
抖音火山极速版官方正版
308.71MB · 2026-02-05

最近在学习 AI 相关的知识,「AI 日记」这个系列会记录我的一些输出与心得,正如我往常的输出内容一致,这并不是一份 stepbystep 的 Roadmap,而是单纯的个人记录、并且考虑到读者我会尽可能地解释清楚并争取让大家也能得到一些有效输入。
我是一个刚学习没多久的 AI 小白,文章中肯定有局限甚至错误之处,仅仅用来参考和一起交流。
目前我有一些关于许多高等院校的信息,这些信息有非常多的方面和字数,而且经过了专人的检验,是相对网络数据更可靠的信息源;于是我希望做一个聊天机器人,用户能够去询问这个聊天机器人关于高校的一些问题,而机器人会根据上述提到的可靠信息源来生成回复给到用户。
很显然如果我直接调用诸如 deepseek 的模型的话,它更多的参考依据是网络的数据,而我更希望向用户呈现的是经过我们的检验的可靠数据;但是我又不可能在每一次用户提问时,都把我的数据作为 Prompt(提示词)同用户的输入一起提交给模型,因为我的数据有成千上万条,字数多达百万级别,模型不可能在用户可接受的时间内一次处理这么多数据,这既不高效也不经济。
这时我们就需要一些手段来实现此类需求。
RAG(检索增强生成,Retrieval-Augmented Generation)是一种通过在生成响应之前从外部权威知识库中检索相关信息,来优化大语言模型(LLM)输出的AI技术。它让 AI “查资料再作答”,有效解决了大模型训练数据过期、生成内容不准确(幻觉)及缺乏领域私有知识的问题。
RAG 的核心要素与工作流程是:
检索 (Retrieval): 系统将用户的查询与外部知识库(如企业文档、数据库、即时网络信息)进行比对,找出最相关的内容。
增强 (Augmentation): 将检索到的知识与用户的提示词(Prompt)整合,形成上下文。
生成 (Generation): LLM 利用这些增强后的知识生成专业、准确、最新的回答
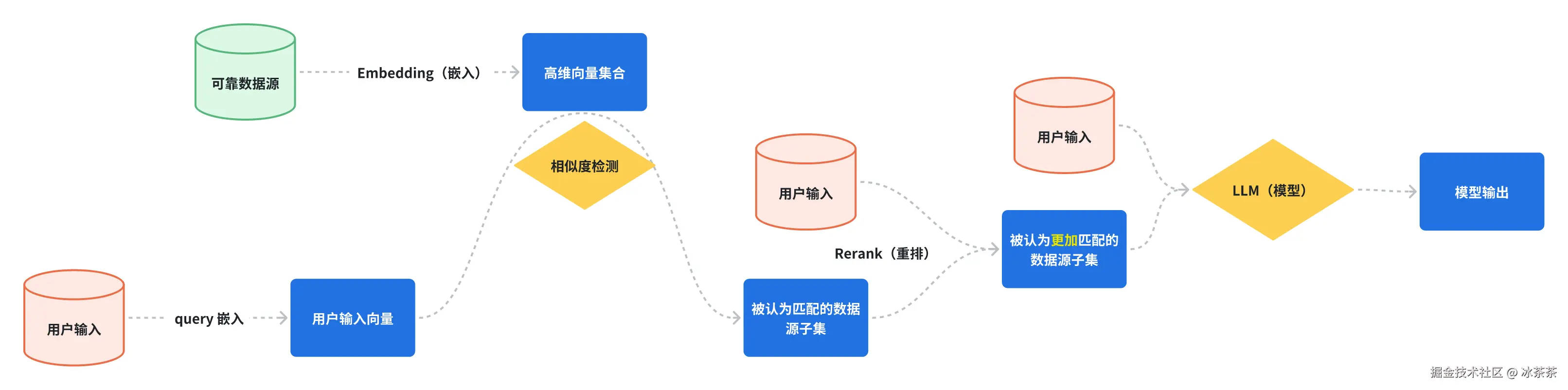
下面我来简单地画一张示意图来体现 RAG 中的一些核心流程:
这张图中省略了非常多的技术细节,但是最核心的流程无非就以下几步:
Embedding(嵌入):由于我们的数据源的数据量非常大,不可能等到用户实际发生提问时再来处理,所以我们必须要对其进行预处理,Embedding 就是一种将高维、离散的数据(如文本、图像、商品ID)映射为低维、连续的稠密向量的技术:嵌入模型可以将我们数据源中一段段文本(可能是关于某个高校的师资力量的信息)映射处理为一个高维向量(在接下来我的实例中是 1024 维),注意我这里虽然说它是一个「高维」向量,但是它已经比原始文本数据的维度低多了,所以并不和定义中的「低维」冲突;当这些可靠的数据源被处理成了一个个高维的向量,由文字转化为了数字,那么后续的匹配对比操作就是计算机更擅长的事了
相似度检测:当用户输入一个问题以后,这串输入首先会同样被 Embedding(没错,这个处理的模型应该和处理数据源的Embedding模型是同个模型:如果不是一个模型的话,它们最后就没法在同个嵌入的向量空间去做相似度检测,那就没意义了)成一个同维度的向量,然后根据一些相似度检测算法去进行检测,可以简单理解为就像是在一个平面直角坐标系中,我们去找到距离更近的两个点一样,只不过现在的维度不是2维而是1024维;接着通过一些参数的配置,我们可以返回那些和用户输入最接近的一些数据源片段(比如返回十个)
Rerank(重排):其实到这里数据复杂度已经大大下降了,但是如果还想做到更极致一些的话就可以用到重排;在通过相似度检测初步召回了一些相关性高的十个数据源片段后,我们可以利用精细的模型对候选片段同用户提问的语义相关性进行深度分析和重新排序,这里的算法和 Embedding 并不一样,而且会更加地耗时;比如我们通过 Rerank 完成了这十个数据源片段更加精细的相似度排名,并且只取前五个返回
LLM输出(大语言模型输出):接下来就来到了「最后一公里」,那就是我们拿着用户输入和经过 Rerank 的五个数据源片段,一股脑全部扔给 LLM,让大语言模型再去帮助我们分析问题、理解资料、回答用户的问题。
不难发现,我们通过一系列操作,使得大模型不必临场时再去开卷翻一遍并且现场理解所有的资料来回答用户,而是我们预先对于数据做了各种处理,使得最后大模型只需要处理少部分数据就可以得到精确的回答。
虽然自己动手写更多代码肯定能学到更多东西,但是我想要在速度上也有较快的正反馈,所以我使用了 RAGFlow,它有点像是开发的低代码平台,我觉得当你真的对于一些原子背后的结构和底层有一定了解之后,单纯去写各种调用或者设置参数的繁琐代码感觉性价比并不会更高。
RAGFlow(github.com/infiniflow/… 是一款领先的开源检索增强生成 ( RAG ) 引擎,它将前沿的 RAG 技术与代理功能融合,为生命周期管理 (LLM) 创建卓越的上下文层)。
跑 RAGFlow 需要在 docker 上运行,如果有部署需求,可以直接在公司的服务器或者开发机运行,或者在本地搞好 MVP 后,再把对应的配置文件同步过去。
跑 docker 的时候内存最好分配大一些(我分配了16GB),最开始我只分配了8GB,导致 Elasticsearch 一直因为内存不足而不断重启。
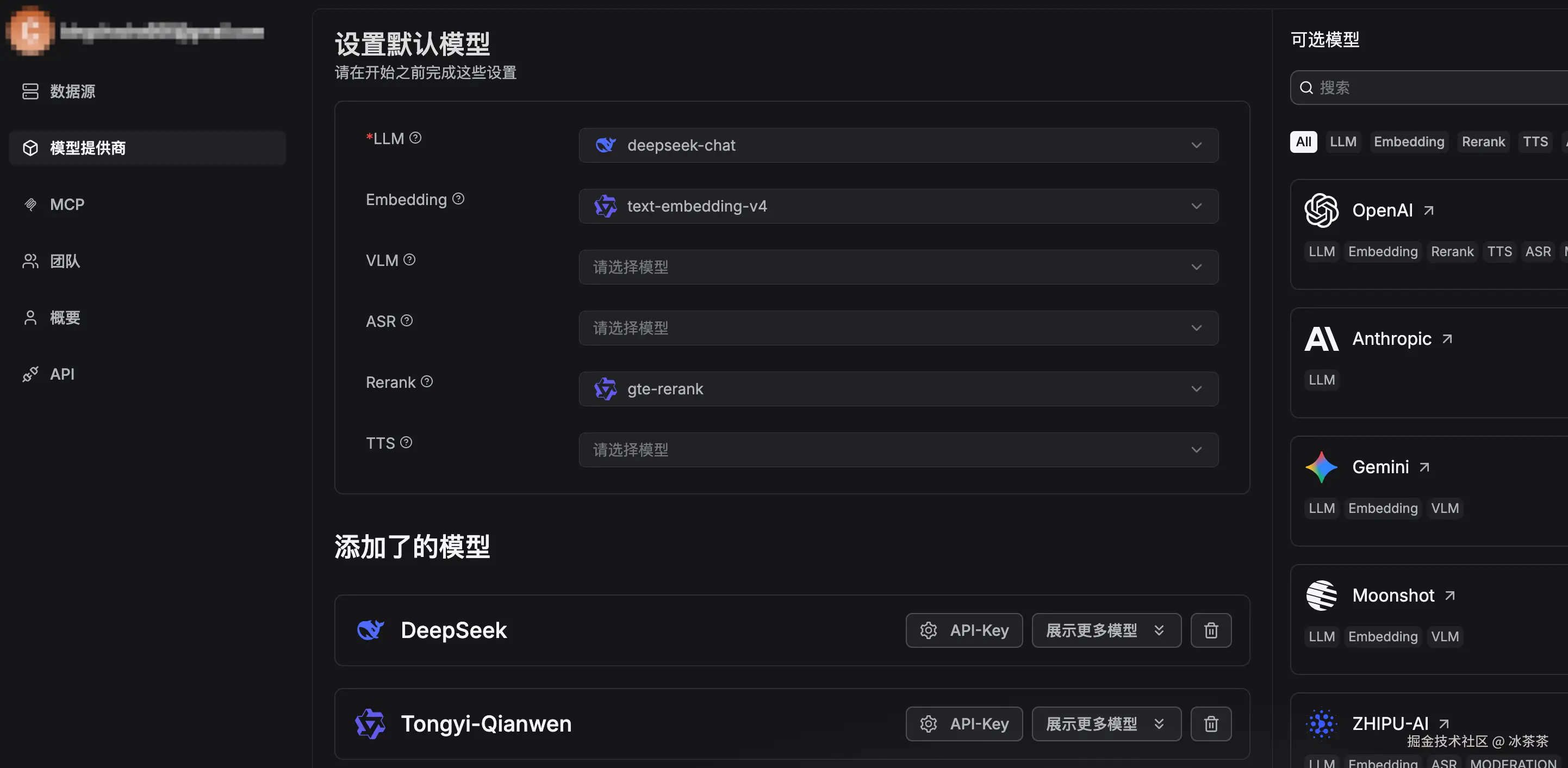
成功跑起来以后就可以在打开本机 IP 后进入图形化配置界面了,首先我们把必须的一些模型给配置好,冲着方便和便宜我就选了 deepseek 和通义千问的模型。
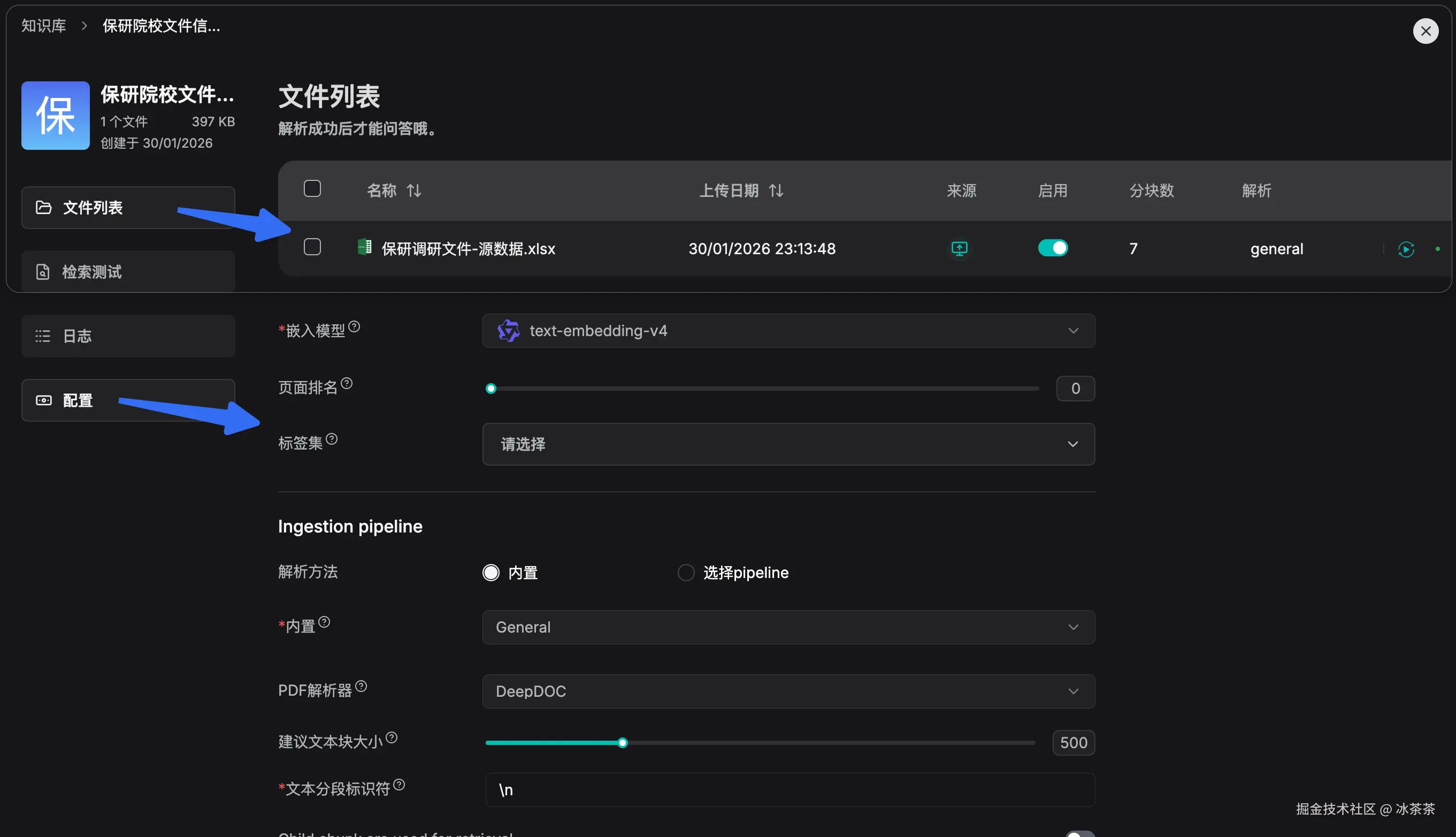
然后我们就可以去处理我们的数据集了,我们可以上传我们的源数据(我这里是一个 xlsx 文件),在配置页面可以去选择和试错一些参数,然后点击运行解析就完成了,整个过程非常傻瓜式,
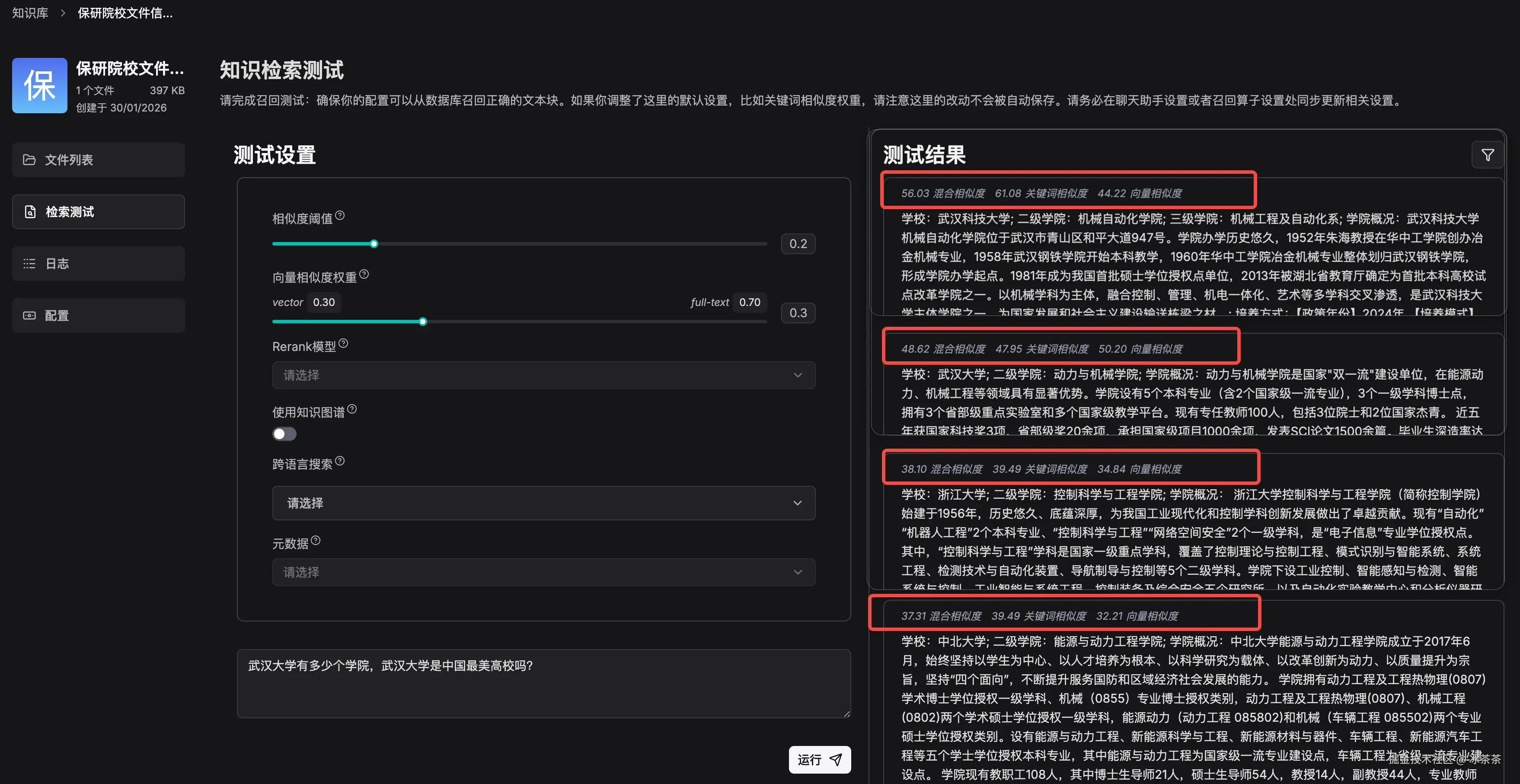
然后我们可以在测试页面去进行「检索测试」,比如输入一个问题,然后看看右侧召回的片段分别有哪些,并且在召回片段上侧还会返回混合相似度供参考,你可以根据这些来判断 Embedding 结果是否尽如人意。
当然,我们还可以稍微精细化一点,即自己创建一个 workflow 工作流来进行数据集处理(其实和上面的简化形式差不太多);
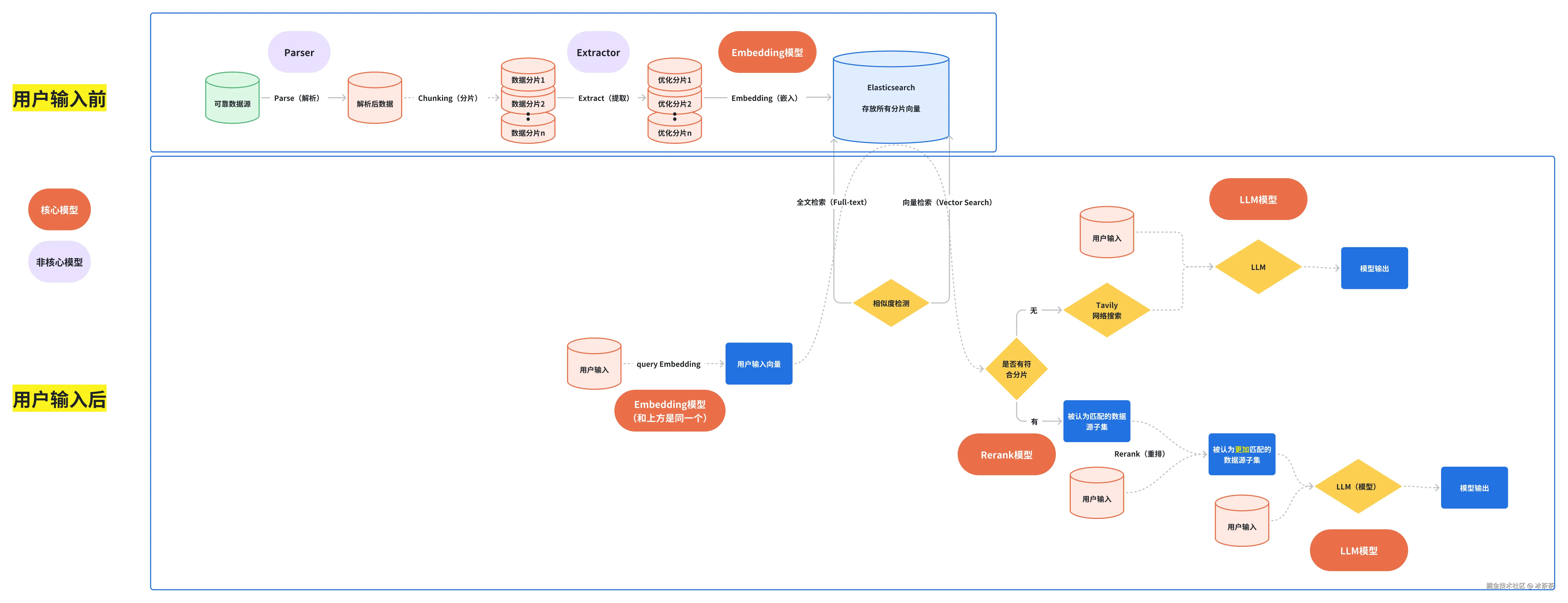
其实这一条 workflow 就像是 RAG 系统中的“后厨”逻辑,对我们的数据集进行各种拆解方便后续的大快朵颐:
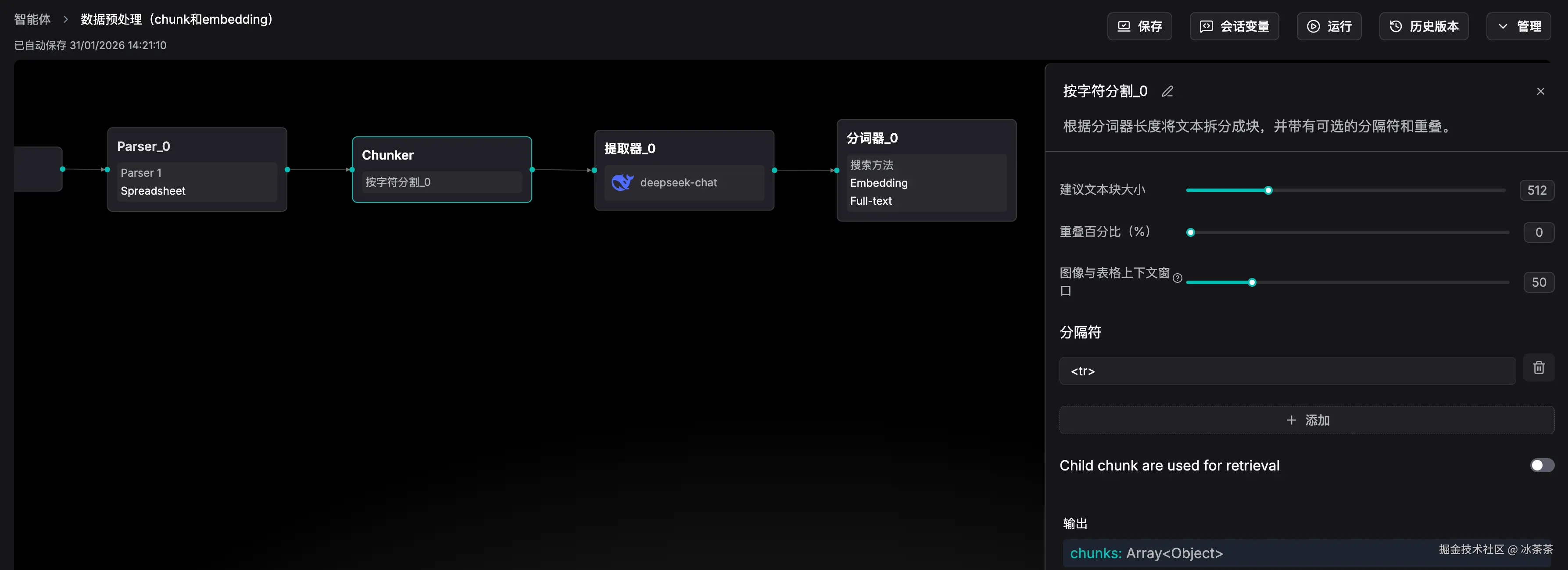
Parser(解析器):如果你使用不同的文件,比如 PDF、Word、Excel 等不同形式的文件,可能会有不同的效果更好的处理方式,解析器的任务是把我的数据源文件里的文字提取出来,并且最好适配原始的格式;你可以使用 RAGFlow 自带的 Parser,或者自己使用一些 Parser 模型,比如在这个流中我选择了 Spreadsheet(电子表格)类型,并使用了 qwen2-vl-plus(多模态大模型)作为解析方法
Chunker(分块器):这里很好理解,就是先将我们的数据源进行分块处理,不然后续的片段查找就没意义了。现在的分块算法应该有挺多的,但是我不是特别了解这块,我在这里选择了 作为分隔符(因为我的表格会在Parse 过程中被转化成一个 HTML Table 对象)
Extractor(提取器):这个流程非必须,但是却可以帮助我们提高分片数据和整个 RAG 流程的质量,比如提取器可能会利用大模型把这段话重写或提取 Metadata (关键标签),相当于将一些原始的分片数据转化成了带有标签和摘要的精品分块,这样可以极大增加搜索时的命中率,因为模型不仅能搜到字面意思,还能理解这一块内容到底在讲什么。这里我使用 deepseek-chat模型对每个小块进行深加工
Embedding(嵌入,分词器):通过 Embedding 模型我们最终可以将分片数据转化成一串长长的数字列表,也就是前文说的高维向量,同时现在的嵌入模型还会做 Full-text(全文索引),通过建立关键词索引可以使得后续查询的时候不仅仅根据语义的相似度进行检索,还可以基于一些全文匹配的方式来辅助检索
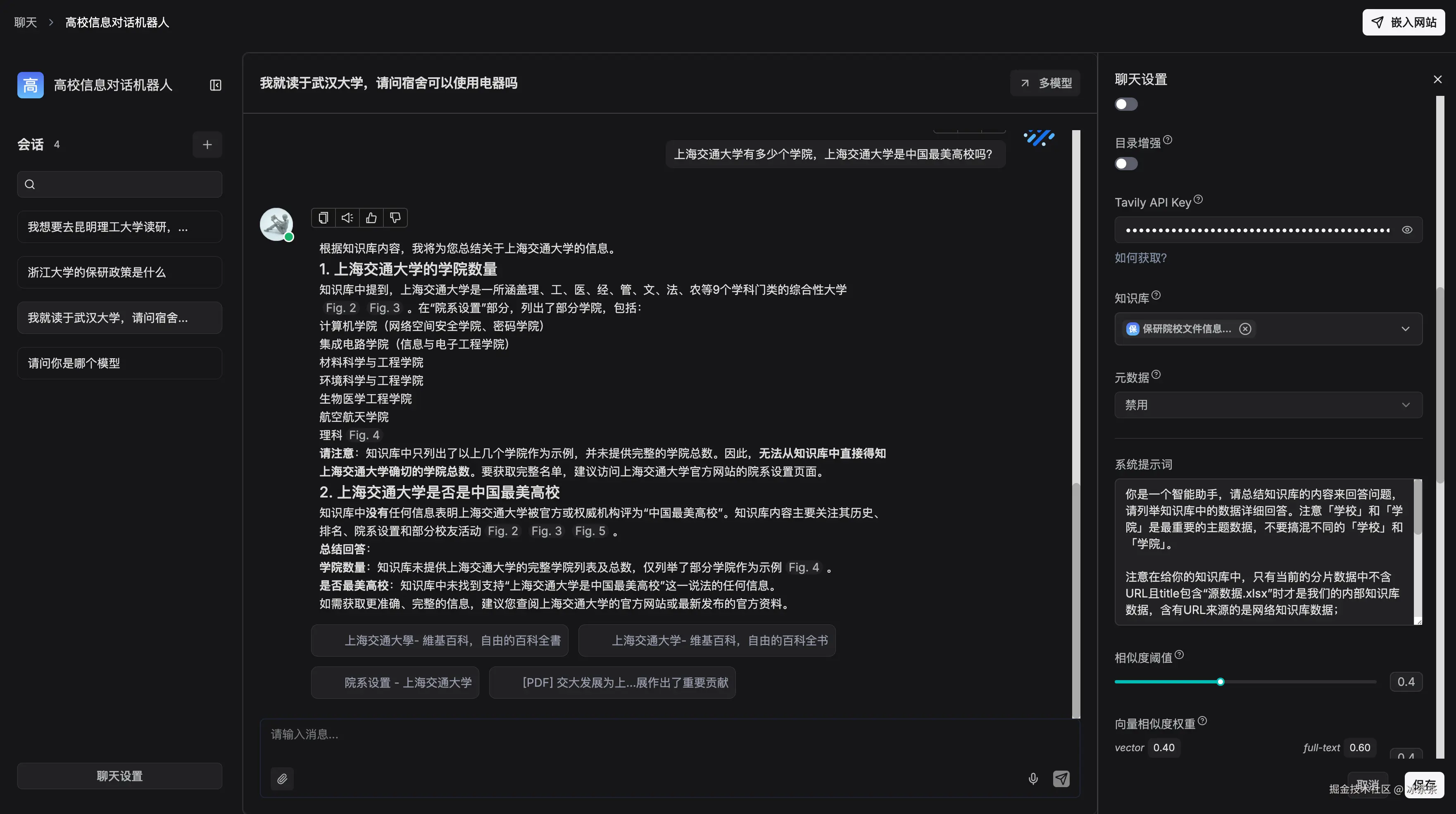
接下来的事情更加简单,我们直接建立一个 Chat 项目,在这个页面去配置一些系统提示词、选择已经处理好后的数据集、增加一些兜底措施、试图微调参数等。
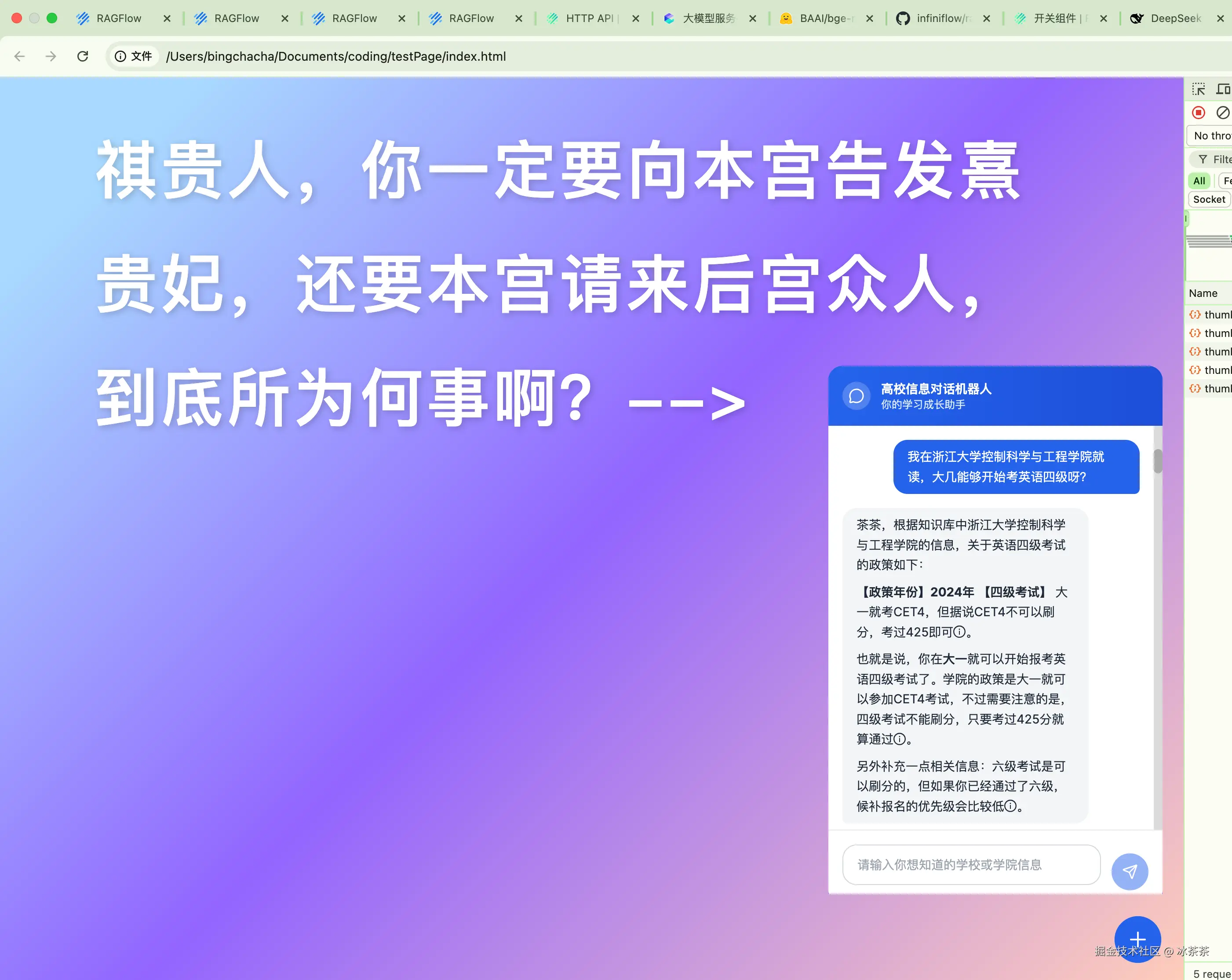
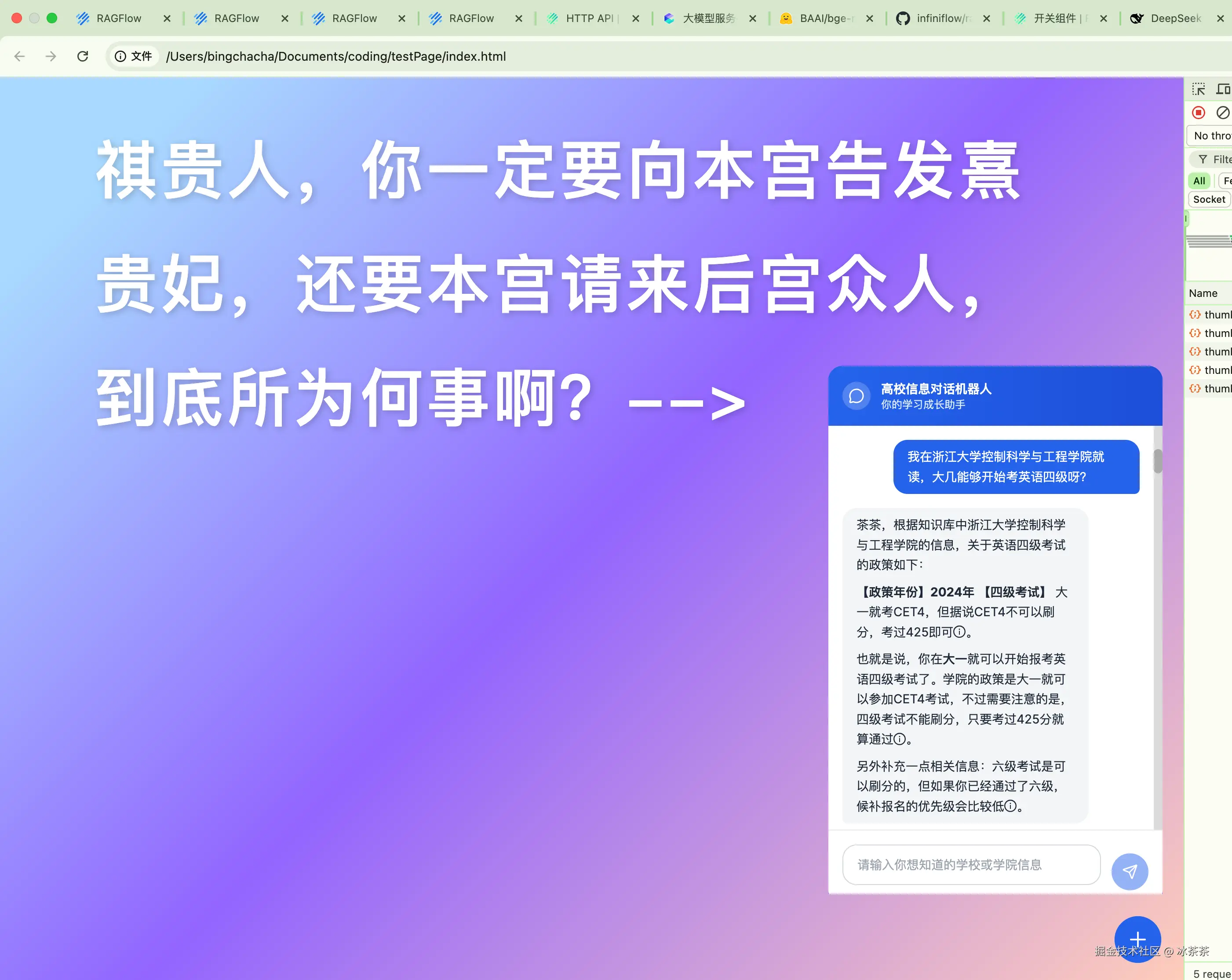
然后我们就可以拿着调试好的成果去应用到我们自己的前端页面啦~只要复制好系统给的代码样例,然后就能来到我们文章开头的那一幕:
那么一个非常粗糙的基于我们自己数据集的聊天机器人就完成啦,依托于各种低代码配置,我只花了一天半的时间就完成了,并且还对整个 RAG 有了一些开天辟地的认知。
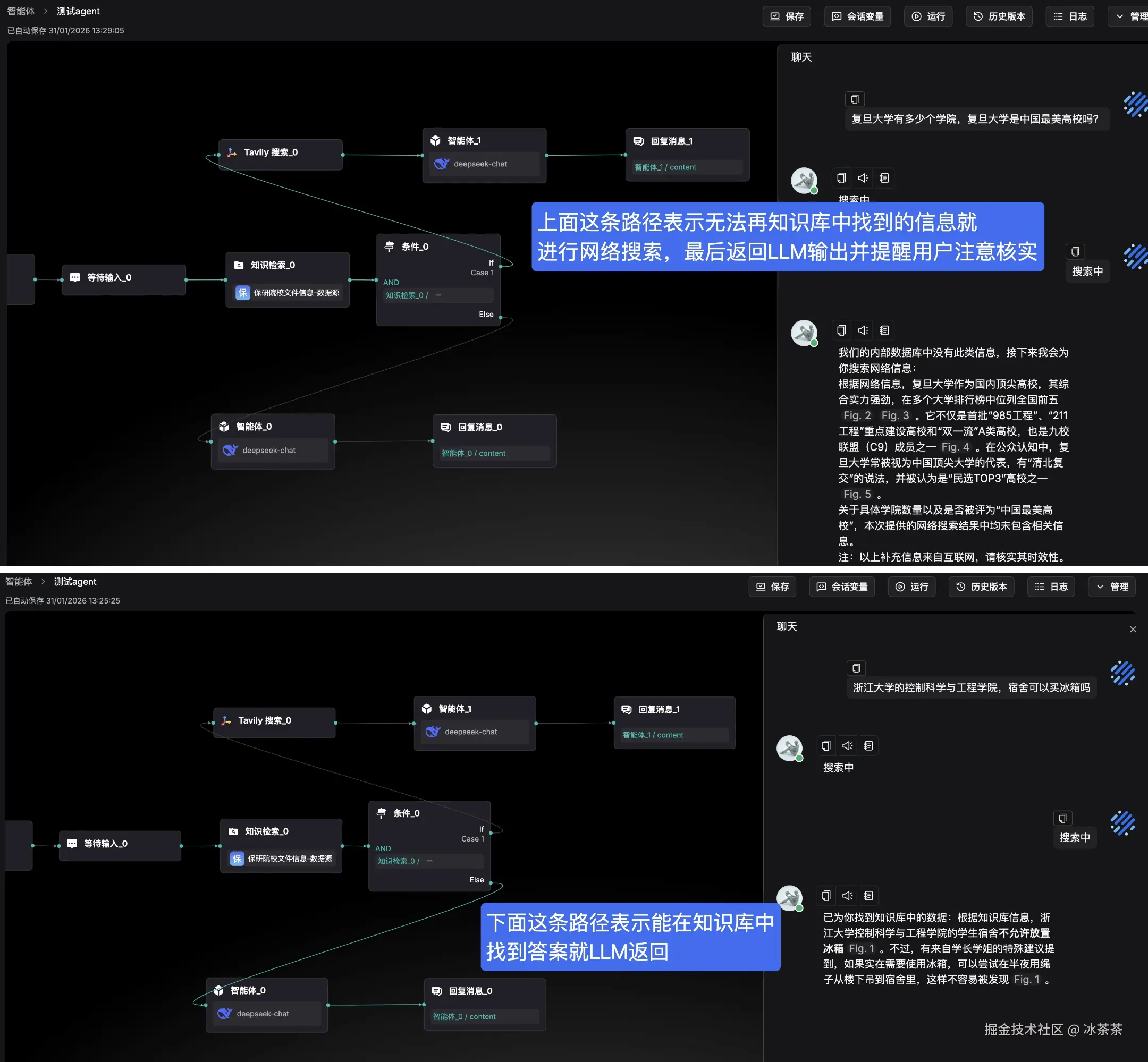
当然,越是操作简单无代码就说明可配置性越不够灵活嘛,其实我们还可以用其中的 agent Flow 模式来写我们的前端聊天逻辑,下图就非常清晰了:对于我们可靠数据源中能查到的信息我们直接返回并且告诉用户这是可靠信息,否则就使用网络搜索作为兜底并且提醒用户注意核实网络信息。(而这一点在上面那个更傻瓜式的配置界面不是特别好实现,只能在 Prompt 中做一些 hack 提示,但这里就会比较灵活)
如果需要更加灵活的方式那应该就需要涉及到写更多的代码了,比如就用 LangChain 来自己去写各种模块的内在逻辑和流程,这个就看业务的需求和复杂度了~
现在让我再来基于上面我所做的事情梳理一个更清晰的流程图:
得益于各种开源工具和生态,让我这个2026年才开始接触和学习 AI 的人也能上手做一些东西,而且学习 一样事物的最快方法确实就是实践,先去网上看几十个小时的视频再来动手绝对会耗费大量的热情,而且现在各种 chat 模型已经可以充当非常好的指路人了。
多说无益,让我们一起加油,因为从什么时候开始都不晚~
308.71MB · 2026-02-05
308.71MB · 2026-02-05
339.21MB · 2026-02-05

