录音机录音
97.64M · 2026-02-05

Agent Skills 是由 Anthropic 开发并作为开放标准发布的智能体能力扩展工具,其本质是将专业知识和工作流封装为可复用的能力单元。
与传统提示词工程不同,Agent Skills 采用"文件夹+SKILL.md"的结构化设计,使模型能够按需加载不同层级的技能信息。
Agent Skills 最核心的创新是**渐进式披露(Progressive Disclosure)**机制。该机制将技能信息分为三个层次,智能体按需逐步加载:
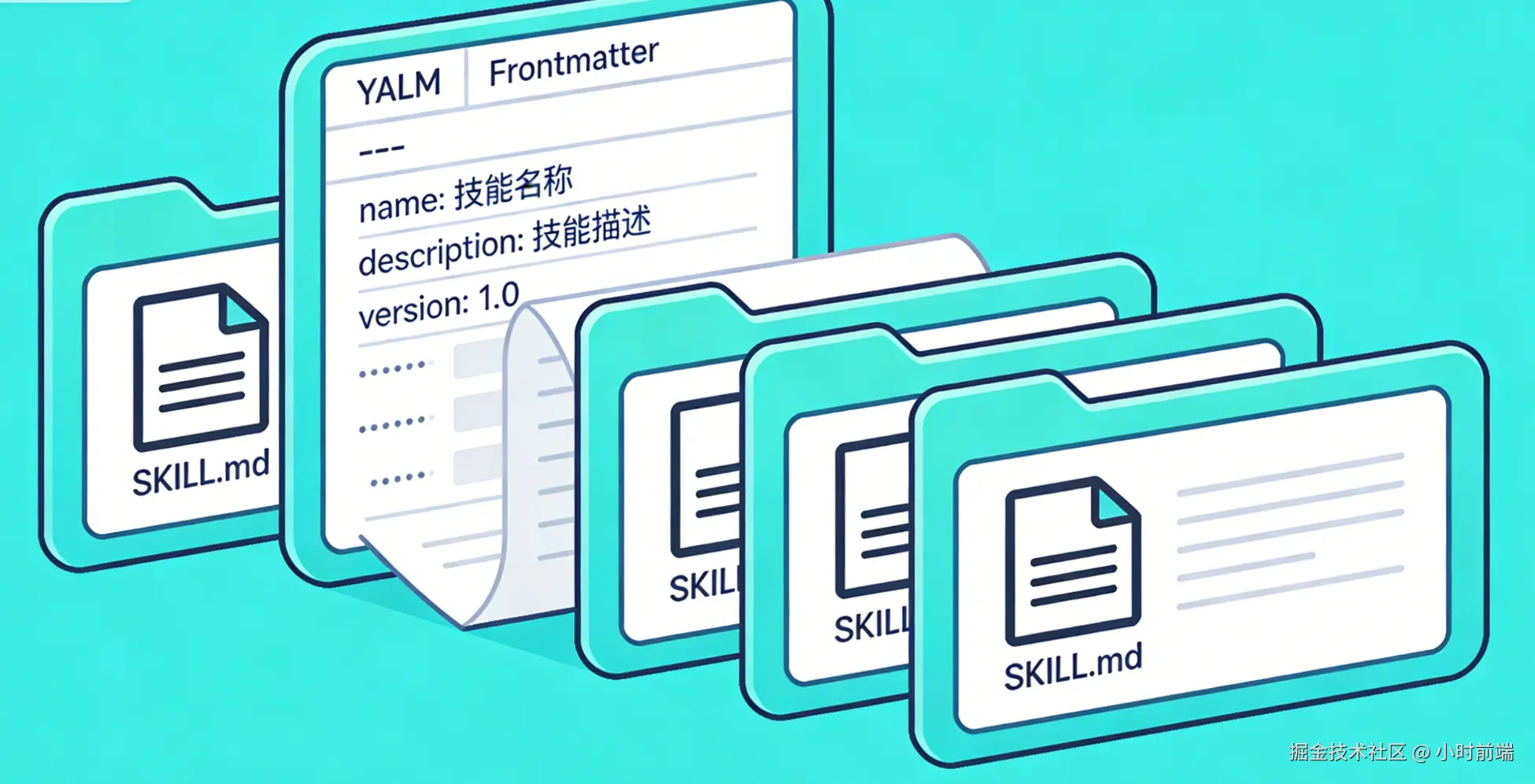
在 Skills 的设计中,每个技能都存放在一个独立的文件夹中,核心是一个名为 SKILL.md 的 Markdown 文件。这个文件必须以 YAML 格式的 Frontmatter 开头,定义技能的基本信息:
---
name: pdf-processing
description: Extract text and tables from PDF files... Use when working with PDF files...
---
当智能体启动时,它会扫描所有已安装的技能文件夹,仅读取每个 SKILL.md 的 Frontmatter 部分,将这些元数据加载到系统提示词中。根据实测数据,每个技能的元数据仅消耗约 100 个 token。
当智能体通过分析用户请求,判断某个技能与当前任务高度相关时,它会进入第二层加载。此时,智能体会读取该技能的完整 SKILL.md 文件内容,将详细的指令、注意事项、示例等加载到上下文中。这部分内容的 token 消耗取决于指令的复杂度,通常在 1,000 到 5,000 个 token 之间。
对于更复杂的技能,SKILL.md 可以引用同一文件夹下的其他文件:脚本、配置文件、参考文档等。智能体仅在需要时才加载这些资源。
| 层级 | 内容 | 加载策略 | Token消耗 | 技术价值 |
|---|---|---|---|---|
| 元数据层 | YAML Frontmatter的name和description字段 | Always-On常驻加载 | 极低(<1%) | 模型路由决策与意图识别 |
| 指令层 | SKILL.md正文的规则和步骤 | On-Demand按需加载 | 中等(5-10%) | 定义业务处理逻辑与SOP |
| 资源层 | 外部文档、手册、脚本等 | Context-Triggered条件触发 | 高但可变 | 按需加载专业知识,用完即弃 |
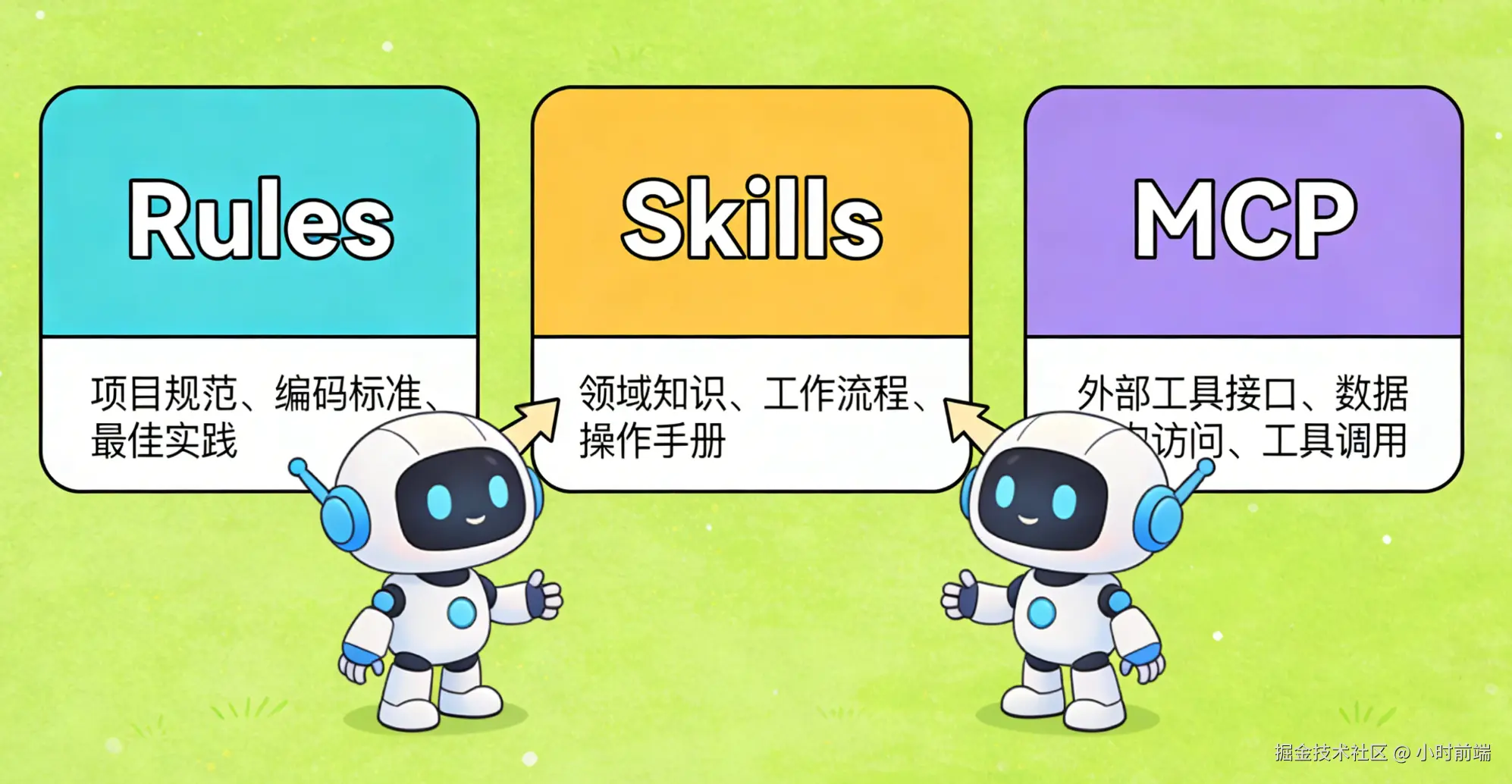
Rules 是项目级别的静态规范,定义了代码风格、架构模式、开发流程等通用规则。
# 项目开发规范
## 编码规范
- 使用 TypeScript,严格类型检查
- 优先使用 UnoCSS 原子类
- 组件逻辑抽离到 useXxx.ts hooks 文件
Skills 是任务级别的动态能力,提供特定领域的专业知识和工作流程。
---
name: design-conversion
description: Figma 设计稿转换为 uni-app 代码的技能,包含图片资源下载、UnoCSS 原子类使用、rpx 单位转换等完整规范
---
MCP 是工具级别的连接协议,提供标准化的外部工具和数据访问接口。
用一个完整的软件开发流程来理解:
Rules = 公司编码规范手册
Skills = 特定任务的操作手册
MCP = 工具和服务的驱动程序
假设用户请求:"帮我把这个 Figma 设计稿转换成代码"
1. Rules 提供基础约束
└─> "使用 UnoCSS 原子类,不要自定义 CSS"
└─> "使用 TypeScript,严格类型检查"
└─> "组件逻辑抽离到 hooks 文件"
2. Skills 提供专业知识
└─> 触发 design-conversion skill
└─> 加载 "如何从 Figma 下载图片"
└─> 加载 "rpx 单位转换规则"
└─> 加载 "UnoCSS 使用规范"
3. MCP 提供工具接口
└─> 使用 Figma MCP 下载图片资源
└─> 使用文件系统 MCP 保存文件
└─> 使用代码编辑器 MCP 创建文件
设计理念:连接性(Connectivity)与能力(Capability)应该分离。
如果说 MCP 为智能体提供了"手"来操作工具,那么 Skills 就提供了"操作手册"或"SOP(标准作业程序)",Rules 则提供了"公司规范手册"。
| 维度 | Rules | Skills | MCP |
|---|---|---|---|
| 定位 | 项目规范 | 领域知识 | 工具接口 |
| 加载时机 | Always-On | On-Demand | Runtime |
| 作用范围 | 项目级别 | 任务级别 | 工具级别 |
| 内容性质 | 静态规范 | 动态能力 | 连接协议 |
| Token消耗 | 中等(常驻) | 可变(按需) | 低(接口定义) |
| 复用性 | 项目内 | 跨项目 | 跨平台 |
| 更新频率 | 低 | 中 | 中 |
上下文窗口是公共资源。 技能与 Claude 需要的所有其他内容共享上下文窗口:系统提示、对话历史、其他技能的元数据以及实际的用户请求。
默认假设:Claude 已经非常智能。 只添加 Claude 尚未具备的上下文。质疑每条信息:
优先使用简洁的示例而不是冗长的解释。
根据任务的脆弱性和可变性匹配具体程度:
将 Claude 想象成在探索一条路径:有悬崖的狭窄桥梁需要特定的护栏(低自由度),而开阔的田野允许多条路线(高自由度)。
保持 SKILL.md 正文精简,不超过 500 行,以最小化上下文膨胀。当接近此限制时,将内容拆分到单独的文件中。
关键原则: 当技能支持多种变体、框架或选项时,仅在 SKILL.md 中保留核心工作流程和选择指导。将特定于变体的详细信息(模式、示例、配置)移至单独的参考文件。
要创建有效的技能,需要清楚理解技能将如何使用的具体示例。这种理解可以来自直接的用户示例或经过用户反馈验证的生成示例。
关键问题:
要将具体示例转化为有效的技能,通过以下方式分析每个示例:
分析维度:
这是技能最重要的部分,因为这是 Claude 用来确定何时使用该技能的唯一字段。
---
name: skill-name
description: 清晰全面地描述技能是什么以及何时应该使用它。包括技能做什么以及使用它的特定触发器/上下文。
---
关键要点:
name:技能名称,使用 kebab-casedescription:必须包含所有"何时使用"信息——而不是在正文中。正文仅在触发后加载,因此正文中的"何时使用此技能"部分对 Claude 没有帮助license)好的描述示例:
description: 全面的文档创建、编辑和分析,支持修订追踪、批注、格式保留和文本提取。当 Claude 需要处理专业文档(.docx 文件)时使用,用于:(1) 创建新文档,(2) 修改或编辑内容,(3) 处理修订追踪,(4) 添加批注,或任何其他文档任务
写作指南: 始终使用祈使句/不定式形式。
结构建议:
references/ 中的详细文档避免:
references/ 中)根据步骤 2 的分析,创建必要的资源文件:
重要原则:
SKILL.md 或参考文件中,而不是两者都有SKILL.md 精简:仅在 SKILL.md 中保留基本的程序性指令和工作流程指导在实际任务中使用技能,注意困难或低效之处,确定应如何更新 SKILL.md 或捆绑资源,实施更改并再次测试。
skill-name/
├── SKILL.md # 必需:技能主文件
│ ├── YAML 前置元数据(必需)
│ │ ├── name:(必需)
│ │ └── description:(必需)
│ └── Markdown 说明(必需)
│
└── 捆绑资源(可选)
├── scripts/ # 可执行代码
│ ├── process_data.py
│ └── generate_report.sh
│
├── references/ # 参考文档
│ ├── api-docs.md
│ ├── database-schema.md
│ └── workflows.md
│
└── assets/ # 输出资源
├── templates/
│ └── report-template.html
├── icons/
│ └── logo.png
└── fonts/
└── custom-font.ttf
每个技能的核心文件,包含:
YAML 前置元数据(必需)
---
name: skill-name
description: 技能描述,包含何时使用此技能的信息
---
Markdown 正文(必需)
用于需要确定性可靠性或重复编写的任务的可执行代码。
何时包含:
示例:
scripts/rotate_pdf.py - PDF 旋转任务scripts/process_data.py - 数据处理脚本scripts/generate_report.sh - 报告生成脚本优点:
用于根据需要加载到上下文中以指导 Claude 过程和思考的文档和参考材料。
何时包含:
示例:
references/api-docs.md - API 规范文档references/database-schema.md - 数据库模式references/workflows.md - 详细工作流程指南references/company-policies.md - 公司政策文档最佳实践:
SKILL.md 中包含 grep 搜索模式SKILL.md 或参考文件中,而不是两者都有不打算加载到上下文中,而是在 Claude 产生的输出中使用的文件。
何时包含:
示例:
assets/logo.png - 品牌资产assets/slides.pptx - PowerPoint 模板assets/frontend-template/ - HTML/React 样板assets/font.ttf - 字体文件优点:
技能应仅包含直接支持其功能的必要文件。不要创建多余的文档或辅助文件,包括:
技能应仅包含 AI 代理完成手头工作所需的信息。它不应包含关于创建过程的辅助上下文、设置和测试程序、面向用户的文档等。
# PDF 处理
## 快速入门
使用 pdfplumber 提取文本:
[代码示例]
## 高级功能
- **表单填写**:完整指南请参见 [FORMS.md](references/FORMS.md)
- **API 参考**:所有方法请参见 [REFERENCE.md](references/REFERENCE.md)
- **示例**:常见模式请参见 [EXAMPLES.md](references/EXAMPLES.md)
Claude 仅在需要时加载 FORMS.md、REFERENCE.md 或 EXAMPLES.md。
bigquery-skill/
├── SKILL.md(概述和导航)
└── references/
├── finance.md(收入、账单指标)
├── sales.md(机会、管道)
├── product.md(API 使用、功能)
└── marketing.md(活动、归因)
当用户询问销售指标时,Claude 只读取 sales.md。
# DOCX 处理
## 创建文档
使用 docx-js 创建新文档。请参见 [DOCX-JS.md](references/DOCX-JS.md)。
## 编辑文档
对于简单编辑,直接修改 XML。
**对于修订追踪**:请参见 [REDLINING.md](references/REDLINING.md)
**对于 OOXML 详情**:请参见 [OOXML.md](references/OOXML.md)
Claude 仅在用户需要这些功能时读取 REDLINING.md 或 OOXML.md。
重要指南:
SKILL.md 起一层深度。所有参考文件应直接从 SKILL.md 链接references/ 中SKILL.md 或参考文件中,而不是两者都有SKILL.md 中保留基本的程序性指令和工作流程指导# 好的写法
使用 pdfplumber 提取文本。
优先使用 UnoCSS 原子类。
# 避免的写法
你应该使用 pdfplumber 提取文本。
我们建议优先使用 UnoCSS 原子类。
SKILL.md 中包含 grep 搜索模式SKILL.md 起一层深度)这是技能最重要的部分,因为这是 Claude 用来确定何时使用该技能的唯一字段。
# 不好的描述(太简短,缺少触发信息)
description: PDF 处理技能
# 好的描述(包含何时使用信息)
description: 全面的 PDF 文档处理,支持文本提取、表格提取、页面旋转和合并。当 Claude 需要处理 PDF 文件时使用,用于:(1) 提取文本内容,(2) 提取表格数据,(3) 旋转页面,(4) 合并多个 PDF,或任何其他 PDF 操作任务
这是一个实际项目中的 Skill,展示了完整的目录结构和内容组织。
design-conversion/
├── SKILL.md
└── references/
├── rpx转换速查表.md
└── 响应式单位使用指南.md
---
name: design-conversion
description: Figma 设计稿转换为 uni-app 代码的技能,包含图片资源下载、UnoCSS 原子类使用、rpx 单位转换等完整规范
tags:
- figma
- design-to-code
- uniapp
- unocss
- rpx
---
正文结构:
渐进式披露:
避免重复:
SKILL.md 中包含核心规则和检查清单references/ 中清晰的触发条件:
这是一个元技能(meta-skill),用于创建其他技能。
skill-creator/
├── SKILL.md
├── LICENSE.txt
├── scripts/
│ ├── init_skill.py
│ ├── package_skill.py
│ └── quick_validate.py
└── references/
├── output-patterns.md
└── workflows.md
包含脚本:
init_skill.py:初始化新技能package_skill.py:打包技能quick_validate.py:快速验证参考文档:
output-patterns.md:输出格式模式workflows.md:工作流程指南渐进式披露:
SKILL.md 中references/ 中Rules、Skills、MCP 三者职责分离:
写好 Skill 的核心原则:
标准目录结构:
SKILL.md(必需):元数据 + 核心指令scripts/(可选):可执行代码references/(可选):参考文档assets/(可选):输出资源最佳实践:
SKILL.md 精简(不超过 500 行)
