space |
+-----------------------+
元组头结构:
typedef struct HeapTupleHeaderData {
union {
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; // 当前元组ID(页号+行指针)
uint16 t_infomask2; // 属性数量+标志位
uint16 t_infomask; // 标志位(可见性、锁等)
uint8 t_hoff; // 头长度
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; // NULL位图
} HeapTupleHeaderData;
PostgreSQL支持多种索引访问方法:
| 索引类型 | 适用场景 | 内部结构 | 特性 |
|---|---|---|---|
| B-Tree | 默认索引,范围查询 | B+树变体 | 支持排序、唯一约束 |
| Hash | 等值查询 | 哈希表 | 仅支持等值比较 |
| GiST | 地理数据、全文搜索 | 平衡树 | 可扩展,支持自定义操作符 |
| SP-GiST | 非平衡数据结构 | 空间分区树 | 适合不规则数据分布 |
| GIN | 多值类型(数组、JSON) | 倒排索引 | 支持包含查询 |
| BRIN | 大数据表,有序数据 | 块范围索引 | 存储空间小 |
元组可见性判断算法:
bool HeapTupleSatisfiesMVCC(HeapTuple htup, Snapshot snapshot,
Buffer buffer) {
// 获取元组的事务信息
xmin = HeapTupleHeaderGetXmin(htup->t_data);
xmax = HeapTupleHeaderGetXmax(htup->t_data);
// 根据快照判断可见性
if (TransactionIdIsCurrentTransactionId(xmin)) {
// 当前事务插入
if (HeapTupleHeaderGetCmin(htup->t_data) >= snapshot->curcid)
return false; // 命令ID在快照之后
else
return true;
} else if (TransactionIdIsInProgress(xmin)) {
// 其他活跃事务插入
return false;
} else if (TransactionIdDidCommit(xmin)) {
// 已提交事务插入
// 检查删除事务
if (!HeapTupleHeaderXmaxCommitted(htup->t_data)) {
if (TransactionIdIsCurrentTransactionId(xmax)) {
// 当前事务删除
return false;
}
if (TransactionIdIsInProgress(xmax)) {
// 其他活跃事务删除
return true;
}
if (TransactionIdDidCommit(xmax)) {
// 已提交事务删除
return false;
}
return true; // 删除事务已中止
}
return false; // 已删除
} else {
// 插入事务已中止
return false;
}
}
-- PostgreSQL支持的隔离级别
SET TRANSACTION ISOLATION LEVEL
READ UNCOMMITTED | -- 实际实现为READ COMMITTED
READ COMMITTED | -- 默认级别
REPEATABLE READ | -- 快照隔离
SERIALIZABLE; -- 可串行化
快照数据结构:
typedef struct SnapshotData {
SnapshotType snapshot_type; // 快照类型
TransactionId xmin; // 最早仍活跃的事务ID
TransactionId xmax; // 第一个未分配的事务ID
TransactionId *xip; // 活跃事务ID数组
uint32 xcnt; // 活跃事务数量
CommandId curcid; // 当前命令ID
uint32 speculativeToken;
struct GlobalVisState *vistest;
TimestampTz taken_at; // 快照获取时间
// ... 其他字段
} SnapshotData;
typedef struct XLogRecord {
uint32 xl_tot_len; // 记录总长度
TransactionId xl_xid; // 事务ID
XLogRecPtr xl_prev; // 前一条记录指针
uint8 xl_info; // 标志位
RmgrId xl_rmid; // 资源管理器ID
pg_crc32c xl_crc; // CRC校验
// 之后是实际的数据
} XLogRecord;
检查点触发条件:
检查点执行流程:
void CreateCheckPoint(int flags) {
// 1. 开始检查点
START_CRIT_SECTION();
// 2. 刷新所有脏页到磁盘
CheckPointBuffers();
// 3. 写入检查点记录到WAL
XLogBeginInsert();
XLogRegisterData(&checkPoint, sizeof(checkPoint));
XLogInsert(RM_XLOG_ID, XLOG_CHECKPOINT_SHUTDOWN);
// 4. 刷新WAL到磁盘
XLogFlush(recptr);
// 5. 更新控制文件
UpdateControlFile();
// 6. 删除旧的WAL文件
RemoveOldWalFiles();
END_CRIT_SECTION();
}
// 扩展加载接口
typedef struct {
const char *name; // 扩展名
void (*init)(void); // 初始化函数
void (*shutdown)(void); // 关闭函数
// ... 其他钩子函数
} ExtensionCallbacks;
// 注册示例
PG_MODULE_MAGIC;
void _PG_init(void) {
// 注册扩展
RegisterExtension("my_extension", my_init, my_shutdown);
}
| 组件类型 | 注册函数 | 用途示例 |
|---|---|---|
| 数据类型 | CREATE TYPE | 自定义几何类型、货币类型 |
| 函数 | CREATE FUNCTION | 用户定义函数、聚合函数 |
| 操作符 | CREATE OPERATOR | 自定义比较操作符 |
| 索引方法 | CREATE ACCESS METHOD | 支持新的索引结构 |
| 外部数据包装器 | CREATE FOREIGN DATA WRAPPER | 访问外部数据源 |
| 表访问方法 | CREATE TABLE ACCESS METHOD | 自定义表存储格式 |
| 过程语言 | CREATE LANGUAGE | PL/Python、PL/Java |
-- 并行查询配置
SET max_parallel_workers_per_gather = 4;
SET parallel_setup_cost = 1000;
SET parallel_tuple_cost = 0.1;
-- 并行执行计划示例
EXPLAIN (ANALYZE, VERBOSE)
SELECT COUNT(*) FROM large_table WHERE condition;
-- 输出将显示 Workers Planned/Launched
-- 声明式分区
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-- 创建分区
CREATE TABLE measurement_y2023m01
PARTITION OF measurement
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
-- 分区裁剪优化
EXPLAIN SELECT * FROM measurement
WHERE logdate >= '2023-01-15' AND logdate < '2023-01-20';
# postgresql.conf 关键参数
shared_buffers = 4GB # 共享缓冲区,建议系统内存的25%
work_mem = 64MB # 每个操作的内存,复杂查询需要更多
maintenance_work_mem = 1GB # 维护操作内存
effective_cache_size = 12GB # 优化器假设的OS缓存大小
wal_level = replica # 或 logical 用于逻辑复制
max_wal_size = 4GB # 最大WAL大小
min_wal_size = 1GB # 最小WAL大小
checkpoint_timeout = 15min # 检查点时间间隔
checkpoint_completion_target = 0.9 # 检查点完成目标
max_worker_processes = 8 # 最大工作进程数
max_parallel_workers_per_gather = 4 # 每个Gather节点的并行数
max_parallel_workers = 8 # 系统并行工作进程数
parallel_setup_cost = 1000 # 并行启动成本
parallel_tuple_cost = 0.1 # 并行元组传输成本
PostgreSQL 的架构设计体现了"稳健优先、功能丰富、高度可扩展"的哲学思想。其多进程模型虽然在某些高并发场景下可能不如多线程模型高效,但提供了无与伦比的稳定性和隔离性。清晰的模块化设计使得每个组件都可以独立优化和扩展,而严谨的 MVCC 实现和完整的 WAL 机制确保了数据的一致性和持久性。
随着 PostgreSQL 的持续发展,其架构也在不断演进,如引入了并行查询、JIT编译、增量排序等现代特性,同时保持了向后兼容性。这种平衡传统与创新的设计理念,使得 PostgreSQL 能够在保持稳定可靠的同时,不断适应新的应用场景和技术挑战。

