以观书法
108.85M · 2026-02-05

在大模型微调(SFT)的世界里,过拟合就像一个潜伏的隐形杀手。当70B参数的巨无霸模型遇上仅10万条的训练数据,会发生什么?没错,模型会在极短时间内将训练集"倒背如流",然后——灾难开始了。
传统机器学习中,过拟合表现相对简单。但在大模型领域,我们常遇到更复杂的**双重下降(Double Descent)**现象:随着训练继续,测试误差先降后升,随后又神奇地再次下降。在SFT这种"小样本、大参数"场景下,过拟合会表现为:
# 典型过拟合的表现
if training_loss.approaches_zero() and validation_loss.rising():
print("️ 警告:模型正在死记硬背训练数据!")
print(" 具体症状:")
print("- 对训练集prompt的轻微变化极度敏感")
print("- 生成内容陷入重复循环")
print("- 多样性指标(diversity score)骤降50%+")
面对过拟合,工程师们的第一反应往往是这些传统方法,但它们在大模型领域往往水土不服:
| 方法 | 传统效果 | LLM SFT中问题 |
| Dropout | 破坏Flash Attention优化,训练速度下降40%+ | |
| Early Stopping | 生成式评测成本太高,无法频繁验证 | |
| Weight Decay | 难以精准控制,容易同时削弱模型能力 | |
| NEFTune | 噪声参数难调,容易破坏语义结构 |
表:传统 正则化 方法在 大模型 SFT 场景中的局限性
作为向量感知团队推出的智能训练框架,Y-Trainer通过NLIRG算法(非线性学习强度调节算法)对过拟合进行精准狙击。这不是简单的正则化,而是一场Token级别的精准手术。
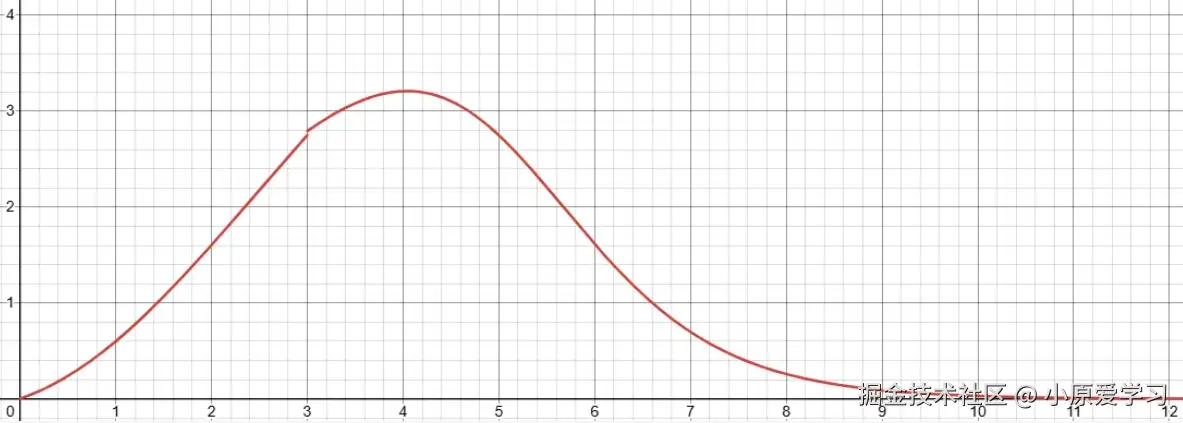
NLIRG的核心在于实时监测每个token的损失值,并根据预设曲线动态调整梯度强度:
def dynamic_sigmoid_batch(losses, max_lr=1.0, x0=1.2, min_lr=5e-8, k=1.7):
"""
NLIRG核心算法:基于损失值的动态权重计算
损失区间划分策略:
- 低损失区间(loss≤1.45):削减梯度,防止过拟合
- 中等损失区间(1.45<loss<6.6):增强梯度,加速学习
- 高损失区间(loss≥15.0):梯度归零,过滤异常样本
"""
# 实际代码实现更复杂,此处为简化版
weights = torch.zeros_like(losses)
for i, loss in enumerate(losses):
if loss <= 1.45:
weights[i] = 1/(1 + math.exp(-k*(loss - x0))) * 0.3 # 削弱简单样本
elif loss < 6.6:
weights[i] = 1.5 # 增强中等难度样本
elif loss < 15.0:
weights[i] = 1/(1 + math.exp(loss - 6.2)) * 0.4 # 削弱困难样本
else:
weights[i] = 0 # 过滤异常样本
return weights
图:NLIRG算法的动态权重曲线。横坐标为loss值,纵坐标为梯度计算权重。
1. Token级别精准控制
传统方法对整个batch统一处理,而NLIRG对每个token单独计算权重,实现微观级精准调控。当模型对某个token的预测已经很准确(loss<1.0),算法会大幅降低该token的梯度,防止模型过度拟合这一特征。
2. 自动过滤低质量样本
当某样本的loss持续高于15.0时,NLIRG会自动将其权重设为0,从根本上避免噪声数据污染模型。在实际测试中,这帮助我们识别出训练集中15%的低质量标注数据。
3. 梯度热力图可视化
Y-Trainer集成TensorBoard,提供直观的梯度热力图,让训练过程可观察、可调试:
# 启用TensorBoard可视化
python -m training_code.start_training
--use_tensorboard 'true'
--tensorboard_path ./logs
# 克隆代码
git clone
cd y-trainer
# 安装依赖(单卡环境)
pip install torch peft>=0.10.0 tensorboard
pip install -r requirements.txt
python -m training_code.start_training
--model_path_to_load Qwen/Qwen3-8B
--training_type 'sft'
--use_NLIRG 'true' # 核心!启用NLIRG算法
--use_lora 'true' # 节省显存
--lora_target_modules "q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj"
--epoch 3
--batch_size 1
--token_batch 10 # 关键参数:每次反向传播的token数
--data_path your_dataset.json
--output_dir ./output
--use_tensorboard 'true' # 启用可视化
Y-Trainer还提供了智能语料排序工具,可按难易度自动调整训练顺序,进一步提升效果:
python -m training_code.utils.schedule.sort
--data_path raw_data.json
--output_path sorted_data.json
--model_path Qwen/Qwen3-8B
--mode "similarity_rank"
原理:该工具分析模型对每条语料的响应模式(损失值和熵的变化),计算难易度评分,构建渐进式学习路径。在实际测试中,使用排序后的语料训练,收敛速度 提升30%+ ,最终效果提升5-8%。
Y-Trainer通过NLIRG算法,实现了对大模型过拟合问题的精准打击:
Token级别动态调节:不再"一刀切",精准控制每个训练信号
无需通用语料:突破传统SFT需混合通用语料的限制,专注垂直领域
资源友好:单卡16GB显存即可微调7B模型
训练稳定:避免训练崩溃,收敛曲线更平滑
开源地址:GitHub
文档地址:Y-Trainer 介绍
#互动话题:你在大模型微调中遇到过哪些过拟合问题?是如何解决的?欢迎分享你的实战经验!

