

未感染者模拟器
62.73M · 2026-04-13

@[toc]
把 Oracle 换成金仓(KingbaseES),大家第一反应往往是“兼容性到底行不行”。但真到项目里,最要命的不是“能不能跑”,而是“怎么稳稳交付”。说白了:兼容性帮你少改代码,不会替你把项目做完。所以我习惯先把替换拆成四件事:
手册里对 Oracle 兼容覆盖面写得很细:在 Oracle 模式下,数据类型、伪列、DML/DQL、过程化语言、触发器、动态 SQL 这些常见能力都在兼容范围里,连 DBLink 这种偏“工程向”的能力也给到了。这篇文章我就按“现场真的会踩”的路子来写:先把数据类型落稳,再把过程/函数跑通,最后把 ROWNUM、CONNECT BY、DBLINK 这些高频点用可执行的方式验证一遍。
flowchart TD
A[源库盘点<br/>对象/SQL/数据量/依赖] --> B[问题词归类<br/>类型/语法/过程/运维]
B --> C[目标库准备<br/>Oracle模式实例+参数基线]
C --> D[结构迁移<br/>schema/表/索引/分区/序列]
D --> E[数据迁移<br/>全量->校验->增量窗口]
E --> F[SQL改写与兼容验证<br/>ROWNUM/CONNECT BY/外连接/包]
F --> G[性能回归<br/>执行计划/索引/统计信息]
G --> H[上线与回滚预案<br/>灰度/双写/对账]
我不太建议一上来就“全量自动迁”。更稳的做法是先把风险收敛:挑一个模块或一组核心表,把类型、过程、慢 SQL 这三件事跑通,手里有了可复用的套路再扩面。
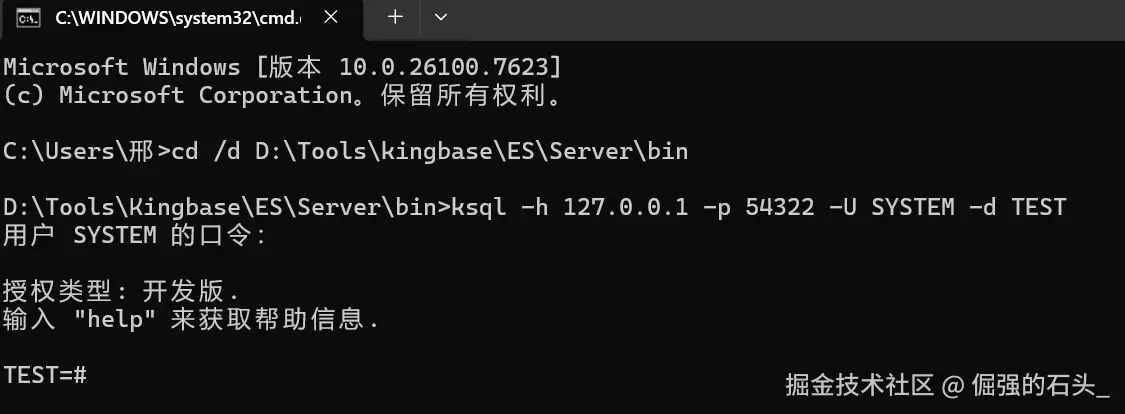
文章环境是 Windows 且在 ksql 上操作,下面所有演示默认满足:
ksql如果你的环境这一步就卡住了(比如端口不通、服务没起来、ksql 连不上),我之前写过一篇从安装到连通性验证的笔记,按步骤走基本不会翻车:
Windows 安装 KingbaseES V9R1C10 与 Oracle 兼容特性实战
概念解释我就不展开了,先用能跑通的方式把环境确认下来:只要你在 ksql 里把几个关键语法跑起来,后面所有实操才有意义。
ksql -h 127.0.0.1 -p 54321 -U system -d test
端口这块按你的实例来,我这边 Oracle 兼容版用的是 54322,所以截图里会看到 54322。
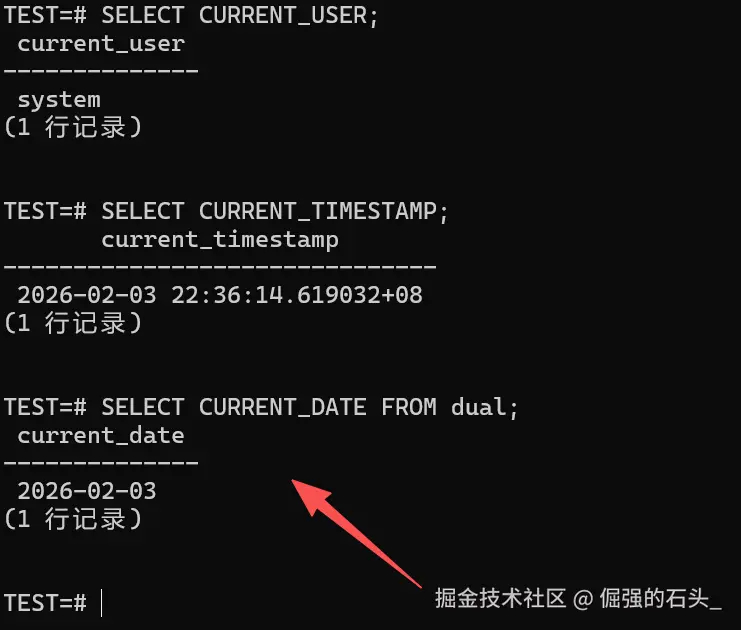
进到 test=# 之后,先做三件事:
SELECT CURRENT_USER;
SELECT CURRENT_TIMESTAMP;
-- Oracle 习惯的 dual 伪表(能跑通,基本说明你在 Oracle 语义环境里)
SELECT CURRENT_DATE FROM dual;
如果你接下来还能跑通 ROWNUM 和 CONNECT BY,基本可以认为“Oracle 迁移的高频语法”处在可验证范围内(第 6 章会给例子)。
类型映射这事,最容易被“建表不报错”给骗了。表是建起来了没错,但语义一旦偏了,后面就是慢慢对账、慢慢掉坑。真实项目里,类型风险我基本都栽在这三类上:
KingbaseES 的手册里有类型对照表(比如 numeric/number 对 Oracle NUMBER 的对应关系等)我自己在项目里常用的“落地映射建议”大概是这样:
| Oracle 常见类型 | 迁移落地建议(KingbaseES Oracle 模式) | 我会额外检查的点 |
|---|---|---|
| NUMBER(p,s) | 优先保持为 NUMBER(p,s) / NUMERIC(p,s) | 金额字段是否存在隐含精度扩展 |
| VARCHAR2(n) | VARCHAR(n) | 字段长度边界、是否依赖空串/空值差异 |
| CHAR(n) | CHAR(n) | 尾部空格比较规则 |
| DATE | DATE(Oracle 语义环境下更贴近原用法) | 是否有“只存日期不存时间”的约定 |
| TIMESTAMP | TIMESTAMP | 时区列是否需要 TIMESTAMP WITH TIME ZONE |
| CLOB/NCLOB | CLOB/NCLOB | 大字段更新是否走 DBMS_LOB 路线 |
| BLOB | BLOB | 事务与定位器用法 |
我自己的经验是:别在迁移第一天就“顺手把 NUMBER 全改成 INT”。你省下来的那点存储空间,后面很容易以“线上对账差 0.01”的形式加倍还你。
下面这套脚本可以直接在 ksql 里执行:建表、建索引、建序列、建分区表、插数据。一口气跑完,后面第 6、7、8 章的兼容验证和性能定位就能顺着做下去。
-- 清理(如存在)
DROP TABLE IF EXISTS t_order_item;
DROP TABLE IF EXISTS t_order;
DROP TABLE IF EXISTS t_order_audit;
DROP SEQUENCE IF EXISTS seq_order_id;
-- 序列(Oracle项目里常见:主键来自 sequence)
CREATE SEQUENCE seq_order_id START WITH 100001 INCREMENT BY 1;
-- 订单主表:按下单时间做范围分区(示例:按月)
CREATE TABLE t_order (
order_id NUMBER(12,0) NOT NULL,
customer_id NUMBER(12,0) NOT NULL,
order_time TIMESTAMP NOT NULL,
status VARCHAR(20) NOT NULL,
remark VARCHAR(200),
total_amount NUMBER(12,2) DEFAULT 0 NOT NULL,
CONSTRAINT pk_t_order PRIMARY KEY (order_id)
)
PARTITION BY RANGE (order_time)
(
PARTITION p202601 VALUES LESS THAN (TO_DATE('2026-02-01', 'YYYY-MM-DD')),
PARTITION p202602 VALUES LESS THAN (TO_DATE('2026-03-01', 'YYYY-MM-DD'))
);
-- 明细表
CREATE TABLE t_order_item (
item_id NUMBER(12,0) NOT NULL,
order_id NUMBER(12,0) NOT NULL,
sku VARCHAR(32) NOT NULL,
qty NUMBER(12,0) NOT NULL,
unit_price NUMBER(12,2) NOT NULL,
CONSTRAINT pk_t_order_item PRIMARY KEY (item_id)
);
CREATE INDEX idx_t_order_item_order_id ON t_order_item(order_id);
CREATE INDEX idx_t_order_customer_time ON t_order(customer_id, order_time);
-- 审计表(演示自治事务/日志)
CREATE TABLE t_order_audit (
audit_id NUMBER(12,0) NOT NULL,
order_id NUMBER(12,0),
action VARCHAR(30) NOT NULL,
action_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
detail VARCHAR(200),
CONSTRAINT pk_t_order_audit PRIMARY KEY (audit_id)
);
CREATE SEQUENCE seq_audit_id START WITH 1 INCREMENT BY 1;
-- 插入一些订单
INSERT INTO t_order(order_id, customer_id, order_time, status, remark, total_amount)
VALUES (seq_order_id.NEXTVAL, 2001, TO_TIMESTAMP('2026-01-15 10:12:00','YYYY-MM-DD HH24:MI:SS'), 'NEW', NULL, 0);
INSERT INTO t_order(order_id, customer_id, order_time, status, remark, total_amount)
VALUES (seq_order_id.NEXTVAL, 2002, TO_TIMESTAMP('2026-02-03 09:45:10','YYYY-MM-DD HH24:MI:SS'), 'PAID', '年度合同首单', 0);
-- 插入明细(手工写几条,后面也会演示用 CONNECT BY 批量造数)
INSERT INTO t_order_item(item_id, order_id, sku, qty, unit_price)
SELECT 1, (SELECT MIN(order_id) FROM t_order), 'SKU-001', 2, 99.50 FROM dual;
INSERT INTO t_order_item(item_id, order_id, sku, qty, unit_price)
SELECT 2, (SELECT MIN(order_id) FROM t_order), 'SKU-002', 1, 199.00 FROM dual;
INSERT INTO t_order_item(item_id, order_id, sku, qty, unit_price)
SELECT 3, (SELECT MAX(order_id) FROM t_order), 'SKU-003', 3, 39.90 FROM dual;
COMMIT;
验证一下对象是否都在:
SELECT COUNT(*) AS order_cnt FROM t_order;
SELECT COUNT(*) AS item_cnt FROM t_order_item;
ROWNUM 伪列是为了兼容 Oracle 而加的,手册里也专门提醒了一个经典坑:带 ORDER BY 的时候,ROWNUM 的结果会受取数顺序影响
在项目里我一般这么写 Top-N:
-- 先排序,再截断
SELECT *
FROM (
SELECT order_id, customer_id, order_time, total_amount
FROM t_order
ORDER BY order_time DESC
)
WHERE ROWNUM <= 10;
如果你更偏标准写法,也可以直接用 ORDER BY ... LIMIT ...。但在迁移阶段,我通常先求“老 SQL 能稳定跑”,等核心链路稳了,再慢慢把写法往更标准的方向收敛。
层次查询这块,我更关心的是“能不能把老逻辑原样接住”。手册里也写得比较明确:层次查询用于父子关系数据的层次返回,KingbaseES 与 Oracle 都支持,语义上是兼容的
下面用一个组织结构做演示(同时把“造测试数据”的方法也带上):
DROP TABLE IF EXISTS t_dept;
CREATE TABLE t_dept(
dept_id NUMBER(12,0) PRIMARY KEY,
parent_id NUMBER(12,0),
dept_name VARCHAR(50) NOT NULL
);
INSERT INTO t_dept VALUES (1, NULL, '总部');
INSERT INTO t_dept VALUES (2, 1, '研发中心');
INSERT INTO t_dept VALUES (3, 1, '销售中心');
INSERT INTO t_dept VALUES (4, 2, '平台组');
INSERT INTO t_dept VALUES (5, 2, '应用组');
COMMIT;
-- 层次查询:从总部开始展开
SELECT
LPAD(' ', (LEVEL-1)*2) || dept_name AS dept_tree,
dept_id,
parent_id,
LEVEL
FROM t_dept
START WITH dept_id = 1
CONNECT BY PRIOR dept_id = parent_id
ORDER SIBLINGS BY dept_id;
迁移项目里我会专门加两类用例,提前把隐患揪出来:
在 Oracle 模式下,KingbaseES 的兼容能力中包含 DBLink 这类高级能力,官网文章里也给了 DBLink 在 Oracle 兼容模式下实现跨库实时访问/同步的思路
我在项目里会先问一句:你要的是“跨库查询”还是“跨库同步”。这会影响你是把它当作运行时依赖,还是把它当作数据集成链路的一环。
下面给一个“能读懂也好改”的例子(远端连接信息按你环境替换):
-- 示例:创建数据库链接(语法风格与 Oracle 接近)
-- 具体参数与权限要求以你版本的手册/规范为准
CREATE DATABASE LINK lk_remote_finance
CONNECT TO remote_user IDENTIFIED BY "remote_password"
USING '192.168.10.20:1521/ORCL';
-- 使用方式(示意):通过 @dblink 访问远端对象
SELECT * FROM remote_schema.remote_table@lk_remote_finance WHERE ROWNUM <= 5;
我的工程建议是:
在 Oracle 模式下,过程化语言语法基础、静态/动态 SQL、存储过程/函数、匿名块、触发器这些能力都覆盖了。我在迁移里更喜欢走“小步快跑”:先挑一个低耦合、能验证闭环的过程跑通(最好带事务、日志、异常),再把迁移规范固化下来,然后再规模化推进。
下面这个过程做两件事:
先开输出:
SET SERVEROUTPUT ON;
创建过程:
CREATE OR REPLACE PROCEDURE p_recalc_order_total(p_order_id NUMBER)
IS
v_total NUMBER(12,2);
PRAGMA AUTONOMOUS_TRANSACTION;
v_audit_id NUMBER(12,0);
BEGIN
SELECT COALESCE(SUM(qty * unit_price), 0)
INTO v_total
FROM t_order_item
WHERE order_id = p_order_id;
UPDATE t_order
SET total_amount = v_total
WHERE order_id = p_order_id;
SELECT seq_audit_id.NEXTVAL INTO v_audit_id FROM dual;
INSERT INTO t_order_audit(audit_id, order_id, action, detail)
VALUES (v_audit_id, p_order_id, 'RECALC_TOTAL', 'total=' || v_total);
COMMIT;
DBMS_OUTPUT.PUT_LINE('订单' || p_order_id || '已回写总金额=' || v_total);
END;
/
执行验证(你可以把订单号换成你实际生成的):
SELECT order_id, total_amount FROM t_order ORDER BY order_id;
BEGIN
p_recalc_order_total((SELECT MIN(order_id) FROM t_order));
END;
/
SELECT order_id, total_amount FROM t_order ORDER BY order_id;
SELECT * FROM t_order_audit ORDER BY audit_id;
迁移项目里我会在这一层加两类断言:
这类代码在报表、批处理里很常见,迁移验证时我会用它来确认“游标控制流是不是一致”:
DECLARE
CURSOR c_orders IS
SELECT order_id, customer_id
FROM t_order
ORDER BY order_id;
v_order_id t_order.order_id%TYPE;
v_customer_id t_order.customer_id%TYPE;
BEGIN
OPEN c_orders;
LOOP
FETCH c_orders INTO v_order_id, v_customer_id;
EXIT WHEN c_orders%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('order_id=' || v_order_id || ', customer=' || v_customer_id);
END LOOP;
DBMS_OUTPUT.PUT_LINE('rows=' || c_orders%ROWCOUNT);
CLOSE c_orders;
END;
/
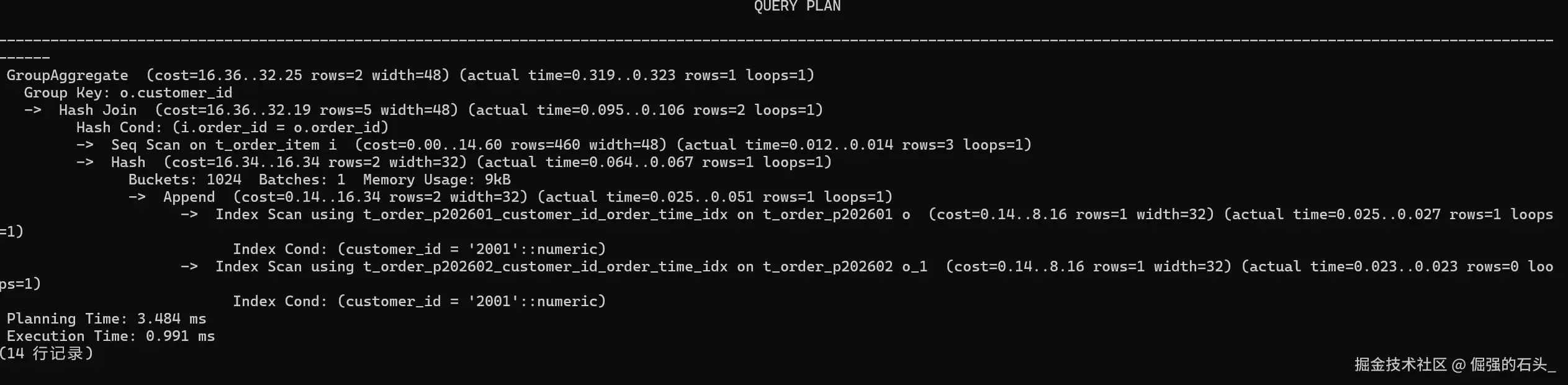
替换项目里,“慢”本身其实没那么可怕,真正难受的是:线上报了慢 SQL,你盯着 SQL 文本看半天,还是不知道该从哪里下手。我的经验很朴素:只要你能稳定拿到执行计划(最好带实际执行耗时)、看得懂索引有没有用上、分区有没有裁剪到位,调优就不会变成玄学。
EXPLAIN ANALYZE
SELECT
o.customer_id,
SUM(i.qty * i.unit_price) AS amt
FROM t_order o
JOIN t_order_item i ON i.order_id = o.order_id
WHERE o.customer_id = 2001
GROUP BY o.customer_id;
这条 SQL 我跑出来的计划里,有几个细节挺“对味”的
t_order 是分区表,所以计划里出现了 Append,而且两条分区分别走了各自的索引扫描:t_order_p202601_customer_id_order_time_idx 和 t_order_p202602_customer_id_order_time_idx。这点很关键,它说明按 customer_id = 2001 的过滤条件,优化器确实愿意用索引去“定位少量数据”,而不是把整张表扫一遍。t_order_item 这边是 Seq Scan,别看到顺序扫描就慌。这里我的明细表就几行数据,顺扫反而更省事。真实项目里如果明细表很大,那就要盯紧:是不是缺索引、或者 join 条件写法导致索引用不上。Hash Join + GroupAggregate,而且 Planning Time 大概 3.484 ms、Execution Time 大概 0.991 ms。对我这种“为了验证链路是否跑通”的小数据集来说,这个量级就够了;到大数据量时,我反而更关注节点类型有没有跑偏(比如该走索引却变成全表扫、该裁剪分区却全分区扫描)。很多 Oracle 项目里 HINT 用得特别重,这在迁移阶段很正常:你得先把核心链路“钉住”,别让执行计划飘来飘去。我的用法是:先拿 HINT 做一个对照实验,确认它在这个版本/这个写法下确实生效,再决定要不要保留到上线阶段(能不长期背着就不背着)
你可以这样做一个“对照实验”:
EXPLAIN ANALYZE
SELECT /*+ INDEX(t_order idx_t_order_customer_time) */
order_id, order_time, total_amount
FROM t_order
WHERE customer_id = 2001
ORDER BY order_time DESC;
结果其实很能说明问题:它直接走了 Index Scan Backward,而且同样是按分区做 Append,计划里没出现额外的 Sort 节点。对 ORDER BY order_time DESC 这种查询来说,这通常意味着索引顺序刚好能满足排序需求,优化器就省掉了排序开销。Planning Time 大概 2.230 ms、Execution Time 大概 0.116 ms,至少在这个数据集下,路径是清晰且稳定的。
所以我的建议还是那句话:迁移早期用 HINT 兜住“稳定可控”没问题,但后面要尽量把 SQL 和索引配合好,让优化器自己也能选到这条路。否则你会发现:业务一扩表、统计信息一变化,HINT 可能反而成了隐患。
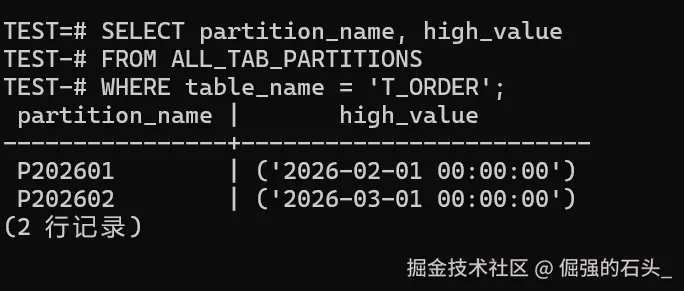
分区这块我一般不靠“感觉”,而是先查一遍分区边界是不是你以为的那样。比如下面这条查询,能直接把 T_ORDER 的分区名和上界拉出来:
SELECT partition_name, high_value
FROM ALL_TAB_PARTITIONS
WHERE table_name = 'T_ORDER';
从图中结果看,P202601 和 P202602 的 high_value 分别是 2026-02-01 00:00:00、2026-03-01 00:00:00,跟我们建表时按月切分的预期一致。确认了这个,再谈“分区裁剪”才有意义。
调优时我通常先做两件事:

