妖媚琉璃
81.71M · 2026-03-26

# 数据的导入
import pandas as pd
df= pd.read_csv('data/data.csv')
#数据的导出
df= df.tail()
df.to_csv('data/output.csv')
# 简单json
df= pd.read_json('data/data.json')
# 复杂json
import json
with open('data/data_complex.json') as f:
data = json.load(f)
import pandas as pd
import numpy as np
s=pd.Series([1,2,np.nan,None,pd.NA])
df=pd.DataFrame([[1,pd.NA],[2,3,5],[None,4,6]],columns=['第一列','第二列','第三列'])# # # 查看是否是缺失值
print(s.isna())
print(s.isnull())
print(df.isna())
print(df.isnull())
print(df.isna().sum(axis=1))
print(s.isna().sum()) # 查看缺失值的个数
# 剔除缺失值
print(s.dropna())
print(df.dropna())
print(df.dropna(how='all')) # 如果所有的值都是缺失值,删除这一行
print(df.dropna(thresh=2)) # 如果至少有n个值不是缺失值,就保留
print(df.dropna(axis=1)) # 剔除一整列的记录
print(df.dropna(subset=['第一列'])) # 如果某列有缺失值,则删除这一行
# 填充缺失值
df=pd.read_csv('data/data_withNA.csv')
df.isna().sum(axis=0)
print(df.fillna({'join_date':20})) # 使用字典来填充
print(df.fillna(df[['age']].mean())) # 使用统计值来填充
print(df.ffill()) # 用前面的相邻值填充
print(df.bfill()) # 用后面的相邻值填充
import pandas as pd
data = {
"name":['alice' ,'alice' ,'bob' ,'alice' ,'jack' ,'bob' ],
"age": [26,25,30,25,35,30],
"city":['NY' ,'NY' ,'LA' ,'NY' , 'SF' , 'LA' ]
}
df=pd.DataFrame(data)
df.duplicated() # 一整条记录都是一样的,标记为重复,返回True
df.drop_duplicates(subset=['name'])# 根据指定列去重
df.drop_duplicates(subset=['name'],keep='last') # 保留最后一次出现的行
df['age']=df['age'].astype('int16')
import pandas as pd
data = {
'ID': [1, 2],
'name' : ['alice', 'bob' ],
'Math': [90, 85],
'English': [88, 92],
'Science': [95, 89]
}
df = pd.DataFrame(data)
df.T # 转置
#宽表转换为长表
df2=pd.melt(df,id_vars=['ID','name'],var_name='科目',value_name='分数')
df2.sort_values('name') #排序
#长表转宽表
pd.pivot(df2,index=['ID','name'],columns='科目',values='分数')
data = {
'ID': [1, 2],
'name' : ['alice smith' , 'bob smith' ],
'Math': [90, 85],
'English': [88, 92],
'Science': [95, 89]
}
df = pd.DataFrame(data)
# 分列
df[['first','last']]= df['name'].str.split(' ',expand=True)
# 数据分箱 pd.cat(x,bins,labels)
df1=df.head(5)[['id','age']]
pd.cut(df1['age'],bins=2) # bins=n,分成n段区间,起始值、结束值是所有数据的最小值、最大值
pd.cut(df1['age'],bins=2).value_counts()
pd.cut(df1['age'],bins=[0,25,35,45]) # bins=list,分成n段区间
pd.cut(df1['age'],bins=[0,25,35,45]).value_counts()
pd.cut(df1['age'],bins=[0,25,35,45],labels=['幼','中','老'])
pd.qcut(df1['age'],3)
# 重命名
df = pd.DataFrame(
{
'name' : [ 'jack' ,'alice' , 'tom' , 'bob' ],
'age':[20,30,40,50],
'gender' : ['female' , 'male' , ' female' , 'male' ]
}
)
df.set_index('name',inplace=True)
df.reset_index(inplace=True)
df.rename(columns={'age':"年龄"},index={0:4})
df.index=[1,2,3,4]
df.columns=['姓名','年龄','性别']
import pandas as pd
d = pd.Timestamp('2015-05-02 10:22')
print('年:',d.year)
print('季度:',d.quarter)
print('是否是月底:',d.is_month_end)
# 方法
print('星期几:',d.day_name())
print('转换为天:',d.to_period('D'))
print('转换为季度:',d.to_period('Q'))
print('转换为年度:',d.to_period('Y'))
print('转换为月度:',d.to_period('M'))
# 字符串转换为日期类型
a = pd.to_datetime('2015-01-04 10:22')
print(a)
print(type(a))
# dataFrame 日期转换
df= pd.DataFrame(
{
'sales':[100,200,300],
'date':['20250601','20250704','20250506']
}
)
df['datatime']=pd.to_datetime(df['date'])
print(type(df['datatime']))
df['week'] = df['datatime'].dt.day_name()
# 日期数据作为索引
df.set_index('date',inplace=True) # 设置原来的df的索引
#print(df.loc['2025-05-06':'2025-07-04'])
# 时间间隔
d1 = pd. Timestamp('2013-01-15')
d2 = pd.Timestamp('2023-02-23')
d3 = d2-d1
print(type(d3))
# 日期生成
days= pd.date_range('2025-07-03','2026-01-04',freq='W')
print(days)
days= pd.date_range('2025-07-03',periods=10,freq='W')
print(days)
# df.groupby('分组的字段')['聚合的字段'].聚合函数()
# df.groupby('分组的字段').groups # 查看分组
# df.groupby('分组的字段').get_group(n) # 查看具体的某个分组数据
matplotlib 是 Python 中最常用的数据可视化库之一,主要用于绘制 2D 图表(也支持简单的 3D 绘图)。它功能强大、灵活,广泛应用于科学计算、数据分析和机器学习等领域。
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 设置中文字体(确保支持中文显示)
rcParams['font.sans-serif'] = ['STKAITI'] # 使用黑体或华文楷体
# 数据
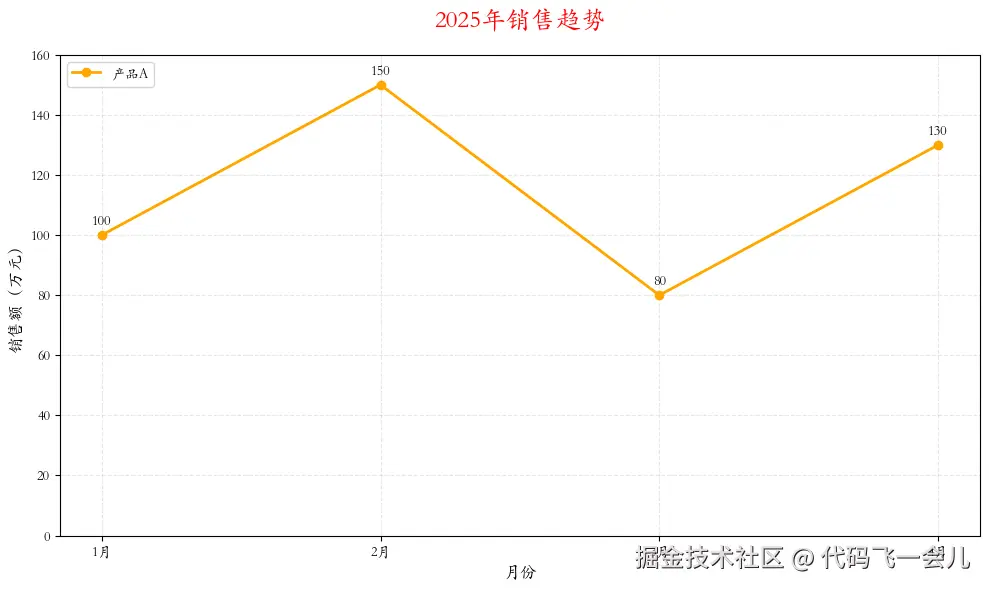
months = ['1月', '2月', '3月', '4月']
sales = [100, 150, 80, 130]
# 创建图形和轴
plt.figure(figsize=(10, 6))
# 绘制折线图
plt.plot(months, sales, marker='o', color='orange', linewidth=2, markersize=6)
# 添加标题
plt.title('2025年销售趋势', fontsize=18, color='red', pad=20)
# 设置坐标轴标签
plt.xlabel('月份', fontsize=12)
plt.ylabel('销售额(万元)', fontsize=12)
# 设置y轴范围
plt.ylim(0, 160)
# 添加网格线
plt.grid(True, alpha=0.3, linestyle='--', linewidth=0.8)
# 添加图例
plt.legend(['产品A'], loc='upper left', frameon=True, fancybox=True, shadow=False)
# 在每个数据点上标注数值
for i, (x, y) in enumerate(zip(months, sales)):
plt.text(x, y + 2, str(y), ha='center', va='bottom', fontsize=10, color='black')
# 调整布局,避免标签被裁剪
plt.tight_layout()
# 显示图表
plt.show()
# 绘制柱状图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(10,5))
# 要绘图的数据
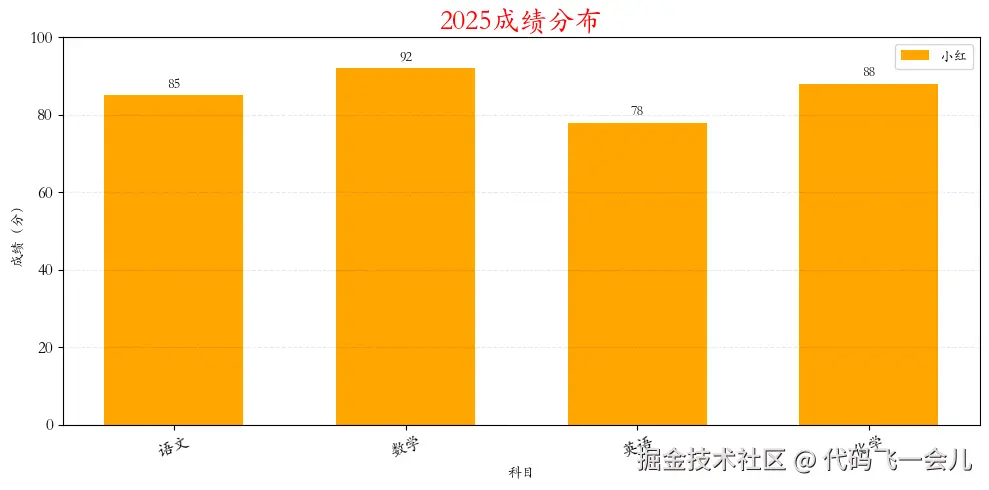
subjects=['语文','数学','英语','化学']
scores=[85,92,78,88]
# 绘制柱状图
plt.bar(subjects,scores,label='小红',color='orange',width=0.6)
# 添加标题
plt.title('2025成绩分布',color='red',fontsize=20)
# 添加坐标轴标签
plt.xlabel('科目',fontsize=10)
plt.ylabel('成绩(分)',fontsize=10)
# 添加图例
plt.legend(loc='upper right')
# 添加网格线
# plt.grid(True,alpha=0.1,color='blue',linestyle='--') # '-':实线 ;'--':虚线
plt.grid(axis='y',alpha=0.1,color='blue',linestyle='--')
# 设置刻度字体大小
plt.xticks(rotation=20,fontsize=12)
plt.yticks(rotation=0,fontsize=12)
# 设置y轴的范围
plt.ylim(0,100)
# 每个数据点上显示数值
for x,y in zip(subjects,scores):
# print(x,y)
plt.text(x,y+1,str(y),ha='center',va='bottom',fontsize=10)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()
# 绘制条形图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(10,5))
# 要绘图的数据
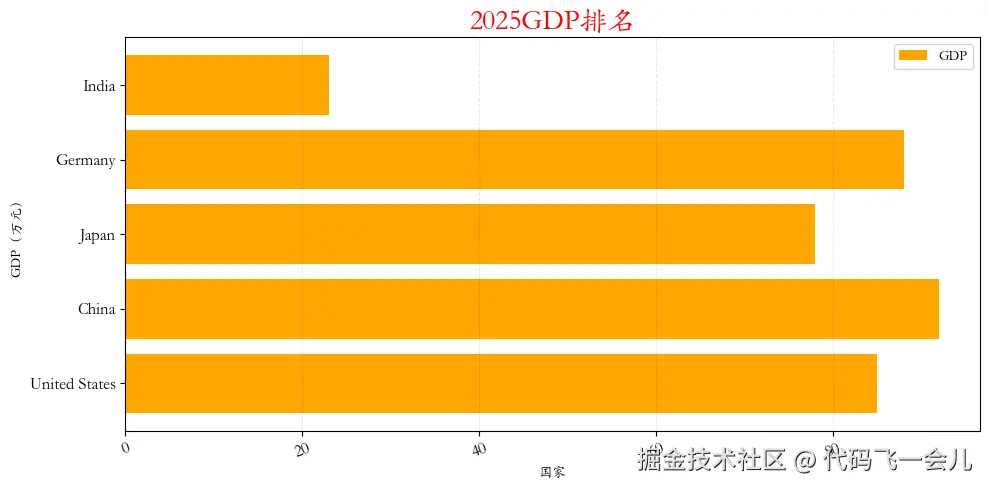
countries=['United States' , 'China' , 'Japan' ,'Germany' , 'India' ]
gdp=[85,92,78,88,23]
# 绘制条形图
plt.barh(countries,gdp,label='GDP',color='orange')
# 添加标题
plt.title('2025GDP排名',color='red',fontsize=20)
# 添加坐标轴标签
plt.xlabel('国家',fontsize=10)
plt.ylabel('GDP(万元)',fontsize=10)
# 添加图例
plt.legend(loc='upper right')
# 添加网格线
# plt.grid(True,alpha=0.1,color='blue',linestyle='--') # '-':实线 ;'--':虚线
plt.grid(axis='x',alpha=0.1,color='blue',linestyle='--')
# 设置刻度字体大小
plt.xticks(rotation=20,fontsize=12)
plt.yticks(rotation=0,fontsize=12)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()
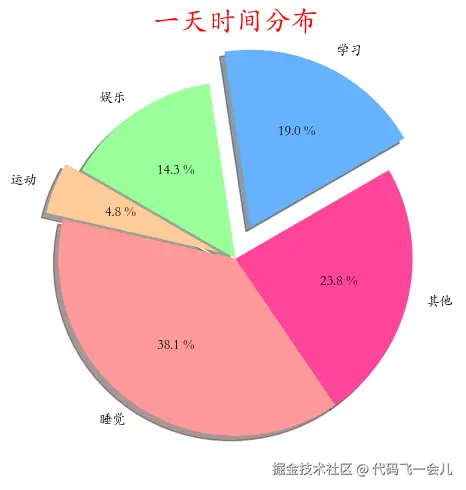
# 绘制饼图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(10,5))
# 要绘图的数据
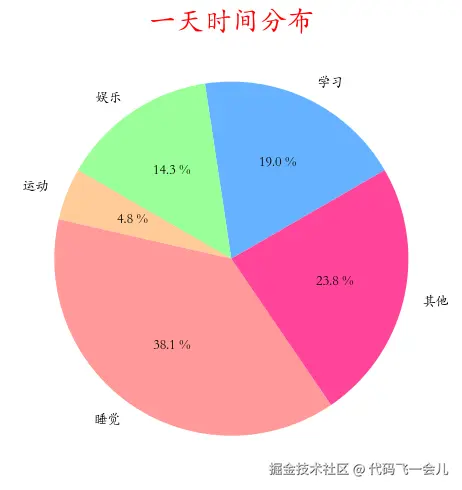
things=['学习','娱乐','运动','睡觉','其他']
times = [4,3,1,8,5]
colors = ['#66b3ff','#99ff99','#ffcc99','#ff9999','#ff4499'] #配色
# 绘制饼图
plt.pie(times,labels=things,autopct='%1.1f %%',startangle=30,colors=colors)# startangle调整初始角度
# 添加标题
plt.title('一天时间分布',color='red',fontsize=20)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()
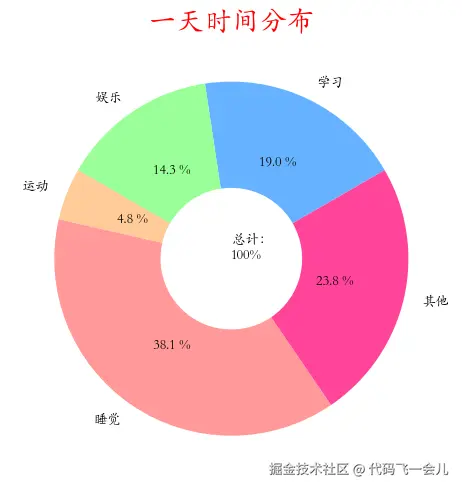
# 绘制环形图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(10,5))
# 要绘图的数据
things=['学习','娱乐','运动','睡觉','其他']
times = [4,3,1,8,5]
colors = ['#66b3ff','#99ff99','#ffcc99','#ff9999','#ff4499'] #配色
# 绘制环形图
plt.pie(times,labels=things,autopct='%1.1f %%',
startangle=30,colors=colors,# startangle调整初始角度
wedgeprops={'width':0.6},# 圆环宽度
pctdistance=0.6)
# 添加标题
plt.title('一天时间分布',color='red',fontsize=20)
plt.text(0,0,'总计:n100%')
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()
# 绘制爆炸式饼图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(10,5))
# 要绘图的数据
things=['学习','娱乐','运动','睡觉','其他']
times = [4,3,1,8,5]
colors = ['#66b3ff','#99ff99','#ffcc99','#ff9999','#ff4499'] #配色
explode = [0.2,0,0.1,0,0]# 设置突出块的位置
# 绘制爆炸式饼图
plt.pie(times,labels=things,autopct='%1.1f %%',startangle=30,colors=colors,explode=explode,shadow=True)# startangle调整初始角度
# 添加标题
plt.title('一天时间分布',color='red',fontsize=20)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()
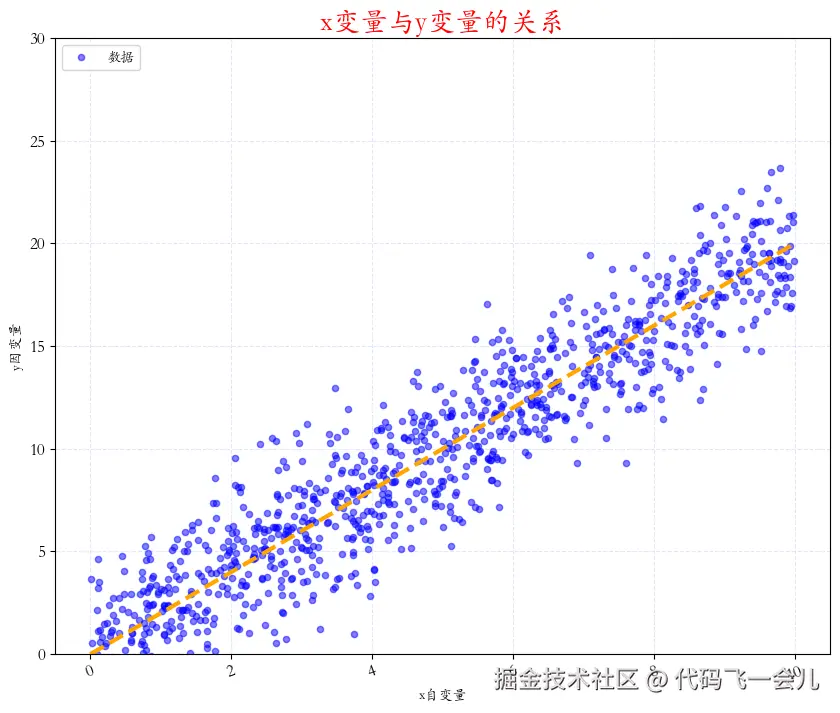
# 绘制散点图
import random
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(10,8))
# 要绘图的数据
x=[]
y=[]
for i in range (1000):
tmp=random.uniform(0,10)
x.append(tmp)
y.append(2*tmp+random.gauss(0,2))
# 绘制散点图
plt.scatter(x,y,color='blue',alpha=0.5,s=20,label="数据")
# 添加标题
plt.title('x变量与y变量的关系',color='red',fontsize=20)
# 添加坐标轴标签
plt.xlabel('x自变量',fontsize=10)
plt.ylabel('y因变量',fontsize=10)
# 添加图例
plt.legend(loc='upper left')
# 添加网格线
plt.grid(True,alpha=0.1,color='blue',linestyle='--') # '-':实线 ;'--':虚线
# plt.grid(axis='x')
# 设置刻度字体大小
plt.xticks(rotation=20,fontsize=12)
plt.yticks(rotation=0,fontsize=12)
# 设置y轴的范围
plt.ylim(0,30)
plt.plot([0,10],[0,20],color='orange',linewidth=3,linestyle='--')
# 显示图表
plt.show()
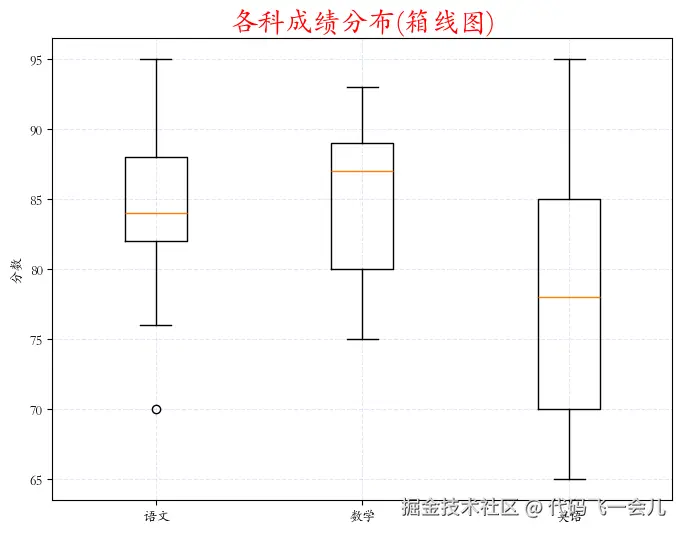
# 绘制箱线图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
#rcParams['font.family'] = 'STKAITI' #华文楷体
rcParams['font.sans-serif'] ='STKAITI' #华文楷体
# 创建图表,设置大小
plt.figure(figsize=(8,6))
# 要绘图的数据
data ={
'语文':[82,85,88,70,90,76,84, 83,95],
'数学':[75,80,79,93,88,82,87,89,92],
'英语':[70,72,68,65,78,80,85,90,95]
}
# 绘制散点图
plt.boxplot(data.values(),tick_labels=data.keys())
# 添加标题
plt.title('各科成绩分布(箱线图)',color='red',fontsize=20)
# 添加坐标轴标签
plt.ylabel('分数',fontsize=10)
# 添加网格线
plt.grid(True,alpha=0.1,color='blue',linestyle='--') # '-':实线 ;'--':虚线
# plt.grid(axis='x')
# 显示图表
plt.show()
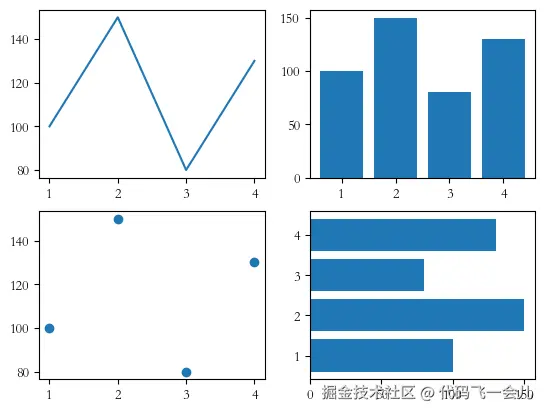
# 多个图的绘制方法
import matplotlib.pyplot as plt
# 要绘图的数据
month = ['1', '2' , '3' , '4' ]
sales = [100,150, 80, 130]
f1 = plt.subplot(2,2,1)# 生成一个子图,行 列 索引(逗号可省略)
f1.plot(month,sales)
f2= plt.subplot(2,2,2)
f2.bar(month,sales)
f3= plt.subplot(2,2,3)
f3.scatter(month,sales)
f4= plt.subplot(2,2,4)
f4.barh(month,sales)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体(可选,英文环境下可注释掉)
plt.rcParams["font.sans-serif"] = ["STKAITI"]
# 原始数据
data = {
'Physics': [78, 85, 92, 68, 88, 80, 94, 73, 87],
'Chemistry': [82, 76, 89, 71, 93, 85, 79, 88, 91],
'Biology': [85, 90, 77, 72, 84, 89, 93, 76, 82]
}
# 转为 DataFrame
df = pd.DataFrame(data)
sns.histplot(data=df, x='Physics')
plt.title('Histogram of Physics Scores')
plt.show()
核密度估计图(KDE,Kernel Density Estimate PLot)是一种用于显示数据分布的统计图表,它通过平滑直方图的方法来估计数据的概率密度函数,使得分布图看起来更加连续和平滑。核密度估计是一种非参数方法,用于估计随机变量的概率密度函数。其基本思想是,将每个数据点视为一个“核”(通常是高斯分布),然后将这些核的贡献相加以形成平滑的密度曲线。 #绘制喙长度的核密度估计图
sns.kdeplot(data=data, x="Physics")
sns.histplot(data=data, x="Physics",kde=True)
计数图用于绘制分类变量的计数分布图,显示每个类别在数据集中出现的次数,是分析分类数据非常直观的工具,可以快速了解类别的分布情况。
# 将 Physics 分数进行分箱处理,转换为分类变量
bins = [0, 60, 70, 80, 90, 100] # 自定义分区
labels = ['0-60', '60-70', '70-80', '80-90', '90-100']
df['Physics_Bins'] = pd.cut(df['Physics'], bins=bins, labels=labels, right=False)
#绘制不同数量的计数图
sns.countplot(data=df, x="Physics_Bins")
data_long = {
'subject': ['Physics', 'Chemistry', 'Biology'] * 9,
'score': [
78, 82, 85,
85, 76, 90,
92, 89, 77,
68, 71, 72,
88, 93, 84,
80, 85, 89,
94, 79, 93,
73, 88, 76,
87, 91, 82
],
'student_group': ['A', 'A', 'A',
'A', 'A', 'A',
'B', 'B', 'B',
'B', 'B', 'B',
'A', 'A', 'A',
'B', 'B', 'B',
'A', 'A', 'A',
'B', 'B', 'B',
'A', 'A', 'A']
}
df = pd.DataFrame(data_long)
#绘制横轴为科目,纵轴为成绩的散点图。可通过hue参数设置不同组别进行对比。
sns.scatterplot(data=df, x="subject", y="score", hue="student_group")
#通过jointplot()函数,设置kind="hex"来绘制蜂窝图。
sns.jointplot (data=data, x="Physics", y="Chemistry", kind="hex")
#通过kdeplot()函数,同时设置x参数和y参数来绘制二维核密度估计图。
sns.kdeplot(data=penguins, x="body_mass_g", y="flipper_length_mm")
#通过fill=True设置为填充,通过cbar=True设置显示颜色示意条。
sns.kdeplot(data=penguins, x="body_mass_g", y="flipper_length_mm",fill=True, cbar=True)
sns.barplot(data=penguins, x="species", y="bill_length_mm",estimator="mean", errorbar=None)
sns.boxplot(data=penguins, x="species", y="bill_length_mm")
小提琴图(Violin Plot)是一种结合了箱线图和核密度估计图(KDE)的可视化图表,用于展示数据的分布情况、集中趋势、散布情况以及异常值。小提琴图不仅可以显示数据的基本统计量(如中位数和四分位数),还可以展示数据的概率密度,提供比箱线图更丰富的信息。
sns.violinplot(data=penguins, x="species", y="bill_length_mm")
成对关系图是一种用于显示多个变量之间关系的可视化工具。它可以展示各个变量之间的成对关系,并且通过不同的图表形式帮助我们理解数据中各个变量之间的相互作用。对角线上的图通常显示每个变量的分布(如直方图或核密度估计图),帮助观察每个变量的单变量特性。其他位置展示所有变量的两两关系,用散点图表示。
sns.pairplot(data=penguins, hue="species")

