山水画廊
70.10M · 2026-04-12

tid表示一行数据在数据页上的逻辑地址,通过block id和offset来定义一个page内具体数据位置。定义如下:
struct ItemPointerData
{
BlockIdData blkid; // 页号, u32类型
OffsetNumber posid;// 业内slotid, u16类型
}
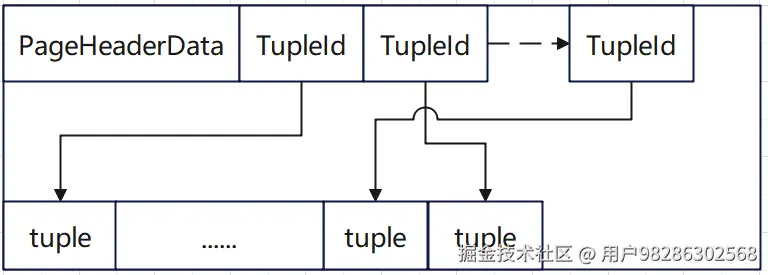
pg修改行数据时,保留旧行,并插入新行。每个事务都有唯一的事务id称为xid。
每行数据称为一个元组tuple,行头包含四个属性和一些标志位(行头总共有20字节,存储开销大,oracle只有3字节):
每个事务开启时,获取一个32bit的xid值,修改数据时,会创建新的元组记录xid到xmin中,并且写入到表数据中(新旧元组同时存在)。并标记老元组。
伪码示例
create table t1(c1 int, c2 int);
create index idx1(t1.c2);
insert into t1 values(1,2);
insert into t1 values(2,3);
#主表行信息:
ctid xmin xmax t_ctid data
(0,1) 100 0 (0,1) [1 2]
(0,2) 100 0 (0,2) [2 3]
#执行delete删除第二行:delete from t1 where c1=2
#查询主表只会返回一行数据,但是存储的真实行数没有变化,只是将xmax更改为delete语句对应的xid:200,行本身不会真的删除
ctid xmin xmax t_ctid data
(0,1) 100 0 (0,1) [1 2]
(0,2) 100 200 (0,2) [2 3]
#执行update语句更新第一行:update t1 set c2 = 5 where c1=1
#pg会拷贝第一行数据生成一个新的tuple, 然后更新old tuple的xmax和t_ctid, 来和new tuple链接起来
ctid xmin xmax t_ctid data
(0,1) 100 300 (0,3) [1 2]
(0,2) 100 200 (0,2) [2 3]
(0,3) 300 0 (0,3) [1 5]
#执行查询语句时, 会根据版本号判断返回第一行还是第三行给客户端
#由于c2列上存在索引,上述操作也会影响到索引表,索引表数据也会修改,和主表一样不会被“delete”掉;
#pg的索引表没有多版本概念,而是借用主表的多版本来找到“可见”的最新行;因此索引表的tuple没有xmin/xmax等列;
#索引表的tuple通过htid列来关联上主表的tuple;
#更新主表索引列时,索引表也会做相应的修改;
#更新主表非索引列时,索引表不会做修改,通过上面介绍的版本链来找到最新tuple(HOT机制:heap-only tuple);
#可以看出pg的多版本会很容易导致磁盘空间膨胀,需要vacuum操作来释放磁盘空间

