
未感染者模拟器
62.73M · 2026-04-13

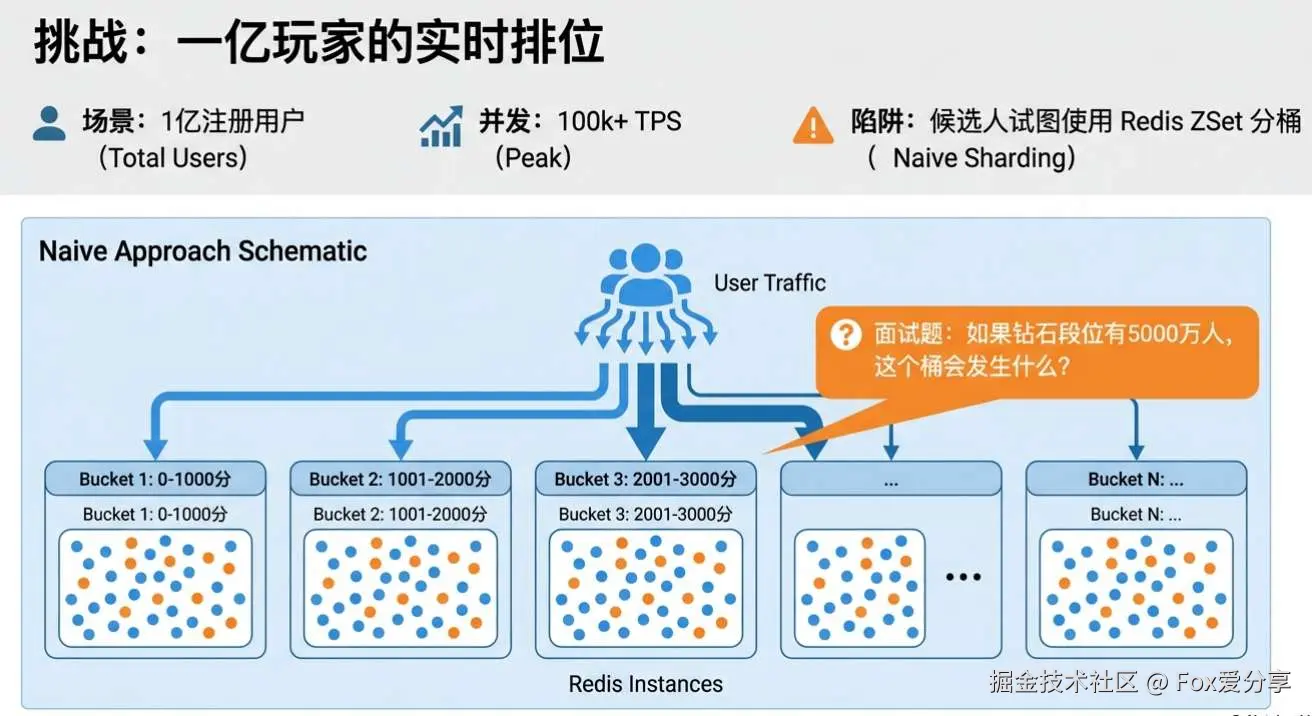
昨天有位粉丝找我哭诉腾讯 IEG的二面经历。题目很经典:“王者荣耀全服 1 亿玩家,如何设计实时战力排行榜? ”
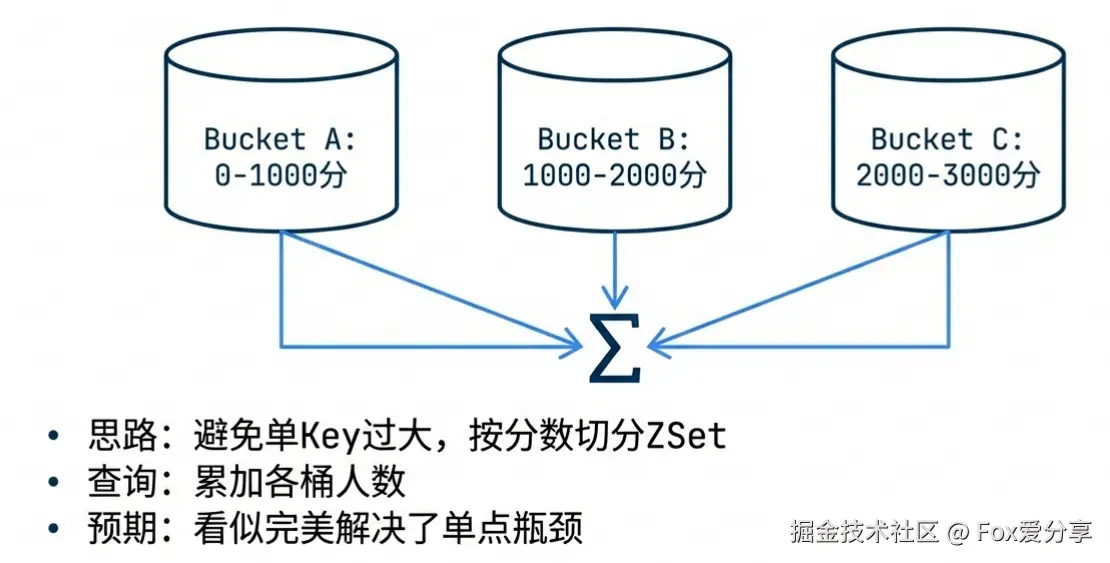
他显然是有备而来,自信满满地甩出了 “Redis ZSet 分段桶排序” 的方案:把玩家按分数每 1000 分切一个 ZSet,避免 BigKey,查排名时累加各桶人数。
本以为稳了,结果面试官冷冷地问了三个问题,直接让他破防:
兄弟出了会议室直接想删号。今天我们就来硬核拆解这道题。从“想当然”的八股文,到真正能扛住亿级流量的 “工业级”架构。
很多候选人死守“分桶”策略(0-1000分一桶,1000-2000分一桶)。这在电商金额分布里可能行得通,但在游戏里是死路。
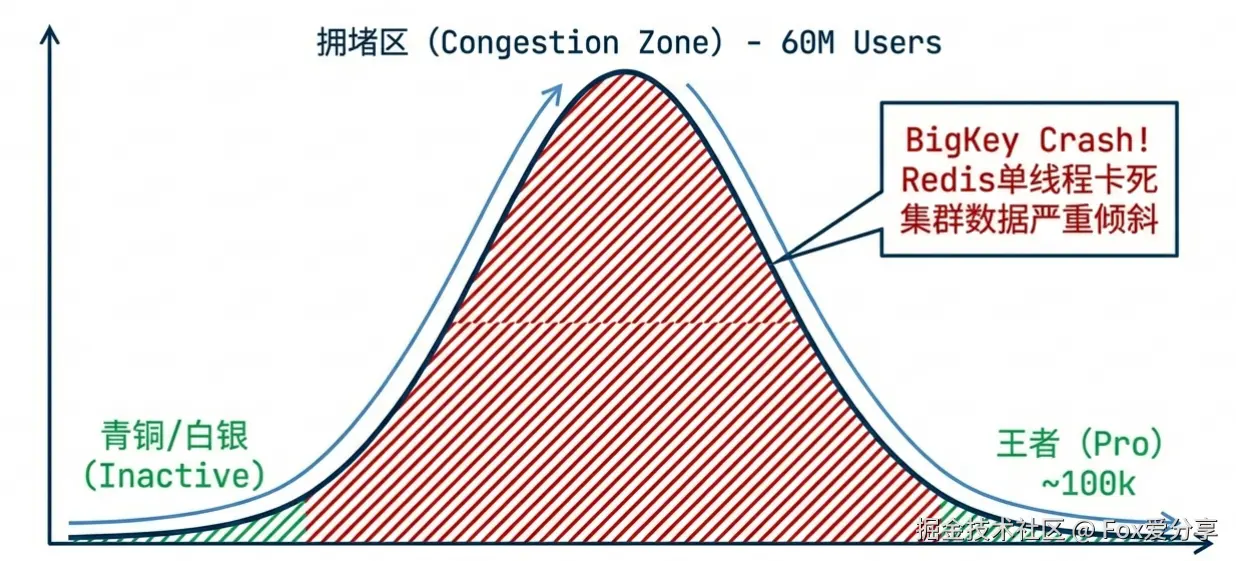
游戏段位是典型的正态分布!
惨案复现:
如果你按固定分数分桶,那个“钻石桶”里依然会有 5000 万+ 的数据。
结局:BigKey 问题压根没解决,Redis 单线程操作依然卡死,且集群数据严重倾斜,一个节点忙死,其他节点闲死。
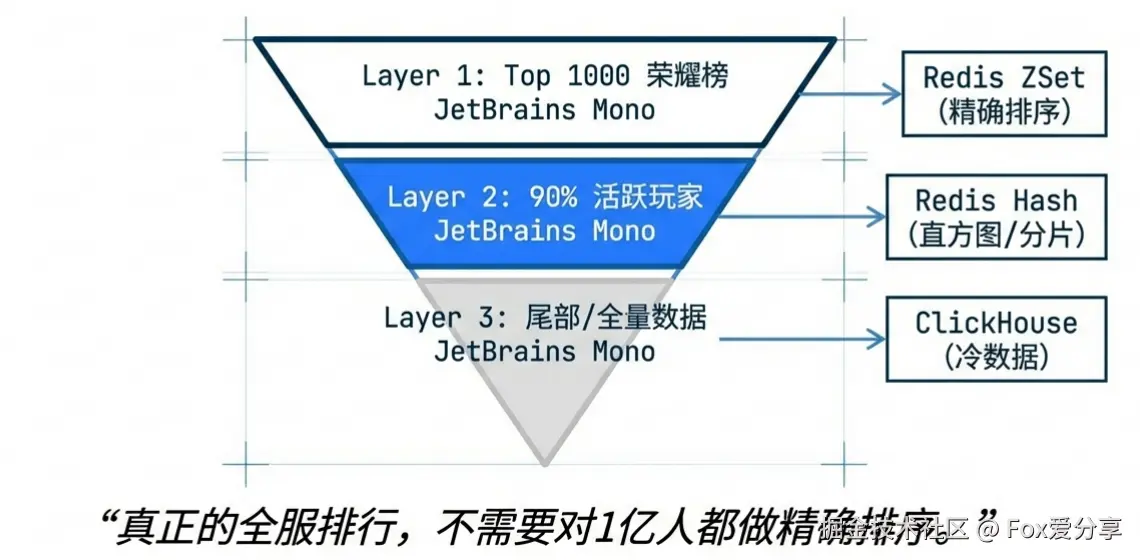
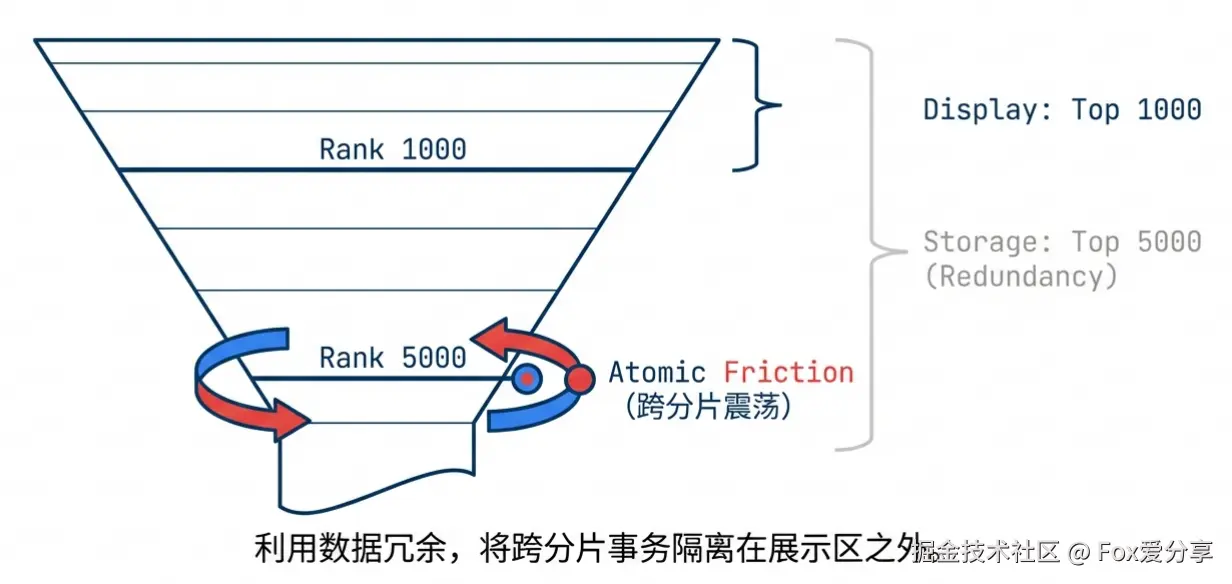
要解决 1 亿人的排名,核心心法只有一条: “抓大放小,甚至不准” 。真正的全服排行,其实不需要对 1 亿人都做 ZSet 排序。我们把玩家分成三层漏斗:
global_rank_zset 存储,实时性要求秒级。防坑(跨界摩擦):
如果第 1001 名赢了一把变成了第 1000 名,涉及“ZSet 踢人”和“Hash 计数器减人”的跨数据结构操作,Redis Cluster 无法保证原子性。
策略: “数据冗余” 。ZSet 实际存储 Top 5000,对外只展示 Top 1000。这样“边界摩擦”发生在第 5000 名,对前 1000 名的展示没有任何影响,实现了软隔离。
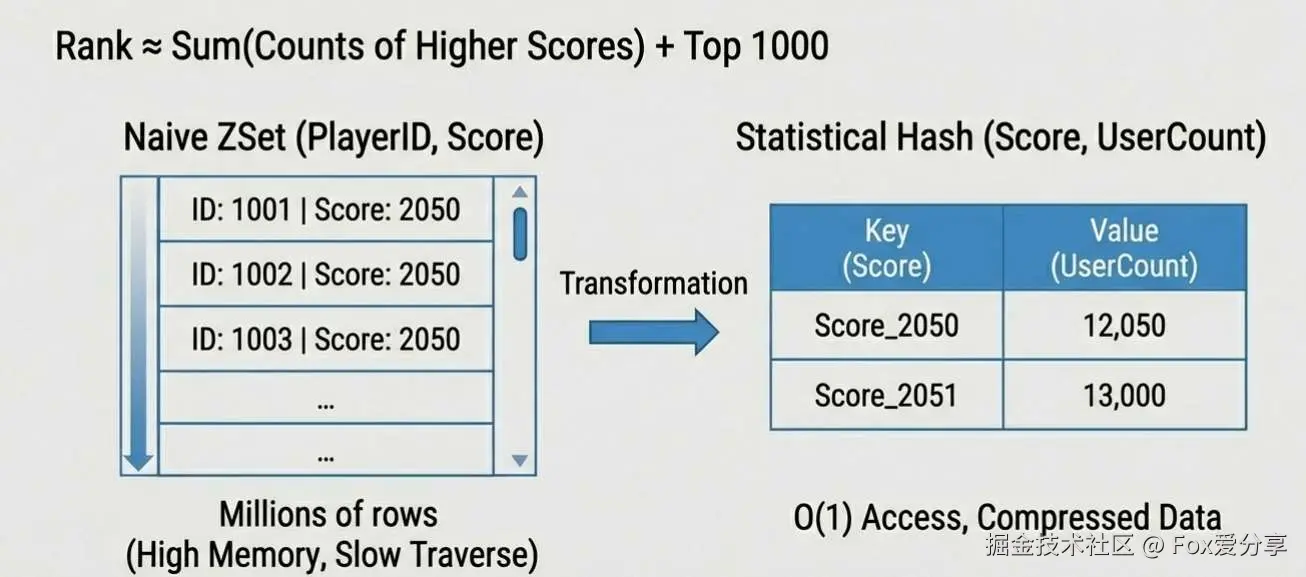
(PlayerID, Score) 的 ZSet,而是把分数切得更细(比如 1 分一个槽),只存 “这个分数有多少人” 。结构示例(Redis Hash):
Key: Rank_Counter
Field: "Score_2500" -> Value: 12050人
Field: "Score_2501" -> Value: 13000人
算排名:
我的排名 (比我高分的所有 Score 的人数之和) + (Top 1000 人数)。
Fox 高能预警(防杠补丁):
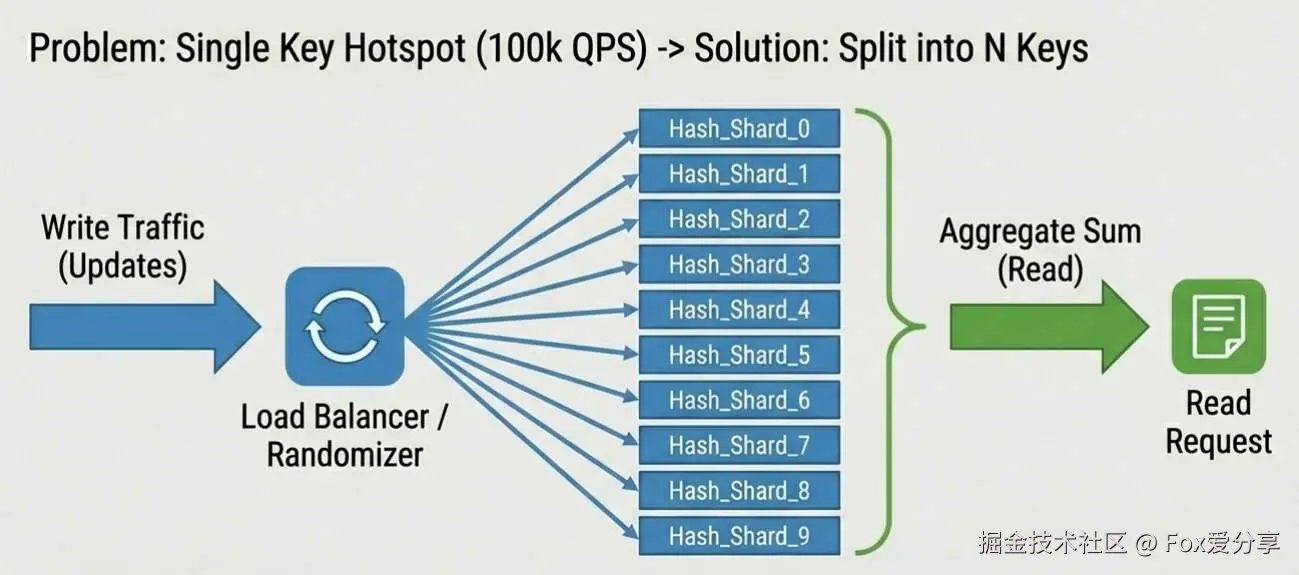
如果 5000 万人在线,每秒有 10 万人结算,这 10 万写 QPS 打在一个 Rank_Counter Key 上,Redis 依然会爆。
优化: Sharding(分片) 。必须将 Hash 拆分成 N 个 Key(如 Rank_Counter_1 ~ Rank_Counter_10)。写入时随机分片,读取时聚合所有分片的数据。这就把单点压力分散到了集群。
面试官如果问到这里,说明他对你很满意了。但真正的杀招在后面。
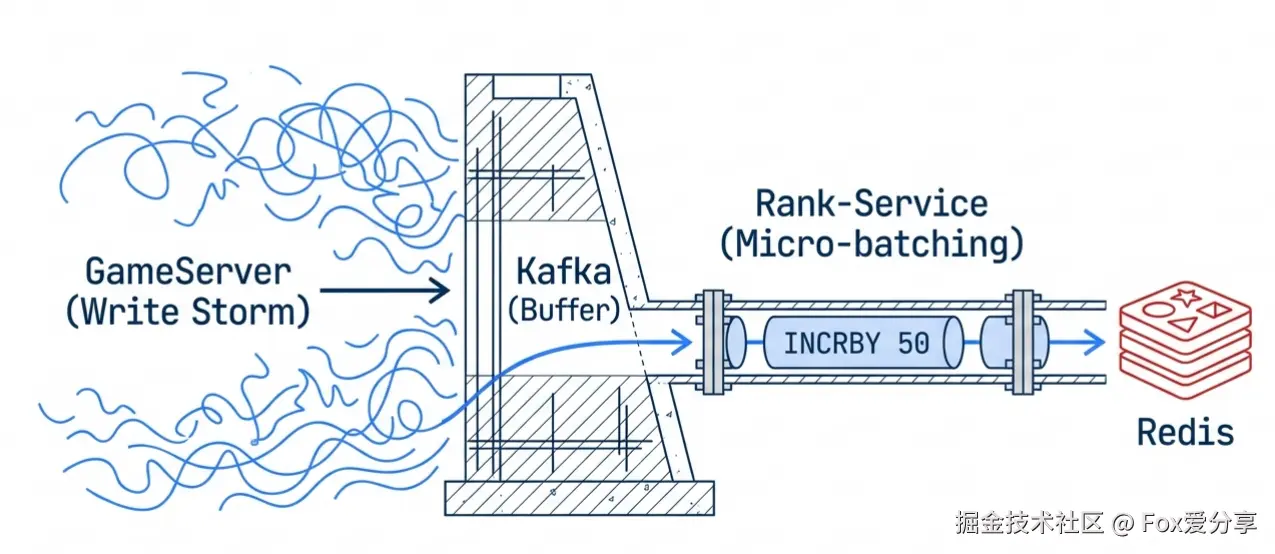
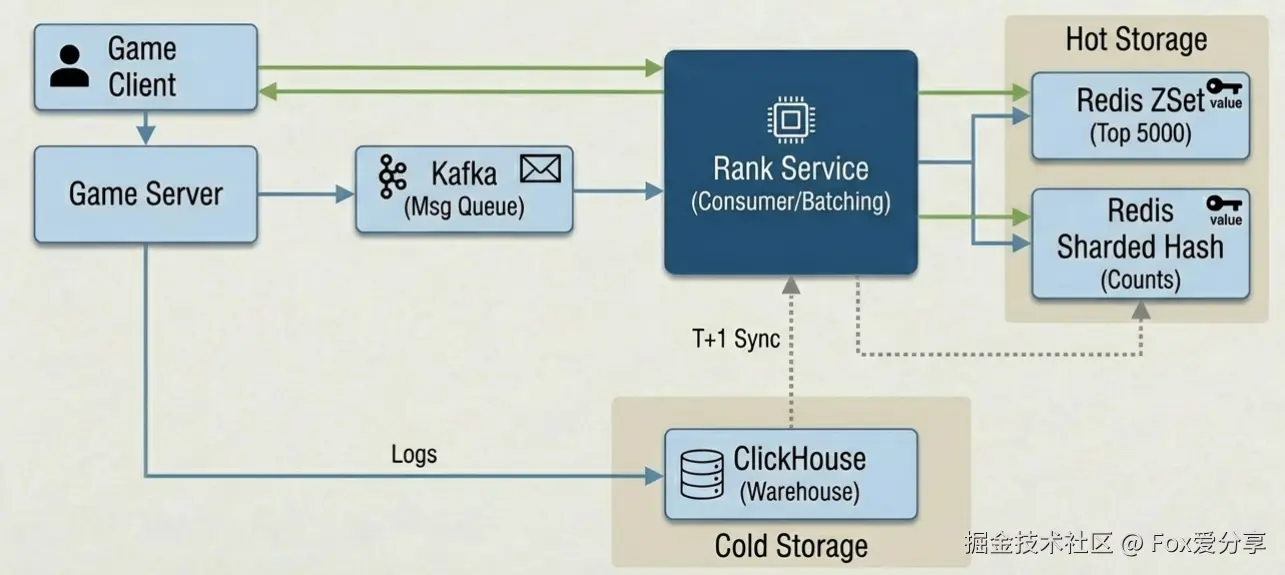
问题:1 亿玩家,晚高峰每秒几十万局游戏结束,直接操作 Redis 会导致写风暴。
解法:Kafka 缓冲 + 微批处理。
Rank-Service 消费 Kafka,将 100 毫秒内的 50 个 +1 操作合并成一次 INCRBY 50,再写 Redis。问题:计数器方案是 INCRBY 操作,如果服务挂了,-1 成功但 +1 失败,总人数就会永久少 1 个。时间久了,排行榜人数会越来越少(数据漂移)。
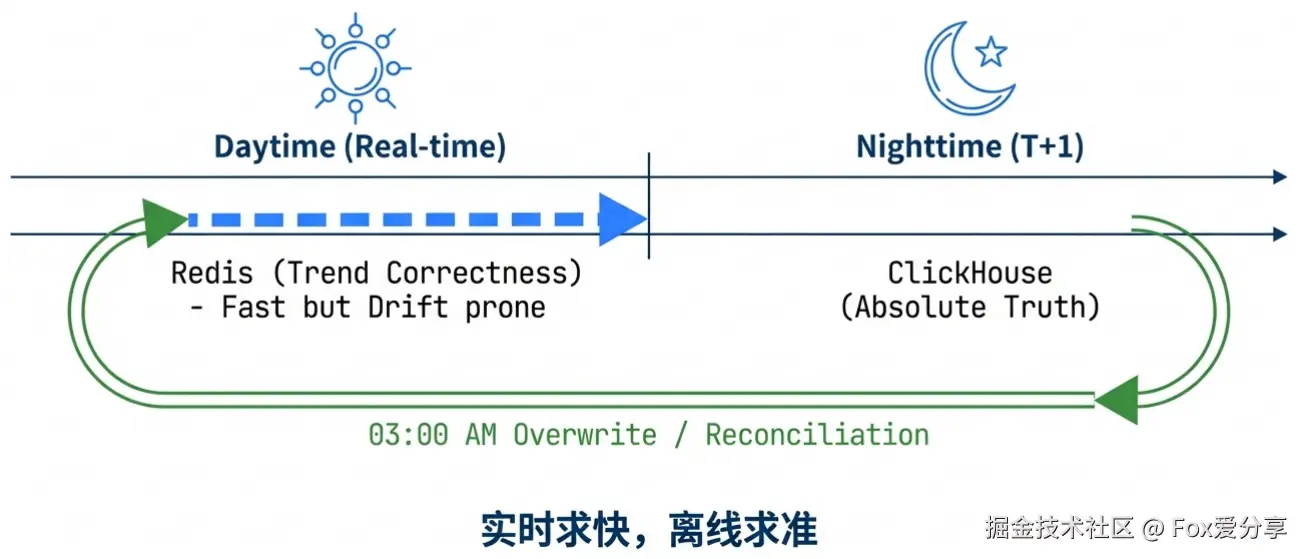
解法:T+1 离线对账。
Redis 只负责“实时趋势正确”。每天凌晨,利用 ClickHouse 的全量数据重算一遍 Hash 计数器,覆盖 Redis。实时求快,离线求准。
面试官问的第 3 点:“同分先到先得”。
网上的通解是:Score = 分数 + (1 - 时间戳/极大值)。
错!大错特错!
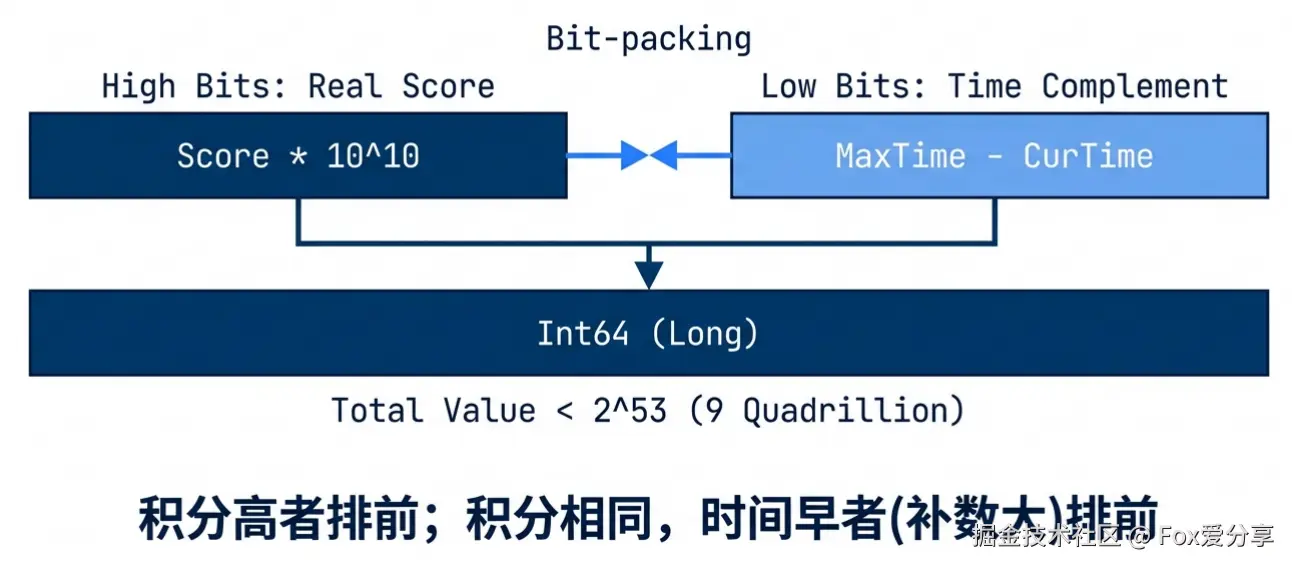
Redis 的 ZSet Score 是 Double 类型(IEEE 754),有效精度只有 52 位。如果你的时间戳(毫秒级)除以一个大数,变成小数点后十几位,Redis 会直接丢弃精度! 导致两人 Score 变成一样。
正确解法(位运算拼接):
利用整数的“高位”和“低位”思想,但要确保总数值不超过 。
公式:
真实分数
(Max - Cur) 越大,低位补得越多,总分越大,排前面。注意:必须严格计算位数,确保拼接后的数字不超过 9 千万亿(即 安全整数范围),否则 double 依然会丢精度。如果业务分数很高,建议直接牺牲时间精度(精确到秒即可)。
下次再被问 1 亿排名,请抛弃“简单的分桶”,甩出这套工业级组合拳:
“面试官,针对 1 亿级玩家,单纯的分桶策略无法解决正态分布导致的 BigKey 问题,且集群下无法原子操作。我的设计思路是 ‘分层架构 + 统计估算’:
分层架构(Funnel) :
抗压与一致性:
精度处理:
这套方案既规避了 Redis 内存瓶颈,又完美契合了游戏业务对‘实时性’和‘精确度’的分层需求。”
技术面试考的永远不是死记硬背 API,而是你对 “极端场景” 的敬畏心。能用 1 万个 Key 解决的问题(计数法),绝不用 1 亿个 Key(ZSet)。架构做减法,才是真专家。
你有没有在面试中被“海量数据”题坑过?欢迎评论区吐槽!
觉得这篇真的能帮你避坑的,点个赞,收藏起来。 别等生产环境炸了,才想起来回来翻这篇救命文。
关注公众号【Fox爱分享】,这里没有八股文,只有被坑出来的血泪经验。

