悟牛
52.96M · 2026-02-28

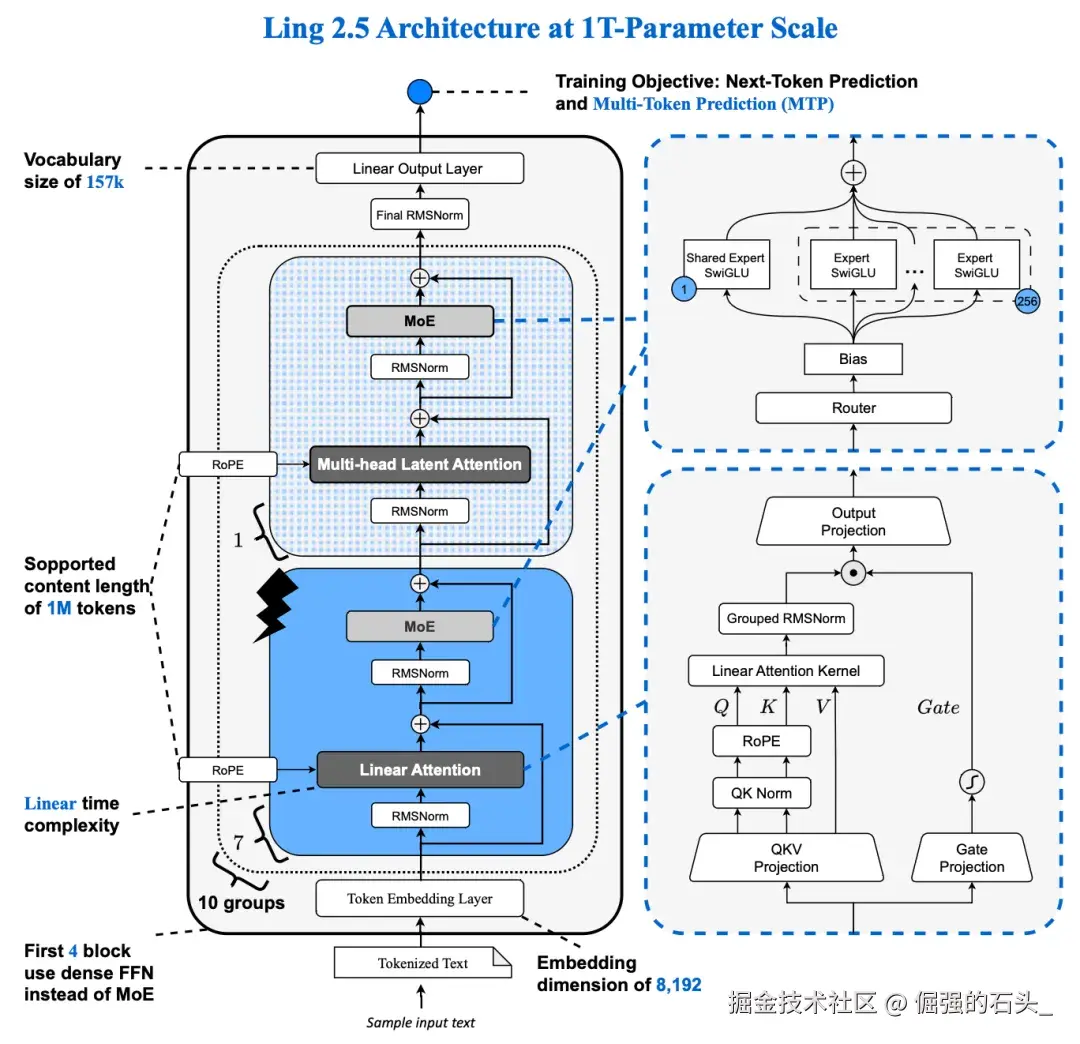
作为一名长期关注 LLM 架构演进的技术博主,最近发布的 Ring-2.5-1T 引起了我的极大兴趣。不同于市面上常见的 Transformer 变体,它采用了大胆的混合线性注意力架构(Hybrid Linear Attention)。
简单来说,通过 1:7 的 MLA + Lightning Linear 结构,Ring-2.5-1T 在保证万亿参数(激活参数 63B)强大表达能力的同时,将访存规模降低了 10 倍以上,生成吞吐提升了 3 倍。这意味着什么?意味着在处理**超长上下文(Long Context)和深度思考(Reasoning)**任务时,它能像“闪电”一样快,同时保持极高的逻辑严谨性。
今天,我就带大家深入 Ling Studio,看看这个“思考怪兽”在实际工作流中究竟能发挥多大的威力。
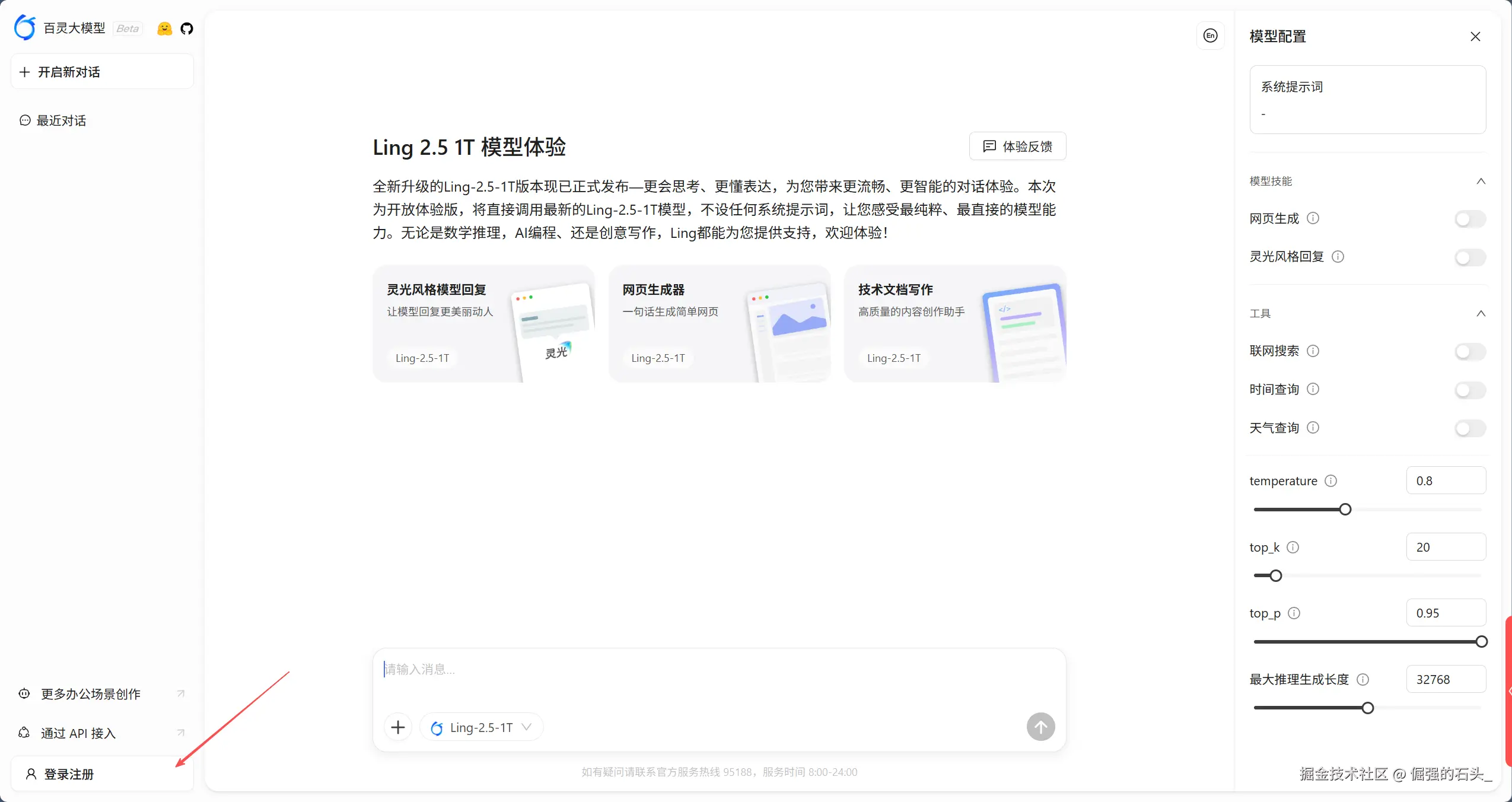
打开 Ling Studio (ling.tbox.cn),界面设计非常克制。左侧是历史记录,右侧是参数配置,中间是核心对话区。
Ling-1T(通用语言模型)和我们今天的主角 Ring-2.5-1T(思考模型)。
如果你想把“对话生成”真正落到“文档交付”,关键是先对齐 Tbox(百宝箱) 的能力边界:它更偏“生成文档/文章/PPT 等结构化产物”的入口,主要是 Ling(例如 Ling-2.5-1T)
使用的组合方式是:
实操路径:
这套方式的关键是把**“思考(Model)”与“沉淀(Document)”**绑定到同一条流水线:生成、校对、结构化输出、二次迭代,都能在一个入口里完成。
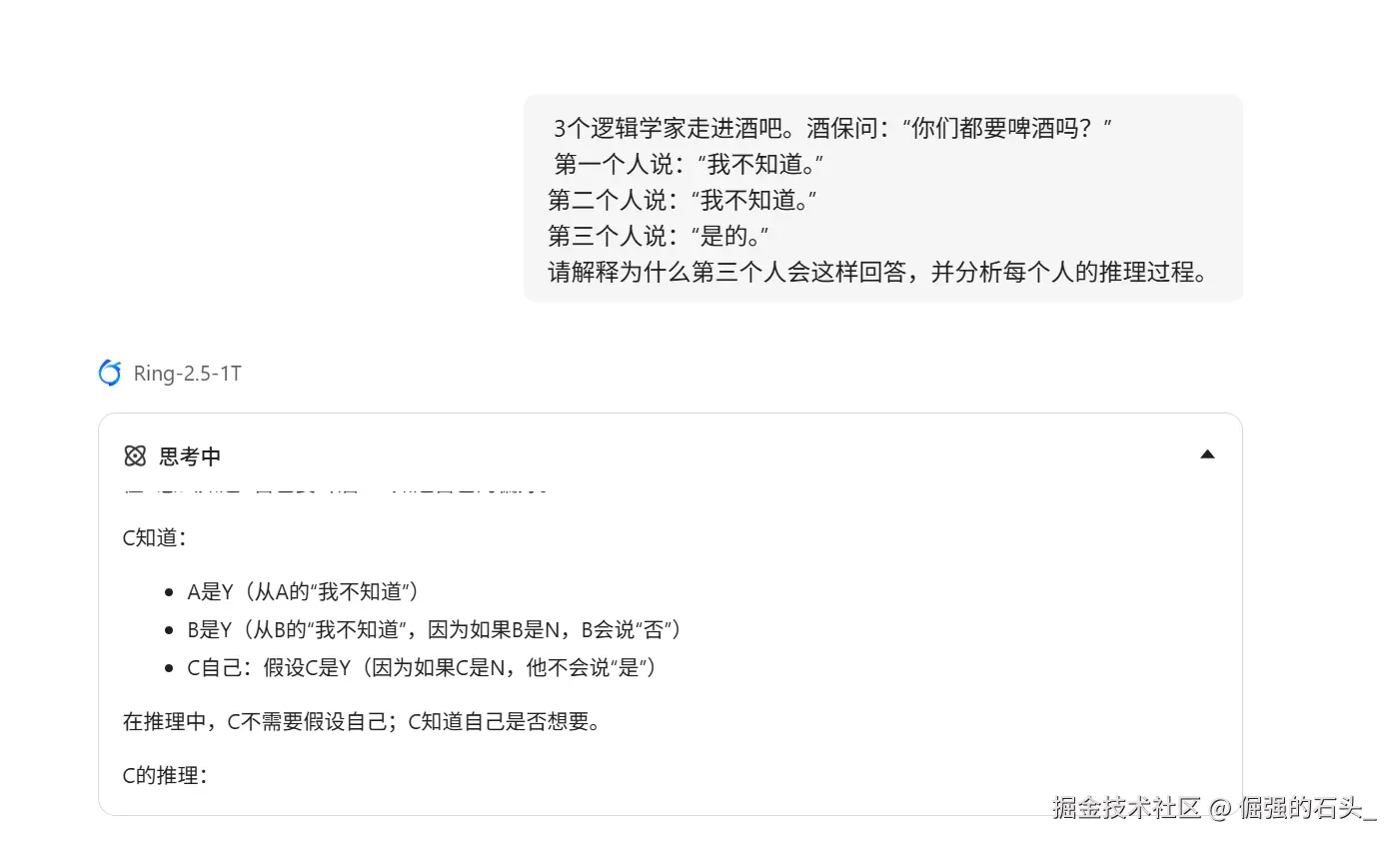
为了测试 Ring-2.5-1T 的极限,我们抛弃那些简单的“写首诗”测试,直接上硬菜。
测试题目:一道经典的博弈论逻辑陷阱题。
Ring-2.5-1T 的表现:
点击发送后,可以清晰地看到 Thinking Process(思考过程) 展开:
点评:普通模型往往会陷入“不知道”的字面意思循环,而 Ring-2.5-1T 展现了极强的**多跳推理(Multi-hop Reasoning)**能力,这得益于其 RLVR 带来的严谨性。
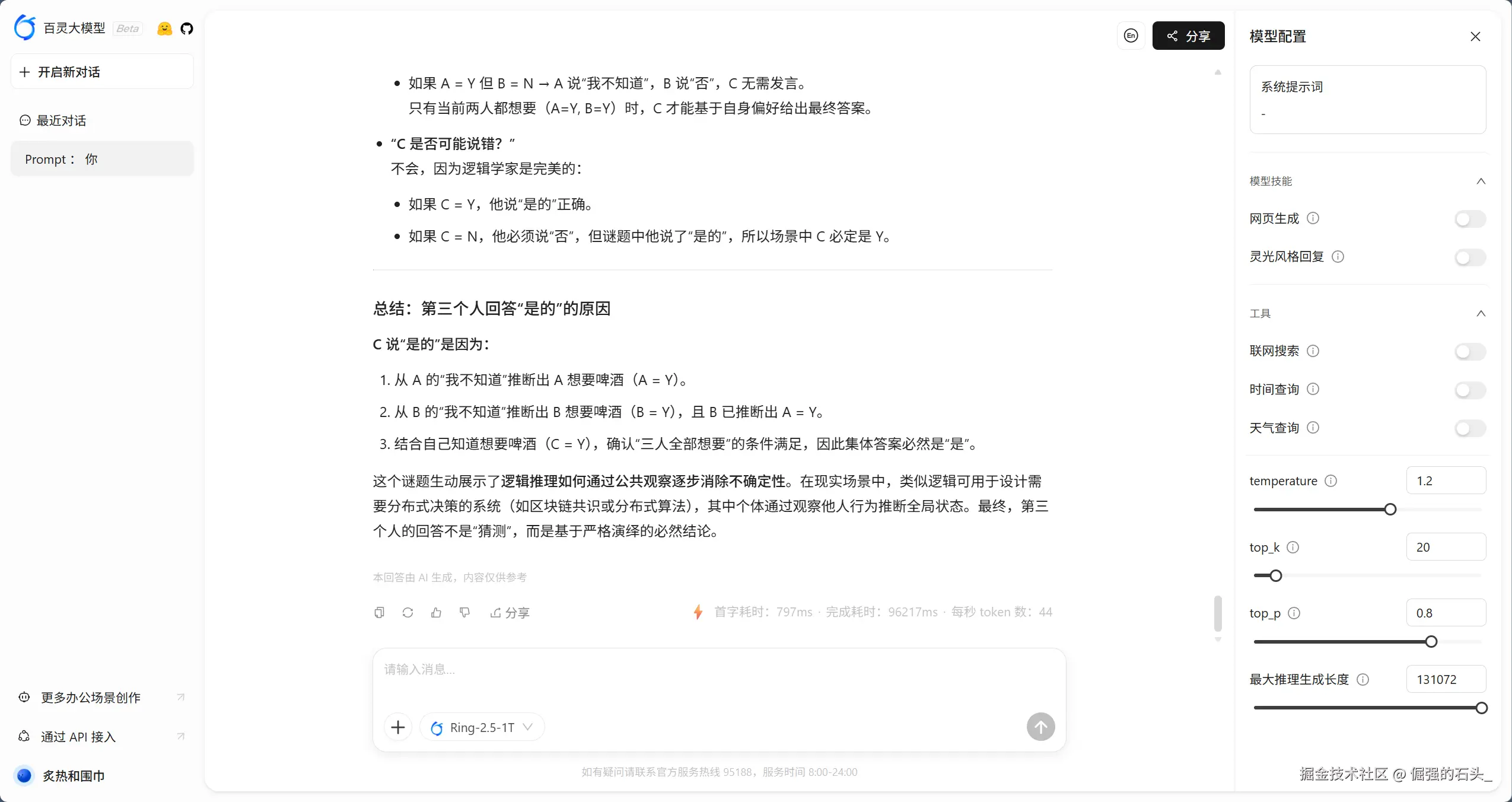
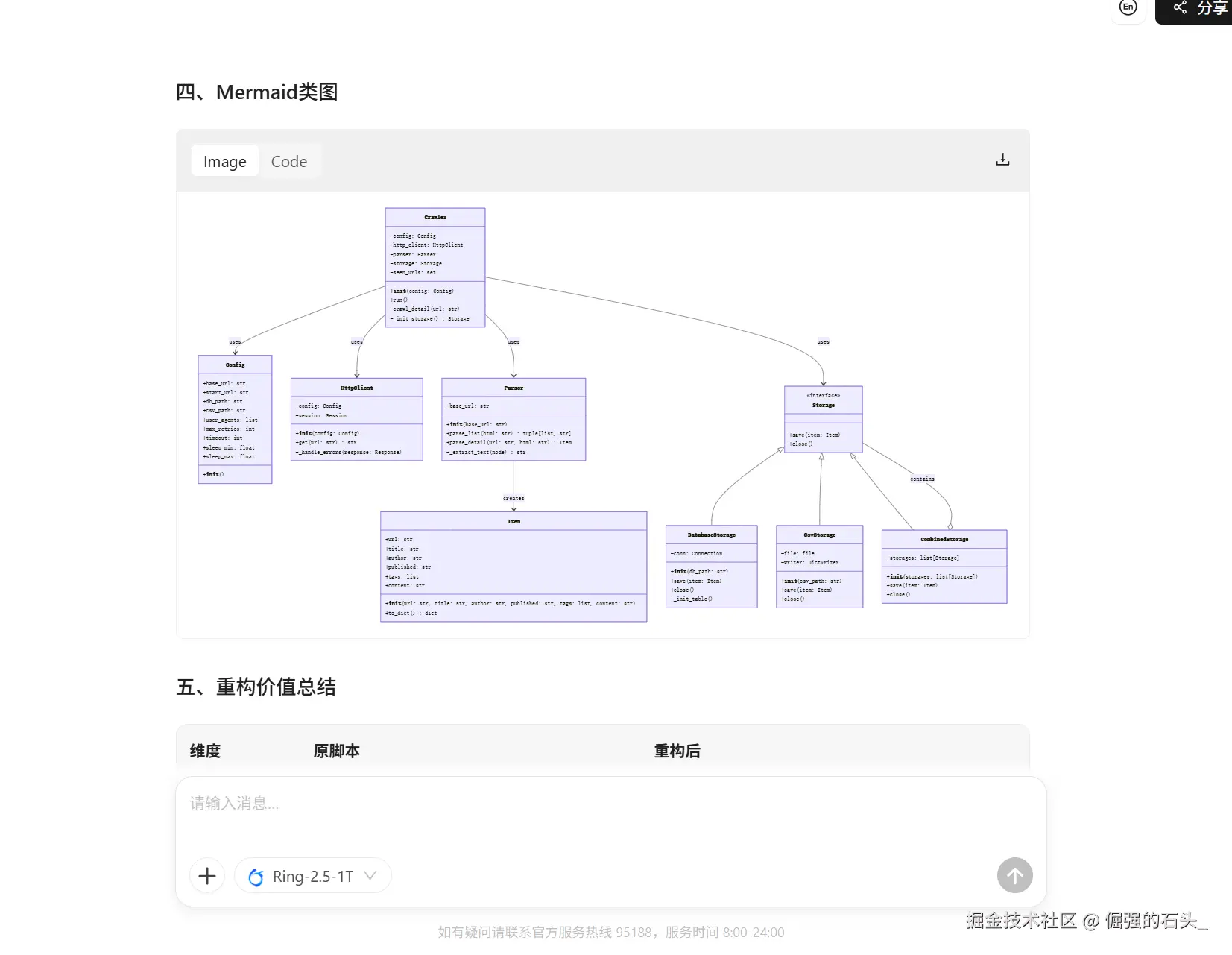
测试场景:给出一个 200 行的混乱 Python 爬虫脚本,要求重构为面向对象结构,并输出 Mermaid 类图。
Ring-2.5-1T 的表现:
下面是我的完整测试示例和模型输出结果,你可以参考结果(含“混乱脚本”“重构版本”“Mermaid 类图”)。
import os
import re
import csv
import json
import time
import random
import sqlite3
from urllib.parse import urljoin, urlparse
import requests
from bs4 import BeautifulSoup
BASE = "https://example.com"
START = "https://example.com/blog?page=1"
DB = "spider.db"
OUT = "items.csv"
UA = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/121.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Version/17.0 Safari/605.1.15",
]
S = requests.Session()
S.headers.update({"Accept": "text/html,application/xhtml+xml"})
def init_db():
conn = sqlite3.connect(DB)
cur = conn.cursor()
cur.execute(
"create table if not exists items (url text primary key, title text, author text, published text, tags text, content text, raw json)"
)
conn.commit()
conn.close()
def put_db(item):
conn = sqlite3.connect(DB)
cur = conn.cursor()
cur.execute(
"insert or replace into items(url,title,author,published,tags,content,raw) values(?,?,?,?,?,?,?)",
(
item.get("url"),
item.get("title"),
item.get("author"),
item.get("published"),
",".join(item.get("tags") or []),
item.get("content"),
json.dumps(item, ensure_ascii=False),
),
)
conn.commit()
conn.close()
def append_csv(item):
existed = os.path.exists(OUT)
with open(OUT, "a", newline="", encoding="utf-8") as f:
w = csv.DictWriter(
f, fieldnames=["url", "title", "author", "published", "tags", "content"]
)
if not existed:
w.writeheader()
w.writerow(
{
"url": item.get("url"),
"title": item.get("title"),
"author": item.get("author"),
"published": item.get("published"),
"tags": ",".join(item.get("tags") or []),
"content": (item.get("content") or "").replace("n", " ").strip(),
}
)
def sleep_jitter():
time.sleep(random.random() * 0.8 + 0.2)
def get(url):
S.headers["User-Agent"] = random.choice(UA)
try:
r = S.get(url, timeout=10, allow_redirects=True)
if r.status_code in (429, 503):
time.sleep(2)
r = S.get(url, timeout=10)
if r.status_code != 200:
return ""
r.encoding = r.apparent_encoding
return r.text
except Exception:
return ""
def extract_text(node):
if not node:
return ""
return re.sub(r"s+", " ", node.get_text(" ", strip=True)).strip()
def parse_list(html):
soup = BeautifulSoup(html, "html.parser")
a_list = soup.select("a.post-link")
urls = []
for a in a_list:
href = a.get("href") or ""
if not href:
continue
u = urljoin(BASE, href)
if urlparse(u).netloc != urlparse(BASE).netloc:
continue
urls.append(u)
next_a = soup.select_one("a.next")
next_url = urljoin(BASE, next_a.get("href")) if next_a and next_a.get("href") else ""
return urls, next_url
def parse_detail(url, html):
soup = BeautifulSoup(html, "html.parser")
title = extract_text(soup.select_one("h1"))
author = extract_text(soup.select_one(".author"))
published = extract_text(soup.select_one("time"))
tags = [extract_text(x) for x in soup.select(".tags a")]
content = extract_text(soup.select_one("article")) or extract_text(soup.select_one(".content"))
if not title:
title = extract_text(soup.select_one("title"))
item = {
"url": url,
"title": title,
"author": author,
"published": published,
"tags": [t for t in tags if t],
"content": content,
}
return item
def crawl():
init_db()
url = START
seen = set()
while url and url not in seen:
seen.add(url)
html = get(url)
if not html:
break
urls, next_url = parse_list(html)
for u in urls:
sleep_jitter()
d = get(u)
if not d:
continue
item = parse_detail(u, d)
if not item.get("title"):
continue
put_db(item)
append_csv(item)
url = next_url
if __name__ == "__main__":
crawl()
import os
import re
import csv
import json
import time
import random
import sqlite3
from abc import ABC, abstractmethod
from urllib.parse import urljoin, urlparse
from typing import List, Tuple, Dict, Any, Optional
import requests
from bs4 import BeautifulSoup
class Item:
"""数据实体类 - 封装抓取结果"""
def __init__(self, url: str, title: str = "", author: str = "",
published: str = "", tags: List[str] = None, content: str = ""):
self.url = url
self.title = title
self.author = author
self.published = published
self.tags = tags or []
self.content = content
def to_dict(self) -> Dict[str, Any]:
return {
"url": self.url,
"title": self.title,
"author": self.author,
"published": self.published,
"tags": self.tags,
"content": self.content
}
def __str__(self):
return f"Item(url={self.url}, title={self.title[:30]}...)"
class Config:
"""配置中心 - 集中管理所有配置参数"""
def __init__(self):
self.base_url = "https://example.com"
self.start_url = "https://example.com/blog?page=1"
self.db_path = "spider.db"
self.csv_path = "items.csv"
self.user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/121.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Version/17.0 Safari/605.1.15",
]
self.max_retries = 3
self.timeout = 10
self.sleep_min = 0.2
self.sleep_max = 1.0
class Storage(ABC):
"""抽象存储接口 - 定义统一存储行为"""
@abstractmethod
def save(self, item: Item) -> None:
pass
@abstractmethod
def close(self) -> None:
pass
class DatabaseStorage(Storage):
"""SQLite存储实现"""
def __init__(self, db_path: str):
self.conn = sqlite3.connect(db_path)
self._init_table()
def _init_table(self) -> None:
cursor = self.conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS items (
url TEXT PRIMARY KEY,
title TEXT,
author TEXT,
published TEXT,
tags TEXT,
content TEXT,
raw JSON
)
""")
self.conn.commit()
def save(self, item: Item) -> None:
cursor = self.conn.cursor()
cursor.execute(
"INSERT OR REPLACE INTO items (url, title, author, published, tags, content, raw) "
"VALUES (?, ?, ?, ?, ?, ?, ?)",
(
item.url,
item.title,
item.author,
item.published,
",".join(item.tags),
item.content,
json.dumps(item.to_dict(), ensure_ascii=False)
)
)
self.conn.commit()
def close(self) -> None:
self.conn.close()
class CsvStorage(Storage):
"""CSV存储实现"""
def __init__(self, csv_path: str):
self.csv_path = csv_path
self.file_exists = os.path.exists(csv_path)
self.file = open(csv_path, "a", newline="", encoding="utf-8")
self.writer = csv.DictWriter(
self.file,
fieldnames=["url", "title", "author", "published", "tags", "content"]
)
if not self.file_exists:
self.writer.writeheader()
def save(self, item: Item) -> None:
self.writer.writerow({
"url": item.url,
"title": item.title,
"author": item.author,
"published": item.published,
"tags": ",".join(item.tags),
"content": item.content.replace("n", " ").strip()
})
self.file.flush()
def close(self) -> None:
self.file.close()
class HttpClient:
"""HTTP客户端 - 封装网络请求逻辑"""
def __init__(self, config: Config):
self.config = config
self.session = requests.Session()
self.session.headers.update({"Accept": "text/html,application/xhtml+xml"})
def get(self, url: str) -> str:
"""带重试机制的GET请求"""
for attempt in range(self.config.max_retries):
try:
self.session.headers["User-Agent"] = random.choice(self.config.user_agents)
response = self.session.get(
url,
timeout=self.config.timeout,
allow_redirects=True
)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
elif response.status_code in (429, 503):
time.sleep(2 ** attempt) # 指数退避
except requests.RequestException as e:
print(f"Request failed ({attempt+1}/{self.config.max_retries}): {str(e)}")
time.sleep(random.uniform(
self.config.sleep_min,
self.config.sleep_max
))
return ""
class Parser:
"""HTML解析器 - 专注内容提取"""
def __init__(self, base_url: str):
self.base_url = base_url
@staticmethod
def _extract_text(node) -> str:
if not node:
return ""
return re.sub(r"s+", " ", node.get_text(" ", strip=True)).strip()
def parse_list(self, html: str) -> Tuple[List[str], Optional[str]]:
"""解析列表页,提取详情页URL和下一页链接"""
soup = BeautifulSoup(html, "html.parser")
urls = []
for a in soup.select("a.post-link"):
href = a.get("href", "")
if not href:
continue
full_url = urljoin(self.base_url, href)
if urlparse(full_url).netloc == urlparse(self.base_url).netloc:
urls.append(full_url)
next_url = None
next_a = soup.select_one("a.next")
if next_a and next_a.get("href"):
next_url = urljoin(self.base_url, next_a["href"])
return urls, next_url
def parse_detail(self, url: str, html: str) -> Optional[Item]:
"""解析详情页,提取结构化数据"""
soup = BeautifulSoup(html, "html.parser")
title = self._extract_text(soup.select_one("h1")) or
self._extract_text(soup.select_one("title"))
author = self._extract_text(soup.select_one(".author"))
published = self._extract_text(soup.select_one("time"))
tags = [self._extract_text(tag) for tag in soup.select(".tags a")]
content = self._extract_text(soup.select_one("article")) or
self._extract_text(soup.select_one(".content"))
if not title:
return None
return Item(
url=url,
title=title,
author=author,
published=published,
tags=[t for t in tags if t],
content=content
)
class Crawler:
"""主爬虫控制器 - 协调各组件工作流"""
def __init__(self, config: Config = None):
self.config = config or Config()
self.http_client = HttpClient(self.config)
self.parser = Parser(self.config.base_url)
self.storage = self._init_storage()
self.seen_urls = set()
def _init_storage(self) -> Storage:
"""初始化存储组件"""
db_storage = DatabaseStorage(self.config.db_path)
csv_storage = CsvStorage(self.config.csv_path)
# 使用装饰器模式组合存储(同时写入DB和CSV)
class CombinedStorage(Storage):
def __init__(self, storages: List[Storage]):
self.storages = storages
def save(self, item: Item) -> None:
for storage in self.storages:
storage.save(item)
def close(self) -> None:
for storage in self.storages:
storage.close()
return CombinedStorage([db_storage, csv_storage])
def run(self) -> None:
"""启动爬虫主流程"""
current_url = self.config.start_url
while current_url and current_url not in self.seen_urls:
print(f"Crawling: {current_url}")
self.seen_urls.add(current_url)
html = self.http_client.get(current_url)
if not html:
break
urls, next_url = self.parser.parse_list(html)
for detail_url in urls:
self._crawl_detail(detail_url)
current_url = next_url
self.storage.close()
print(f"Completed! Processed {len(self.seen_urls)} pages")
def _crawl_detail(self, url: str) -> None:
"""抓取并处理单个详情页"""
if url in self.seen_urls:
return
self.seen_urls.add(url)
html = self.http_client.get(url)
if not html:
return
item = self.parser.parse_detail(url, html)
if item and item.title:
self.storage.save(item)
print(f"Saved: {item}")
if __name__ == "__main__":
crawler = Crawler()
crawler.run()
classDiagram
class Config {
+base_url: str
+start_url: str
+db_path: str
+csv_path: str
+user_agents: list
+max_retries: int
+timeout: int
+sleep_min: float
+sleep_max: float
+__init__()
}
class HttpClient {
-config: Config
-session: Session
+__init__(config: Config)
+get(url: str) str
-_handle_errors(response: Response)
}
class Parser {
-base_url: str
+__init__(base_url: str)
+parse_list(html: str) tuple[list, str]
+parse_detail(url: str, html: str) Item
-_extract_text(node) str
}
class Item {
+url: str
+title: str
+author: str
+published: str
+tags: list
+content: str
+__init__(url: str, title: str, author: str, published: str, tags: list, content: str)
+to_dict() dict
}
class Storage {
<<interface>>
+save(item: Item)
+close()
}
class DatabaseStorage {
-conn: Connection
+__init__(db_path: str)
+save(item: Item)
+close()
-_init_table()
}
class CsvStorage {
-file: file
-writer: DictWriter
+__init__(csv_path: str)
+save(item: Item)
+close()
}
class CombinedStorage {
-storages: list[Storage]
+__init__(storages: list[Storage])
+save(item: Item)
+close()
}
class Crawler {
-config: Config
-http_client: HttpClient
-parser: Parser
-storage: Storage
-seen_urls: set
+__init__(config: Config)
+run()
-crawl_detail(url: str)
-_init_storage() Storage
}
Crawler --> Config : uses
Crawler --> HttpClient : uses
Crawler --> Parser : uses
Crawler --> Storage : uses
Parser --> Item : creates
Storage <|-- DatabaseStorage
Storage <|-- CsvStorage
Storage <|-- CombinedStorage
CombinedStorage o-- Storage : contains
这里分享两个我在使用 Ling + Tbox 时摸索出的高阶玩法。
在工程写作里,Mermaid 更像是一种“可维护的图”。这里的玩法是:用 Ling Studio(更推荐 Ring-2.5-1T)或 Tbox(Ling)生成 Mermaid 代码块,然后把它作为图表源码嵌进 Tbox 的文档里;如果你的 Tbox 编辑器不支持直接渲染 Mermaid,就把 Mermaid 代码粘到在线渲染器里导出图片/截图,再回填到文档中。
Prompt 技巧:
sequenceDiagram
autonumber
actor User
participant Crawler
participant HttpClient
participant Parser
participant Repo as Repository
participant Site as TargetSite
User->>Crawler: run()
Crawler->>HttpClient: get_text(start_url)
HttpClient->>Site: GET /blog?page=1
Site-->>HttpClient: HTML(list)
HttpClient-->>Crawler: html
Crawler->>Parser: parse_list(html)
Parser-->>Crawler: urls[], next_url
loop for each post url
Crawler->>HttpClient: get_text(post_url)
HttpClient->>Site: GET /post/xxx
Site-->>HttpClient: HTML(detail)
HttpClient-->>Crawler: detail_html
Crawler->>Parser: parse_detail(url, detail_html)
Parser-->>Crawler: Article
Crawler->>Repo: save(Article, raw)
end
Crawler->>HttpClient: get_text(next_url)
操作流:
mermaid ... )。
效果:瞬间将枯燥的代码逻辑转化为了清晰的时序图。Ring-2.5-1T 对代码逻辑的理解极深,生成的流程图几乎无需修改。我们可以利用 Ring-2.5-1T 的 System Prompt 能力,定义一个专属的 Skill。
Skill 设定:
将这个 Prompt 保存为你的常用模板,按两段式来跑:
体感上,Ring 更像“严苛的资深 Reviewer”,Tbox 更像“把结论写成可传播资产的编辑部”。
Ring-2.5-1T 的发布,标志着大模型从“聊天机器人(Chatbot)”向“智能体(Agent)”的进化。
结合 Ling Studio 的强大推理能力与 Tbox 的知识管理能力,我们可以构建如下的 Agentic Workflow:
这不再是简单的“辅助工具”,而是你团队中一位不知疲倦、逻辑严密的硅基合伙人。

