刮个爽
184.81M · 2026-03-22

索引并非与生俱来就是B+树结构,但大多数人与MySQL打交道时,都默认了索引=B+树的认知。我们往往记住了最终的结论,却忽略了背后的迭代历程——它为何会从早期的查找树,一步步演化成如今的B+树?每一次迭代都在解决什么核心痛点,今天我们就来拆解MySQL索引结构的演变。
在追溯演进前,我们先明确一个核心前提:所有索引结构的设计,都围绕三大核心诉求平衡展开,这也是判断结构优劣的关键标尺。
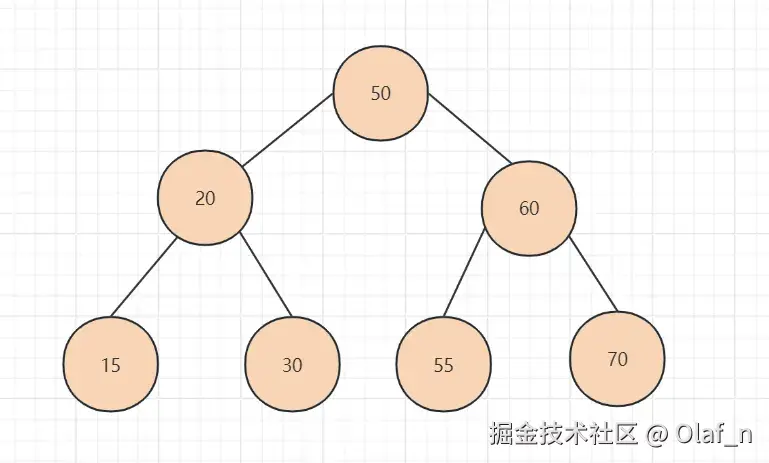
二叉查找树的特点如下
如图
核心结构:每个节点最多包含两个子节点,左子树的所有节点值小于父节点,右子树的所有节点值大于父节点,通过这种有序性实现快速查找。
查找逻辑:以查询值与父节点比较,小于则进入左子树,大于则进入右子树,依次递归,直到找到目标节点或遍历至空节点。
致命局限:完全无法适配MySQL的大数据量、磁盘存储场景
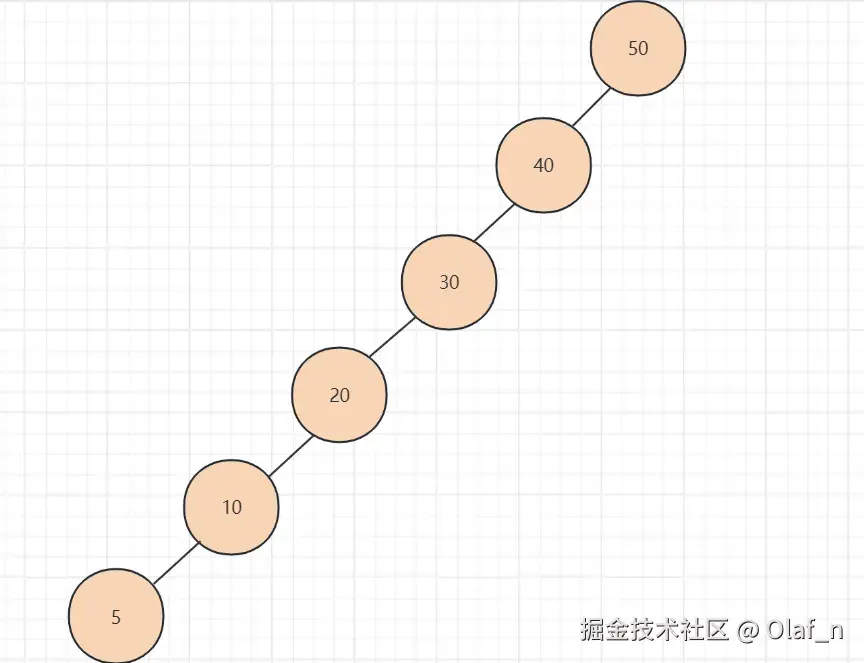
这种结构有一个致命的缺陷就是会退化成单链表,查找时间复杂度从O(logn)骤变为O(n),与全表扫描无异;比如这种数据情况【50,40,30,20,10,5】
树高过高百万级数据下,树高可达数十层甚至上百层,而磁盘IO是毫秒级操作,过多IO次数会导致查询极慢;
不支持范围查询高效遍历:需额外排序或全量遍历,无法满足MySQL高频范围查询需求。
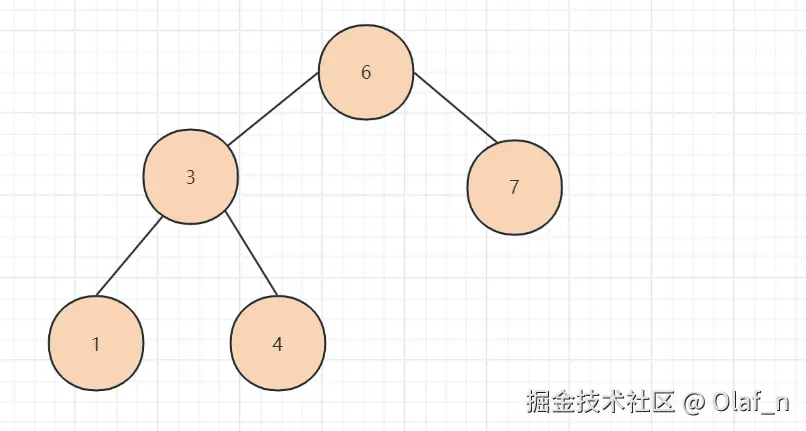
平衡二叉树的特点:在满足二叉搜索树的基础上,左树和右树的高度差绝对值不超过1
平衡二叉树可以通过左旋转和右旋转调整树的高度,使其维持基本的平衡,但是还有一个核心的问题还没有解决。树的高度问题,如果数据量过大,还是会导致这棵树的高度过高。
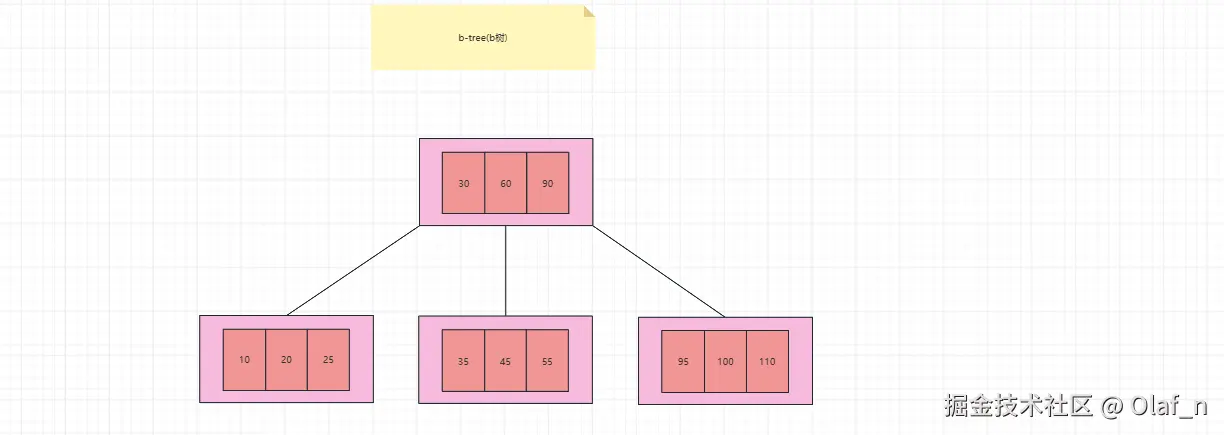
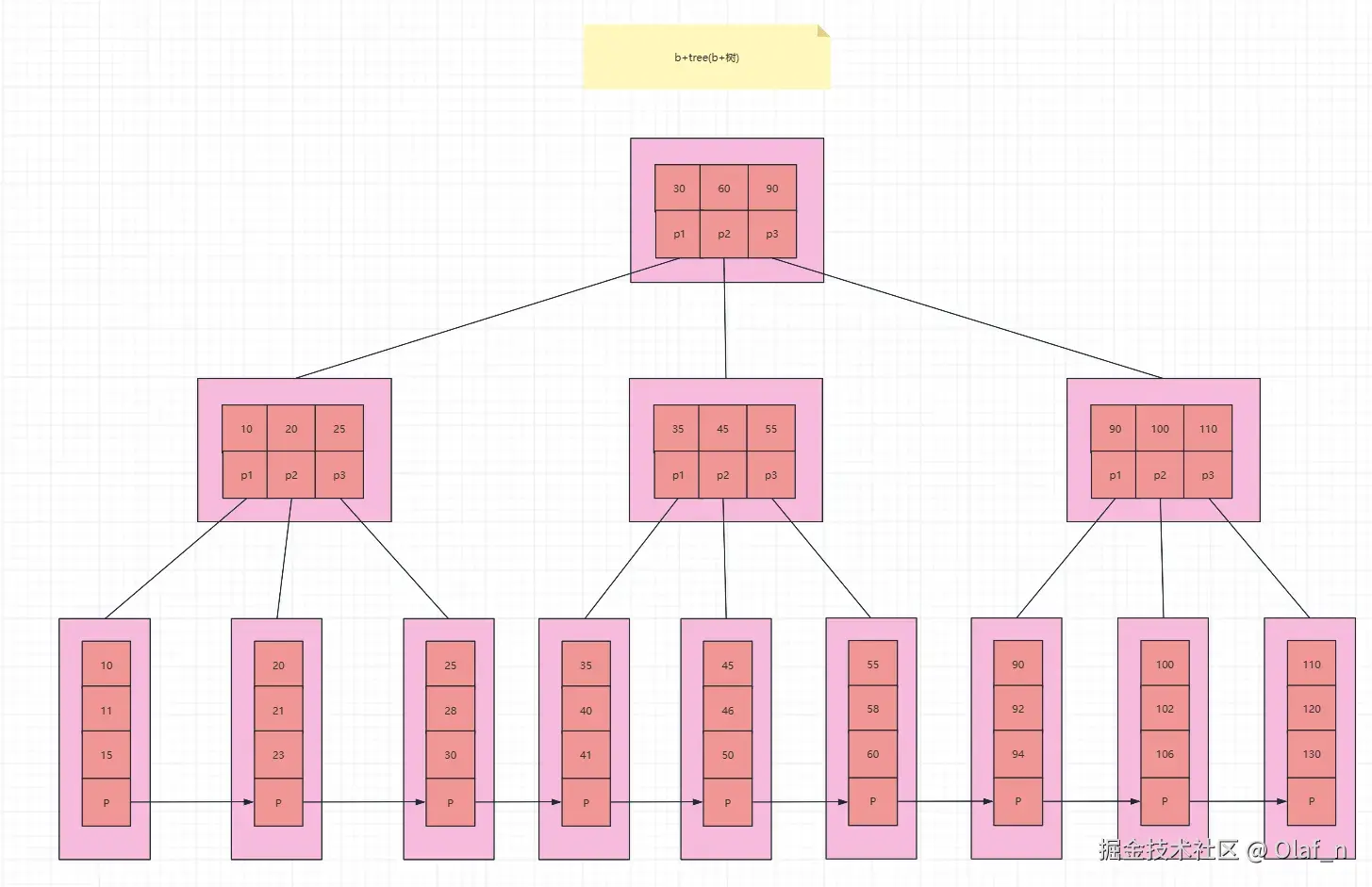
B树的本质上是一种多路查找树结构,B树的特征点是每一层节点存的都是真实数据。B树的结构如下
B树的查找流程
从根节点开始查找
根节点包含关键字 [30, 60, 90]。
根据 B 树的查找规则:
在目标子节点中查找数据
进入子节点 [35, 45, 55] 后,在该节点内部对关键字进行查找(顺序查找或二分查找)。
此时可以直接定位到 key = 45,对应的数据记录被成功命中,查找流程结束。
范围查询是B树相对容易暴露性能问题的场景。
首先定位范围起点
与单条查询类似,按照 B 树的查找规则,从根节点 [30, 60, 90] 出发,最终定位到包含起始 key = 45 的子节点 [35, 45, 55]。
在起始节点中进行扫描
在节点 [35, 45, 55] 中,从 key = 45 开始向右扫描,命中符合范围条件的数据:
[45, 55]
需要注意的是,此时范围查询不会结束,因为后续节点中仍然可能存在满足条件的 key。
回溯并切换到其他相关节点继续查找
扫描完当前子节点后,需要回溯到上层节点 [30, 60, 90],继续判断:
[95, 100, 110],在该节点中从左向右扫描,继续命中:[95, 100]
遍历结束,范围查询完成
当所有可能包含目标范围的数据节点都被访问后,查询结束。
最终命中的数据为:
[45, 55, 60, 90, 95, 100]
从上述流程可以明显看出B树的范围查询并非线性顺序扫描,查询过程中需要在子节点、父节点、兄弟节点 之间频繁切换
在数据库场景下,这种节点切换往往意味着额外的磁盘 IO
这正是 B 树在范围查询场景下的先天劣势,也是 B+ 树设计中重点优化的问题之一。
B+Tree 是针对 B树的改进,先来看看一看B+Tree长什么样子。
可以看到B+Tree对B-Tree做了以下改进
B+Tree的数据查找流程
从根节点开始查找
根节点中包含索引关键字 [30, 60, 90]。
根据 B+ 树的查找规则:
[35, 45, 55]。在非叶子节点中继续向下定位
虽然在节点 [35, 45, 55] 中已经可以看到 key = 45,
但此时查找不能停止,因为该节点是非叶子节点,只保存索引 key 与子节点指针,并不存储真实数据。
继续向下,直到叶子节点
沿着指针继续向下访问子节点,最终在某个叶子节点中定位到 key = 45,对应的数据记录。
至此,单条数据查找流程结束。
先定位范围起点
首先查找 key = 45,查找过程与单条查询完全一致,最终定位到包含 45 的叶子节点。
从起始叶子节点开始顺序扫描
在叶子节点中,从 key = 45 开始向右遍历,依次命中满足条件的数据。
沿叶子节点链表持续遍历
B+ 树中的所有叶子节点通过指针形成一个有序链表。
因此,当当前叶子节点扫描完成后,可以直接通过指针访问下一个叶子节点,无需回到父节点或重新查找。
直到超出范围为止
当扫描到 key > 100 时,范围查询结束。
最终命中的数据为:
[45, 46, 50, 55, 58, 60, 92, 94, 100]
与 B 树相比,B+ 树在范围查询中的优势非常明显:
在数据库场景下,这种顺序扫描方式可以显著减少磁盘 IO 次数,这也是 MySQL 等关系型数据库选择 B+ 树作为索引结构的核心原因之一。
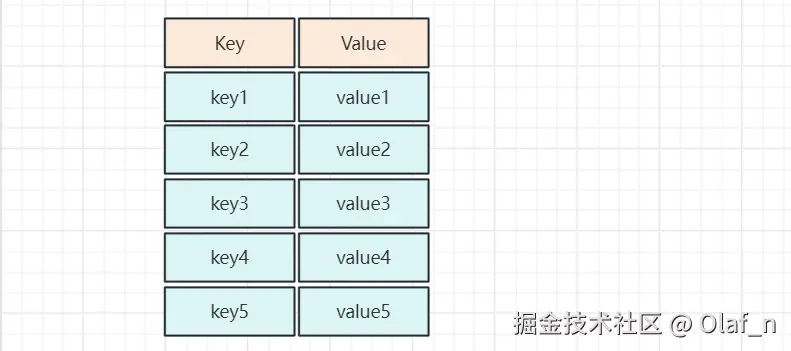
是一张表,里面有对应的key和value
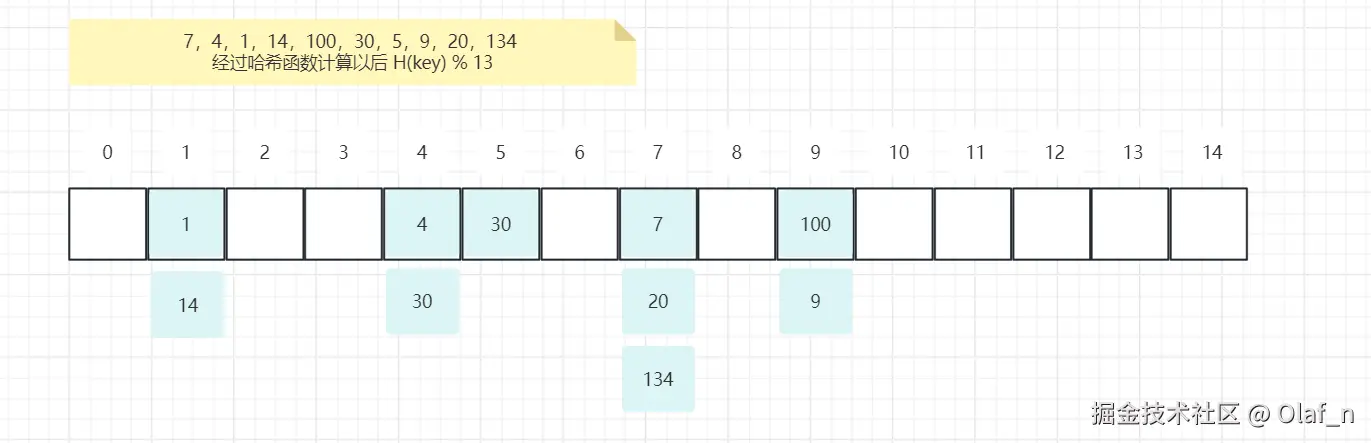
查询操作直接通过 get(key) 进行获取,时间复杂度O(1),好处是检索速度极快,缺点就是支持不了范围查找,还有一个问题就是但是Hash结构如果产生Hash冲突,会导致整个数据散列的不均匀,查找可能会退化成O(n)
等值查找可以直接get(key),但是如果想要完成范围查找就又得遍历整个hash表,效率很慢,hash就不合适了。在MySQL这类需要高效支撑大量范围查询的应用场景中,Hash结构并不适用,这也是为什么它未能成为主流数据库索引结构的重要原因。
MySQL索引结构的演进,本质上是一场围绕“高效查询、低存储成本、稳定性适配”三大核心诉求的持续优化之旅,每一代结构的迭代都精准解决了前序方案在数据库实际场景中的致命局限,最终沉淀出适配主流业务需求的B+树结构。
早期的二叉查找树凭借有序性实现了基础快速查找,但极易因数据分布失衡退化为单链表,且树高过高导致磁盘IO次数激增,完全无法适配大数据量、磁盘存储的数据库场景。平衡二叉树通过旋转调整机制解决了结构失衡问题,维持了查询时间复杂度的稳定性,但未能突破树高限制,面对海量数据时仍存在IO效率瓶颈。
B树作为多路查找树,通过多节点存储特性大幅降低了树高,减少了磁盘IO层级,一定程度上优化了查询效率。但B树的核心缺陷的在于范围查询时需在父子节点、兄弟节点间频繁切换,引发额外磁盘IO,在高频范围查询场景中性能受限,这也为B+树的出现埋下了伏笔。
B+树在B树基础上完成了关键性改进,成为MySQL索引的最优解。其一,实现数据与索引分离,非叶子节点仅存储索引指针,叶子节点集中存储所有真实数据,使查询路径固定统一,时间复杂度稳定在O(logN);其二,叶子节点通过链表有序连接,范围查询只需一次自顶向下定位起点,随后沿链表顺序扫描即可,彻底规避了节点间的频繁切换,大幅降低磁盘IO成本,完美适配数据库等值查询、范围查询、排序等核心业务场景。
而Hash索引虽能以O(1)时间复杂度实现等值查询,检索速度极快,但存在天然短板:无法支持范围查询,且Hash冲突可能导致性能退化为O(n),难以适配MySQL多样化的查询需求,因此仅适用于特定等值查询场景,无法成为主流索引结构。
总而言之MySQL索引结构的演进并非偶然,而是从场景需求出发,不断弥补前序结构缺陷、平衡各项性能指标的过程。B+树之所以成为主流,核心在于其精准契合了磁盘存储特性与数据库高频查询场景,在查询效率、稳定性与适配性上达到了最优平衡,而其他结构或因场景局限、或因性能短板,最终沦为特定场景的补充方案。这一演进逻辑也启示我们,索引结构的选择本质是对业务场景与性能需求的精准匹配。

