未感染者模拟器
62.73M · 2026-04-13

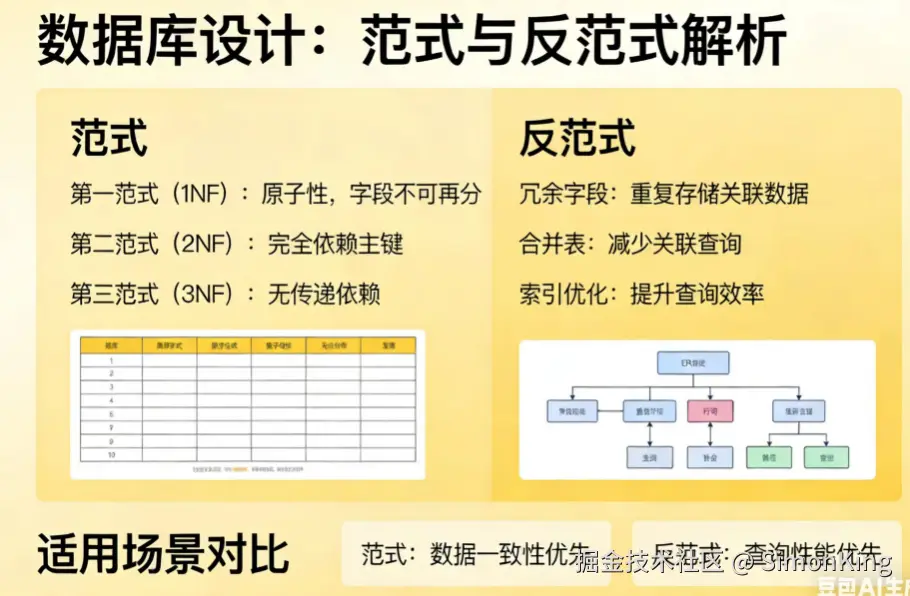
作为一名开发,数据库表的设计肯定都遇到过。数据设计的三范式是数据库规范化理论中的核心概念,你是否遵守了,又为什么打破范式?还是说野生程序员,无所谓范式的遵守。
所谓范式,就是在漫长的开发设计过程中,总结出来的规范,能够很大程度上规避一些问题。
第一范式(1NF):原子性。规范表中的每一列都是不可再分的最小数据单元,即每个字段都是原子的。
反例
-- 不符合1NF的设计
CREATE TABLE tb_user (
id INT PRIMARY KEY,
name VARCHAR(50),
contact VARCHAR(100) -- 包含电话和邮箱:'13800138000,test@email.com'
);
这里的contact字段包含了电话和邮箱信息,破坏了字段的原子性。当然一般人也不会这么设计,大家也都知道每一个字段都代表独立的含义,不会去聚合字段。但是这种骨子里都会这样设计的方式,被人总结为第一范式。
正例
-- 符合1NF的设计
CREATE TABLE tb_user (
id INT PRIMARY KEY,
name VARCHAR(50),
phone VARCHAR(20),
email VARCHAR(50)
);
第二范式(2NF):消除部分依赖。在满足1NF的基础上,非主键列必须完全依赖于整个主键(针对复合主键)。
这个比较好理解,这就是针对符合主键的。要么依赖整个复合主键要么不依赖,坚决不能只依赖复合主键的一部分。
反例
-- 不符合2NF的设计(用户角色表)
CREATE TABLE tb_user_role (
user_id INT,
role_id INT,
role_name VARCHAR(100), -- 仅依赖于role_id,而非整个主键
create_time datetime
PRIMARY KEY (user_id, role_id)
);
role_name字段仅仅依赖于role_id,而非user_id、role_id联合主键。所以字段应该放到其他表中。
正例
-- 符合2NF的拆分
CREATE TABLE tb_user (
id INT PRIMARY KEY,
user_name VARCHAR(50),
phone VARCHAR(20),
email VARCHAR(50)
);
CREATE TABLE tb_role (
id INT PRIMARY KEY,
role_name VARCHAR(50)
);
CREATE TABLE tb_user_role (
user_id INT,
role_id INT,
create_time datetime
PRIMARY KEY (user_id, role_id)
);
第三方范式(3NF):消除传递依赖。在满足2NF的基础上,非主键列之间不能存在传递依赖。
第三方范式和第二范式非常相似,按照的理解完成可以用冗余字段来说明,也就是不允许表中有冗余字段。
反例
-- 不符合3NF的设计
CREATE TABLE tb_employee (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
department_id INT,
department_name VARCHAR(50), -- 依赖于department_id,而非直接依赖于employee_id
department_location VARCHAR(100)
);
员工表中已经存在了部门ID(department_id),而department_name是依赖department_id,是不属于员工信息的。必须要消除这种传递的依赖。
正例
-- 符合3NF的拆分
CREATE TABLE tb_employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
department_id INT
);
CREATE TABLE tb_departments (
department_id INT PRIMARY KEY,
department_name VARCHAR(50),
location VARCHAR(100)
);
1NF是为了解决字段混乱,无法准确描述字段含义的问题,给查询带来困难。2NF、3NF是为了解决字段冗余问题,保证每次查询的信息没有异议。
但是我们实际开发中会严格遵守这写范式么?不一定,我们通常都是根据业务场景设计数据库表,以满足业务逻辑。常常进行反范式的设计。
反范式设计的目的只有一个,那就是方便业务处理。
正常的来讲,第一范式是必须要遵守的。但是,并不是绝对的。
主要的业务字段完全遵守原子性的设计,然而对于辅助字段来说,就没有那么严格了。比如我们数据库设计中要求必须要有一个字段:reamrk VARCHAR(200)
这个字段是为了保存一些额外的,业务之外用于技术人员查看的信息。很有可能存入一些符合信息。
二三范式可以按照冗余说明。
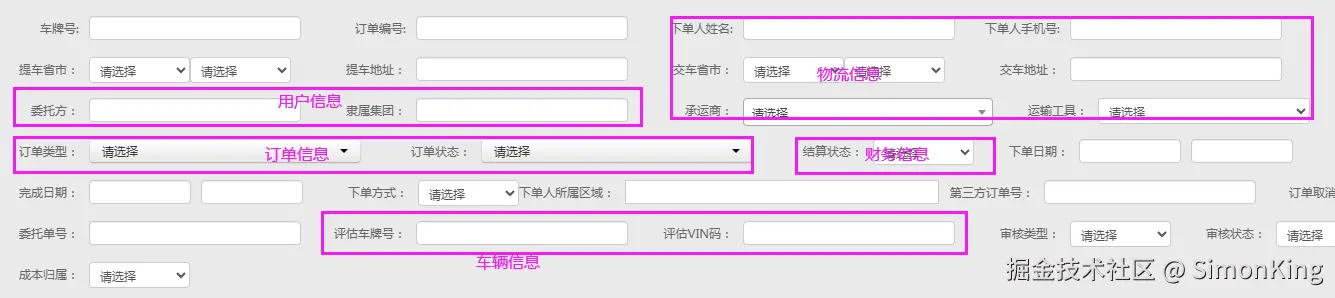
业务为了查询方便,比如一个后台页面,业务人员需要按照用户信息、订单、商品信息查询。
如图,查询条件中就包含了5个表的信息
如果按照范式设计,需要通过关联表查询即可。但是,随着数据量的增加,查询就会变慢,为了解决慢的问题,我们尽量减少跨表查询,就需要冗余字段。
冗余字段
冗余字段可以减少库表之间的关联。
-- 电商订单系统优化
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
customer_id INT,
customer_name VARCHAR(50), -- 冗余:避免连接Customers表
total_amount DECIMAL(10,2), -- 冗余:预计算值
item_count INT, -- 冗余:避免聚合查询
status VARCHAR(20),
created_at TIMESTAMP
);
宽表设计
大数据时代,为了分析数据,我们需要建宽表,宽表中会冗余大量的字段,以报表见多。
-- 销售报表宽表(星型模型)
CREATE TABLE Sales_Fact (
sale_id INT PRIMARY KEY,
sale_date DATE,
product_id INT,
product_name VARCHAR(100), -- 维度冗余
category_name VARCHAR(50),
customer_id INT,
customer_region VARCHAR(50), -- 维度冗余
salesperson_id INT,
salesperson_name VARCHAR(50), -- 维度冗余
unit_price DECIMAL(10,2),
total_amount DECIMAL(10,2),
discount_amount DECIMAL(10,2),
net_amount DECIMAL(10,2),
INDEX idx_date (sale_date),
INDEX idx_product (product_id),
INDEX idx_customer (customer_id)
) ENGINE=InnoDB;
T+1报表
为了业务需要,我们需要统计时间段内的销售数据,为了避免实时查询带来的性能损耗,我们经常会设计T+1的报表。T+1的报表会忽略业务表字段的传递,大量冗余需要的字段,已完成展示的需要。
三范式是数据库设计的理论基础,保证了数据的一致性和完整性。反范式设计是实践中的优化手段,通过牺牲部分规范化来提升查询性能。无论何种设计思想,目的只有一个,那就是为业务服务。

