


元素潮汐
33.9MB · 2026-03-05

人类很少像今天这样面对一个如此信息膨胀的阶段。每天都有新的模型,新的工具,新的产品,乃至新的概念侵袭我们的日常。每个人都在担心晚一步就落后了时代。
很多人在装上Openclaw之后的第一件事就是让它定时推送AI信息,但是龙虾在黑盒子里自己搜集的信息似乎总有些不够及时,不够全面,或者不是我们期望关注的方向。
所以我花了几天时间搭建了一套高度可定制化的AI信息推送系统——AI Daily。
不仅仅是AI消息,如果是其它领域,只需要更换订阅源,修该一下提示词的信息关注倾向,即可完成对任意领域信息的及时坚控。
灵活,轻量,方便 是 AI Daily的设计理念。
(以下内容的时间参考点基于2026-03-03)
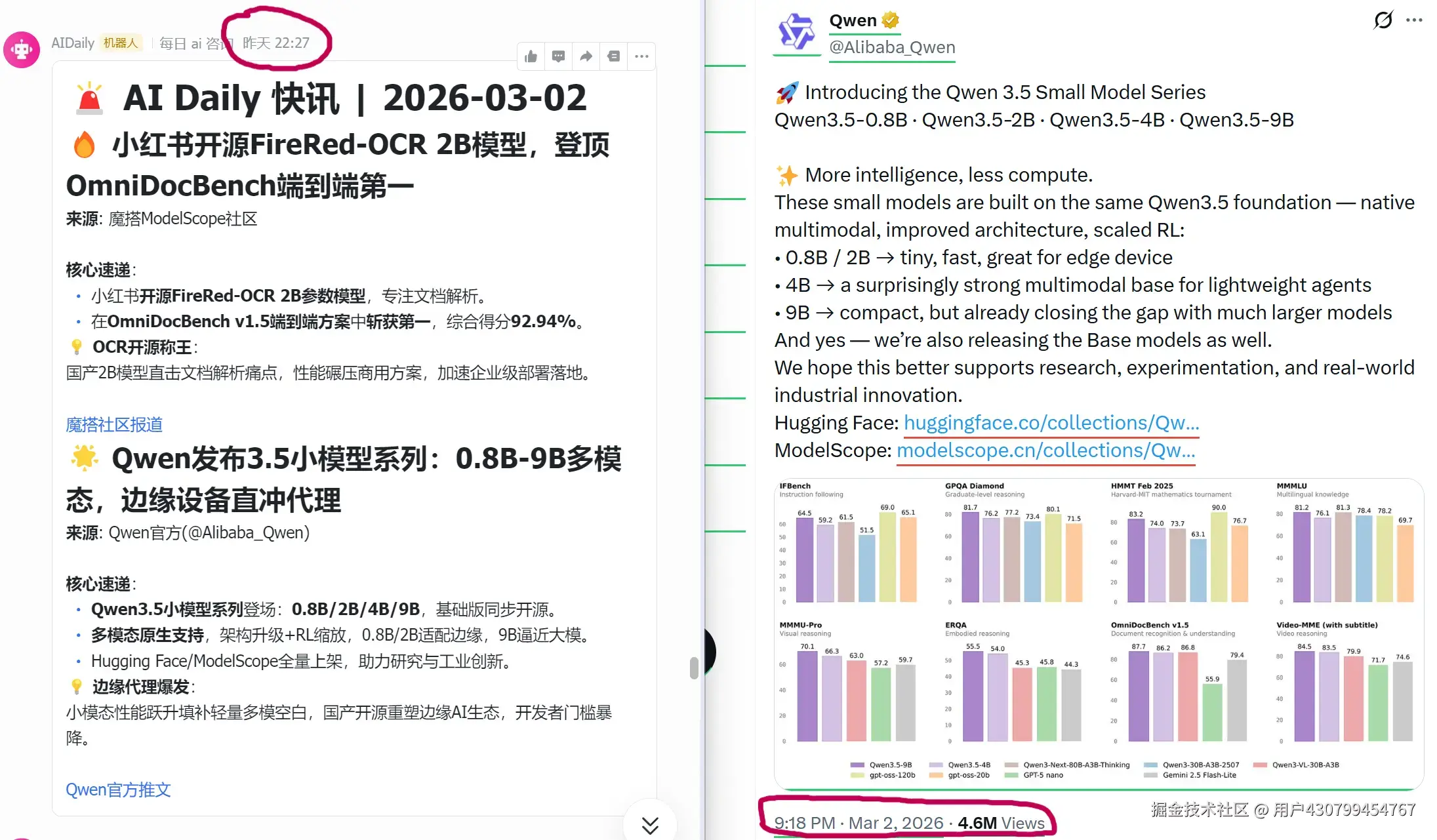
昨天晚上21:18,也就是3月2号,Qwen官推在X上发布了Qwen3.5小模型系列的贴文。 大概一个小时候后22:27分,AI Daily监测到这一消息,并且认为比较重要,判断需要及时推送,所以就发到了我的飞书里面。
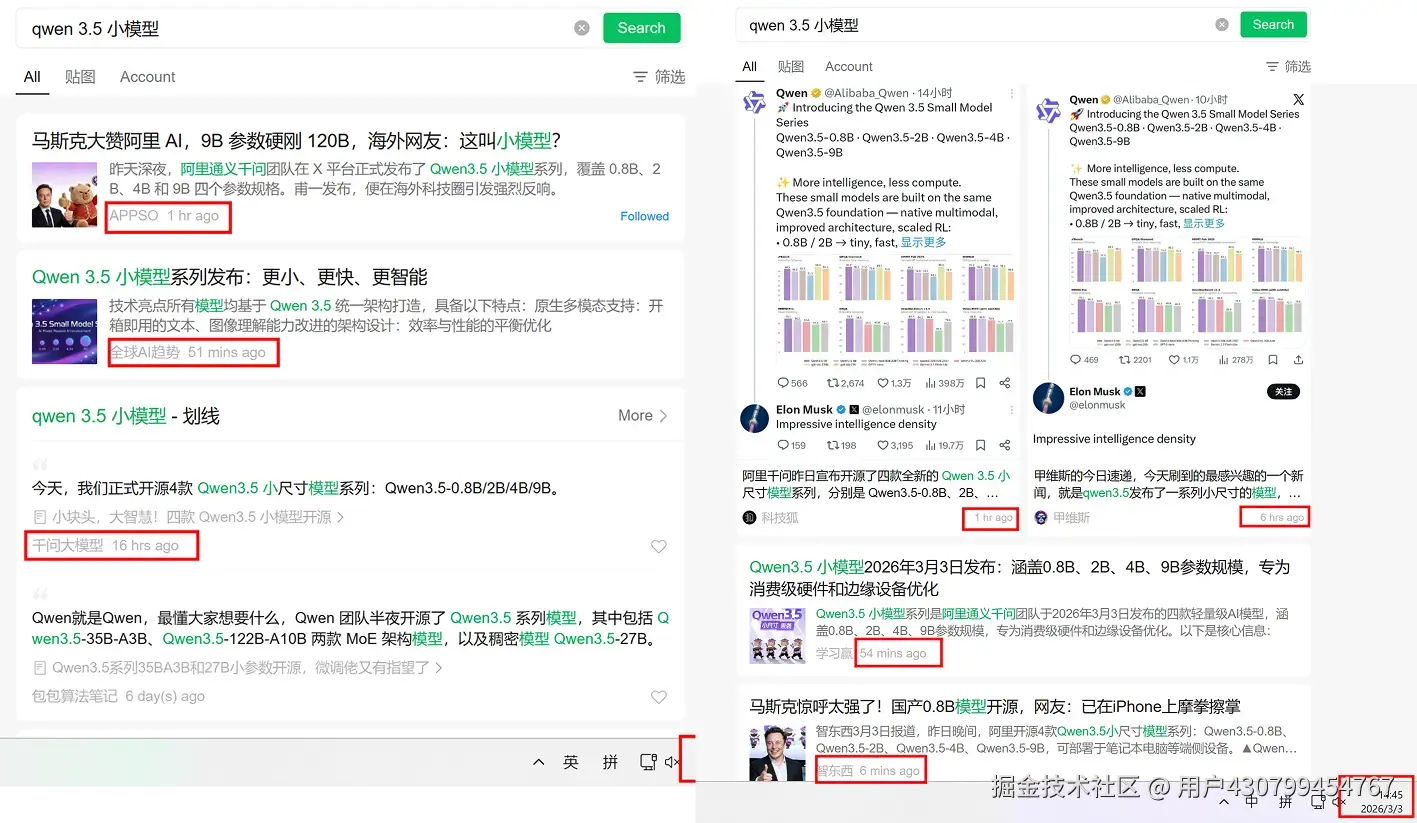
截止到当前时刻(2026-03-03 14:38),如果在微信公众号里面搜索 qwen 3.5 小模型,可以看到 APPSO 在1个小时之前才更新关于该模型的信息,大部分都是在今天才更新的相关信息。只有官方公众号 千问大模型 在16小时前,也就是跟X上推文同步发布了 Qwen3.5小模型 的信息。
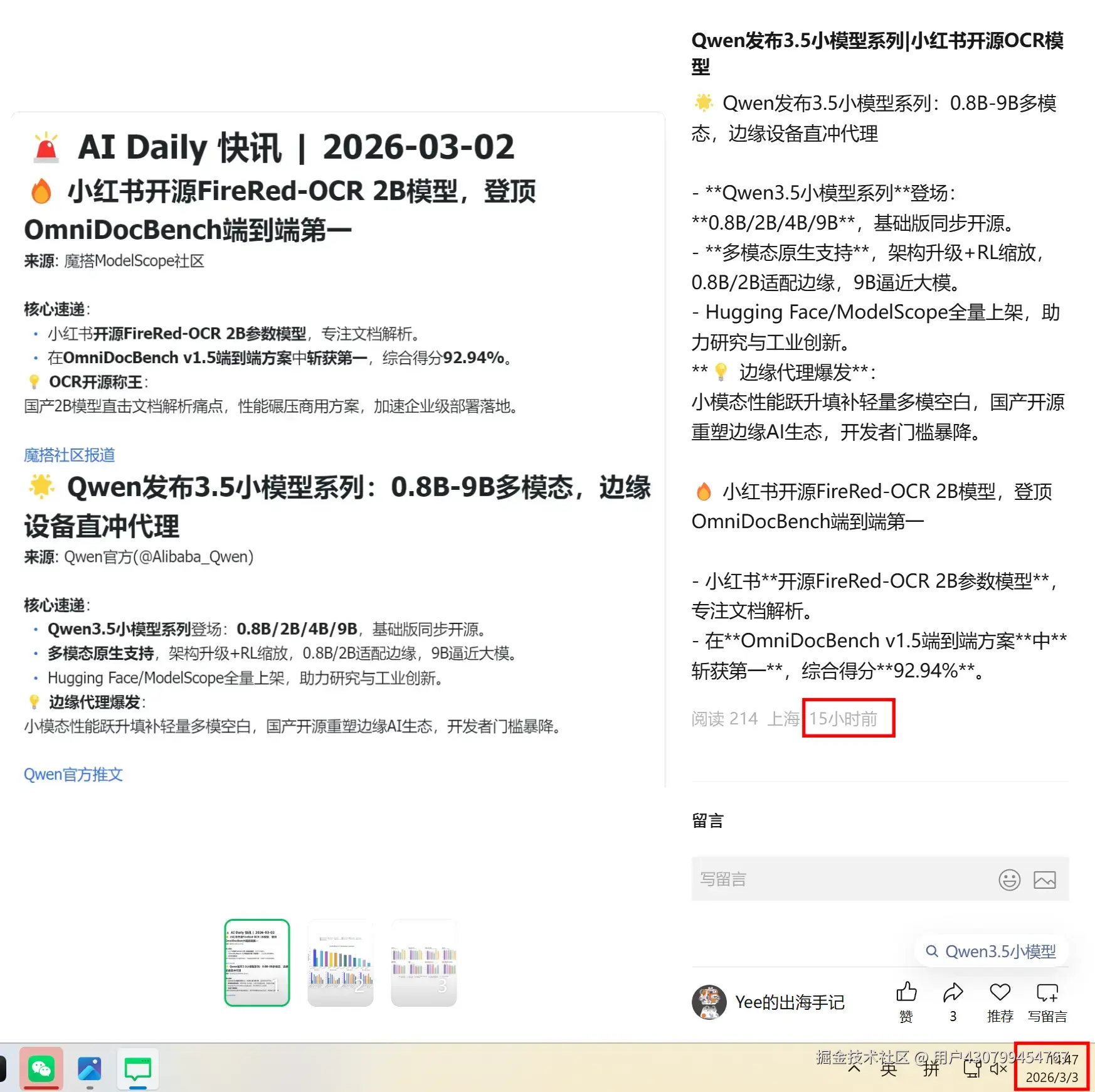
其实我在收到飞书消息之后,也在公众号发了一篇图文。需要继续往下滑才能看到(),时间大概是15h之前。
当然肯定也有其他人在千问公众号刚发出的时候就获知了消息,不过我想说的是不仅仅是千问模型,AI Daily通过实时监测着其它各个科技公司的社交媒体账号,博客,热门公众号,ai领域的KOL的发帖等等,主动地提前推送ai领域重大新闻咨询,让我们对AI信息的把控始终能快人一步。
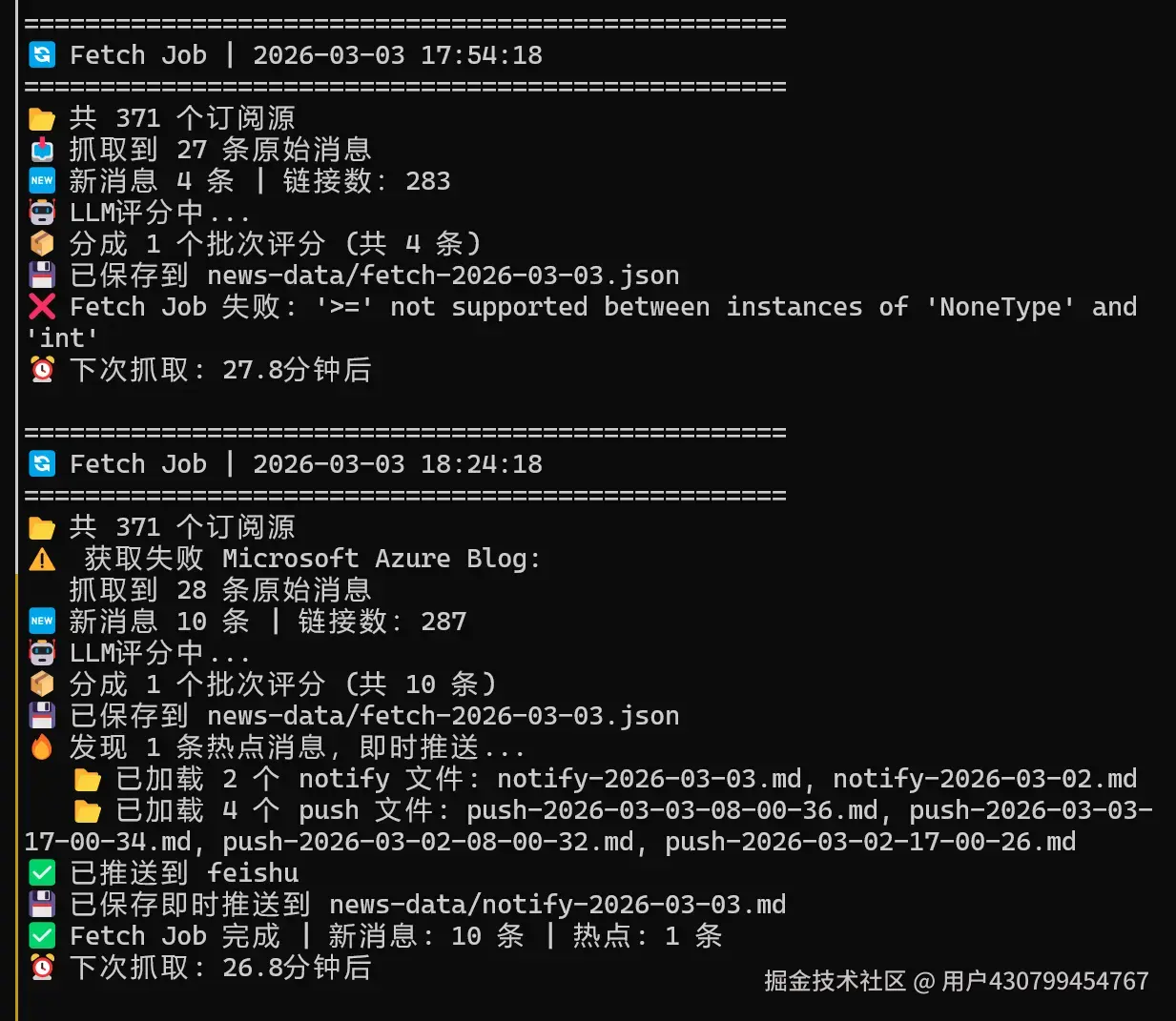
除了及时推送之外,AI Daily 还支持通过cron表达式定时推送过去一段时间的消息。
比如我配置了早八点和晚上5点,config里面这样配置的
"push_cron": ["0 8 * * *", "0 17 * * *"],
飞书里面早上八点和晚上五点就会给我准时推送日报,我截图如下。 排版,措辞可能欠佳,不过整个雏形还是很不错的。
细心的朋友会发现,以上截图中有些新闻前面带"持续跟踪"的标记,比如claude,openai和美国正府之间的矛盾, Qwen3.5小模型发布之后生态链的集成等,这是因为系统判断这一类消息虽然已经推送过,但是又有新的进展,它也会持续跟踪报道。所以 AI Daily 的定位不是一个AI新闻的总结者,而是 AI 行业的观察者。
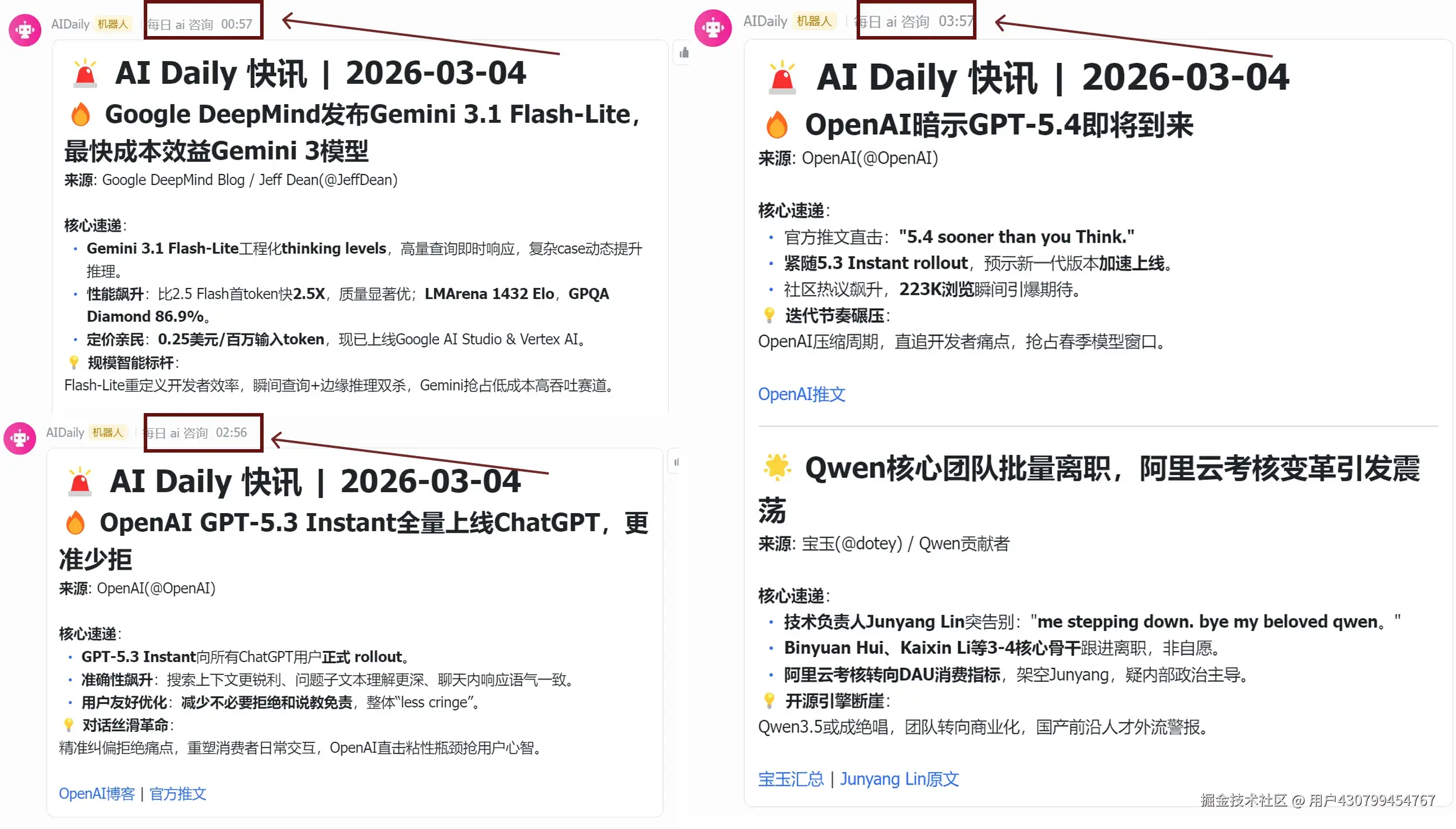
(3.3 没写完,3.4接着写) 再贴几张3.4夜里发生的事情(即时推送):
3.4晨报:
可以看出今天早上你们能看到的ai领域的热点信息都在,Gemini 3.1 Flash-Lite和Gpt-5.3 Instant的发布,Gpt-5.4的上线信息以及Qwen 3.5 团队的离职。
以上就是AI Daily所要实现的效果:
其实在写这样一个推送系统之前,我有尝试让Openclaw给我每天定时推送消息。但是我觉得不够及时。于是我用python简单写了一个每半个小时推送一次的脚本,这时候信息量又太多了。经过对比总结之后,我把及时和汇总结合到一起,设计了这样一个系统。
AI Daily的数据基于rss订阅源。 RSS (Really Simple Syndication)是一种很古老的阅读互联网内容的方式了,他是一种内容协议。网站发布内容时,会生成一个 XML 文件(RSS 种子),包含文章标题、链接、摘要、发布时间等信息。
AI 热点追踪使用 RSS有很多好处:
比如你要爬一个新闻网站的数据,直接的方式是要请求首页内容,解析新闻列表,然后分别请求每篇文章的内容,再去解析文章标题,发布时间,文本内容等等。遇到反爬严重的还会遇到验证码拦截。
而RSS的开放性允许程序不需要做复杂的鉴权验证,只需要简单请求网络数据就可以。结构化则填平了各个平台间的内容格式差异,任何平台的媒体内容都会按照RSS统一的内容协议展现出来,所以方便程序大批量解析。每一个rss订阅源卡其实就是一个链接,所以可以很方便地添加/移除订阅源。
这也是 AI Daily 选择RSS源的原因。
这里我要特别致谢 ginobefun/BestBlogs ,本项目中的RSS 订阅源即从这里整理来的。原始数据包含约 420 个 AI 领域优质信息源,经过配置过滤之后真正使用的有371个。
用户也可自行配置 RSS 源文件 可参考后文内容。
当然RSS数据源也不是一劳永逸的。首先得有源. 如果网站本身不提供这个协议,那么就不能抓取到了。不过不用担心,一方面大厂得技术博客比如OpenAI,Google一般都会提供RSS订阅(但是deepseek官网居然没有,甚至没有博客页面)。即便不提供的,比如微信公众号和X,也有其它二手的办法可以得到。
确定好数据源格式之后,接下来就是程序结构。如下图。
为了实现即时推送+定时汇总,我设计了两个循环:
这里面LLM评分相当于是个人对新闻关注度的一个反映,我们希望看到哪一类新闻,就告诉AI让哪一类加分. 所以这个系统可以应用在任何的热点追踪上面。
请根据以下标准为每条信息打分(0-100):
- 【90-100分】首发重大新闻、里程碑级发布。
*例子:Google官方宣布Nano Banana 2发布;OpenAI官方宣布新模型;Anthropic拒绝美国防部合同(首发报道)。*
- 【80-89分】重要技术进展、知名大佬的核心观点、深度长文。
*例子:某知名开发者开源了一个能让性能提升50%的框架;Jeff Dean对某项新技术的深度解析长推文。*
- 【70-79分】实用工具更新、有价值的教程、行业数据报告。
*例子:Cursor新增了某个小功能;某博主分享的Claude Code 45个实用技巧。*
- 【60-69分】二手信息、一般性新闻、小道消息。
*例子:某媒体转发了Google发布的推文(非首发);未经验证的传言。*
- 【<60分】低价值/局部内容:纯情绪宣泄、无营养的评价、广告、日常闲聊、KOL个人生活动态、硬广软文、无营养的二手评价。
*例子:“Nano Banana 2太牛了!”(无具体测试数据);“Anthropic真硬气”(纯情绪);“快来买我的课”。*
开始coding的那一天,我花了大半天跟Claude code对齐技术方案。让它动工,它几分钟就写完了初版。当天晚上修修补补整个流程就能跑起来了。
但是我看着手机里的内容,有一丝苦恼。因为这个AI系统有点呆:
如果要让AI Daily 好用,就必须解决上面的问题,让它有记忆,懂得连结,能从极度碎片化、充满个人情绪与主观评价的信息里面把握其中的行业动态,形成主次分明、结构清晰、有洞察力的专业内容。
但是我又不想让整个系统太过笨重,不要专业的庞大的数据库,不要复杂的向量搜索,要轻量,简单。
所以我设计了一个简易存储的上下文系统:3大类型文件,7天数据缓存,选择性上下文注入
3大类型文件
| 字段 | 说明 |
|---|---|
title | 内容标题 |
link | 原始链接 |
published | 发布时间 |
source | 来源(T@witter 账号或博客名) |
content | Markdown 格式的正文内容 |
tags | LLM 识别的标签 |
score | LLM 评分(0-100) |
summary | LLM 生成的中文摘要 |
fetched_at | 抓取时间 |
7天数据缓存
所有数据最多保留7天。每天过零点后半小时内自动清理。
上下文注入
大模型其实没有记忆。硬要说有,那也就在训练完成的那一刻定格了。我们现在所谈论的Agent记忆系统其实是注入哪些上下文的问题。所以为了让大模型对最近发生的新闻事件有所了解,我们就需要把之前的数据喂给它。
如果单纯地把近七天地数据都给它,似乎有些鲁莽了。一方面担心上下文窗口会超,另一方面token是需要花钱的。我钱不多,我要花小钱办大事。
下述表格展示了每一次推送的上下文参考周期。针对即时推送,会参考过去两天内的notify文件和push文件,这里只关注高分重磅消息和每日的汇总消息,并且事件跨度不需要太大。 而定时汇总,会参考两天内的fetch文件和5天内的push文件,这里不关注即时推送是推送过,只专注于对过去一段时间内的信息熔炼、重组成一篇结构极度清晰、主次分明、洞察深刻的每日精选。
| fetch文件 | notify文件 | push文件 | |
|---|---|---|---|
| 即时推送 | - | 2天 | 2天 |
| 定时汇总 | 2天 | - | 5天 |
这里面还有很多小细节。比如fetch文件信息零碎,条目众多,可以先过滤以下。比如最小得分不小于60分。文章属性只保留部分属性。fetch文件还会按照过去已经参考过和未参考过进行划分。
以上修改完再优化一下提示词,推送的消息就好看多了。比如3.4最新的上午定时推送,有Gemini 3.1 Flash的发布, Qwen 核心团队离职(持续跟踪,跟之前的Qwen3.5模型发布有联系),OpenAI GPT-5.3 Instant发布. 看着还不错吧。
AI Daily采用python开发,依赖很轻量,配置非常简单,代码加起来只有一千多行。
除了python环境,还需要Openai接口兼容的大模型api,配置好baseurl,apikey,modelid等。
另外就是手机端的通知接口,目前支持飞书和Discord。
你还可以直接把AI Daily Github 仓库 直接发给你的Claude Code或者openclaw让ai自动帮你配置,省事!
拉取代码:
git clone git@github.com:YeeKal/ai-daily.git
python -m venv .venv # 见仁见智
source .venv/bin/activate # Linux/Mac
# 或 .venvScriptsactivate # Windows
pip install -r requirements.txt
在项目根目录创建 .env 文件,添加以下配置:
# LLM API( OpenAI API 兼容接口,变量名随便起,后续在config里面配置变量名)
OPENROUTER_API_KEY=your_api_key_here
# 飞书 Webhook(飞书群机器人的发送消息接口,下文有获取教程)
FEISHU_WEBHOOK_URL=your_feishu_webhook_url_here
# Or Discord Webhook
# DISCORD_WEBHOOK_URL=your_webhook_url_here
在 config.json 中修改 llm 和 push
{
"llm": {
"provider": "<whatever>", # 随便七个名字,只是作为标识用
"model": "<model id>", # 模型id
"baseUrl": "<base url>",
"apiKeyName": "OPENROUTER_API_KEY", # 刚才在env里面配置的llm api 变量名
},
"push": {
"feishu": {
"enabled": true, # 开启飞书通知
"apiKeyName": "FEISHU_WEBHOOK_URL"
}
},
}
python -m src.main
Done! 你的ai推送系统就开始运行了,运行成功会出现类似以下打印
首次运行会自动创建 news-data/ 目录并开始抓取数据。
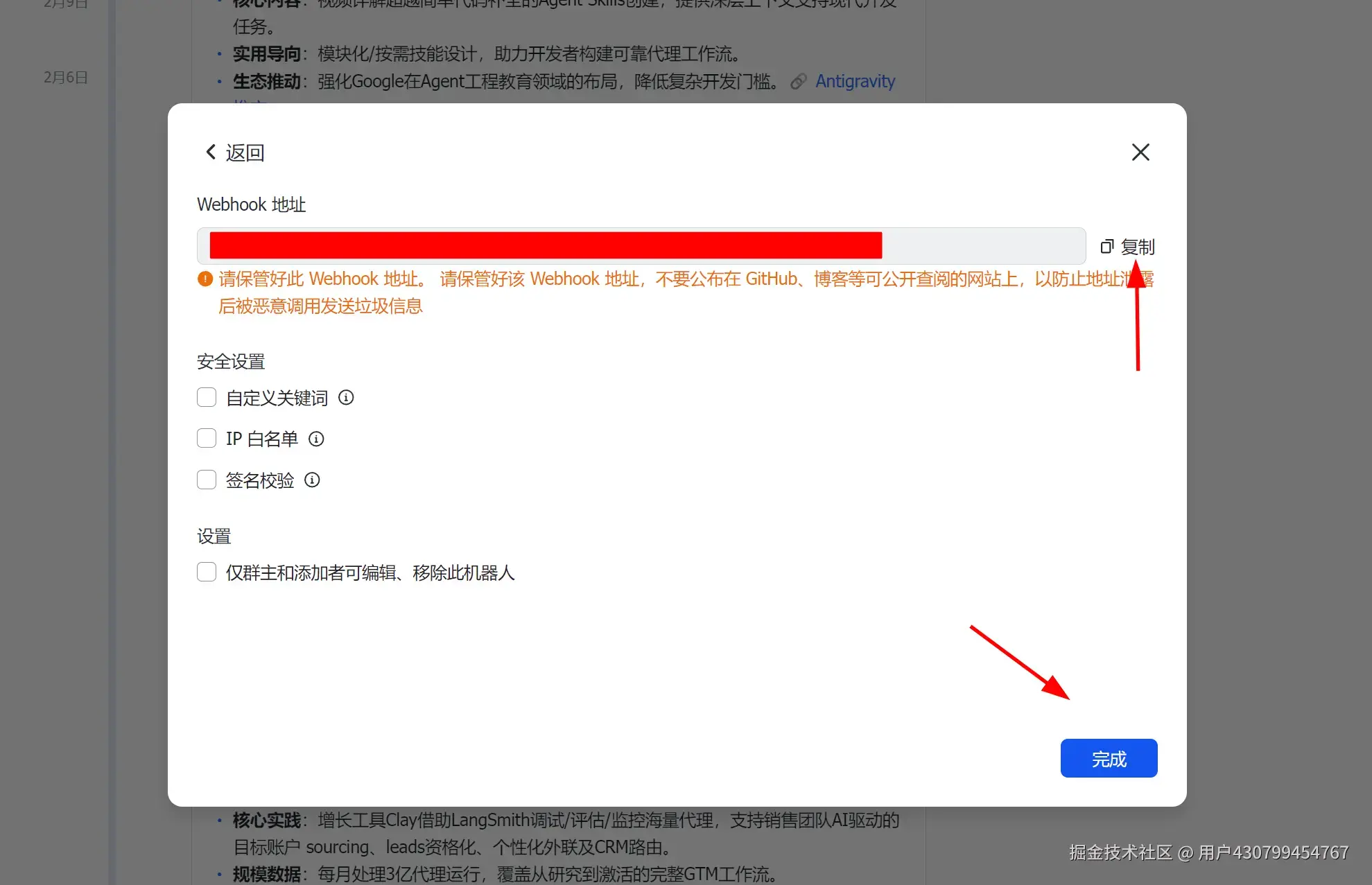
获取飞书群机器人 Webhook
获取 Discord Webhook:
AI Daily 支持高度定制化,参数,模型乃至信息源。详细可参考项目地址: github.com/YeeKal/ai-d…
完整的配置文件结构如下,每个字段都有详细说明:
{
// 内容过滤
"filter": {
"min_score": 60, // 最低评分阈值,低于此分不推送
"hot_threshold": 90, // 热点阈值,达到立即即时推送
"context_days": 3, // 汇总时参考的历史天数
"keep_days": 7, // 数据保留天数
"push_context_days": 5, // 汇总推送去重的上下文有效天数
"no_content_marker": "[NO_NEW_CONTENT]" // LLM返回的无内容标记,用于判断是否跳过推送
},
// 调度配置
"schedule": {
"fetch_interval_minutes": 30, // RSS抓取间隔(分钟)
"fetch_lookback_minutes": 120, // RSS冗余缓存时间(分钟),必须大于fetch_interval_minutes,用于防止RSS延迟导致漏读
"push_cron": ["0 8 * * *", "0 17 * * *"], // 定时推送cron表达式
"timezone_hours": 8 // 时区偏移(8=北京时间)
},
// 抓取配置
"fetch": {
"max_workers": 10, // 最大并发数
"timeout": 10 // 单请求超时(秒)
},
// LLM配置
"llm": {
"provider": "openai", // 提供商类型
"model": "x-ai/grok-4.1-fast", // 模型名称
"baseUrl": "https://openrouter.ai/api/v1", // API端点
"apiKeyName": "OPENROUTER_API_KEY", // 环境变量名
"max_prompt_chars": 128000, // 单次prompt最大字符数
"max_concurrent_batches": 3, // 最大并发批次数
"prompts": { // prompt文件路径
"score": "prompts/score.txt",
"score_batch": "prompts/score_batch.txt",
"immediate_push": "prompts/immediate_push.txt",
"digest": "prompts/digest.txt"
}
},
// 推送配置
"push": {
"discord": {
"enabled": true, // 是否启用
"apiKeyName": "DISCORD_WEBHOOK_URL" // Webhook环境变量名
},
"feishu": {
"enabled": false,
"apiKeyName": "FEISHU_WEBHOOK_URL"
}
},
// 订阅源管理
"sources": {
"base_opml": "resources/rss.opml", // 基础OPML文件,包含400+预设源
"add": [ // 自定义添加的RSS源
{
"title": "OpenAI News",
"xmlUrl": "https://openai.com/news/rss.xml",
"category": "AI"
}
],
"block": [ // 手动屏蔽的源,精确匹配xmlUrl
{
"title": "Google Developers Blog",
"xmlUrl": "https://developers.googleblog.com/feeds/posts/default"
}
],
"block_domains": ["*.substack.com", "*.you@tube.com"] // 域名屏蔽,支持通配符
},
}
RSS 订阅源文件位于 resources/rss.opml,目前包含约 420 个订阅源。初始整理自 ginobefun/BestBlogs。
用户可自行配置 RSS 源文件,只需遵循 OPML 格,在 config.json 的 sources.base_opml 修改文件路径即可。 同时用户可修改 sources.add或者 sources.block以在不破换OMPL文件的前提下对rss源进行增加或者删除。格式示例:
"sources": {
"base_opml": "resources/rss.opml",
"add": [ // 添加新的源
{
"title": "OpenAI News",
"xmlUrl": "https://openai.com/news/rss.xml",
"category": "AI"
},
{
"title": "Chrome for Developers",
"xmlUrl": "https://developer.chrome.com/static/blog/feed.xml",
"category": "Chrome"
}
],
"block": [
{
"title": "Google Developers Blog",
"xmlUrl": "https://developers.googleblog.com/feeds/posts/default"
},
{
"title": "Microsoft for Developers",
"xmlUrl": "https://devblogs.microsoft.com/landing"
},
{
"title": "ElevenLabs Blog",
"xmlUrl": "https://api.bestblogs.dev/feed/elevenLabsBlog"
}
],
"block_domains": ["*.substack.com", "*.you@tube.com"]
}
src/push/ 目录下创建新文件,继承 PushPlatform 基类validate_config() 和 send() 方法src/push/__init__.py 中注册这个系统还不完美,我能在每次的推送里面感受到措辞还有待进步,但是我现在已经再用了。整个系统框架已经跑起来了,后面可能有很多细节可以完善,或者特性可以增加。
比如这些:
另外我分享一个有意思的bug,不然大家可能无法理解配置里面下面这两个参数的区别
// 调度配置
"schedule": {
"fetch_interval_minutes": 30, // RSS抓取间隔(分钟)
"fetch_lookback_minutes": 120, // RSS冗余缓存时间(分钟),必须大于fetch_interval_minutes,用于防止RSS延迟导致漏读
}
这个系统一开始只有 fetch_interval_minutes=30 这一个参数,意思是每30min抓取一次,抓取过去30min内更新的内容。这逻辑听上去毫无破绽。
但是我还是察觉到一丝异样。抓取的数据量太少了!每天只有八十条。
我提到我在写这个之前已经写过一个简单的脚本,当时抓取过去一天的数据大概有3-4百条。
我有想过是不是每天事件的正常波动导致的差异。不过我还是用正常的思维考虑了一下:这应该是个bug.
我突然想到一个可能: RSS源更新延迟。
想想这样一种情况:假设某条消息12:00 发布,而RSS源12:45才收录。当我的程序在12:25访问源的时候,检测不到这条消息。过了半个小时,当我的程序在12:55访问源的时候,能检测到这条消息,但是认为发布时间超过30min就把它过滤了。所以罪魁祸首就是:
后面验证了一下,所以又加了一个参数 fetch_lookback_minutes=120,这个参数的含义是假设RSS源的更新延迟最大不超过两个小时。
最后的逻辑变成了:每30min抓取一次,抓取过去(30min+120min)内更新的内容。然后抓取的信息条数就正常了。
AI 热点跟踪的工具已经很多了,不过多我一个也不算多。
搭建这个系统的初衷很简单:。我想主动获取信息,而不是被信息流被动投喂。我要及时被通知到信息,而不是等待我去刷手机。
RSS + LLM 的组合让这成为可能:前者保证了信息来源的开放和结构化,后者让机器理解内容成为可能。整个系统没有复杂的数据库,没有向量检索,只有一千多行 Python 代码和几个 JSON 配置文件。
最后分享一下这几天的 token 消耗:
我用的是 openrouter 里的 Grok 4.1 Fast,就是便宜,输入每百万 0.2。在这个任务里每天的 api 费用不到 0.2$,四舍五入差不多一天一块钱。
如果你对这个项目感兴趣,欢迎 Star。

