





锦书在线
80.52M · 2026-03-21

Agent Skills最近非常火!它最初只是 Claude 中的一个功能模块,但在最近两个月里,随着越来越多开发者体验到其强大与便捷,Codex、Cursor、OpenCode 等主流 AI 编程工具也相继加入了对 Agent Skills 的支持。就连我日常使用最频繁的字节跳动旗下工具 Trae,也于近期集成了这一能力。
2025 年 12 月 18 日,Anthropic 正式将 Agent Skills 发布为开放标准,标志着它正与 MCP 一样,朝着通用化、跨平台化的规范方向发展。如果大家还不熟悉 Agent Skills,也无需担心——本文将带大家系统梳理其技术原理,解析关键设计模式,并通过实战代码为大家完整解读 Agent Skills 的核心内容。
这里同样宣传一下笔者正在编写的专栏:《大模型训练指南》,该专栏预计会有50期内容,将系统拆解从数据处理、模型训练到强化学习与智能体开发的全流程,并带大家从零实现模型,帮助大家掌握大模型训练的全技能,真正掌握塑造智能的能力!
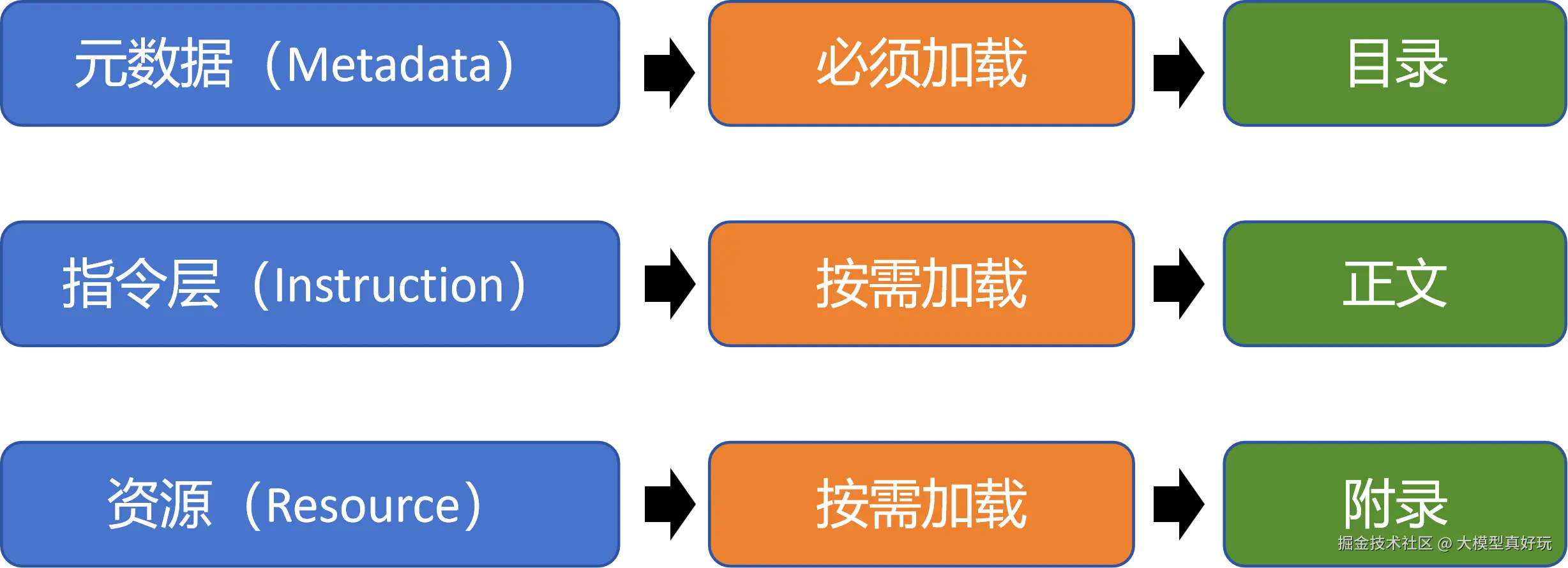
如果用一句话概括,Agent Skills 就像一份“带目录的说明书” 。更专业地说,它是一种渐进式披露的提示词管理机制。
该规范将提示词分为三个层次:
其中,只有元数据层默认被加载到大模型的上下文中,其余两层均为按需加载。大家可以这样理解:
智能体在执行时,首先仅载入“目录”(元数据),随后根据实际需求,再决定是否查阅该目录下的“正文”(指令)与“附录”(资源)。
与传统的完整 Prompt 或 MCP 方式相比,Agent Skills 最显著的优势在于大幅降低了 Token 消耗与提示词的复杂度,使智能体的能力扩展更加轻量与高效。
当然,仅理论描述仍显抽象。接下来笔者将通过一个 Claude Skills 的实际案例,带大家直观理解 Agent Skills 是如何运作的。
既然 Skills 规范由 Anthropic 公司提出,笔者就以 Claude Code 为例,首先介绍其基本用法。
npm install -g @anthropic-ai/claude-code命令, 安装完成后,可通过 claude --version 验证是否安装成功。C:Users{你的用户名}.claude 目录下(若无则新建),创建 settings.json 文件,并填入以下配置:{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你注册的智谱api key(大家可以买套餐注册)",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1
}
}
4. 完成基础配置: 在 C:Users{你的用户名} 目录下,创建 .claude.json 文件并写入以下内容,配置完成后,请重新启动命令行窗口以使环境变量生效:
{ "hasCompletedOnboarding": true }
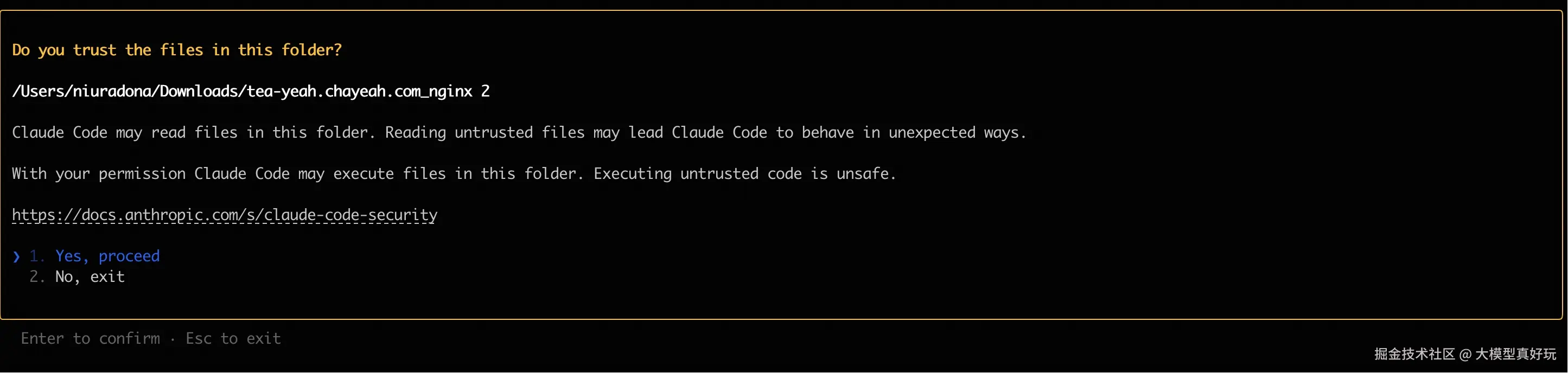
5. 启动与使用: 新建一个项目目录,通过命令行进入该目录后,执行 claude 命令即可启动。首次在某个目录使用时,系统可能会询问是否信任该目录,选择 YES 即可。
下面笔者将通过一个实战案例(思路参考自 @技术爬爬虾)来演示如何创建并使用一个 Skill。
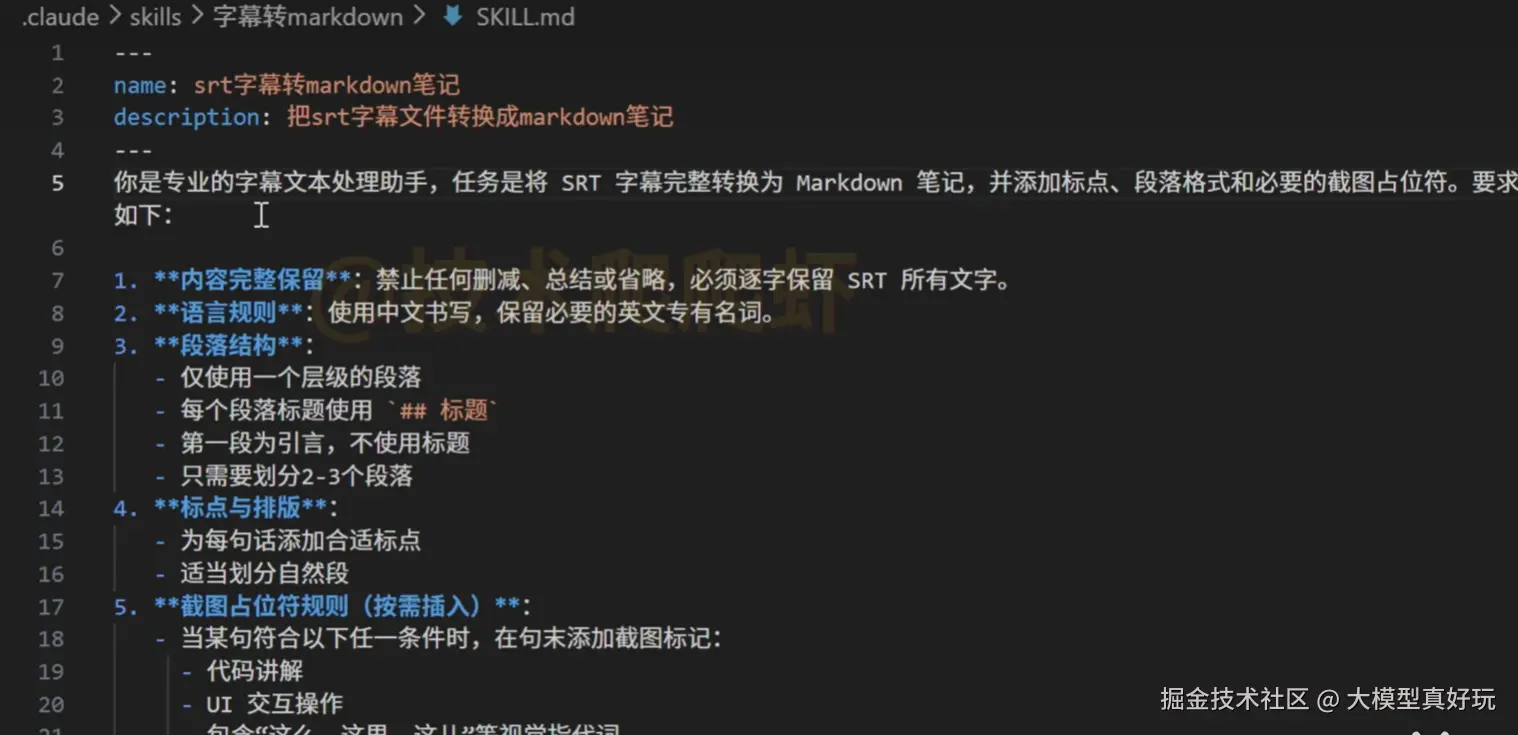
项目目录/.claude/skills/ 路径下。每个 Skill 都是一个独立的文件夹,其中必须包含一个名为 SKILL.md 的定义文件(注意大写)。此文件包含了该 Skill 的元数据层和指令层。此外,文件夹内还可存放其他辅助文件,它们构成了 Skill 的资源层。skill-project)下,依次创建 .claudeskills字幕转markdown 文件夹,并在其中创建 SKILL.md 文件(注意名称必须为SKILL.md,大小写都要一致)。SKILL.md 文件中首先写入元数据,元数据用于描述 Skill 的基本信息,需用 --- 包裹。它会被优先加载到大模型上下文中,相当于“能力目录”。---
name: srt字幕转markdown笔记
description: 把srt字幕文件转换为markdown笔记
---
4. 编写 Skill 指令: 在SKILL.md 文件中元数据后面紧接着编写指令部分,指令部分定义了 Skill 的具体操作逻辑和详细要求,采用 Markdown 格式编写。
你是专业的字幕文本处理助手,任务是将sRT 字幕完整转换为 Markdown 笔记,并添加标点、段落格式和必要的截图占位符。要求
如下:
1.**内容完整保留**:禁止任何删减、总结或省略,必须逐字保留 SRT 所有文字。
2.**语言规则**:使用中文书写,保留必要的英文专有名词。
3.**段落结构**:
-仅使用一个层级的段落
-每个段落标题使用## 标题
-第一段为引言,不使用标题
-只需要划分2-3个段落
4. **标点与排版**:
-为每句话添加合适标点
-适当划分自然段
5.**截图占位符规则(按需插入)**
-当某句符合以下任一条件时,在句末添加截图标记:
-代码讲解
-UI 交互操作
-包含"这么、这里、这儿"等视觉指代词
-提及网址/链接/地址(包括 GitHub、API endpoint等)
-任何借助视觉材料更易理解的内容
-形式必须严格为:
```
Screenshot-[hh:mm:ss]
```
-仅在真正有助理解时插入,不可滥用
比如:
```
原始SRT
00:02:08,600-->00:02:09,800
安装这个工具
```
6. **输出文件格式**:
- 生成内容保存为单个Markdown 文件,命名为:
```
项目根目录/xxx.md
```
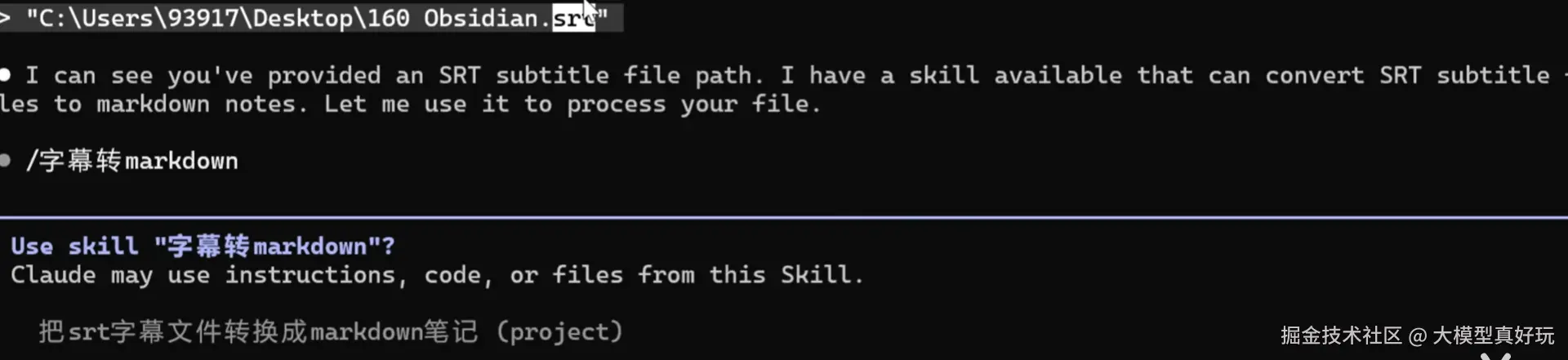
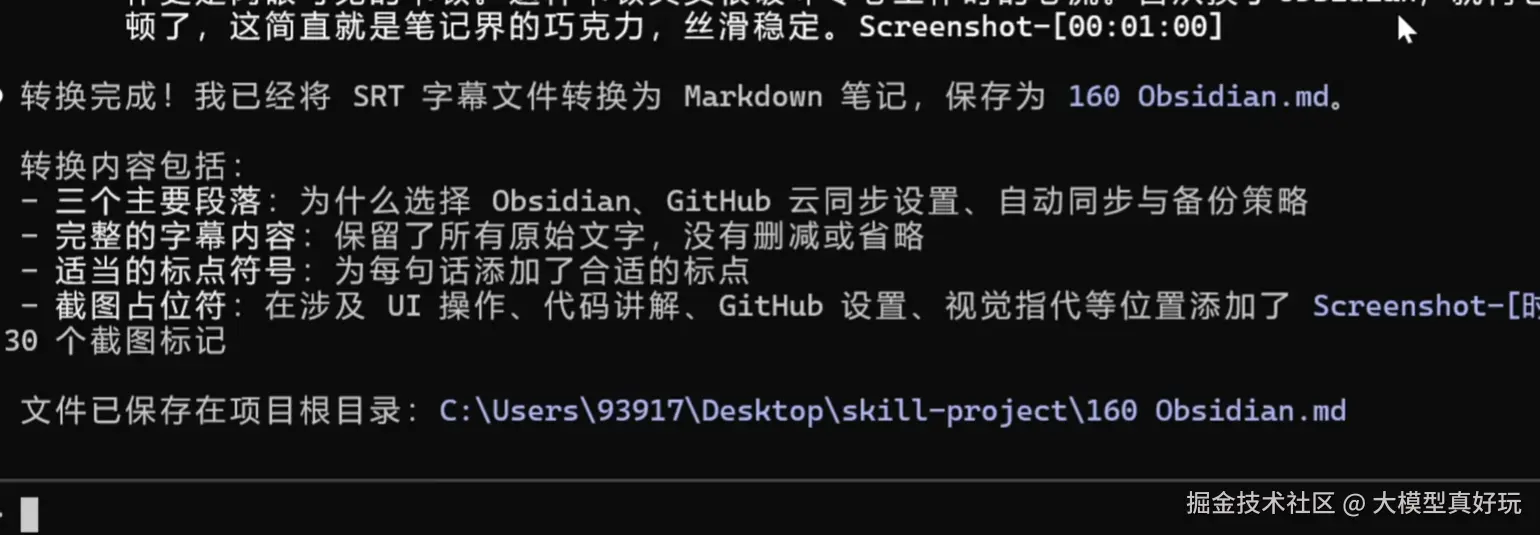
/skills,即可看到已定义好的 Skill。.srt 字幕文件拖入 Claude Code 命令行。此时,大模型仅加载了 SKILL.md 中的元数据(“目录”),识别出这是一个字幕文件,并询问是否使用对应的 Skill。SKILL.md 中详细的指令部分(“正文”)加载到上下文中,并开始执行转换任务。这就是 “渐进式披露提示词” 机制的核心体现:按需加载,显著节省 Token,这样大家是不是就理解了Skills设计的核心概念啦!一个 Skill 的强大之处在于可以集成各种资源文件(脚本、文档、图片等),以实现更复杂的自动化工作流。下面笔者就继续优化字幕转markdown skills,让其功能变得更强大!
scripts, references, assets)来分类存放资源文件,使结构更清晰。资源文件可以是
可执行脚本、补充说明文档,也可以是图片等其它资源,标准做法是将可执行Python文件放到scripts子文件夹中,把文档放到references这个子文件夹里面,把图片等其它资源放到assets子文件夹里面。字幕转markdown 这个 Skill 的目录下,创建一个 scripts 子文件夹,并放入一个 Python 脚本 screenshot.py。该脚本的功能是:根据 Markdown 中生成的截图标记(如 Screenshot-[00:03:12]),调用 ffmpeg 从对应的视频文件中截取相应时间点的画面,并将标记替换为实际的图片链接。import argparse
import json
import logging
import os
import re
import subprocess
from pathlib import Path
from typing import Iterable, List, Optional, Tuple
def write_note(filename: str, markdown: str) -> Path:
path = Path(f"output/{filename}.md")
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(markdown, encoding="utf-8")
logging.info("Saved note backup: %s", path)
return path
# ---------- 截图 ----------
def extract_screenshot_markers(markdown: str) -> List[Tuple[str, int]]:
"""
找到 Screenshot-00:03:12 或 Screenshot-[00:03:12] 形式的标记。
"""
pattern = r"(?:*?)Screenshot-(?:[(d{2}):(d{2}):(d{2})]|(d{2}):(d{2}):(d{2}))"
results: List[Tuple[str, int]] = []
for match in re.finditer(pattern, markdown):
hh = match.group(1) or match.group(4)
mm = match.group(2) or match.group(5)
ss = match.group(3) or match.group(6)
total_seconds = int(mm) * 60 + int(ss)
results.append((match.group(0), total_seconds))
return results
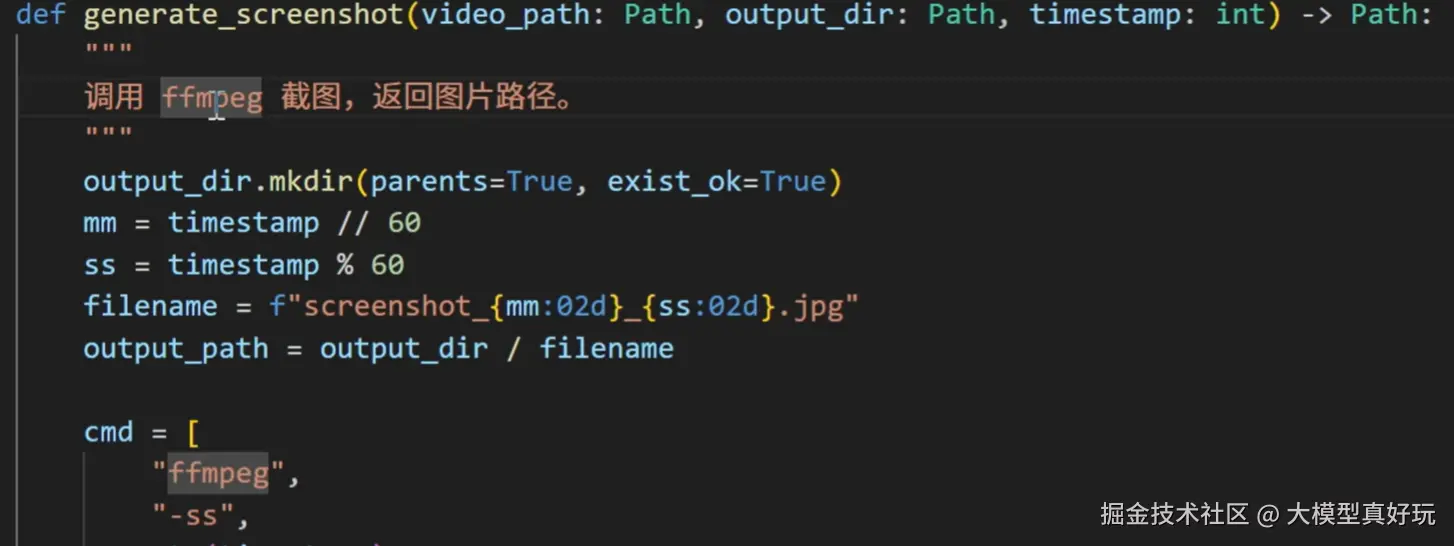
def generate_screenshot(video_path: Path, output_dir: Path, timestamp: int) -> Path:
"""
调用 ffmpeg 截图,返回图片路径。
"""
output_dir.mkdir(parents=True, exist_ok=True)
mm = timestamp // 60
ss = timestamp % 60
filename = f"screenshot_{mm:02d}_{ss:02d}.jpg"
output_path = output_dir / filename
cmd = [
"ffmpeg",
"-ss",
str(timestamp),
"-i",
str(video_path),
"-frames:v",
"1",
"-q:v",
"2",
str(output_path),
"-y",
]
logging.info("生成截图:time=%s, file=%s", timestamp, output_path)
subprocess.run(cmd, check=False, capture_output=True)
return output_path
def replace_screenshots(
markdown: str,
video_path: Optional[Path],
output_dir: Path,
image_base_url: str,
) -> str:
"""
将 Screenshot 标记替换为实际图片链接;没有视频时保持原样。
返回修改后的 markdown。
"""
if not video_path:
logging.info("未提供视频文件,保留 Screenshot 标记不变。")
return markdown
matches = extract_screenshot_markers(markdown)
for idx, (marker, ts) in enumerate(matches):
try:
img_path = generate_screenshot(video_path, output_dir, ts)
url = f"{image_base_url.rstrip('/')}/{img_path.name}"
markdown = markdown.replace(marker, f"", 1)
except Exception as exc: # pylint: disable=broad-except
logging.warning("生成截图失败(%s):%s", marker, exc)
return markdown
def main():
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
)
parser = argparse.ArgumentParser(description="将 SRT/视频转换为 Markdown 笔记")
args = parser.parse_args()
logging.info("环境变量加载完成。")
#从当前工作目录自动查找对应的 SRT 和 MP4 文件
cwd = Path.cwd()
md_path: Path
video_path: Path
# 附件文件夹
image_base_url = "assets"
screenshots_path = Path(f"output/{image_base_url}")
md_candidates = sorted(cwd.glob("*.md"))
if not md_candidates:
raise RuntimeError("当前目录没有找到任何 .md 文件,请把字幕文件夹导出并且放到根目录下。")
if len(md_candidates) > 1:
logging.warning("当前目录中发现多个 .srt,将使用第一个:%s", md_candidates[0])
md_path = md_candidates[0]
mp4_candidates = sorted(cwd.glob("*.mp4"))
if mp4_candidates:
preferred: Optional[Path] = None
video_path = preferred or mp4_candidates[0]
if len(mp4_candidates) > 1 and preferred is None:
logging.warning("当前目录中发现多个 .mp4,将使用第一个:%s", video_path)
else:
logging.info("当前目录未发现 .mp4,将保留 Markdown 中的 Screenshot 标记不变。")
video_path = None
# 读取 markdown 文件内容
markdown = md_path.read_text(encoding="utf-8")
logging.info("读取 Markdown 文件:%s", md_path)
processed_md = replace_screenshots(markdown, video_path=video_path, output_dir=screenshots_path, image_base_url=image_base_url)
logging.info("截图处理完成")
# 备份替换后的 Markdown 内容
output = write_note("note_processed", processed_md)
info = {
"output": str(output),
"screenshots_dir": str(screenshots_path),
"video_used_for_screenshot": str(video_path)
}
print(json.dumps(info, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
SKILL.md 的指令部分末尾,添加调用该脚本的步骤:7.**后续处理**:
markdown生成完毕以后,调用
python scripts/screenshot.py
对视频进行截图,执行python脚本时不需要传递任何参数
4. 运行完整的 Skill 工作流:
1. 将待处理的视频文件 .mp4 也放入项目根目录。
2. 在 Claude Code 中,再次拖入 .srt 字幕文件。
3. Claude Code 将首先执行“字幕转Markdown”任务,生成一份带有 Screenshot-[hh:mm:ss] 标记的笔记。
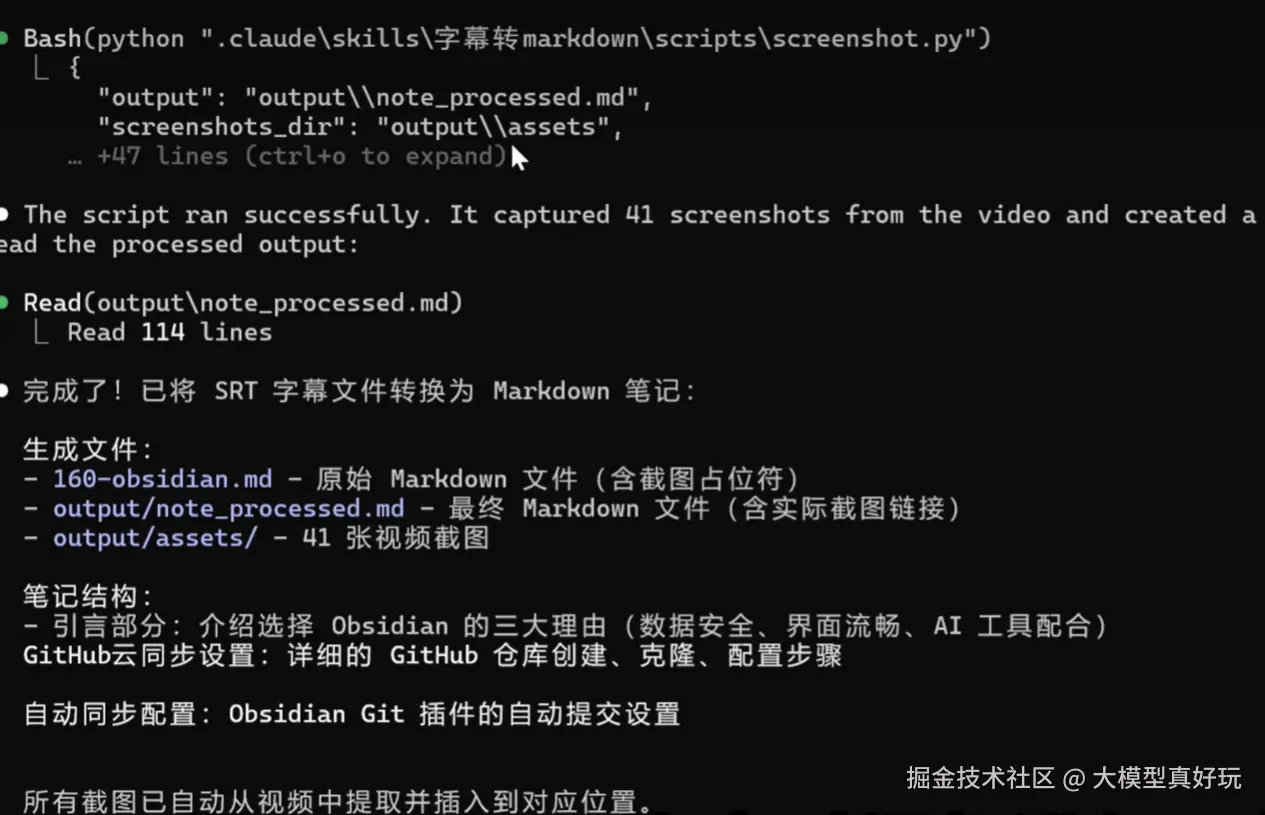
4. 接着,它会自动执行 python scripts/screenshot.py 命令。关键点在于:脚本代码本身不会作为提示词上下文传递给大模型,Claude Code 只是作为执行环境去运行它。这再次体现了 Skills 机制在降低上下文消耗上的优势。
5. 脚本运行后,最终生成一份包含实际截图链接的、图文并茂的 Markdown 笔记。
许多读者询问笔者:同样出自 Anthropic,Skills 与 MCP(Model Context Protocol)究竟有何不同?
实际上,Skills 与 MCP 是两个目标不同、互为补充的规范。它们虽有部分功能重叠,但设计侧重点和使用场景有显著差异:
简单类比:
若大家对 MCP 的具体实现与原理感兴趣,可进一步阅读笔者之前的文章:《理论+代码一文带你深入浅出MCP:人工智能大模型与外部世界交互的革命性突破》。
为更直观对比,以下从几个维度总结二者的主要区别:
| 维度 | Agent Skills | MCP |
|---|---|---|
| 侧重点 | 提示词的结构化组织与渐进式加载 | 外部工具与服务的标准化调用 |
| 类比 | 带目录的说明书 | 标准化工具箱 |
| Token 消耗 | 低(仅按需加载指令与资源) | 较高(需携带工具描述与调用逻辑) |
| 核心主体 | Markdown 文件(SKILL.md) | 软件包/服务(含协议与实现) |
| 编写与部署难度 | 低(文件级配置,易于本地管理) | 较高(需遵循协议,常涉及服务端开发) |
总的来说,Skills 更适合轻量化、提示词驱动的能力扩展,而 MCP 更适合复杂、需频繁调用外部工具或服务的场景。在实际项目中,二者亦可结合使用,例如通过 MCP 提供工具,再通过 Skills 组织调用这些工具的提示词流程,从而实现更高效、可维护的智能体架构。
本篇分享了Agent Skills核心概念。它通过元数据、指令和资源三层结构实现渐进式披露,显著降低Token消耗。以Claude Code为例,详细演示了Skills的创建、使用及进阶集成方法,帮助大家快速掌握Skills的核心概念和开发技巧,助力大家构建更强大的智能体!
当然很多粉丝和笔者一样受制于某些因素无法高效使用Claude Code,也对智谱等模型的订阅机制颇有异议(心疼自己钱包1秒),现在字节跳动的Trae也支持了Skills的编写调用,笔者日后也会分享Trae Skills调用的相关文章,大家敬请期待~
除大模型训练指南专栏外,笔者也在同步更新《深入浅出LangChain&LangGraph AI Agent 智能体开发》免费专栏,要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 37 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。

