FC甜蜜之家
103.03M · 2026-03-26

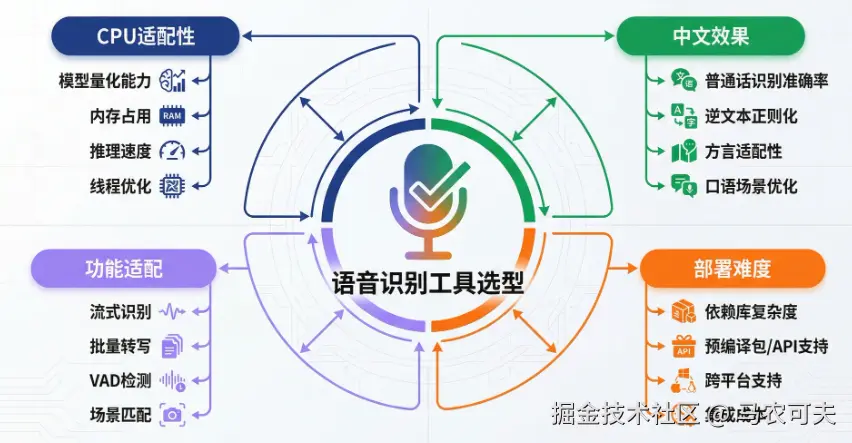
在语音识别(ASR)落地场景中,中文适配性、离线部署能力及CPU环境兼容性是核心诉求,尤其对于政务、客服、嵌入式终端等无GPU支持、需本地闭环运行的场景,选型直接决定项目落地效率与用户体验。本文基于PaddleSpeech、FunASR、Whisper V3等9款主流开源ASR模型,结合离线CPU部署需求,从适配性、效果、部署难度等维度展开分析,提供精准选型方案与落地建议。
针对中文离线CPU场景,需聚焦四大核心维度,避免因资源不匹配导致推理卡顿、精度不足等问题:
结合上述维度,对9款模型进行分级评估,按“优先推荐-可备选-不推荐”分类,明确各模型的适用边界。
此类模型在中文效果、CPU推理效率、部署便捷性上达到平衡,可直接落地工业级场景。
作为阿里达摩院面向中文场景优化的开源ASR工具包,FunASR是CPU离线部署的首选方案。其核心优势的在于中文适配深度与轻量量化能力:提供专为CPU优化的Nano模型,int8量化后体积仅100MB左右,内存占用低至500MB以下,单CPU(4线程)推理速度可达实时1.5倍以上,满足批量转写与流式识别双重需求。
部署层面,FunASR基于onnxruntime实现纯CPU离线运行,无需复杂依赖,支持Python/C++双接口,Windows与Linux系统均能快速集成,同时提供丰富的预训练模型(覆盖通用场景、政务、客服等垂直领域),可直接调用无需额外微调。适合政务语音转写、客服质检、本地桌面应用等对精度与效率均有要求的场景。
WeNet是工业级端到端ASR工具包,以低延迟流式识别为核心优势,完美适配CPU离线实时场景。其中文预训练模型基于大规模中文语料训练,普通话识别准确率优异,支持int8量化优化,CPU推理延迟可控制在100ms以内,且内存占用稳定,不会因长音频推理出现内存溢出问题。
部署上,WeNet提供轻量C++推理库与Python SDK,支持容器化部署与边缘设备集成,可灵活配置线程数与量化策略,适配不同CPU资源场景。相较于FunASR,WeNet在实时对话转写场景更具优势,适合政务实时交互终端、智能客服话术实时记录等场景。
SenseVoice以“轻量化一体化”为核心亮点,int8量化后模型体积229MB,内置VAD+ASR+标点预测全链路能力,无需额外集成第三方VAD工具,极大简化离线部署流程。其逆文本正则化能力突出,可精准转换数字、日期、金额等中文特殊表述,贴合实际业务场景需求。
该模型基于onnx格式分发,支持纯CPU离线运行,适配Windows、macOS、Linux多系统,甚至可部署至嵌入式设备(如ARM架构CPU)。推理速度在单CPU环境下可满足实时需求,适合轻量化离线转写、移动政务终端、嵌入式语音设备等资源受限但需全链路能力的场景。
此类模型存在部分短板,需根据具体场景取舍,仅在特定需求下考虑选用。
PaddleSpeech中文识别准确率极佳,且支持ASR+TTS+语音合成一体化能力,若项目需多语音功能联动,可作为备选。但其依赖PaddlePaddle框架,CPU环境下部署依赖项略多,模型量化后的体积与推理速度略逊于FunASR,单CPU推理实时性一般,适合结合飞桨生态、对多语音能力有需求的政务或企业级项目。
作为Whisper V3的优化版本,Faster-whisper通过量化与推理引擎优化,提升了CPU适配性,支持int8量化后模型体积缩小至原版本的1/4。其优势在于多语种支持与中英混读能力,若场景涉及少量英文内容,可作为备选。但CPU环境下推理速度仍较慢,仅适合短音频转写,长音频批量处理效率不足,且中文专有名词识别准确率略低于FunASR、WeNet。
Vosk是极致轻量化的离线ASR工具,中文小模型体积仅40MB,内存占用低于500MB,支持树莓派等低配置CPU设备,开箱即用无需复杂配置,部署难度极低。但其中文识别准确率一般,仅能满足日常简单语音转写需求,不适合对精度要求较高的政务、客服场景,仅推荐用于资源极度受限的轻量嵌入式设备。
DeepSpeech基于CTC架构,模型轻量化且文档完善,适合新手入门学习或小型离线项目。其CPU适配性良好,支持多系统部署,但中文预训练语料不足,识别准确率与逆文本正则化能力较弱,推理速度中等,仅推荐用于学习研究、原型验证等非工业级场景。
此类模型因体积过大、依赖GPU加速,在纯CPU环境下无法正常落地,直接排除。
结合业务场景快速锁定模型,可遵循以下决策逻辑:
为进一步提升CPU环境下的推理效率,可采用以下优化策略:
中文离线CPU环境下的ASR选型,核心是平衡“精度、效率、部署成本”三者关系。FunASR、WeNet、SenseVoice三款模型覆盖了绝大多数工业级场景,其中FunASR综合表现最优,可作为首选;WeNet与SenseVoice分别在流式识别、轻量化场景中具备独特优势,可针对性选用。
选型时需坚决排除GPU依赖型模型,同时根据业务场景的精度需求、资源限制、功能诉求,灵活调整模型与优化策略,确保项目高效落地。

