




阿里本地通
101.9MB · 2026-02-28

上篇内容 大模型训练全流程实战指南工具篇(六)——OCR工具实战指南(以DeepSeek-OCR-2为例) 笔者分享了如何利用DeepSeek-OCR-2将各类文档统一转换为标准的Markdown格式。从本期开始,笔者将聚焦于如何对这些已格式化的文档进行进一步处理,最终构建出可供大模型训练的高质量数据集。
当前市面上已涌现出如 LLaMAFactory、Unsloth 等成熟的大模型训练训练工具,极大降低了大模型训练的门槛。对于广大中小企业和科研人员而言,数据集准备阶段已然成为整个训练流程中最为棘手的一环。数据的质量直接决定模型的最终效果,而构建高质量的领域数据集往往面临着清洗流程复杂、人工标注成本高等多重挑战。
考虑到本系列教程的目标受众同样包括大模型训练的初学者,如何清晰、直观地呈现数据处理的全流程就显得至关重要。笔者这里直接抛出代码和抽象讲解,容易让大家感到困惑。因此,笔者决定采用当前流程完整、功能强大的 EasyDataset 工具,以实际操作为主线,带大家逐步走通数据集构建的每一个环节。本期内容作为 EasyDataset 专题的开篇,将首先带您完成工具的安装,并快速掌握其基本使用方法,为后续深入实践打下基础。
EasyDataset 是一款专为大模型微调设计的数据集构建工具,旨在解决高质量领域数据集准备过程中的诸多痛点。它实现了从文献解析到数据集构造、标注、导出、评估的全流程闭环,贯穿「文献处理 — 问题生成 — 答案构建 — 标签管理 — 数据导出」的完整链路。
其核心特性主要体现在以下几个方面:
<think></think> 格式)的答案,增强数据质量。除数据处理能力外,EasyDataset 还以项目制为核心单元,集成了一系列提升用户体验的功能:
EasyDataset 的安装部署非常简便,官方推荐直接使用客户端版本,它支持 Windows、macOS 和 Linux 主流操作系统。您可以根据自己的系统环境,前往 GitHub Releases 页面 下载对应的安装包。本文以 Windows 系统为例进行演示。
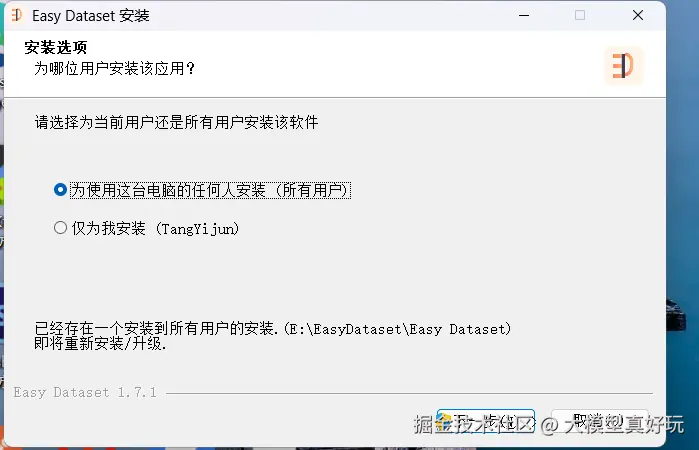
下载完成后,双击 .exe 安装程序,按照提示一路点击“下一步”即可完成安装。安装界面如下图所示:
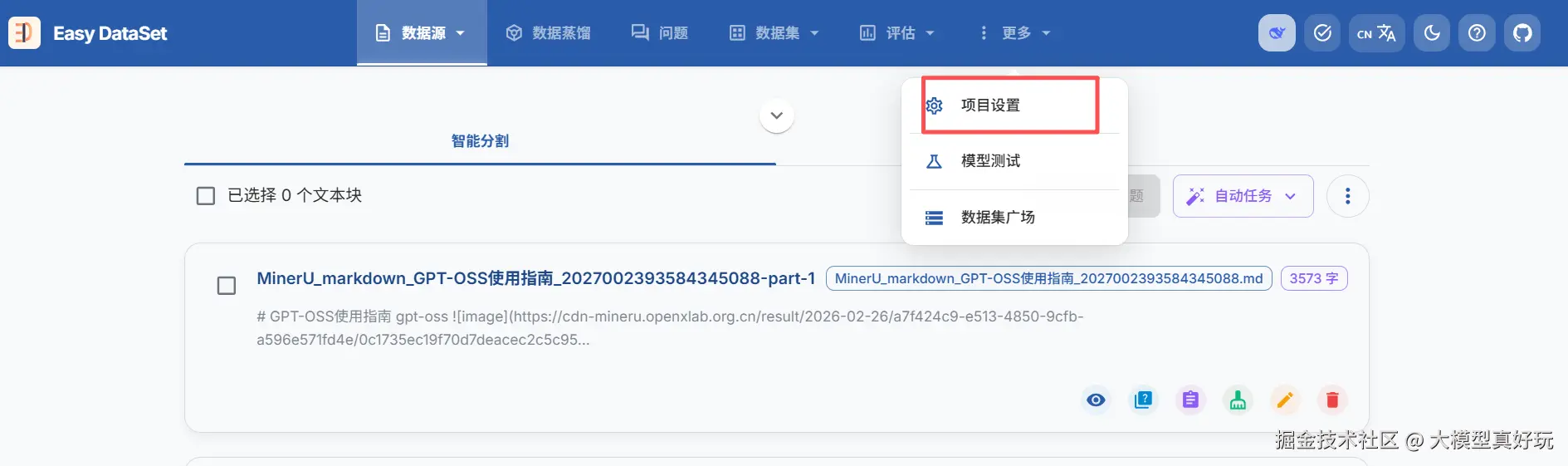
EasyDataset 以项目(Project)为最小处理单元。每个项目拥有独立的配置(包括数据集生成任务配置、模型配置等),可用于处理一批文献,并集中管理基于这些文献生成的所有问答对和数据集。
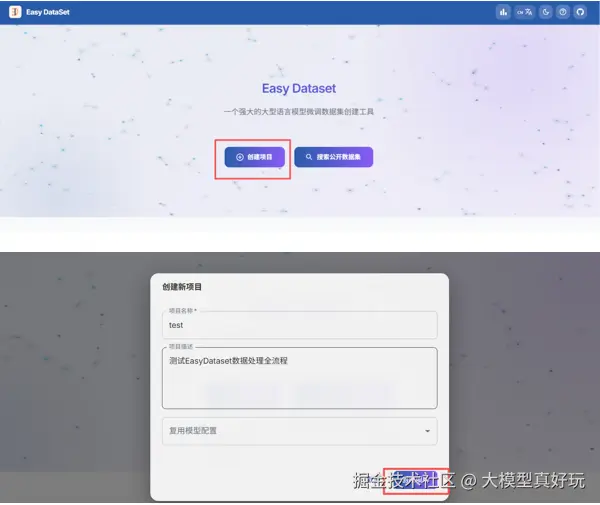
EasyDataset以项目为最小处理单元,首先在EasyDataset中创建一个项目,这里取名为test, 一个项目下有一份独立的配置(包括数据集生成任务配置、模型配置等等),可以处理一批文献并且管理基于这批文献生成的所有问题和数据集。
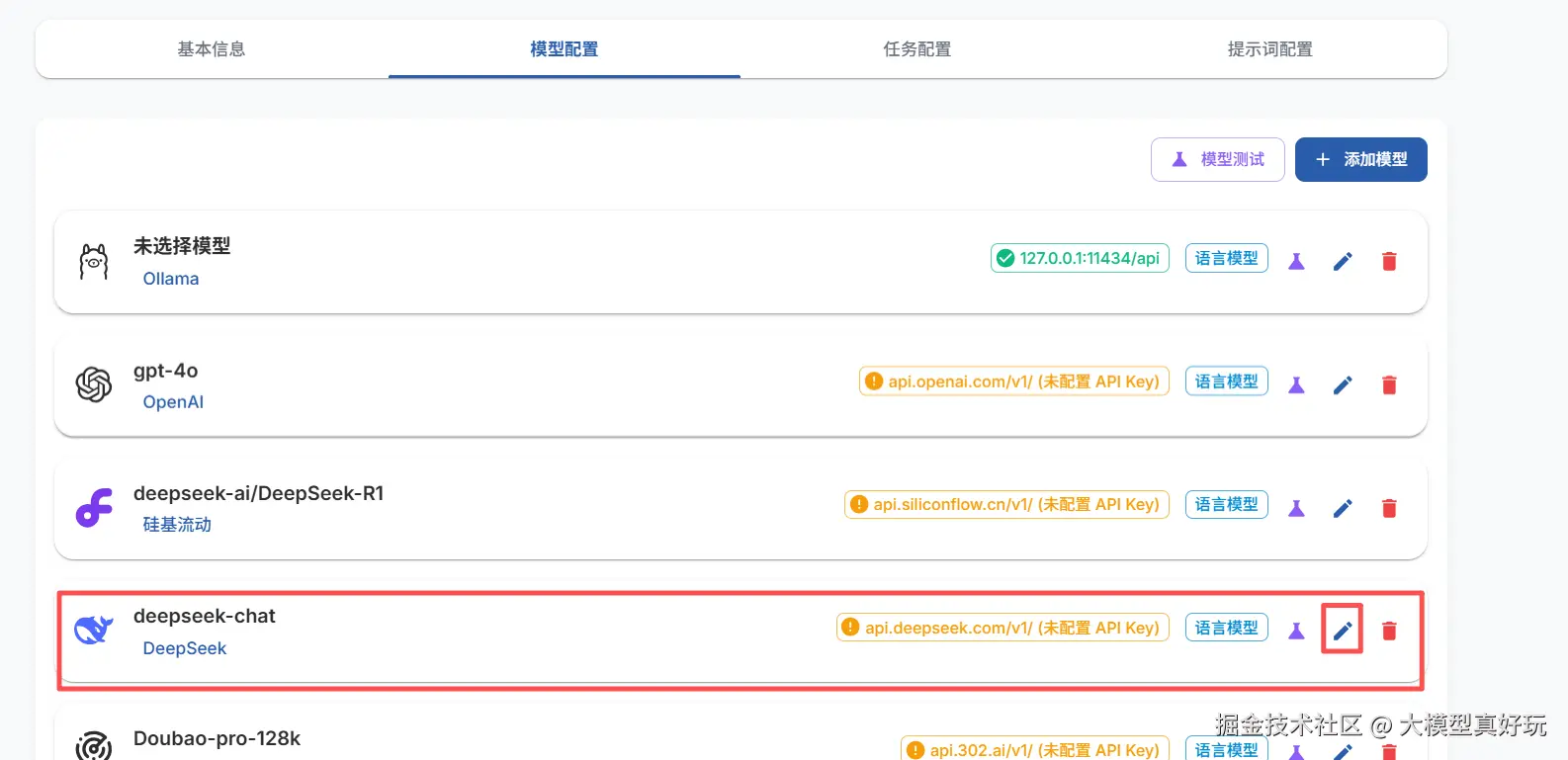
test配置模型: 项目创建完成后,需要配置大模型。在整个数据处理流程中,无论是文本打标签,还是生成问答对,都离不开大模型的参与——它在这里充当“万能 API”的角色,负责各类数据智能处理任务。用户可根据实际情况选择模型接入方式:
为方便演示,笔者选择接入 DeepSeek API,配置界面如下图所示。
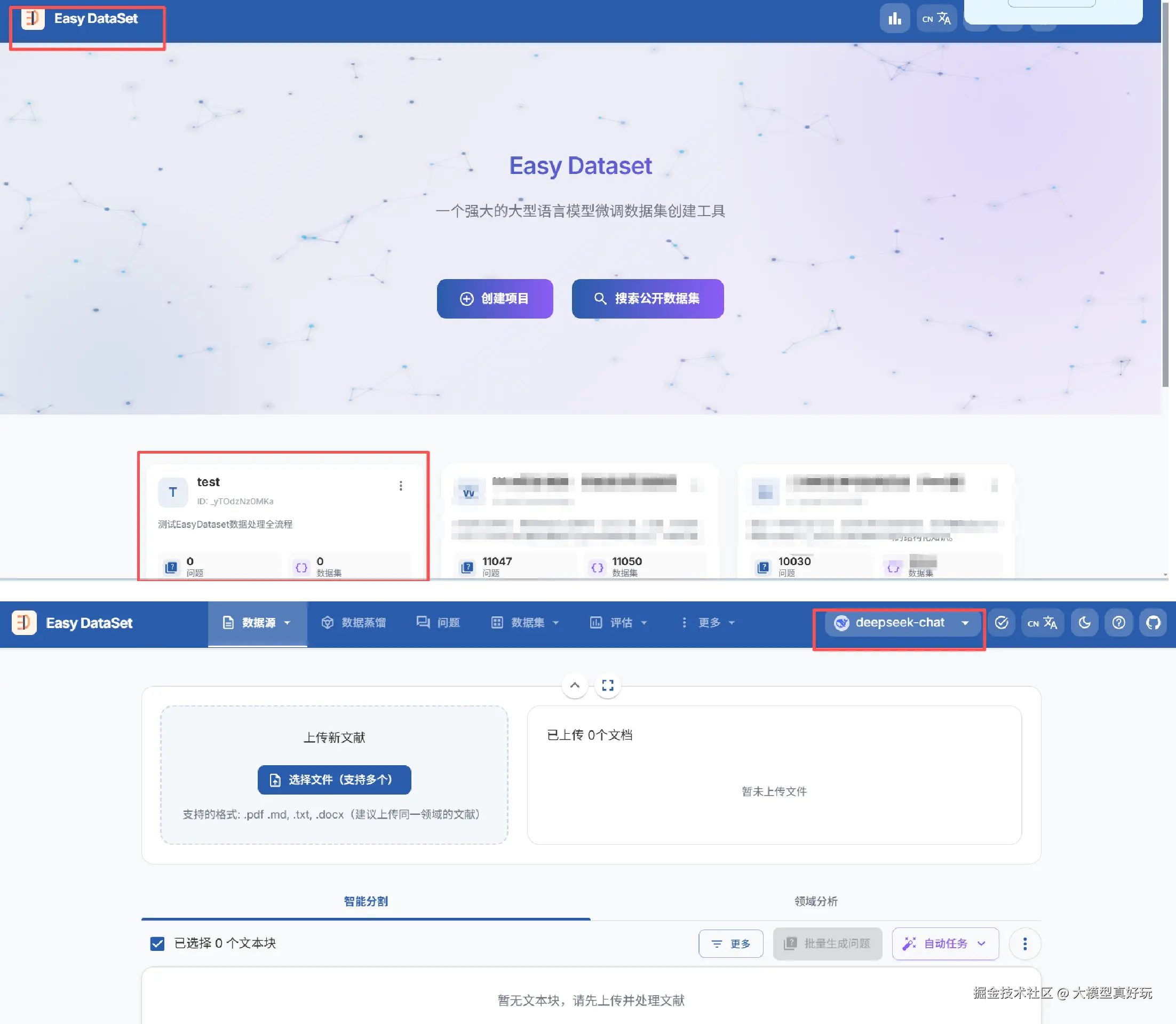
test 项目。在项目界面右上角选择已配置好的模型,即可开始数据处理操作。EasyDataset 支持 Markdown、PDF、DOCX、TXT 四种格式的文献上传。对于纯文本格式,系统可直接读取处理;而对于 PDF 格式,EasyDataset 提供了三种解析方式:基础解析、MinerU(上海人工智能实验室开发的 OCR 模型)解析,以及自定义视觉模型解析。
根据笔者的实际使用经验,单纯依赖 EasyDataset 内置的文件解析功能,处理效果往往不够理想。建议先使用专门的 OCR 模型或工具将各类文档统一转换为 Markdown 格式,再导入 EasyDataset 进行后续处理。
OCR 工具的选择需根据具体应用场景来定:
关于 OCR 技术的更多细节与选型建议,可参考笔者的另一篇文章:《OCR技术简史:从深度学习到大模型,最强OCR大模型花落谁家》。
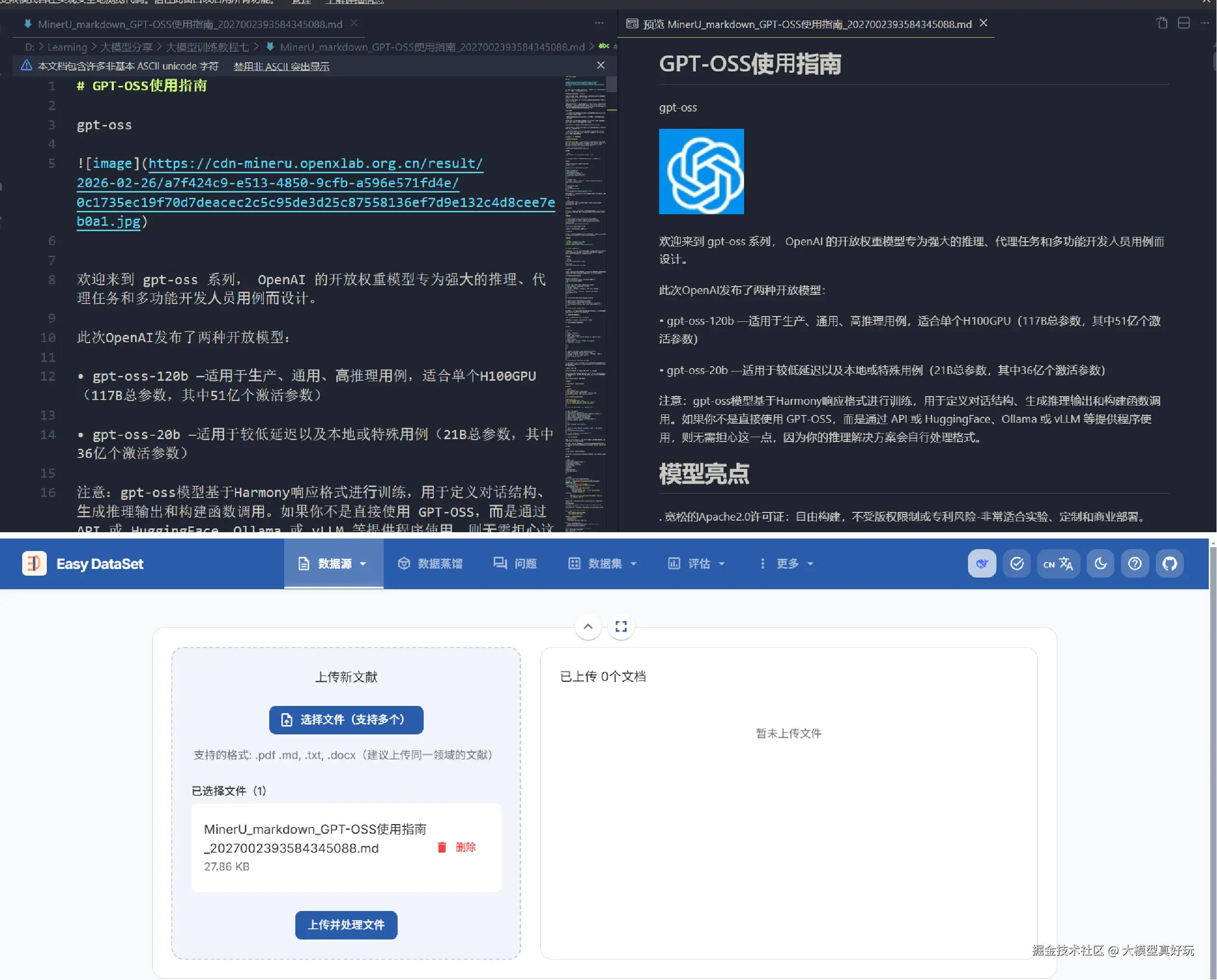
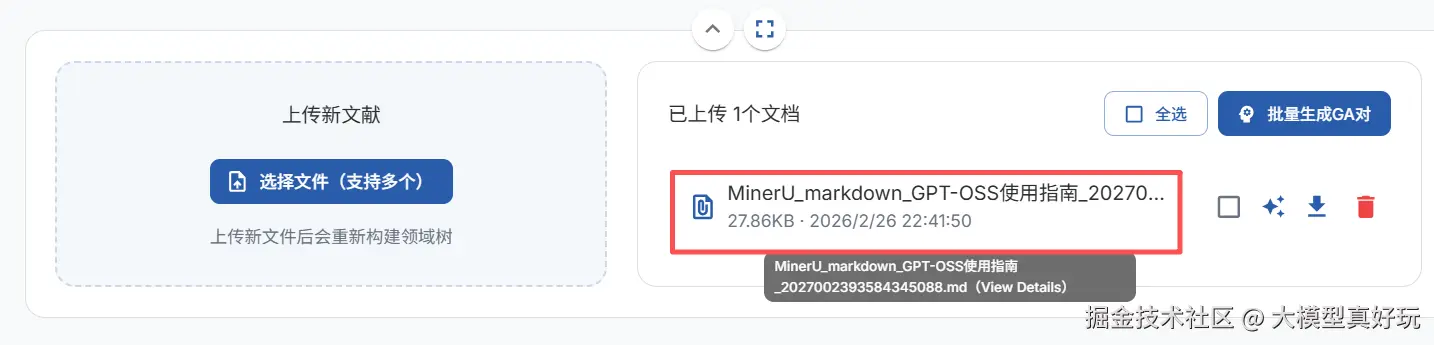
EasyDataset既支持单个文档处理,也支持文档批处理,为方便演示,本文使用一份通过 MinerU 处理好的文档《GPT-OSS使用指南》进行测试。大家可关注笔者同名公众号 「大模型真好玩」,并发送私信 「大模型训练」 免费获取该测试文档。
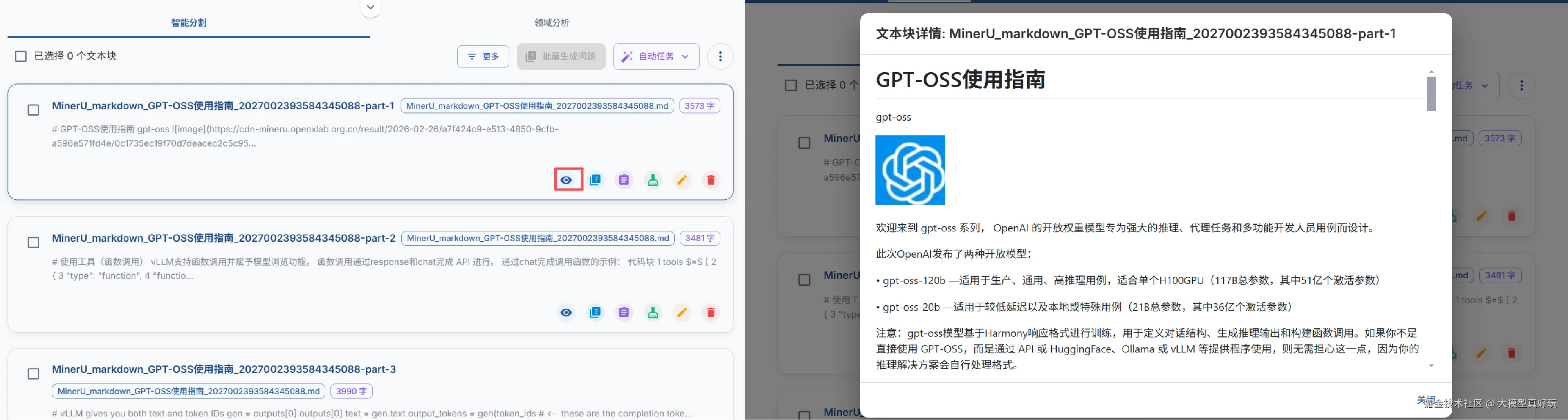
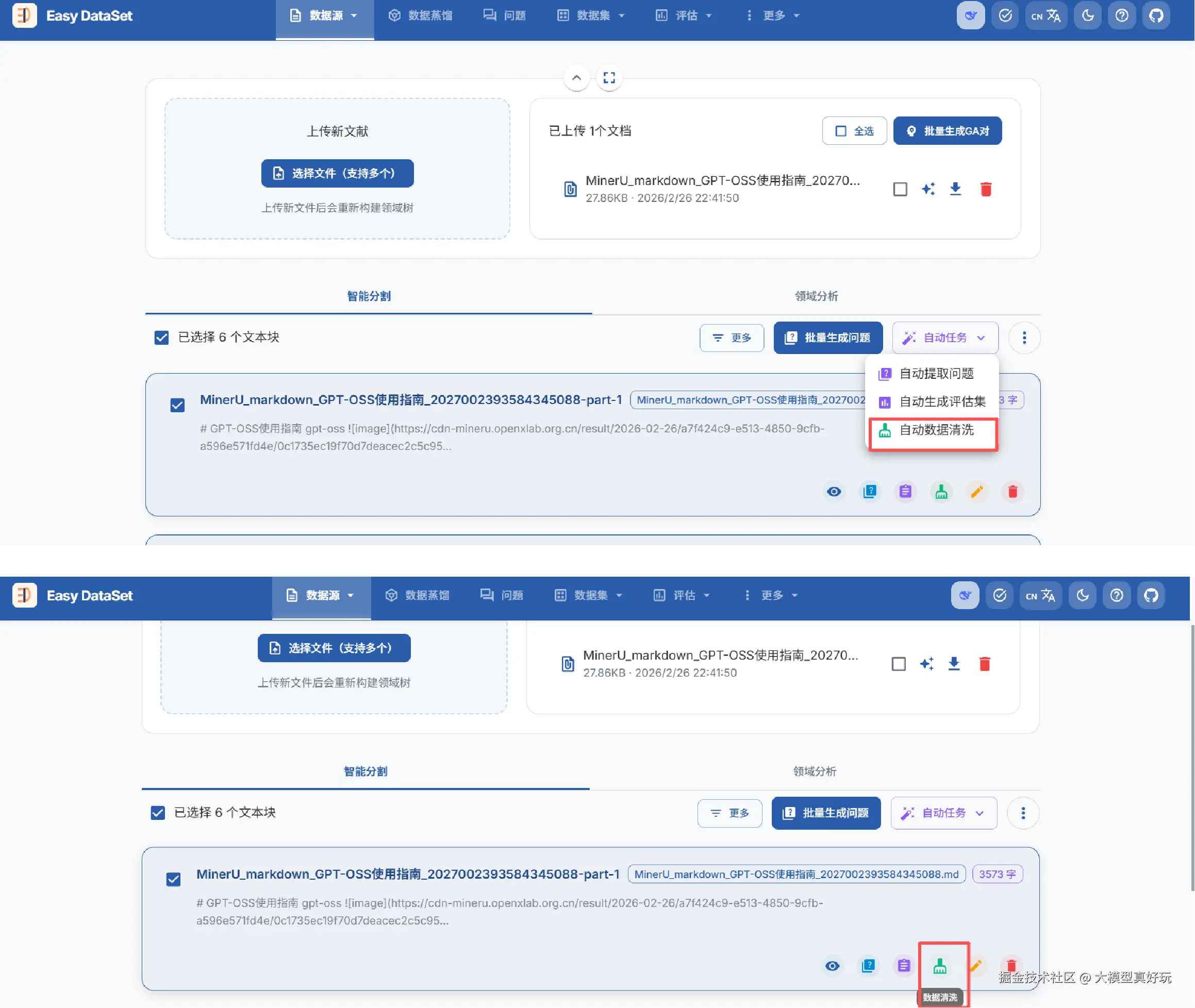
文档上传后,EasyDataset 会自动对文献进行智能分割。用户可以在分割列表中查看拆分后的文本块、每个块的字数以及具体内容,并支持手动修改。
文本分块是将统一格式后的 Markdown 文本转化为高质量数据集的关键步骤。分块的合理与否,直接影响模型预训练效果和后续数据集构建的质量。那么大家这时就有疑问了,为什么不能直接用格式化后的完整文档训练模型呢?
文档分割是数据预处理的核心环节,其主要目的是将长文本拆分为便于处理的短片段,主要基于以下几点考虑:
文本分割是关键一步,但处理不当也会带来问题——例如将同一代码块强行分割,必然造成语义损失。因此,学术界和工业界提出了多种分割算法。
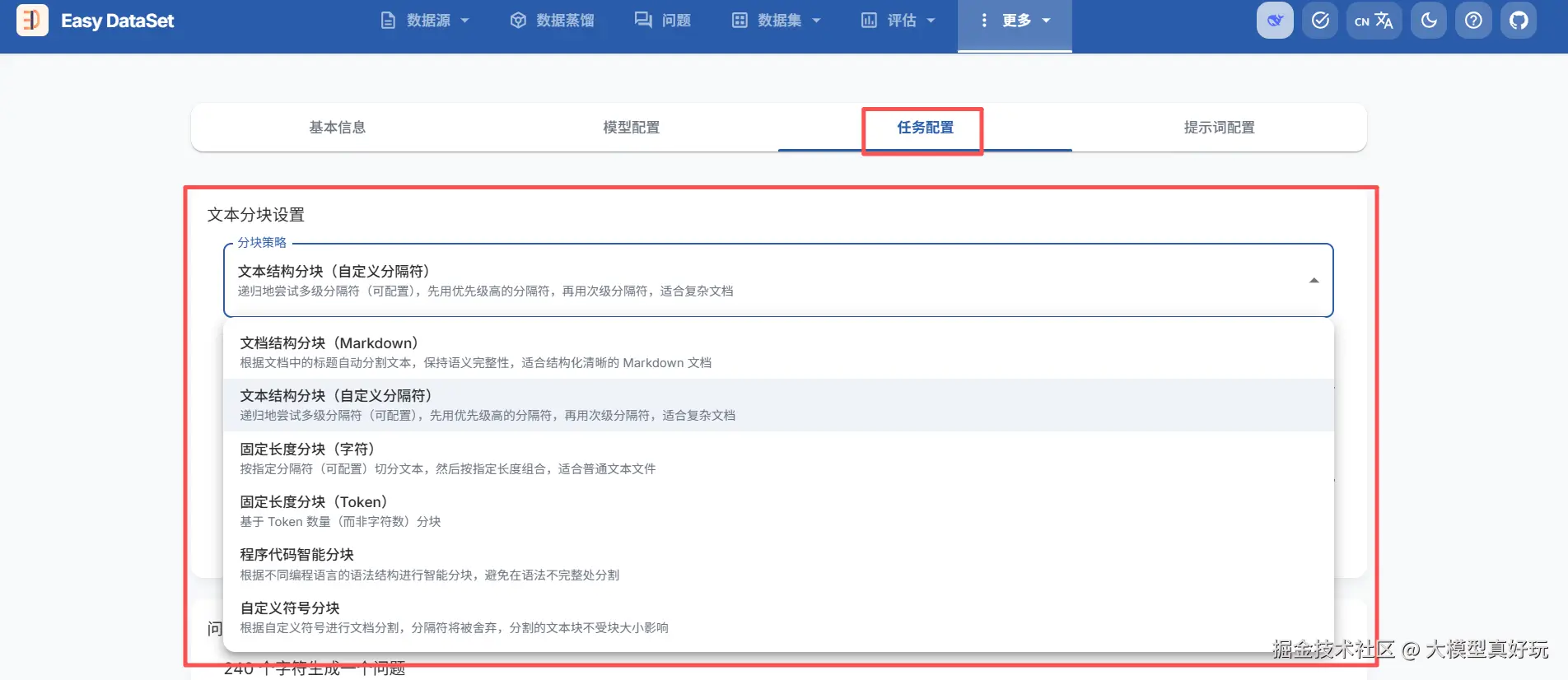
还记得前文提到项目中的任务设置吗?在那里可以看到 EasyDataset 支持的多种文本分割算法。下面笔者将对这几种经典算法进行介绍,帮助大家根据实际场景选择合适的分块策略。
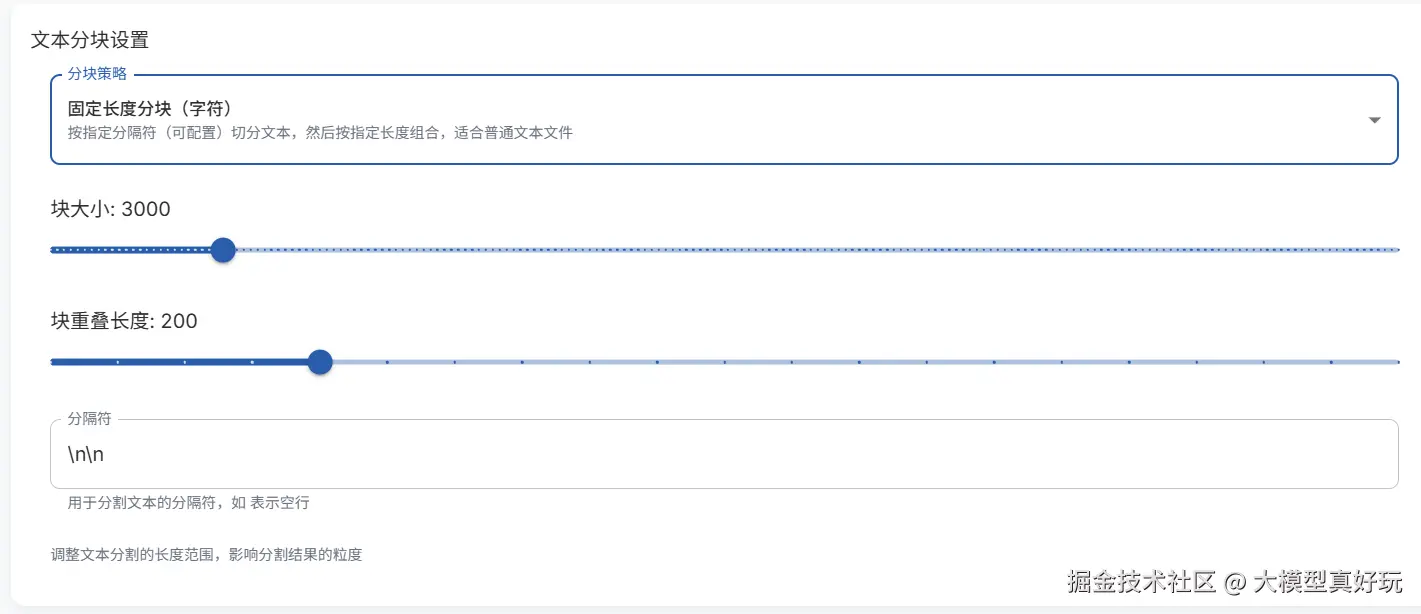
这是最直观的分割方式,即按文档长度(词元数或字符数)进行划分。优点是实现简单、片段长度一致、便于适配不同模型的输入限制。EasyDataset固定长度分割有两种实现方式:
下图展示了基于字符的固定长度分割配置界面,主要包括三个参数:
nn 按段落分割。可根据文本格式调整为 n 或 --- 等。文本天然具有段落、句子、单词等层次结构。递归分块利用这种内在结构,优先保持较大单元(如段落)的完整性;若该单元超出块大小限制,则递归进入下一层次(如句子)继续分割,直至单词级别。
这种方式能较好地保持自然语言的流畅性和语义连贯性。配置时同样可设置最大分块大小和重叠字符数,同时支持自定义多个分隔符:
基于 Markdown 文档结构的分块是目前精度较高、被广泛采用的方式,也是建议将文档统一为 Markdown 格式的重要原因。EasyDataset 默认采用此策略:
#、##、###);当处理包含大量代码的文档时,传统分割方式可能会切断代码逻辑,破坏语法结构。EasyDataset 提供了基于代码语义理解的分割方式,支持按目标编程语言进行智能分块:
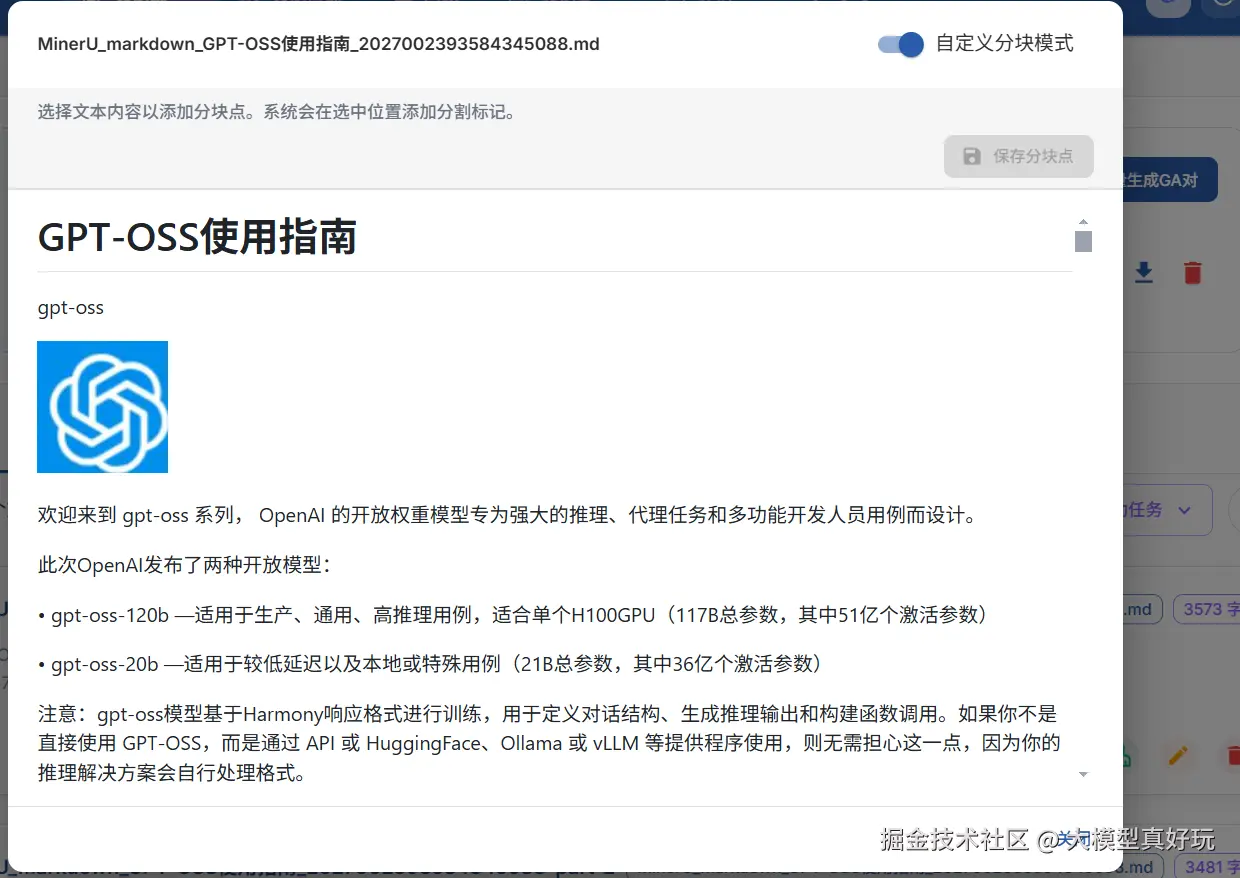
当上述自动分块策略均难以满足需求时,EasyDataset 还提供了可视化自定义分块功能。首先找到目标文献并点击进入预览视图:
打开预览视图后,点击右上角开启自定义分块模式:
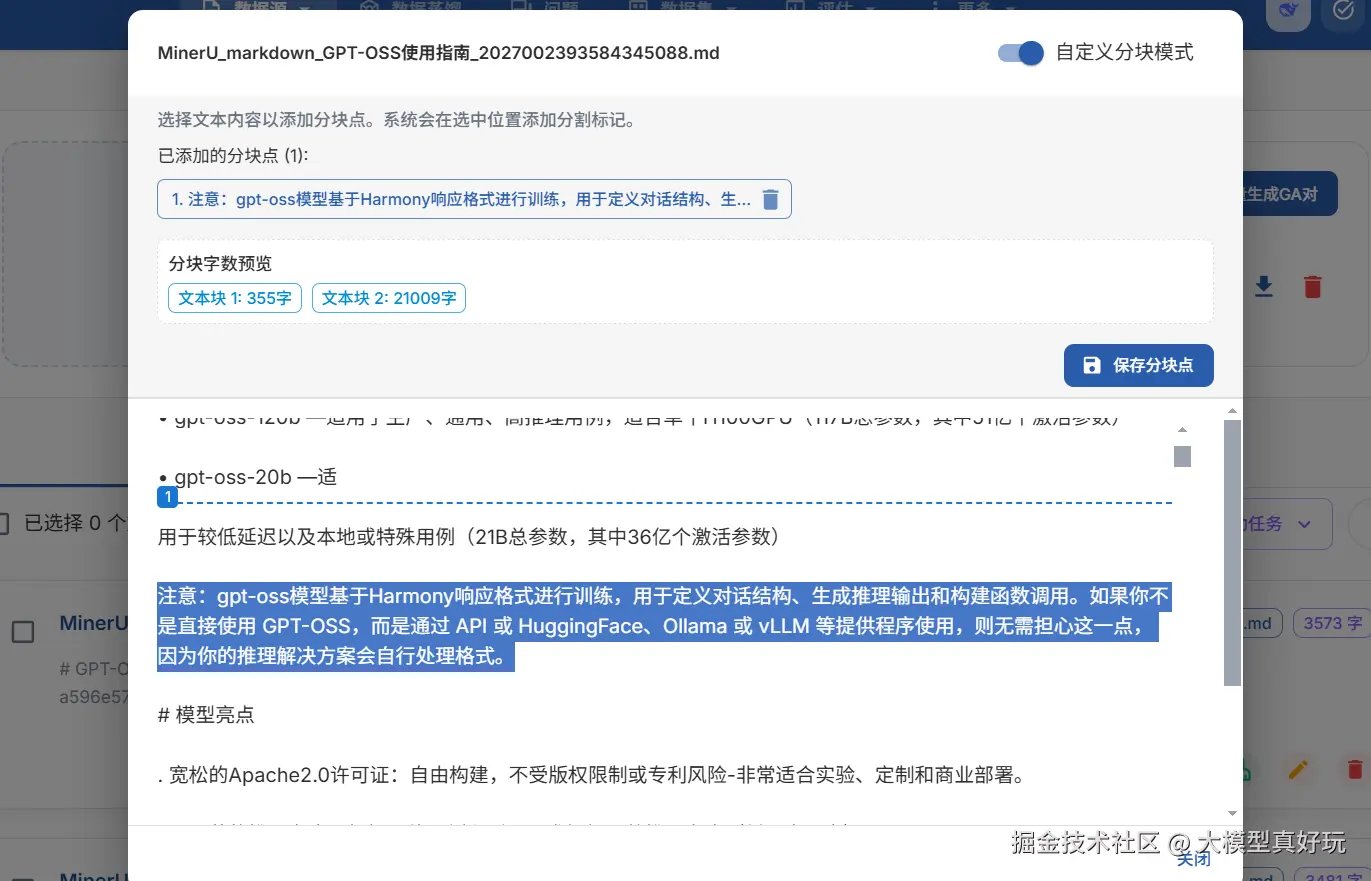
在需要分块的位置选中文本,上方会实时显示当前分块位置、分块数量以及各块字符数。分块完成后点击保存,将完全替换当前文献的历史分块内容:
面对多种分块算法,如何选择最适合自己场景的策略?对于本文适用了《GPT-OSS指南》例子笔者采用了默认的文档结构(Markdown)分块策略,同时笔者还根据实际工作经验,总结了不同算法的适用场景:
| 分块策略 | 适用场景 | 优势 | 注意事项 |
|---|---|---|---|
| 固定长度分块 | 新闻文章、博客帖子等长度较均匀的文本;批处理场景 | 实现简单,速度快,块大小一致 | 可能打断句子或语义单元;需合理设置重叠区避免信息割裂 |
| 文本结构(递归)分块 | 普通文档、报告、一般性技术文档 | 较好保持自然语言流畅性;灵活适应不同粒度 | 计算复杂度略高于固定分块;需合理配置分隔符层级 |
| 文档结构(Markdown)分块 | 结构化良好的文档(技术手册、教程、书籍章节) | 语义完整性强;与文档逻辑结构对齐;推荐首选 | 依赖文档的 Markdown 格式规范性 |
| 代码分块 | 编程文档、代码库、技术教程中的代码示例 | 保持代码语法完整;避免破坏函数、类等逻辑单元 | 需指定编程语言;对混合内容(文字+代码)需配合其他策略 |
| 可视化自定义分块 | 特殊版式文档、对分块有精确控制需求的场景 | 完全人工控制,精度最高 | 耗时较长,适合精细调优阶段 |
总体而言,对于大多数文档处理场景,建议优先尝试文档结构(Markdown)分块或文本结构(递归)分块;当处理代码密集型文档时,选用代码分块;仅在快速原型或对语义要求不高的场景使用固定长度分块;对于有特殊要求的文档,可结合可视化自定义分块进行精细调整。在实际工作中,往往也需要结合待处理不同类别领域的实际数据,通过自定义python处理脚本的方式完成文本分块工作。
文本分块完成后,是否可以直接用于大模型训练?答案是否定的。不同文本段落的质量参差不齐,部分段落可能包含广告、重复内容或无关信息,这些噪声会干扰模型的学习效果。因此,在进入训练环节之前,必须对分块后的数据进行清洗。
对于大规模数据场景,常见的做法是编写 Python 脚本 通过一些规则匹配过滤到无关信息,这种方式效率较高适用于海量数据预处理。 为提高筛选的精确度,也可设计文本清洗提示词,调用本地或云端的大模型对文本块进行自动打标,识别并剔除低质量或无关块。
EasyDataset 内置了数据清洗功能,支持通过大模型对文本块进行更精细的净化处理。用户只需在界面上选择清洗任务,平台便会自动调用配置好的模型,识别并移除不合理的内容,从而提升数据集的整体质量。
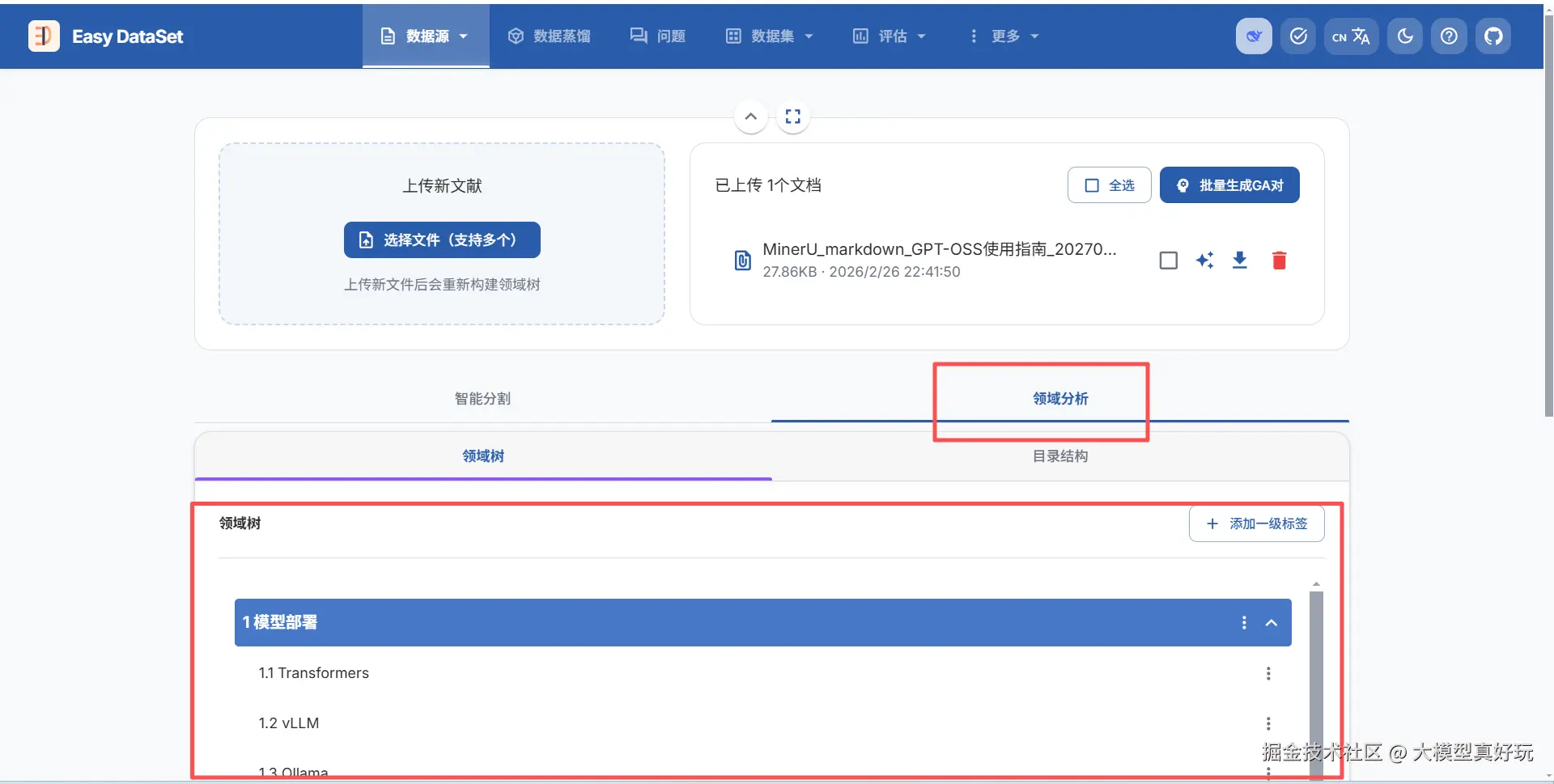
完成分块和清洗后,EasyDataset 会自动调用大模型,基于文献内容构建领域标签树。简单来说,标签树是按层级关系抽象出的文档分类体系,能够为每个文本块赋予所属的垂直领域(如科技、财经、医疗等)。
构建领域标签主要解决两个核心问题:
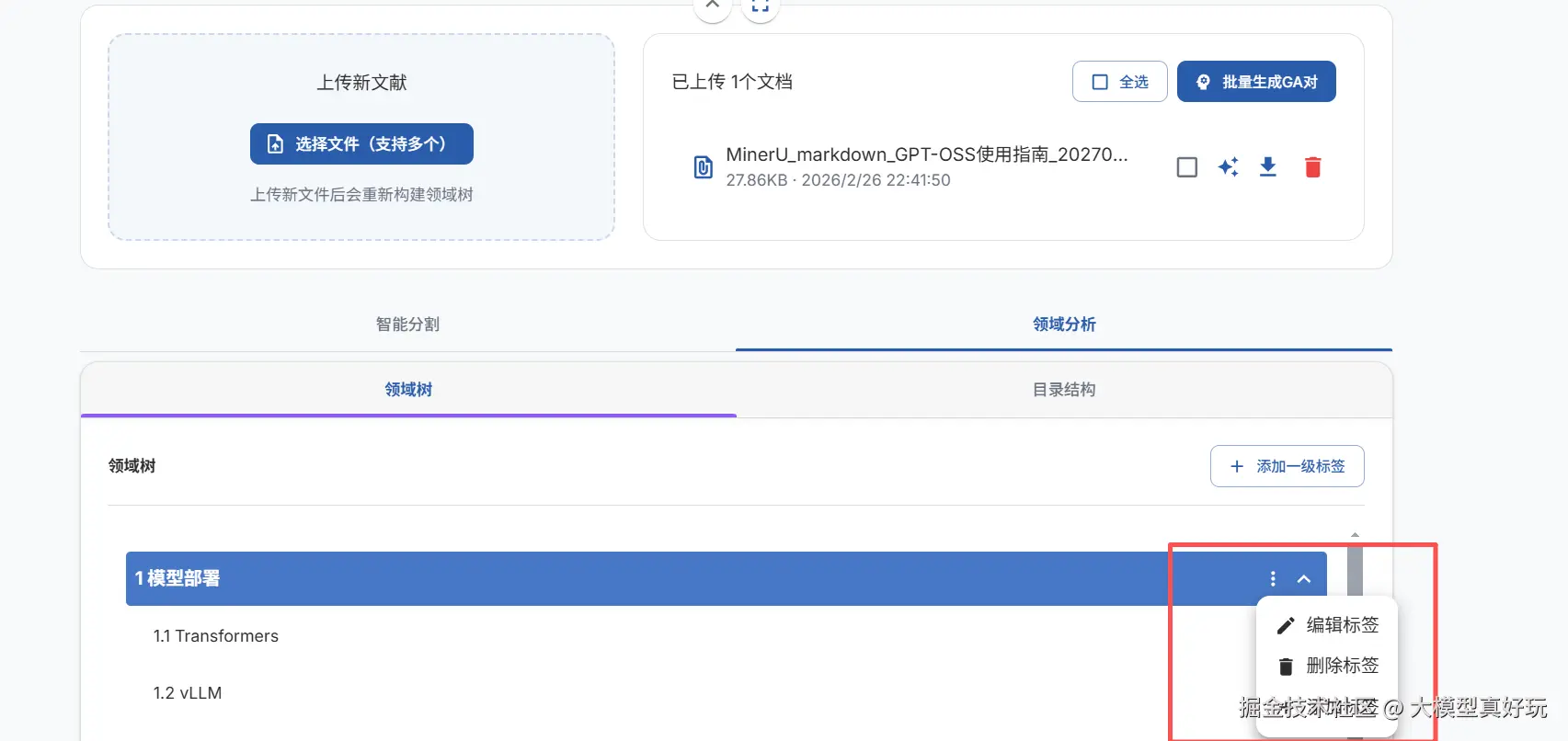
用户可以切换到“领域分析”选项卡,查看 EasyDataset 基于大模型智能生成的领域树以及从文献中提取的原始目录结构。后续生成问答对和数据集的任务中,平台将基于这个领域树进行映射,使每条数据都能关联到具体的领域标签。领域树不仅让每条数据具备全局理解能力,还能有效减少重复数据生成的可能性。
如果觉得大模型自动生成的领域树有不准确或不完善之处,也支持手动添加、修改或删除标签。要生成精确的问答数据集,领域标签的准确性至关重要。
回顾笔者在 《大模型训练全流程实战指南工具篇(五)——大模型训练全流程步骤详解与对应工具推荐》 中介绍的预训练数据格式,可以发现,分块后的文本块正是构成预训练数据集的基本单元。
它们之间的关系可以理解为 “原材料”与“成品” :
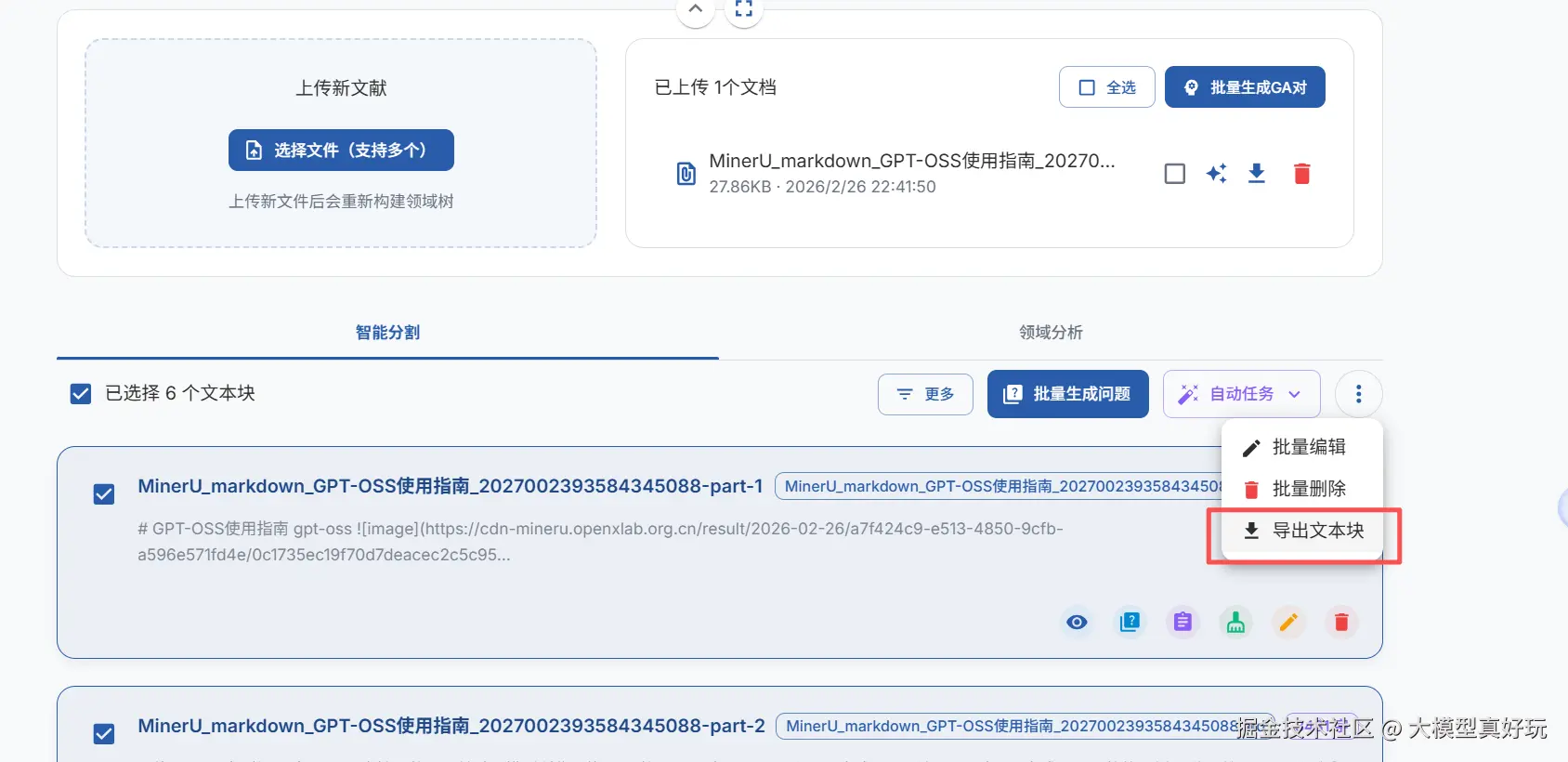
使用 EasyDataset,用户可以批量导出生成的文本块数据集,然后通过脚本进行进一步加工,即可得到高质量的大模型预训练数据。而这些数据,正是大模型知识的最初来源!
本篇内容以EasyDataset为例,系统讲解大模型预训练数据集的构建流程:从安装配置、文本分块(多种策略)、数据清洗到领域标签生成,最终导出预训练数据,为初学者提供从原始文档到高质量数据集的完整实践指南。EasyDataset 不仅能高效生成预训练数据,更强大的功能在于可直接生成高质量的 SFT 微调数据集。下一期笔者将继续深入探索 EasyDataset 的智能问答对生成、答案构建与多格式导出,敬请期待!
除大模型训练外,笔者也在同步更新《深入浅出LangChain&LangGraph AI Agent 智能体开发》免费专栏,要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 40 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。

