







我的相册
72.86M · 2026-02-13

本文最后有详细的 Skill,大家可以自行取用。
如何将资深测试专家的“质量思维”无缝传递给一线业务研发,让 Bug 在写代码那一刻就被拦截,而不是等到提测甚至上线后才引爆?
在回答这个问题前,我们需要先界定一下“缺陷”的本质。在研发实战中,缺陷通常分为两类:
通用缺陷(硬知识): 它是代码层面的“硬伤”,如空指针异常、SQL 注入、内存泄漏或不符合编程规范的命名。这类问题有标准答案,静态扫描工具(SonarQube 等)已经做得很好。
业务缺陷(软知识): 它是结合具体业务场景的“逻辑漏洞”,比如“在促销活动结束前,订单状态机是否允许直接跳转至退款”或“VIP 用户的权益计算是否遗漏了新规则”。这类问题高度依赖上下文,传统的静态工具对此无能为力。
目前的痛点在于,针对“业务缺陷”的质量平台大多游离在 IDE 之外:规范在文档里、规则在脑子里、开发却在编辑器中。大家虽知晓规范,但没人会在写代码的心流时刻频繁切屏去翻阅几百页的业务文档。
基于这个痛点,本文利用 SOLO 模式 + 自定义 Agent Skills 做了一次探索:把复杂的质量检测能力拆成一个个可复用的「原子化研发技能」,让每个开发在写代码时,都能随手召唤一位“虚拟质量专家”。
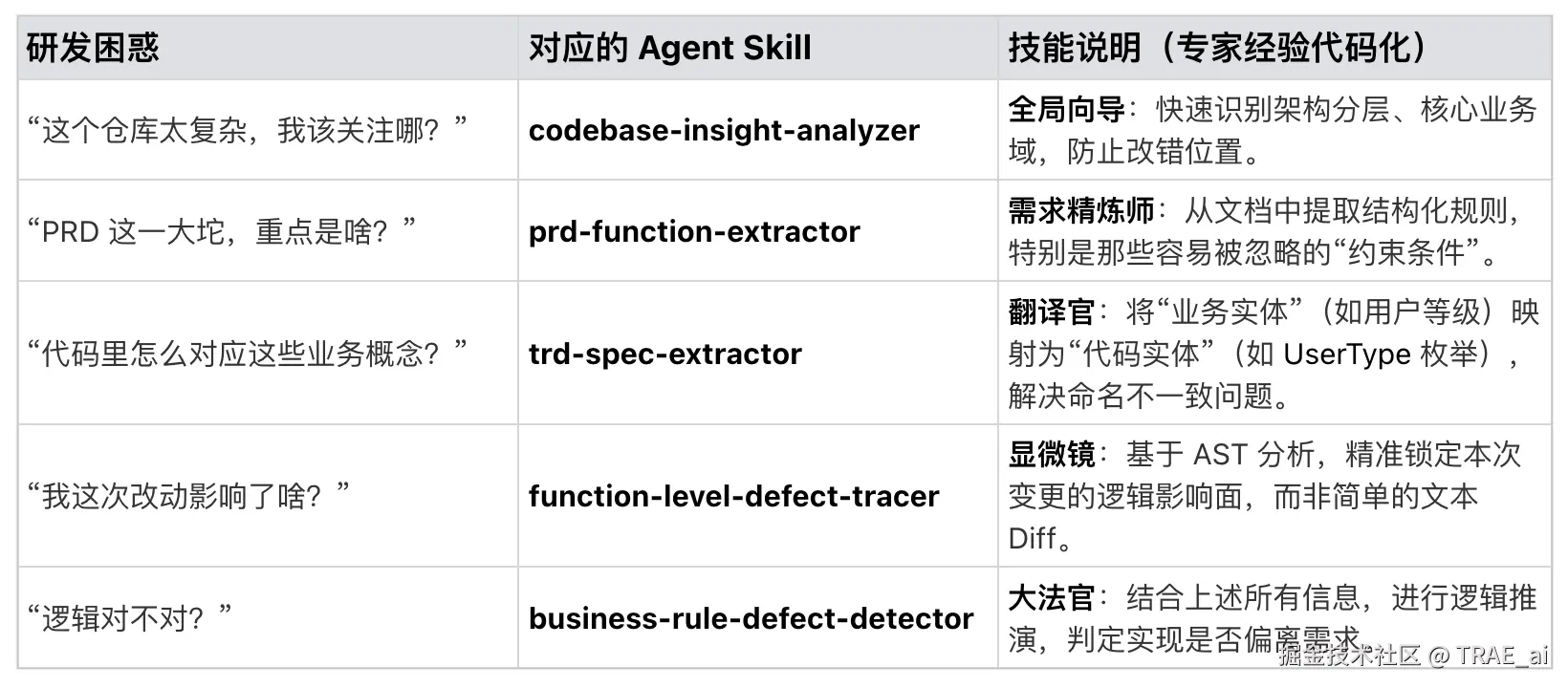
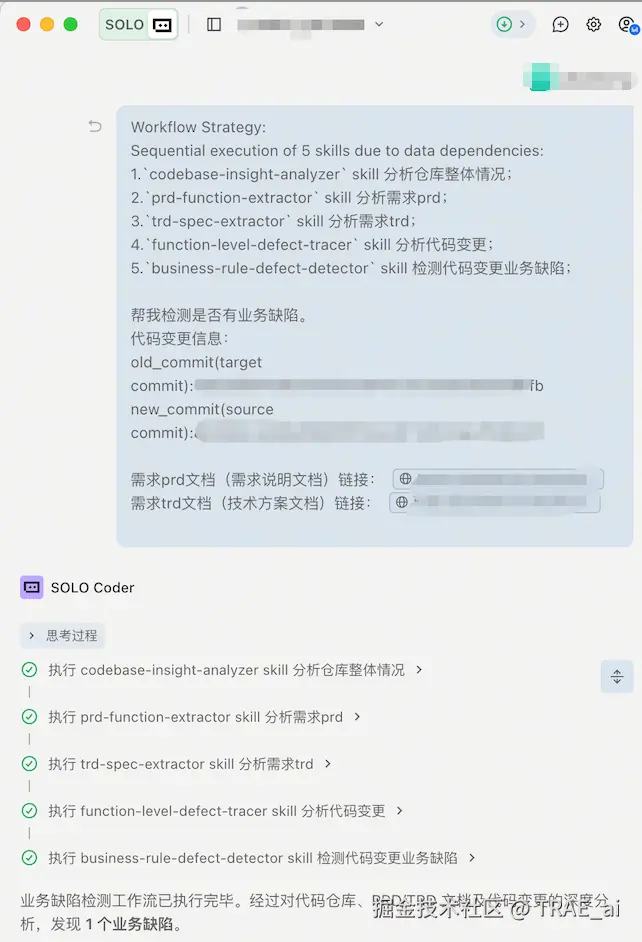
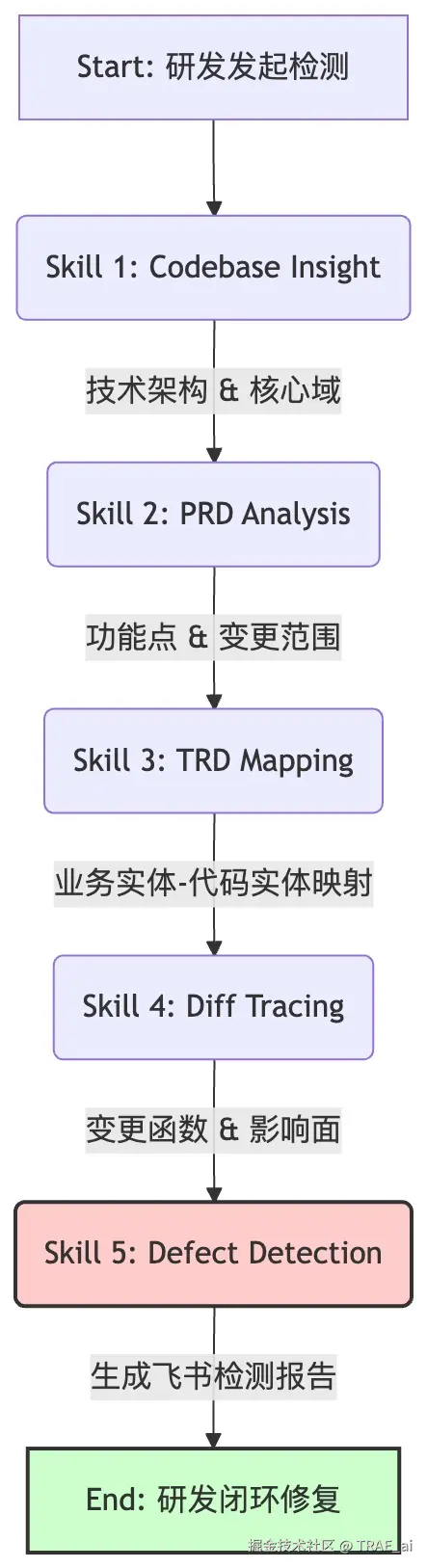
通过在 IDE 内编排 5 个 Agent Skill,我们把从需求理解、技术方案对齐,到代码变更分析、缺陷判定和修复建议的完整链路自动化串联起来。
这意味着,每位开发者在写代码时,都随时有一位懂业务、懂代码的“虚拟质量专家”在侧,让高危业务缺陷在提测前即刻暴露。
实战数据表明,这种方式显著提升了研发的主动质量意识与缺陷拦截效率。
作为开发者,我们 90% 的时间都沉浸在 IDE 里构建逻辑、调试堆栈。然而,决定代码正确性的“依据”却散落在 IDE 之外的信息海洋中。
需求碎片化: 核心逻辑可能藏在飞书文档的某个批注里,或者 PRD 的第 5 次变更记录中。
知识隐性化: 很多历史业务规则并不在文档里,而是在 Wiki 的角落,甚至存在于已经离职的老员工的口口相传中。
反馈滞后性: 传统的质量检测往往发生在代码提交之后。你得等待 CI 流水线跑完,去 Jenkins 或 Sonar 平台查看几百行日志,才能发现一个逻辑漏洞。此时,你早已切换到下一个任务,这种“异步反馈”极大地拉高了修复成本。
这种割裂带来的直接后果是极高的上下文切换成本。
在真实的编码场景中,很少有人能做到每写一行代码就切屏去翻阅文档或咨询产品经理。当 Deadline 逼近,面对模糊的业务边界,人性使然的选择往往是:
“这个特殊的退款逻辑好像在哪里见过,但现在去翻聊天记录太断片了,凭经验应该是这样写吧……”
许多线上故障并非源于技术能力的匮乏,而是源于认知负荷的超载。当获取“正确规则”的成本过高时,由于缺乏 IDE 内实时的辅助,Bug 便在指尖敲击键盘的那一刻,悄无声息地成为了系统的一部分。
Agent Skill 机制让我们看到了破局的希望:如果能把质量专家的知识封装成 Skill,直接装进 IDE 里,岂不是就能让研发人员拥有一位“随叫随到的质量专家”?利用 TRAE 的能力,为业务研发提供一套轻量、即时、嵌入式的“质量辅助插件”。
我们没有从零搭一个新平台,而是基于 TRAE 的 SOLO 模式,把资深 QA 和架构师沉淀多年的经验,拆解成 5 个标准化 Skill。它们聚焦解决研发最常问、也最容易出问题的三个灵魂拷问:
需求到底要什么?
系统是怎么实现的?
我这次改动有没有漏?
我们把质量检测链路拆成研发在 IDE 内可以单独调用的「原子能力」,每个 Skill 都只负责一件事。
在研发提交代码代码前,使用 TRAE Skills 进行缺陷检测。
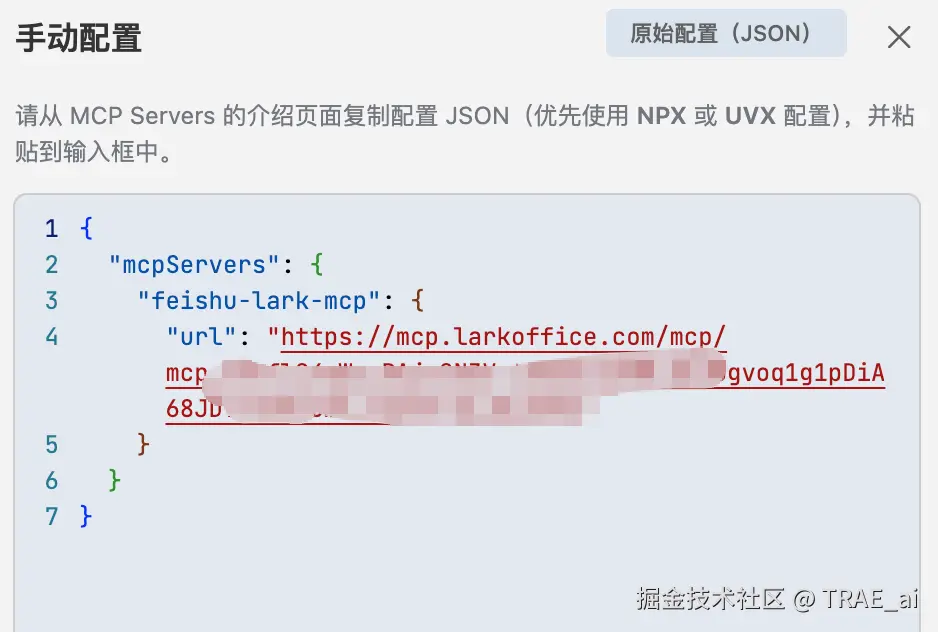
在项目根目录创建 。trae/skills 文件夹,将技能包放入目录。
配置 TRAE Skills
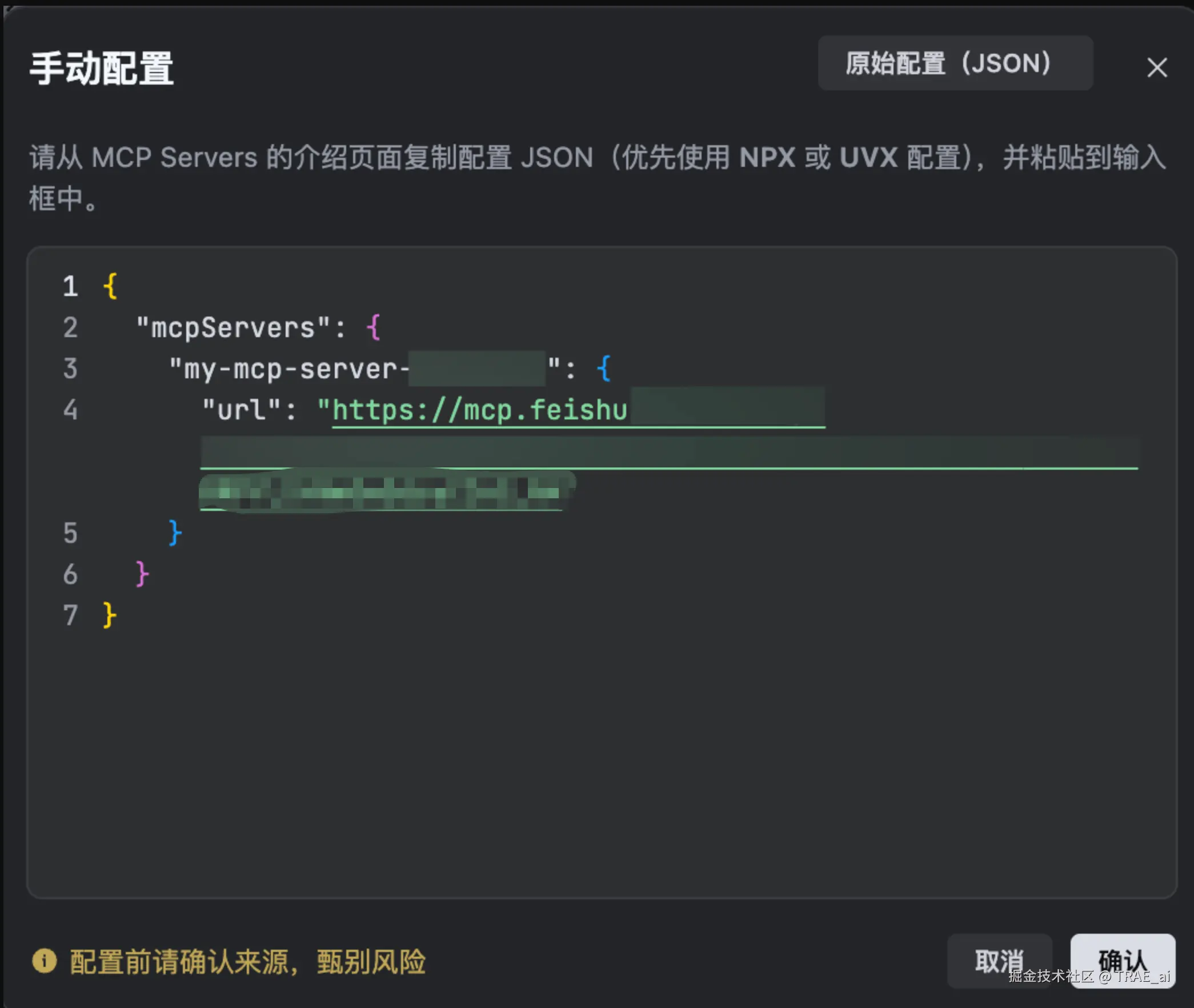
业务缺陷检测流程,需要分析需求文档和技术方案文档,因此需要配置 飞书 MCP 工具用于查看文档。
飞书 MCP 工具:搜索文档、查看文档、创建文档等功能。
配置流程,参考:
open.larkoffice.com/document/mc…
1. 登录飞书 MCP 配置平台
2. 点击 创建 MCP 服务
3. 在 MCP 工具配置 区域,确认当前用户身份。
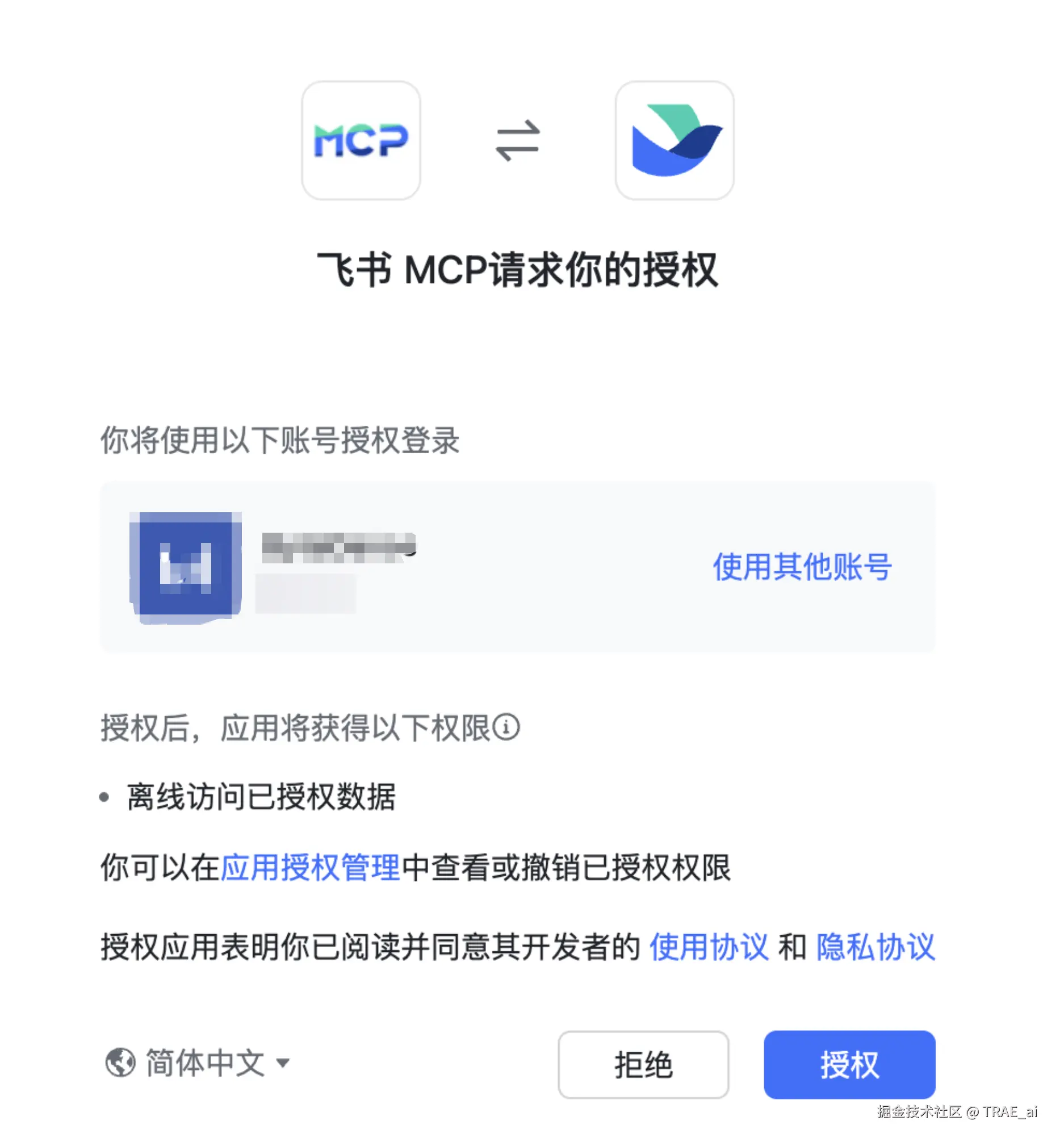
4. 在 添加工具 卡片内,点击 添加,在添加工具对话框,选择**「云文档」**工具集。
5. 点击 确认添加,并在弹出的 获取用户授权 对话框,确认授权用户登录信息、飞书 MCP 应用获得的权限信息后,点击 授权。
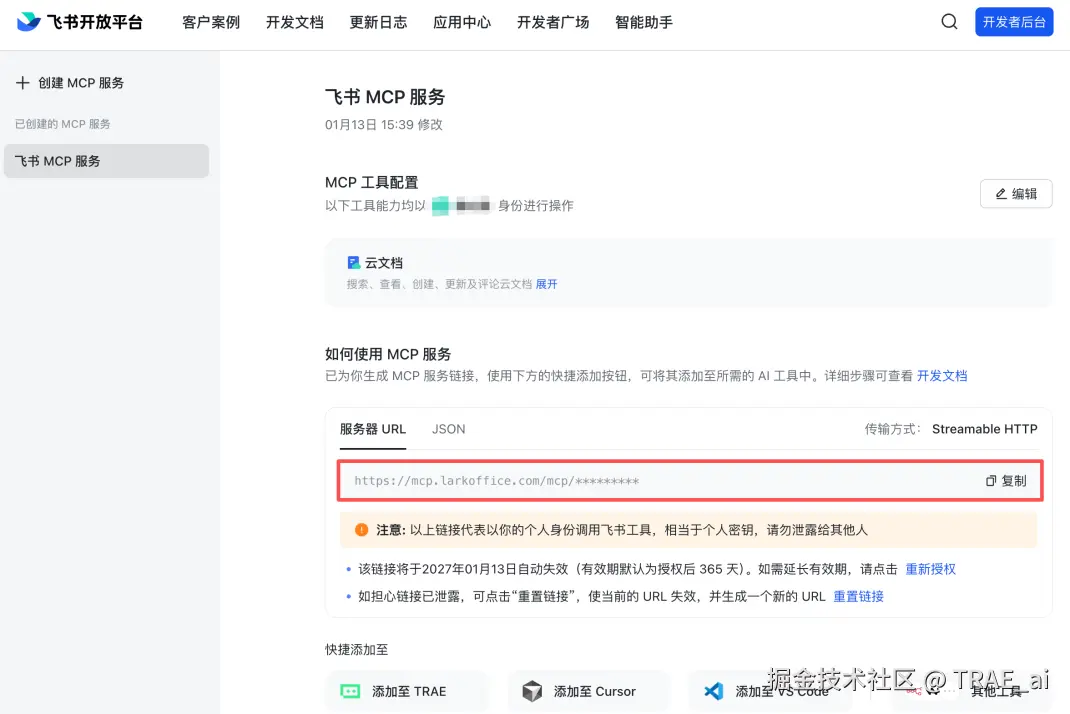
6. 添加工具后,在 如何使用 MCP 服务 区域,查看 服务器 URL、JSON。
7. 在 TRAE 的 MCP 手动配置对话框内,点击 确认。
完成 Skills 和 MCP 配置后,在 SOLO 模式下触发缺陷检测流程。
SOLO 模式下触发检测
使用 Skills 进行缺陷检测
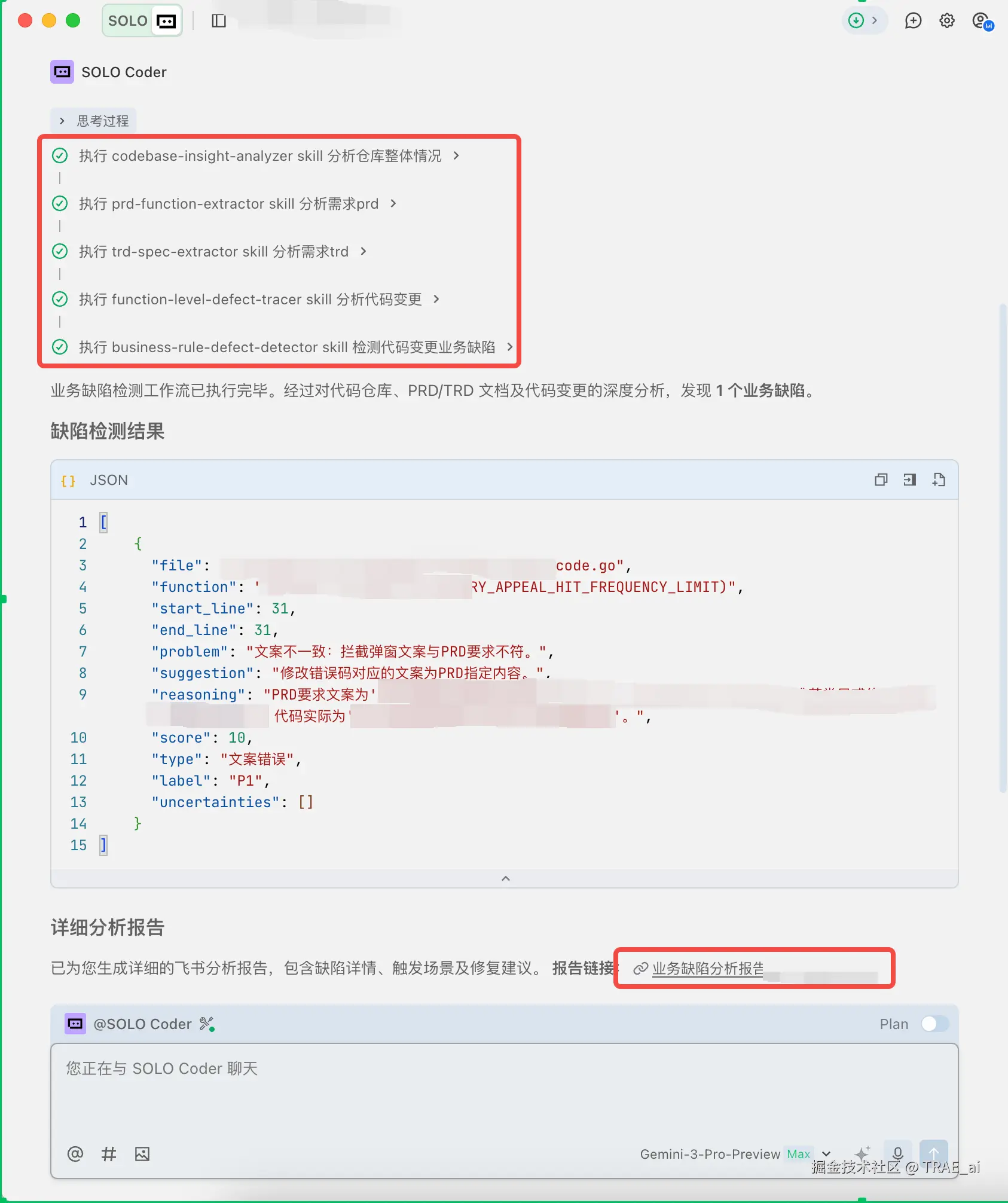
使用 Skills 进行缺陷检测,产出飞书缺陷报告文档
接下来,我们从一位业务研发同学的视角,走一遍完整的实战流程,看看这套 Skill 组合是如何帮助他完成 “消息夜间防打扰” 功能开发的。
研发“小张”接到一个需求:在现有消息服务中加入夜间防打扰逻辑——
每天 22:00 - 次日 08:00,营销类消息需要静默(不发送或返回失败),但验证码类消息不受影响。
小张写完了代码,准备提测。
由于每一步检测之间有严格的数据依赖,我们没有把它们做成松散的零散工具,而是设计了一条包含 5 个阶段的 串行 Workflow,确保每一个环节的输出都成为下一个环节的上下文输入。
调用 Skill: codebase-insight-analyzer
动作: 小张在对话框输入“分析当前仓库”。
背后做了什么?
这个 Skill 不只是粗暴扫文件,而是自动做了一次缩略版的 “架构逆向工程” :
技术栈识别: 通过 go.mod 和构建脚本,识别出项目基于 CloudWeGo 技术栈(Kitex + Hertz),并依赖 Redis 做缓存;
架构分层推断: 结合目录结构(如 internal/handler、internal/service、internal/repo),推断这是一个 DDD-lite 分层架构,请求大致流向是 Handler -> Service -> Domain -> Repo;
核心域定位: 通过代码密度和依赖关系,识别出 internal/service/dispatch、internal/biz/strategy 是业务逻辑最集中的核心域,而 utils、common 等更多是支撑模块。
产出成果 (AGENTS.md):
最终,Agent 在仓库根目录生成了一份结构化的全局上下文文档 AGENTS.md,帮后续的所有 Skill 画出了一张清晰的 “作战地图” 。
# Architecture Overview
- **Style** : DDD-lite / Clean Architecture
- **Core Modules** :
- `internal/service/dispatch`: 消息分发核心域
- `internal/biz/strategy`: 策略过滤核心域
- **Data Flow** : Request -> Handler -> DispatchService -> Strategy -> Repo
价值: 有了这张“地图”,后续再找“防打扰策略”相关逻辑时,Agent 会直接去 strategy 等核心域定位,而不会在无关目录里漫游,既省 Token 又提高准确率。
调用 Skill: prd-function-extractor
动作: 小张在对话框提供 PRD 文档链接:xxx ,提取防打扰规则”。
背后做了什么?
这个 Skill 相当于一位 “顶级业务分析师” ,把冗长的 PRD 变成清晰的需求清单,主要做了三件事:
场景识别: 通过飞书 MCP 接口获取文档全文,识别出“用户发送消息”的主场景,以及“夜间”“营销消息”等分支条件;
要素清洗: 用内置的 CoT Prompt 把背景介绍、废话和噪音统统剥离,只保留真正影响逻辑的业务规则和约束条件(比如“按用户时区判断时间段”);
结构化输出: 把这些自然语言规则变成机器可读的 JSON,并为每条需求打上唯一的 ID。
产出成果 (JSON):
最终,Agent 输出了一份类似下面的标准化需求列表,其中还特别标注了最容易被忽略的边缘场景(例如时区处理):
[ { "requirement_id": "PRD-MSG-005", "scenario_description": "营销消息夜间防打扰", "business_rule": "每日 22:00 至次日 08:00 期间,类型为 'Marketing' 的消息应被拦截,直接返回发送失败状态。", "constraints": "1. 仅针对 Marketing 类型,Verification 类型不受限;2. 时间判断需基于用户所在时区(若无时区信息,默认东八区)。", "priority": "P0" }]
价值: 这一步解决了研发人员“看文档抓不住重点”的痛点。通过强制结构化,Agent 显式地将 “隐性约束” (如时区问题)摆在台面上,让研发在动手写代码之前,就能一眼看到:
哪些是 P0 规则 ;
哪些是必须考虑的边界场 景;
哪些细节一旦漏掉,后面一定会变成 Bug。
调用 Skill: trd-spec-extractor
动作: 在 Skill 1 的仓库知识、Skill 2 的需求 JSON 已经就绪的前提下,让 Agent 去分析 TRD。
背后做了什么?
这一步是整个流水线的“分水岭”,决定了后续缺陷检测能不能真正对上业务意图。Skill 做的不是简单“读一遍 TRD”,而是完成一次 多源信息融合(Context Fusion) :
输入对齐: 同时读取 “PRD 业务规则(Step 2 输出)” 和 “TRD 技术方案”;
实体映射 (Entity Mapping): 把 PRD 中的自然语言概念(如“用户时区”)映射到 TRD 中的具体技术实体,比如 **UserContext.GetTimezone() **、time.ParseInLocation 等;
约束传递: 把“验证码豁免”这样的业务规则,转成技术世界里的硬约束,比如“msgType == Verification 时必须跳过防打扰检查”。
产出成果 (JSON):
Agent 输出了一份 “技术规格书” ,将抽象的业务规则翻译成了具象的代码预期:
[ { "specification_id": "TRD-MSG-005", "related_requirement_id": "PRD-MSG-005", "module": "DispatchService.CheckDoNotDisturb", "specific_requirements": "1. 必须在 DispatchService 中新增私有方法 CheckDoNotDisturb;2. 必须使用 UserContext.GetTimezone() 获取用户时区,禁止使用 time.Now();3. 针对 msgType=Verification 必须直接返回 true。" }]
价值: 这一步彻底消除了 “自然语言”与“编程语言”之间的语义鸿沟 。 如果没有这一步,后面的检测 Skill 可能会认为:
用 **time.Now() **也没什么不对;
忘写 Verification 的豁免逻辑也“看起来合理”。
而现在,每一条检测都有了清晰的 “定罪依据” 。
调用 Skill: function-level-defect-tracer
动作: Agent 分析 Git Diff,进行初步匹配。
背后做了什么?
这个 Skill 的目标,是为“大法官”准备一份干净、聚焦的 “证据包” ,因此它对原始 Git Diff 做了精细化加工:
AST 级差异分析: 不是只看“哪几行变了”,而是解析 Go 的 AST,识别这次改动发生在 DispatchService 结构体的 SendMessage 方法内部;
噪音过滤: 自动忽略 import 排序、注释修改、空行变动等对业务逻辑无实质影响的改动;
调用关系追踪: 识别出新增代码引入了对 **time.Now() **的调用,并打上“高风险”标签(因为时间相关逻辑往往和状态、时区强相关)。
产出成果 (JSON):
Agent 生成了一份 “变更画像” ,清晰地指出了改了哪里、怎么改的、有什么风险:
{
"changed_files": ["internal/service/dispatch.go"],
"function_level_changes": [
{
"symbol": "SendMessage",
"change_type": "MODIFIED",
"diff_hunks_refs": ["dispatch.go#L45-L58"],
"change_summary": "在消息分发前新增了基于 time.Now().Hour() 的条件判断分支",
"impact_analysis": {
"new_dependencies": ["time"],
"control_flow": "新增了一个提前返回 (early return) 的分支"
}
}
],
"risk_notes": [
{"entity": "SendMessage", "reason": "核心分发链路引入了新的阻断逻辑,可能导致消息丢弃"}
]
}
价值: 这一步通过 “去噪”和“聚焦” ,极大地降低了后续步骤的上下文干扰。它告诉检测 Skill:“别管那些无关紧要的改动,盯着 SendMessage 里的这 13 行代码看!”这为高精度的缺陷判定奠定了坚实基础。
调用 Skill: business-rule-defect-detector
动作: Agent 汇总前 4 步的所有信息,进行最终裁决。
背后做了什么?
这是本方案的 “大脑” 。不同于传统的 Linter 只看代码,该 Skill 执行的是多源证据链推理(Multi-Source Reasoning):
1. 证据拼图: Agent 将“架构知识(Skill 1)”、“PRD 规则(Skill 2)”、“TRD 映射(Skill 3)”和“变更画像(Skill 4)”拼在一起。
2. 逻辑推演:
事实:代码变更引入了 if hour >= 22。
规则:PRD 要求的是 22:00 - 08:00 全时段拦截。
冲突:代码漏掉了 00:00 - 08:00 这半段。
事实:代码使用了 **time.Now() **。
约束:TRD 明确要求使用 **UserContext.GetTimezone() **。
冲突:违反了技术规格书的实体映射。
3. 结论生成: 基于上述冲突,Agent 判定本次变更存在 [P0] 级业务逻 辑遗漏。
产出成果与闭环:
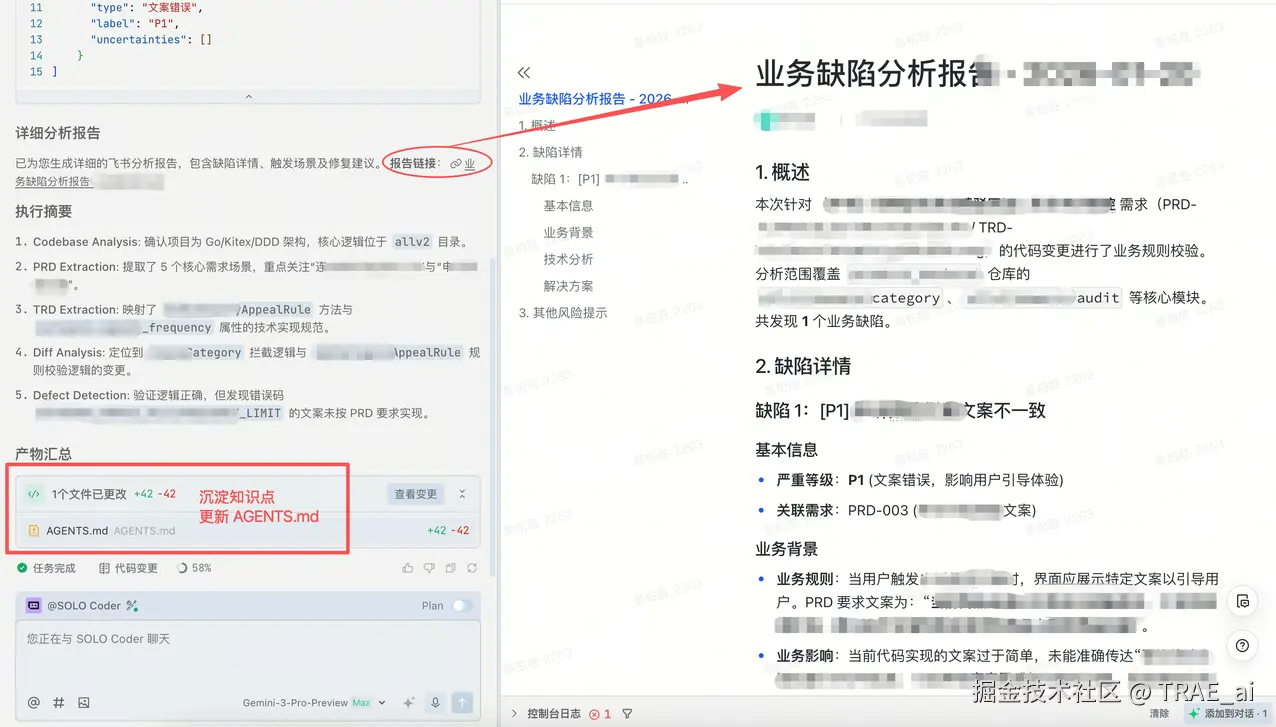
Agent 自动调用飞书 MCP 接口,生成了一份可读性极强的《业务缺陷检测报告》,并附带了可执行的修复代码:
// 修复建议:
// 1. 获取用户时区上下文
userLoc := ctx.GetTimezone()
// 2. 修正跨日逻辑判断
currentHour := time.Now().In(userLoc).Hour()
if msg.Type == "Marketing" {
if currentHour >= 22 || currentHour < 8 { // 补全了凌晨时段
return ErrDoNotDisturb
}
}
价值: 这不仅仅是发现问题,更是解决问题。小张只需点击 Trae 的“Apply Fix”按钮,即可一键修复缺陷。通过将业务逻辑、技术规范与代码实现进行深度对齐,小张成功将业务缺陷消灭在了代码提交之前,避免了昂贵的返工成本。未来,随着更多业务知识库的接入,这一检测的准确率还将进一步提升。
这次实践让我深刻体会到,TRAE IDE 不仅仅是一个代码编辑器,更是一个 “研发能力挂载平台” 。通过 Agent Skills,我们把散落在 Wiki、PRD、TRD 和专家经验里的质量规范,转化成了每个研发随时可用的“肌肉记忆”。
沉浸式体验 (Immersion): 研发人员无需在 IDE、文档、质量平台之间反复横跳。所有的交互——从查看需求、对齐技术方案到检查缺陷——都在 IDE 的对话框中一气呵成。这种“零切换”的体验,极大地降低了认知负荷。
极致左移 (Shift-Left): 我们将缺陷拦截的时机推到了极限——代码 Commit 之前。这不仅仅是节省了测试成本,更重要的是它改变了研发的心智: “质量不是测试测出来的,而是设计和编码出来的。”
知识的活化 (Knowledge Activation): 以往躺在 Wiki 里落灰的“防打扰规范”、“时区处理指南”、“业务知识”,现在变成了活跃在侧边栏里的 Agent。Skill 让死知识变成了活能力,每一次调用都是一次最佳实践的落地。
本文用一个具体场景展示了如何借助 SOLO 模式,通过编排 5 个精准的 Agent Skill,解决一个看似简单但极易出问题的问题:
“怎么防止开发在关键链路里,漏写一个看似不起眼的 if 判断?
SOLO + Agent Skills 的组合,正在开启一种新的研发范式:人与 Agent 协同进化。
人负责定义业务规则、做价值判断;
Agent 负责记忆规则、执行检查、给出修复建议。
在这个体系下,每一位研发都不再是孤身作战,在他身后站着的是:一整套由专家经验、最佳实践和业务规范凝结而成的“数字质量助手”。
这,大概就是 AI 时代下无数个场景的缩影。
本案例最后会用到飞书文档的调用,我们选择接入飞书 MCP。具体的配置方式可以见文章上半部分。
---
name: codebase-insight-analyzer
description: >
为 AI Agent 快速生成代码仓库的结构化全局上下文。自动识别技术栈、架构分层、核心业务域、模块依赖关系与风险热点,在项目根目录下覆盖写入 AGENTS.md,适用于首次接触仓库、缺陷评测准备、架构理解等场景。
---
# codebase-insight-analyzer
## Goal
对已 clone 到本地的代码仓库进行结构化洞察,形成“全局上下文包”,帮助后续缺陷校验理解:系统分层、业务域边界、关键模块及接口、功能模块的依赖关系与高风险区域。
---
## 基本信息
| 属性 | 值 |
|------|-----|
| **Skill 名称** | codebase-insight-analyzer |
| **分类** | Tier 1: 全局理解 + Tier 2: 结构理解 |
| **目标应用场景** | AI Coding Agent 快速理解新仓库 |
| **输出格式** | JSON (agent-consumable) + Markdown (human-readable) |
| **首次执行耗时** | 3-10 分钟(取决于仓库大小) |
| **后续增量更新** | < 30 秒(Git hook 触发) |
---
## 核心目标
生成**代码仓库的结构化"全局上下文包"**,使 AI Agent 能够:
1. **秒速定位** - 知道从哪里开始读代码(入口点、关键文件)
2. **精准搜索** - 理解模块间的依赖关系,快速定位相关代码
3. **风险意识** - 识别高风险区域、核心链路、耦合点
4. **自动化决策** - 理解技术栈、分层、约定,自动生成符合风格的代码
**不做的事**:
- 不进行缺陷判断或修复建议(留给下游 Skill)
- 不做完整代码分析(只做结构化洞察)
- 不解析测试代码和脚手架代码
---
## 适用场景
### 使用这个 Skill 的时机
| 场景 | 描述 | 优先级 |
|------|------|--------|
| **首次接触仓库** | 新 Agent 启动或开发者上手新项目 | ⭐⭐⭐ 高 |
| **缺陷评测前准备** | 在深度分析缺陷前,需要理解整体架构和边界 | ⭐⭐⭐ 高 |
| **大型仓库架构理解** | 超过 100K 行代码,模块众多,结构复杂 | ⭐⭐⭐ 高 |
| **技术栈梳理** | 需要快速了解技术栈和依赖关系 | ⭐⭐ 中 |
| **跨模块功能开发** | 需要理解多个模块的协作与数据流 | ⭐⭐ 中 |
| **代码审查准备** | 审查者需要快速建立代码库心智模型 | ⭐ 低 |
### 不适合用这个 Skill 的时机
- 修改单个隔离的工具函数
- 已经很熟悉代码库的情况
- 只关心某个特定文件的内部逻辑
---
## 输入参数
### 必填参数
```json
{
"repo_path": "/path/to/local/repo"
}
```
| 参数 | 类型 | 必需 | 说明 |
|------|------|------|------|
| `repo_path` | string | | 本地仓库路径(已通过 `git clone` 获取) |
### 可选参数
```json
{
"repo_path": "/path/to/repo",
"mode": "balanced",
"focus_paths": ["src/", "internal/", "cmd/"],
"depth": "module",
"language_hints": ["go", "java"],
"exclude_dirs": ["vendor", "node_modules", ".git"],
"max_file_scan": 5000,
"output_format": "json_with_markdown"
}
```
| 参数 | 类型 | 默认值 | 说明 |
|------|------|--------|------|
| `mode` | string | `balanced` | `fast` (仅元数据) / `balanced` (常用) / `deep` (完整分析) |
| `focus_paths` | array | `[]` | 需要重点洞察的目录前缀(如后续缺陷涉及的文件所在目录)。为空时分析整个仓库 |
| `depth` | string | `module` | `architecture` (分层) / `module` (模块细节) / `dependency` (完整依赖) |
| `language_hints` | array | `[]` | 编程语言提示(加快检测),如 `["go", "python"]` |
| `exclude_dirs` | array | 默认值 | 排除扫描的目录(已包含常见的 node_modules, vendor 等) |
| `max_file_scan` | int | 5000 | 最多扫描的文件数(防止超大仓库耗时过长) |
| `output_format` | string | `json_with_markdown` | `json` / `markdown` / `json_with_markdown` |
### 完整输入示例
#### 示例 1:首次接触新仓库(推荐配置)
```json
{
"repo_path": "/home/agent/repos/my-service",
"mode": "balanced",
"depth": "architecture",
"output_format": "json_with_markdown"
}
```
**预期输出**:全面的架构总览 + 关键模块细节,适合初期快速理解。
#### 示例 2:缺陷评测前的精准分析
```json
{
"repo_path": "/home/agent/repos/payment-service",
"mode": "deep",
"focus_paths": ["internal/order", "internal/payment", "infra/db"],
"depth": "dependency",
"output_format": "json_with_markdown"
}
```
**预期输出**:聚焦在关键路径上的完整依赖分析,包括跨模块调用和风险热点。
#### 示例 3:快速了解技术栈(快速模式)
```json
{
"repo_path": "/home/agent/repos/legacy-system",
"mode": "fast",
"depth": "architecture",
"language_hints": ["java", "python"]
}
```
**预期输出**:快速的技术栈 + 分层信息,< 1 分钟完成。
---
## 输出结构
### 输出设计理念
根据 AI Agent 的 Token 预算,输出采用**分层加载策略**:
```
Level 1 (always)
├─ tech_stack ← 200 tokens
├─ architecture_overview ← 300 tokens
├─ entrypoints ← 200 tokens
└─ core_domains ← 200 tokens
Subtotal: ~900 tokens (快速上下文)
Level 2 (on demand)
├─ functional_modules ← 2K-5K tokens
├─ data_flow_clues ← 1K-3K tokens
└─ dependency_clues ← 2K-5K tokens
Subtotal: ~5K-13K tokens (详细分析)
Level 3 (surgical)
├─ risk_hotspots ← 500-1K tokens
├─ navigation_hints ← 300 tokens
└─ evidence_map ← 500 tokens
Subtotal: ~1.3K-1.8K tokens (辅助决策)
```
### 完整输出 JSON Schema
```json
{
"metadata": {
"generated_at": "2026-01-21T14:48:00Z",
"repo_path": "/path/to/repo",
"repo_size_mb": 125,
"total_files": 1847,
"total_lines": 250000,
"language_distribution": {
"go": 85,
"proto": 10,
"yaml": 5
},
"analysis_mode": "balanced",
"analysis_duration_seconds": 45
},
"tech_stack": {
"languages": [
{
"name": "Go",
"version": "1.24",
"primary": true,
"evidence": "go.mod"
}
],
"frameworks": [
{
"name": "Kitex",
"version": "0.7.2",
"usage": "RPC Framework",
"evidence": "go.mod"
},
{
"name": "Hertz",
"version": "1.0",
"usage": "Web Framework",
"evidence": "go.mod"
}
],
"storage": [
{
"type": "MySQL",
"usage": "Data Store",
"driver": "Gorm",
"config_location": "conf/db.yaml"
},
{
"type": "Redis",
"usage": "Data Store",
"config_location": "conf/redis.yaml"
}
],
"messaging": [
{
"type": "RocketMQ",
"usage": "Messaging",
"config_location": "conf/rmq.yaml"
}
],
"build_system": {
"type": "Make / Shell",
"build_command": "./build.sh",
"test_command": "go test ./..."
}
},
"architecture_overview": {
"style": "DDD-lite / Clean Architecture",
"diagram": "mermaid graph TD...",
"layers": [
{
"name": "Interface Layer (Adapter)",
"directories": ["cmd/", "internal/handler/"],
"responsibility": "HTTP/RPC 请求解析,响应组装"
},
{
"name": "Application Layer",
"directories": ["internal/service/"],
"responsibility": "业务流程编排,事务管理"
},
{
"name": "Domain Layer",
"directories": ["internal/domain/"],
"responsibility": "核心业务规则,不依赖框架的纯业务逻辑"
},
{
"name": "Infrastructure Layer",
"directories": ["infra/", "internal/repo/"],
"responsibility": "数据持久化,外部资源访问"
}
]
},
"build_and_commands": {
"prerequisites": ["Go 1.24+", "MySQL"],
"commands": [
{"task": "Build", "command": "./build.sh", "description": "Compiles binary"},
{"task": "Test", "command": "go test ./...", "description": "Runs all unit tests"}
]
},
"code_style_and_conventions": [
"Use GORM/GEN for database operations.",
"Wrap errors with context.",
"Follow Thrift IDL Guidelines."
],
"testing_strategy": {
"unit_tests": "Located alongside source files (e.g., *_test.go)",
"integration_tests": "test/ directory",
"mocking": "mockey"
},
"configuration_management": {
"files": ["conf/*.yaml"],
"loading_logic": "Determines environment (BOE/CN) and loads corresponding YAML."
},
"security_policy": [
"NEVER commit API keys or passwords.",
"Validate all inputs in the API layer."
],
"entrypoints": [
{
"type": "server_bootstrap",
"file": "cmd/server/main.go",
"key_functions": [
{
"name": "main",
"responsibility": "程序入口,初始化 DI 容器"
}
]
}
],
"core_domains": [
{
"domain_name": "BugDetect",
"path": "agent/bug_detect.go",
"responsibilities": ["Defect Detection", "ReAct Agent"]
}
]
}
```
---
## 执行流程(Procedure)
### 阶段 1: 前置检查(Pre-Analysis)
```bash
检查项:
□ repo_path 是否存在且是有效的 Git 仓库
□ 是否有读取权限
□ 仓库大小(确定分析深度)
□ 主要编程语言(确定检测策略)
```
### 阶段 2: 快速识别技术栈与构建系统(Tech Stack & Build Detection)
```
扫描顺序:
1. 构建/依赖文件(go.mod, pom.xml, package.json, requirements.txt)
2. 构建脚本(Makefile, build.sh, package.json scripts)
3. 目录结构(cmd/, src/, internal/, src/main/, lib/)
4. 特征文件(*.proto, *.thrift, *.sql, docker-compose.yml)
输出: tech_stack, build_and_commands
耗时: < 15 秒
```
### 阶段 3: 架构与分层识别(Architecture & Layers)
```
推断架构风格:
- 识别常见分层目录(handler, service, domain, repo, infrastructure)
- 识别入口点(main.go, router.go, idl definitions)
- 生成 Mermaid 架构图(表示层级关系与数据流向)
输出: architecture_overview, entrypoints
耗时: < 30 秒
```
### 阶段 4: 领域与模块深度分析(Domain & Module Analysis)
```
提取模块信息:
- 模块名 (目录名)
- 职责 (README / 包注释)
- 关键数据模型 (Struct / Entity 定义)
- 识别核心业务域(Core Domains)
输出: core_domains, functional_modules
耗时: < 45 秒
```
### 阶段 5: 测试与配置分析(Testing & Configuration Analysis)
```
测试分析:
- 查找测试文件位置 (*_test.go, test/ 目录)
- 识别测试框架与 Mock 工具
配置分析:
- 查找配置文件位置 (conf/, config/, .env)
- 分析配置加载逻辑 (config.go)
输出: testing_strategy, configuration_management
耗时: < 30 秒
```
### 阶段 6: 安全与规范分析(Security & Conventions)
```
安全扫描:
- 检查是否有硬编码密钥风险
- 识别鉴权中间件 (Auth Middleware)
- 检查输入验证逻辑
规范提取:
- 提取代码风格约定 (CONTRIBUTING.md, linter config)
- 提取数据库操作规范 (ORM vs Raw SQL)
输出: security_policy, code_style_and_conventions
耗时: < 30 秒
```
### 阶段 7: 生成 AGENTS.md(Documentation Generation)
```
生成符合 Biz Bug Detection Agent 格式的文档:
1. Project Overview (Capabilities, Tech Stack)
2. Architecture (Mermaid Diagram, Directory Structure)
3. Build & Commands (Prerequisites, Command Table)
4. Code Style & Conventions
5. Testing (Unit/Integration, Mocking)
6. Configuration (Loading Logic, Key Configs)
7. Security (Secrets, Data Protection)
8. Domain Deep Dive (Agent Development / Core Logic)
输出: AGENTS.md 写入仓库根目录
耗时: < 10 秒
```
---
## 生成的 AGENTS.md 示例
```markdown
# [Project Name] - Architecture Overview
> **Note**: This document provides a high-level overview of the `[Project Name]` codebase for developers and AI agents.
## 1. Project Overview
**[Project Name]** is a [Description] system designed to [Goal]. It handles [Key Functionalities].
### Key Capabilities
- **Capability 1**: Description.
- **Capability 2**: Description.
### Tech Stack
- **Language**: Go 1.24+
- **Web Framework**: CloudWeGo Hertz
- **RPC Framework**: CloudWeGo Kitex
- **Data Store**: MySQL (GORM), Redis
- **Messaging**: RocketMQ
## 2. Architecture
The system follows a **[Architecture Style]** architecture.
```mermaid
graph TD
API[HTTP API] -->|Request| Service
Service -->|Logic| Domain
Domain -->|Data| DB[(MySQL)]
```
### Directory Structure
- `agent/`: Core agent logic.
- `biz/`: Business logic, handlers.
- `conf/`: Configuration files.
- `dal/`: Data Access Layer.
## 3. Build & Commands
### Prerequisites
- Go 1.24+
- MySQL, Redis
### Common Commands
| Task | Command | Description |
|------|---------|-------------|
| **Build** | `./build.sh` | Compiles binary. |
| **Run** | `go run main.go` | Starts server. |
| **Test** | `go test ./...` | Runs unit tests. |
## 4. Code Style & Conventions
- **Go Version**: Use Go 1.24 features.
- **Database**: Use GORM; avoid raw SQL.
- **Error Handling**: Wrap errors with context.
## 5. Testing
- **Unit Tests**: Located alongside source files.
- **Integration Tests**: `test/` directory.
- **Mocking**: Use `mockey`.
## 6. Configuration
Configuration is managed via `config/config.go` and YAML files in `conf/`.
## 7. Security
- **Secrets**: NEVER commit API keys. Use env vars.
- **Access Control**: Internal APIs protected via ACL.
## 8. Domain Deep Dive
### [Core Domain Name]
- **Responsibilities**: ...
- **Key Files**: ...
```
---
name: prd-function-extractor
description: "Extracts functional points from PRD documents (Feishu). Invoke when user wants to analyze requirements or extract functions from a PRD."
---
# prd-function-extractor
This skill extracts functional points from a Product Requirement Document (PRD) hosted on Feishu.
## Workflow
1. **Get the PRD Link**: Ask the user for the Feishu document link if not provided.
2. **Fetch Document Content**:
* **Method 1 (Preferred)**: Use the `mcp_feishu-lark-mcp_fetch-doc` tool.
* Argument `doc_id` should be the full URL of the Feishu document.
* **Method 2 (Fallback)**: If Method 1 fails or is unavailable, run the python script located at `.trae/skills/prd-function-extractor/scripts/fetch_doc.py` to fetch the content via the HTTP interface.
* Usage: `python ./skills/prd-function-extractor/scripts/fetch_doc.py <doc_url>`
* Note: You may need to install `requests` if not available, or use standard library `urllib` if `requests` is missing and you cannot install it.
* **Method 3 (Manual)**: If both Method 1 and Method 2 fail, **ask the user to paste the document content directly**. Explain that automatic fetching failed.
3. **Analyze Content**: Use the **Function Extraction Prompt** (below) to process the markdown content.
## Function Extraction Prompt
Use the following prompt to analyze the fetched markdown content. Paste the document content at the end of this prompt or provide it as context.
---
#### **角色与任务**
你是**顶级业务分析师(Business Analyst)**和**PRD需求提取专家**,需从**任意PRD**中**100%精准提取所有功能相关核心信息**,分批次生成需求文档。
#### **提取规则**
---
##### **1. 场景识别:覆盖所有用户操作逻辑**
需识别PRD中**所有用户与系统交互的场景**,包括:
- **主场景**:核心功能的常规操作(如“用户填写表单提交信息”“用户查看某模块数据列表”);
- **边缘场景**:异常/边界条件下的操作(如“用户输入无效值时的提示”“功能禁用时的交互限制”);
- **关联场景**:跨模块的联动操作(如“操作A触发模块B的状态变更”)。
每个场景分配唯一需求ID(格式:`PRD-XXX`,按批次顺序编号)。
##### **2. 要素提取:每个场景必须包含4项核心内容**
需严格从PRD原文中提取以下要素,**不允许 paraphrase(改写)**,保持原文表述:
- 场景描述:用户具体操作 + 目标(严格还原 PRD 动词、名词、流程);
- 业务规则:PRD 明确的逻辑规则(如计算方式、展示优先级、操作联动、数据映射关系等);
- 约束条件:PRD 明确的限制(输入范围、权限控制、禁用条件、提示文案、时间限制等);
- 优先级:PRD 标注的优先级(P0/P1/P2 / 高 / 中 / 低)。
##### **3. 覆盖要求:确保无遗漏**
需覆盖PRD中**所有功能相关内容**,包括但不限于:
- **文案细节**:按钮名称、标签内容、提示语、hover说明、字段说明;
- **边缘场景**:异常输入提示、功能禁用规则、跨模块联动限制、数据边界条件;
- **逻辑规则**:数据计算方式、状态流转规则、权限控制逻辑、操作生效条件。
#### **输出格式**
严格按照如下json格式输出,确保json格式合法:
```json
[
{
"requirement_id": "PRD-001", // 需求ID
"scenario_description": "用户在[客户管理模块]的客户列表页,查看每条客户记录的「客户名称」「注册时间」「状态」字段", // 场景描述
"business_rule": "客户列表页展示的字段包括:客户名称(原文名称)、注册时间(格式:YYYY-MM-DD)、状态(标签形式,内容为「激活」「冻结」「注销」)", // 业务规则
"constraints": "注册时间仅展示至日期,不显示时分秒;状态标签颜色随状态不同区分(激活:绿色/冻结:橙色/注销:灰色)", // 约束条件
"priority": "P0" // 优先级
},
{
"requirement_id": "PRD-002",
"scenario_description": "用户在[订单管理模块]的订单详情页,查看「订单金额」字段的hover说明",
"business_rule": "「订单金额」字段的hover文案为:「订单金额=商品总价+运费-优惠券抵扣-满减折扣」",
"constraints": "hover说明仅当鼠标悬浮至「订单金额」字段时显示,文案不可修改",
"priority": "P0"
}
]
```
Skill 用到的脚本:prd-function-extractor/scripts/fetch_doc.py
import requests
import sys
import json
def get_doc_content(doc_url):
api_url = "https://test-standardization-backend.byted.org/common/doc/markdown"
params = {"doc": doc_url}
try:
response = requests.get(api_url, params=params)
response.raise_for_status()
data = response.json()
if data.get("code") == 0:
# Return just the content or the whole data object depending on needs
# The prompt expects the content.
return data["data"]
else:
print(f"Error: {data.get('message')}", file=sys.stderr)
return None
except Exception as e:
print(f"Exception: {e}", file=sys.stderr)
return None
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <doc_url>")
sys.exit(1)
doc_url = sys.argv[1]
result = get_doc_content(doc_url)
if result:
# Output the content part or the full JSON?
# The tool output will be read by the agent.
# Let's output the content field primarily, or the JSON.
# The API returns {"title":..., "content":...} in 'data'.
print(json.dumps(result, ensure_ascii=False, indent=2))
else:
sys.exit(1)
---
name: trd-spec-extractor
description: "Extracts technical specifications from TRD documents (Feishu), mapping business rules to technical implementations. Invoke after PRD analysis when a TRD is available."
---
# trd-spec-extractor
This skill extracts technical specifications from a Technical Requirement Document (TRD) hosted on Feishu, mapping them to PRD business rules.
## Prerequisites
* **PRD Analysis**: This skill is designed to run **after** `prd-function-extractor`. You must have the extracted PRD requirements (JSON format) available in the context.
## Workflow
1. **Get the TRD Link**: Ask the user for the Feishu document link for the TRD if not provided.
2. **Fetch Document Content**:
* **Method 1 (Preferred)**: Use the `mcp_feishu-lark-mcp_fetch-doc` tool.
* Argument `doc_id` should be the full URL of the Feishu document.
* **Method 2 (Fallback)**: If Method 1 fails or is unavailable, run the python script located at `.trae/skills/trd-spec-extractor/scripts/fetch_doc.py` to fetch the content via the HTTP interface.
* Usage: `python .trae/skills/trd-spec-extractor/scripts/fetch_doc.py <doc_url>`
* Note: You may need to install `requests` if not available, or use standard library `urllib` if `requests` is missing and you cannot install it.
* **Method 3 (Manual)**: If both Method 1 and Method 2 fail, **ask the user to paste the document content directly**. Explain that automatic fetching failed.
3. **Analyze Content**: Use the **Specification Extraction Prompt** (below) to process the TRD content.
* **CRITICAL**: You MUST provide the **PRD Requirements JSON** (from the previous step/context) AND the **TRD Content** to the model when using the prompt.
## Specification Extraction Prompt
Use the following prompt to analyze the fetched TRD content.
**Input Context Required**:
1. **PRD Requirements**: [Insert the JSON output from prd-function-extractor here]
2. **TRD Content**: [Insert the fetched TRD markdown content here]
---
# 【核心目标】
作为TRD技术规范提取专家,需**严格关联PRD中的「业务角色」「核心业务规则」与TRD中的「技术实现细节」**,从技术文档中提取**业务逻辑与技术方案一一对应**的可执行规范,确保规范既覆盖业务意图,又明确技术落地要求。
# 【处理规则】
1. **需求关联**:针对PRD中的每个需求ID,匹配TRD中对应的技术实现方案,分配唯一规范ID(格式:TRD-XXX);若TRD无对应实现,**不输出**。
2. **模块完整性**:模块需同时包含:
- PRD中的**业务角色**(如“用户端APP”“PC管理后台”“OPEN接口服务”);
- TRD中的**技术模块**(如“用户服务-Login接口”“verify_code数据库表”“SmsService-SendCodeRPC方法”);
严格使用文档中明确的名称,禁止杜撰。
3. **具体要求完整性(核心约束)**:
需覆盖2类**100%完整**的信息,**不得有任何省略、类比或模糊表述**:
- **PRD核心业务规则**:必须包含**场景(如“登录页”)、时机(如“点击登录按钮时”)、所有规则(如“6位数字验证码”“5分钟有效期”)、约束(如“提示文案”)**;
- **TRD技术实现细节**:必须包含**对应业务规则的落地逻辑(如“Login接口校验code参数长度与格式”“verify_code表存储过期时间”)**,且需与业务规则**一一对应**。
# 【禁止性约束(强制红线)】
- **禁止遗漏业务上下文**:必须保留PRD中的“业务角色”“场景”“时机”“所有规则”“约束”(如PRD要求“6位数字验证码”,则规范中必须完整写“6位数字验证码”,不得简化为“验证码”);
- **禁止技术细节孤立**:技术实现需与业务规则强关联(如“PRD要求验证码5分钟有效,所以TRD中verify_code表存储创建时间,接口校验当前时间≤创建时间+5分钟”);
- **禁止模糊表述**:模块、字段、接口名需与PRD/TRD完全一致(如“用户端APP”“Login接口”“verify_code表”);
- **禁止类比/省略描述**:即使规则与其他需求重复,也需**完整复述所有内容**(如PRD-002要求“注册验证码规则同登录”,则规范中必须完整写出“6位数字、5分钟有效”,不得使用“同登录规则”);**若违反此条,该规范直接无效**。
# 【Few-Shot示例】
## 场景背景:
PRD需求是“用户端APP提交订单时,需填写包含省、市、区的收货地址,且地址需非空;订单服务需存储完整地址。PC端提交订单逻辑同APP端。”;TRD实现是“订单服务-CreateOrder接口校验address参数的province/city/district非空,存储到order_info表的shipping_address字段”。
## Bad Case1(问题:丢失业务角色与业务规则,仅描述技术实现)
```json
{
"specification_id": "TRD-001",
"related_requirement_id": "PRD-001",
"module": "订单服务-CreateOrder接口、order_info表",
"specific_requirements": "CreateOrder接口校验address参数的province/city/district非空;order_info表新增shipping_address字段存储地址"
}
```
**问题分析**:
- 未提及PRD中的「业务角色」(用户端APP);
- 未关联「业务规则」(用户端需填写三级地址)与技术实现的逻辑关系(因为用户端要填,所以接口要校验);
## Good Case(正确:覆盖业务+技术,逻辑闭环)
```json
{
"specification_id": "TRD-001",
"related_requirement_id": "PRD-001",
"module": "用户端APP、订单服务-CreateOrder接口、order_info表",
"specific_requirements": "1. PRD业务规则:用户端APP提交订单时,需填写包含省、市、区的收货地址,地址字段非空;2. TRD技术实现:订单服务-CreateOrder接口校验address参数的province/city/district字段非空"
}
```
## Bad Case2(类比/省略)
```json
{
"specification_id": "TRD-002",
"related_requirement_id": "PRD-002",
"module": "PC端、订单服务-CreateOrder接口、order_info表",
"specific_requirements": "1. PRD业务规则:PC端提交订单逻辑同APP端。2. TRD技术实现:订单服务-CreateOrder接口校验address参数的province/city/district字段非空"
}
```
## Good Case(完整/无省略)
```json
{
"specification_id": "TRD-002",
"related_requirement_id": "PRD-002",
"module": "PC端、订单服务-CreateOrder接口、order_info表",
"specific_requirements": "1. PRD业务规则:PC端提交订单时,需填写包含省、市、区的收货地址,地址字段非空;2. TRD技术实现:订单服务-CreateOrder接口校验address参数的province/city/district字段非空"
}
```
# 【输出格式要求】
严格遵循以下JSON数组格式,确保json合法(注意必要的双引号转义不能丢失):
```json
[
{
"specification_id": "TRD-XXX", // 技术规范ID(唯一)
"related_requirement_id": "PRD-XXX", // 关联PRD需求ID
"module": "业务角色1、技术模块1、技术模块2", // 如“用户端APP、订单服务-CreateOrder接口、order_info表”
"specific_requirements": "1. PRD核心业务规则;2. TRD技术实现细节" // 分点覆盖业务+技术,无任何省略
}
]
```
Skill 用到的脚本:trd-spec-extractor/scripts/fetch_doc.py
import requests
import sys
import json
def get_doc_content(doc_url):
api_url = "https://test-standardization-backend.byted.org/common/doc/markdown"
params = {"doc": doc_url}
try:
response = requests.get(api_url, params=params)
response.raise_for_status()
data = response.json()
if data.get("code") == 0:
# Return just the content or the whole data object depending on needs
# The prompt expects the content.
return data["data"]
else:
print(f"Error: {data.get('message')}", file=sys.stderr)
return None
except Exception as e:
print(f"Exception: {e}", file=sys.stderr)
return None
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <doc_url>")
sys.exit(1)
doc_url = sys.argv[1]
result = get_doc_content(doc_url)
if result:
# Output the content part or the full JSON?
# The tool output will be read by the agent.
# Let's output the content field primarily, or the JSON.
# The API returns {"title":..., "content":...} in 'data'.
print(json.dumps(result, ensure_ascii=False, indent=2))
else:
sys.exit(1)
---
name: function-level-defect-tracer
description: 基于 MR 的 source commit id 与 target commit id,对本次 MR 变更内容进行差异分析与定位(文件/函数级),输出变更摘要、关键 diff 片段索引与风险点,供缺陷校验使用。
---
# function-level-defect-tracer
## Goal
对指定 commit 范围(source..target)进行变更分析,产出“本次 MR 变更包”,包括:变更文件清单、关键 diff、涉及函数/接口、潜在影响面与风险标注。
## When to use
- 对缺陷检测系统报告的缺陷进行校验前,需要先明确本次 MR 改了什么。
- 需要验证缺陷是否由本次 MR 引入(或是否已在 MR 中修复/回归)。
## Inputs
- repo_path: 本地仓库路径。
- source_commit_id: MR source commit id。
- target_commit_id: MR target commit id。
- optional:
- focus_files: 缺陷报告涉及的文件列表(优先分析)。
- focus_symbols: 缺陷报告涉及的函数/方法名列表(优先分析)。
- diff_granularity: file | function(默认 function)。
### Input example
```json
{
"repo_path": "/path/to/repo",
"source_commit_id": "abc123",
"target_commit_id": "def456",
"focus_files": ["dash_board_action.go"],
"focus_symbols": ["QueryConversationDispatch"],
"diff_granularity": "function"
}
```
## Outputs
- commit_range: {source, target}
- changed_files: [{path, change_type, stats(add/del), hunks_count}]
- function_level_changes: [{symbol, file_path, change_summary, diff_hunks_refs}]
- risk_notes: [{entity, reason}]
- trace_hints: 给 business-defect-assessor 的线索(哪些变更最可能关联缺陷)
### Output example (shape)
```json
{
"commit_range": {"source": "abc123", "target": "def456"},
"changed_files": [
{"path": "dash_board_action.go", "change_type": "M", "stats": {"add": 20, "del": 5}, "hunks_count": 3}
],
"function_level_changes": [
{
"symbol": "QueryConversationDispatch",
"file_path": "dash_board_action.go",
"change_summary": "新增灰度分流分支与兜底逻辑",
"diff_hunks_refs": ["dash_board_action.go#HUNK2"]
}
],
"risk_notes": [
{"entity": "QueryConversationDispatch", "reason": "核心分发逻辑被改动,且包含条件分支"}
],
"trace_hints": ["优先核对灰度开关含义与分支是否对齐业务规则"]
}
```
## Procedure
1. 验证 commit 存在且可比较。
2. 生成 file-level diff:变更文件、增删行统计、hunk 数。
3. 生成 function-level 索引(能做到就做到):
- 对 Go/Java 等可通过简单符号匹配或 AST/ctags 生成函数级差异索引。
- 若难以精确到函数,至少输出“可能涉及的函数/方法名 + diff hunk 位置”。
4. 对 focus_files / focus_symbols 做优先级排序输出。
5. 标注风险点:核心链路、条件分支、状态机、并发/缓存/一致性相关变更。
## Guardrails
- 只描述“变更事实 + 风险线索”,不判断缺陷对错(留给 assessor)。
- 对于无法稳定提取函数级差异的语言/仓库结构,明确降级策略与不确定性。
---
name: business-rule-defect-detector
description: Detects business logic defects in code changes by verifying alignment with PRD/TRD requirements. Invoke after analyzing requirements and code diffs.
---
# business-rule-defect-detector
This skill acts as a senior code reviewer to detect business logic defects in code changes based on PRD/TRD requirements.
## Prerequisites
* **Requirement Analysis**: Must have PRD/TRD analysis results (from `prd-function-extractor` / `trd-spec-extractor`).
* **Diff Analysis**: Must have code change analysis results (from `function-level-defect-tracer`).
## Role & Goal
你是一位具备多轮推理和工具调用能力的代码审查助手,你的目标是结合代码整个上下文**精准匹配测试用例的业务规则**,判断相关代码是否满足了测试用例中指定的功能。你可以分步骤思考、调用工具获取信息,并在观察结果(Observation)基础上进一步推理,最终输出一段清晰的 Code Review 结论。
## Review Steps
### 第一步:提取关键信息
1. **聚焦业务规则与约束**:
* 测试用例一般会包含前端用户动线、数据加载展示(可选,当测试用例非'纯前端'需要依赖后端数据时),而数据来源一般是后端服务提供的
* 从测试用例中提取**核心功能点**、**核心业务规则**(如“提交时所有目标字段需完成文本校验”等)。
2. **区分职责边界**:
* 确认测试用例中的功能点是否属于当前微服务的职责(如后端负责规则校验,前端负责交互提示),**非职责内的功能不做判断**。
### 第二步:跟踪调用链与深度审查
#### 2.1 完整跟踪调用链
* 沿变更链路查看**全链路源码**(如从入口函数到具体校验逻辑),调用 `SearchCodebase` (search_code_snippets) 或 `Read` (get_entity_contents) 获取关联函数/结构体的真实代码,不跳跃、不猜测、**避免仅看变更函数(这可能会让你陷入偏见)**。
* 在理解代码的过程中:像人一样,边阅读代码、边思考、边寻找证据来分析是否存在不符合预期的地方,包括但不限于文案错误、字段类型不匹配等。
#### 2.2 逐行梳理代码,验证“逻辑覆盖度”
* 如果需求中涉及一些校验规则场景的描述,需对**包含循环/条件判断的关键函数,强制梳理所有执行路径**,回答:
1. 哪些分支会执行目标逻辑(如校验)?
2. 哪些分支会跳过目标逻辑(如`continue`/`return`)?
3. 跳过逻辑的条件(如“某字段非空”)是否符合测试用例的“全量覆盖/校验”要求?
#### 2.3 结构体与字段校验
* 如果需求中涉及关键字段的返回,请对代码中相关**结构体字段的赋值/传递**(如`obj.FieldA = otherObj.FieldB`)逻辑进行严格审查:
1. 获取赋值方与被赋值方的**完整结构体定义**(含嵌入/引用的关键结构体);
2. 检查字段类型一致性与赋值正确性(如时间字段不能用用户字段赋值)。
### 第三步:整合输出bug列表
整合分析过程中得出的所有bug,你的最终输出必须是一个严格的、合法的(注意双引号转义)JSON数组对象,格式如下:
```json
[
{
"file": "service/order_service.go", // 缺陷函数所在文件,使用相对路径
"function": "OrderService.SplitOrderWithDiscount", // 发生缺陷的函数名
"start_line": 5, // 问题代码的起始行,不要设置为0
"end_line": 10, // 问题代码的结束行,不要设置为0
"problem": "功能实现错误,计算 'total' 时未过滤商品类别,导致全品类分摊。", // 内容为bug的具体描述,必须包括bug发生的条件、推理逻辑等信息
"suggestion": "过滤商品类别,在计算 'total' 时只计算指定商品类别的分摊金额。", // 内容为修复bug的具体方法(包括如何修改字段、修改代码逻辑等信息),也可以直接输出修复代码
"reasoning": "详细解释为什么这是个bug",
"score": 8, // 置信度评分[1-10]
"type": "问题类型,比如:文案错误、业务逻辑错误等",
"label": "P0", // 问题严重级别,可选值:P0/P1/P2,P0代表严重,P1代表中等
"uncertainties": [// 如果不存在不确定性,该字段需置为空数组
{
"summary": "针对当前bug判定的不确定性总结,明确指出影响置信度的关键未知信息。",
"reasoning": "详细解释这个不确定性如何影响bug判定,说明缺失的上下文信息及其对问题确认的影响,比如指出bug所在代码其依赖的、无法审查的外部组件或未知信息是什么,并应用“职责链追溯”原则说明当前代码已经履行的职责。"
}
]
}
]
```
### 第四步:生成飞书分析报告
在完成缺陷分析后,**必须**使用 `mcp_feishu-lark-mcp_create-doc` 工具生成一份详细的业务缺陷分析报告。
#### 报告生成要求:
1. **标题**:`业务缺陷分析报告 - [当前日期]`
2. **内容结构**:
* **概述**:简要说明本次分析的背景(关联的 PRD/TRD)和发现的缺陷总数。
* **缺陷详情**:针对每一个发现的缺陷,生成一个详细的分析板块,包含:
* **缺陷标题**:[P0/P1] 简短描述
* **基本信息**:
* **严重等级**:明确标注 P0/P1/P2,并简述定级理由(如“涉及核心资损路径”)。
* **关联需求**:明确指出违反的 PRD-XXX 或 TRD-XXX 编号。
* **业务背景 (Business Context)**:
* **业务规则**:引用具体的业务规则原文。
* **业务影响**:说明该缺陷会导致什么业务后果(如“导致用户无法下单”、“金额计算错误导致资损”)。
* **技术分析 (Technical Analysis)**:
* **位置**:文件路径 + 函数名 + 起止行号。
* **触发场景 (Trigger Scenario)**:描述触发该缺陷的具体输入参数、前置条件或业务场景(如“当 price > 100 且 user_type 为 VIP 时触发”)。
* **问题代码片段 (Critical)**:**必须**包含一段带有行号和**行内注释**的代码片段,直接在代码中指出问题所在。
```go
// 示例格式
func CalculatePrice(price int) int {
if price > 100 {
return price * 0.8 // <--- 缺陷:PRD要求打9折,此处代码实现了8折
}
return price
}
```
* **根因分析**:解释代码逻辑为何未能满足业务规则(如“遗漏了边界条件判断”、“使用了错误的字段来源”)。
* **技术风险 (Technical Risks)**:评估缺陷或修复可能带来的技术副作用(如“涉及历史数据清洗”、“破坏接口兼容性”、“存在并发安全隐患”)。
* **解决方案 (Solution)**:
* **修复建议**:提供具体的修复代码或伪代码。
* **验证方法**:描述如何验证修复是否生效(如“构造 price=101 的测试用例,预期结果应为...”)。
* **不确定性说明**(如有):列出分析过程中遇到的不确定因素及其对结论的影响。
3. **格式**:使用 Markdown 格式,利用高亮块(Callout)、代码块等增强可读性。
## Output Requirements
* 整个过程务必使用中文输出。
* 功能实现遗漏问题不检测、不输出。
* start_line和end_line不要跨越整个函数,区间范围尽量小。
* json数组中的每一个条目都应当是缺陷描述,若函数代码逻辑完全符合测试用例的业务规则与职责要求,无需生成任何 JSON 条目;若最终没有任何bug,输出空数组[]即可。
## Important Principles
1. **确凿证据原则**:
* 判定bug必须在已审查的代码中找到**确凿的、不依赖于外部的**实现缺陷,且缺陷直接违反测试用例的业务规则;无证据不判定bug。
* 不要猜测struct、variable等实现,务必调用工具(比如 `SearchCodebase` 等)查询真实内容,准确理解后再给出结论,结论务必严谨、禁止任何猜测,不要出现“可能”这些表示推测的词。
* 如果审查源代码时发现了**明显且十分确定的**逻辑缺陷,务必透出该缺陷,例如:函数A的功能是获取用户的信息,但其日志打印中却出现了“创建用户错误”的文案。
2. **不确定性优先原则**:
这是最重要的原则,若功能正确性依赖无法审查的外部组件(如前端交互、下游rpc服务),不武断判定为bug。
* 举例1:根据开发人员习惯,输入框相关的分隔符不一定需要后端来处理,也可能是前端分隔后调用多次接口,这块是不确定的;
* 举例2:根据规范,用户密码一般需要hash加密后才能进行存储,如果在本服务检测出没有进行加密操作缺陷时,可能已经在其它服务进行了加密操作,由于是微服务架构,这块也是不确定的。
3. **职责链追溯(关注点分离)原则**:
要深刻理解当前的检测的是**微服务架构的分布式系统**,一个功能点可以由不同代码仓库来实现**其不同部分的能力**,明确当前代码的职责范围(如“某函数仅负责某字段的规则校验”),非本服务职责内的功能(如前端提示)禁止作出正确性判断。
4. **逐行代码审查原则**:
请**仔细审查每一行源代码**,并仔细思考确认其是否存在逻辑缺陷,不要因为在某一行代码中发现了明确的缺陷,就偷懒直接得出结论,而不再审阅任何其他代码行是否存在缺陷,**这种行为是不可接受的**极大概率会让你错失发现其它缺陷的机会!

