反物质维度
69.50M · 2026-03-22

ClickHouse® 是一个开源的列式数据库管理系统(DBMS),专为在线分析处理(OLAP)场景设计。项目采用 Apache 2.0 许可证,由 ClickHouse, Inc.(原 ClickHouse, Inc.)主导开发与维护。根据其活跃的社区活动、月度发布节奏以及全球范围的用户组聚会判断,该项目拥有活跃的开发者社区和用户基础。
ClickHouse 的核心是解决海量数据下的实时分析查询问题。传统行式数据库(如MySQL、PostgreSQL)在处理面向聚合、涉及大量数据扫描的分析查询时,会因不必要的列读取和较低的压缩效率面临I/O和计算瓶颈。
面临的挑战与对应场景:
解决方案与优势: ClickHouse 采用了 列式存储 作为根本解决方案。
商业价值逻辑估算: 其价值体现在替代传统MPP数据仓库或Hadoop/Spark组合方案所带来的成本下降与效率提升。
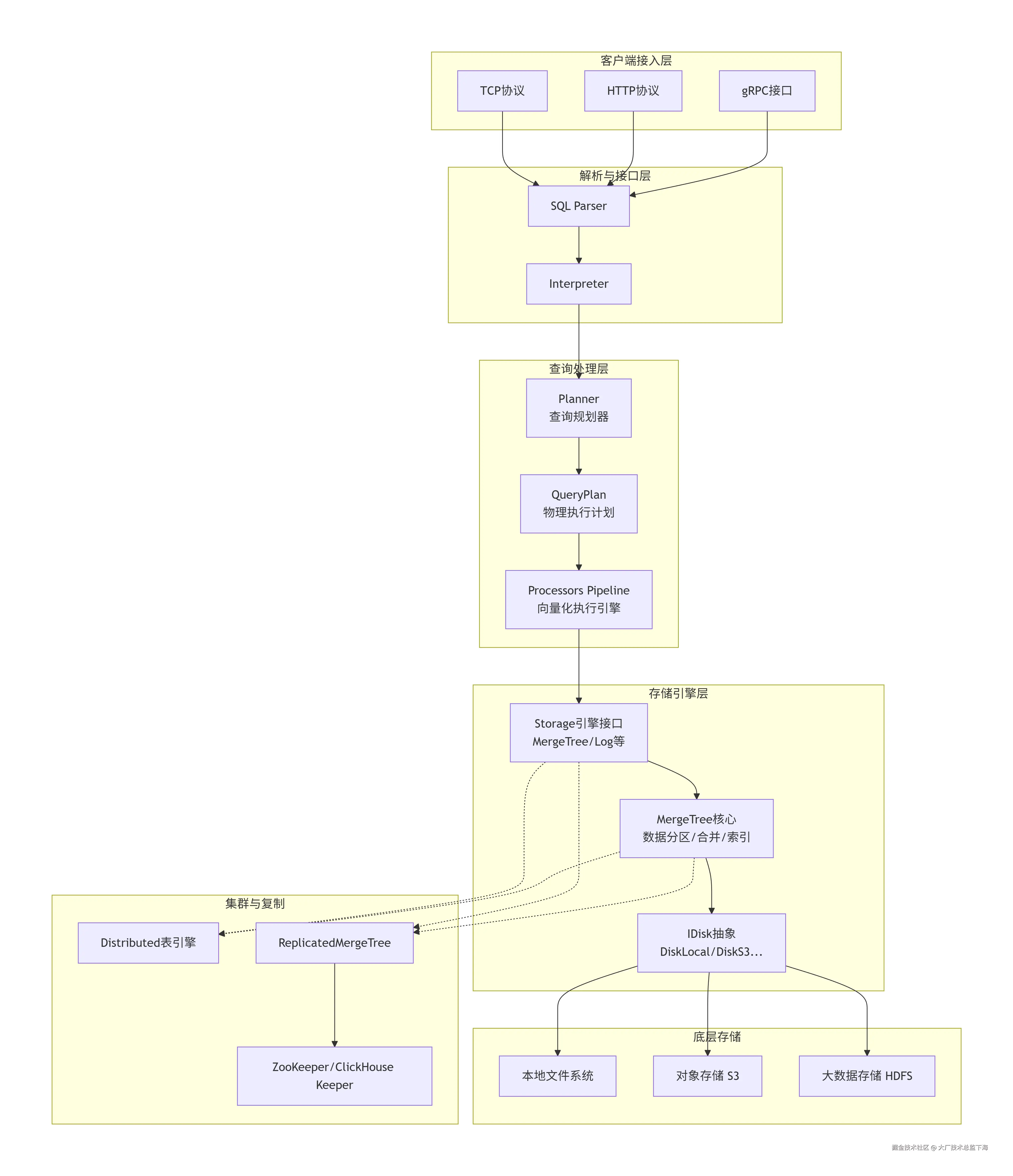
从提供的代码片段可以窥见ClickHouse核心架构的两个关键层面:查询规划与存储抽象。
Planner.h)Planner 类是将经过语法和语义分析后的查询树(QueryTreeNodePtr)转换为可执行的物理查询计划(QueryPlan)的核心组件。这是实现查询优化的关键环节。
QueryNodeToPlanStepMapping 结构支持高级特性如并行副本(parallel replicas)查询,这是实现横向扩展加速查询的关键。IDisk.h)IDisk 类是一个抽象接口,定义了所有存储媒介的通用操作(如读写文件、空间管理)。这是ClickHouse支持多存储后端(本地盘、S3、HDFS等)的基石。
readFile, writeFile, getAvailableSpace 等纯虚函数。DiskLocal, DiskS3, DiskHDFS 等具体实现。supportZeroCopyReplication)、对象存储集成(getObjectStorage)、加密文件处理等企业级功能所需的方法。createTransaction() 方法暗示了其对复杂文件操作原子性的支持框架。IDatabase.h)IDatabase 类抽象了数据库引擎的行为,负责表生命周期管理(创建、删除、附着、分离)。
CREATE DATABASE, ATTACH TABLE 等SQL语句的后端实现。loadStoredObjects, loadTableFromMetadataAsync, startupTableAsync 等方法揭示了ClickHouse支持异步加载和启动表元数据,这对于加速服务启动过程至关重要。DatabaseOrdinary, DatabaseMemory, DatabaseReplicated 等多种数据库引擎,适应不同一致性和持久化需求。IDatabaseTablesIterator 提供了遍历数据库表的统一方式,并支持快照(DatabaseTablesSnapshotIterator)。GROUP BY 并排序?涉及全局排序、聚合下推、本地与远程查询规划等复杂问题。Planner 看,其需要处理多种查询节点(QueryNode, UnionNode),并映射到物理算子树,同时考虑数据本地性、索引、采样等因素,设计难度大。IDisk 抽象需要无缝整合本地NVMe、SSD、远程S3/HDFS,并可能涉及缓存分层,其一致性和性能调优是持续挑战。sequenceDiagram
participant C as Client
participant S as Server
participant P as Parser/Interpreter
participant PLN as Planner
participant QP as QueryPlan Executor
participant STG as Storage(MergeTree)
participant DSK as IDisk
C->>S: 发送SQL查询
S->>P: 解析SQL, 生成AST
P->>PLN: 传递查询树(QueryTreeNodePtr)
PLN->>PLN: 逻辑优化/物理规划
PLN->>QP: 生成并返回QueryPlan
QP->>STG: 调用read()方法,传递查询条件
STG->>STG: 利用主键/分区键/跳数索引定位数据
STG->>DSK: 调用readFile()读取列数据文件(.bin)
DSK-->>STG: 返回数据缓冲区
STG-->>QP: 返回数据块(Block)
QP->>QP: 向量化处理(过滤/聚合等)
QP-->>P: 返回最终结果集
P-->>S: 格式化结果
S-->>C: 返回查询结果
classDiagram
class IDisk {
<<interface>>
+String name
+getPath() String
+readFile() ReadBufferFromFileBase*
+writeFile() WriteBufferFromFileBase*
+existsFile() bool
+getTotalSpace() UInt64
#copyThroughBuffers()
+getDataSourceDescription()
+isRemote() bool
}
class DiskLocal {
+String fs_path
+readFile() override
+writeFile() override
}
class DiskS3 {
+S3Client client
+String bucket
+readFile() override
+writeFile() override
+supportZeroCopyReplication() bool override
}
class Planner {
-QueryTreeNodePtr query_tree
-QueryPlan query_plan
+buildQueryPlanIfNeeded()
+buildPlanForQueryNode()
+buildPlanForUnionNode()
-QueryNodeToPlanStepMapping query_node_to_plan_step_mapping
}
class QueryPlan {
+std::vector~Node~ nodes
+addStep()
+addTree()
}
class IDatabase {
<<interface>>
+String database_name
+getTablesIterator() DatabaseTablesIteratorPtr
+tryGetTable() StoragePtr
+createTable()
+dropTable()
#getCreateTableQueryImpl() ASTPtr
}
class DatabaseOrdinary {
-String metadata_path
+loadStoredObjects() override
}
IDisk <|-- DiskLocal
IDisk <|-- DiskS3
IDatabase <|-- DatabaseOrdinary
注:Planner 与 IDisk、IDatabase 的协作通过 Storage 引擎和 Interpreter 间接进行,图中未展示全部关联。
Planner::buildQueryPlanIfNeeded() - 查询计划构建入口这是查询优化的触发器。其核心职责是分析查询树,将其转换为由一系列物理算子(IQueryPlanStep)组成的执行计划。
// 伪代码逻辑,展示Planner的核心工作流
void Planner::buildQueryPlanIfNeeded() {
if (query_plan.isInitialized()) return; // 避免重复构建
switch (query_tree->getNodeType()) {
case QueryTreeNodeType::QUERY:
buildPlanForQueryNode(); // 处理SELECT查询
break;
case QueryTreeNodeType::UNION:
buildPlanForUnionNode(); // 处理UNION查询
break;
// ... 处理其他节点类型,如 TABLE, JOIN 等
}
// 构建过程中会填充 query_node_to_plan_step_mapping
// 这可能用于后续的运行时统计或并行化策略调整
}
技术要点:
QueryNode, UnionNode),分别优化。query_node_to_plan_step_mapping 对于调试、性能分析和实现“读时写时复制”(Copy-on-Write)的并行查询至关重要。IDisk::readFile() 与 DiskS3::readFile() - 存储抽象的关键实现IDisk::readFile() 是一个纯虚函数,定义了读取文件的统一接口。其具体实现因存储后端而异。
IDisk 接口定义:
// 代码来源: src/Disks/IDisk.h (简化)
virtual std::unique_ptr<ReadBufferFromFileBase> readFile(
const String & path,
const ReadSettings & settings,
std::optional<size_t> read_hint = {}) const = 0;
path: 文件在磁盘抽象层内的路径。settings: 包含IO调度、缓存、超时等高级控制参数。read_hint: 预读大小的提示,用于优化连续读取。DiskS3 的简化实现逻辑:
// 伪代码,展示 DiskS3::readFile() 的可能实现
std::unique_ptr<ReadBufferFromFileBase> DiskS3::readFile(
const String & path, const ReadSettings & settings, std::optional<size_t>) const override
{
// 1. 将逻辑路径转换为S3对象键
String object_key = s3_root_path + path;
// 2. 创建并配置一个面向S3的ReadBuffer
// 它内部会调用 AWS SDK 的 GetObject 操作
auto buffer = std::make_unique<ReadBufferFromS3>(
s3_client,
bucket,
object_key,
settings
);
// 3. 可能附加缓存层(如本地SSD缓存)
if (settings.read_from_filesystem_cache_if_exists_otherwise_bypass_cache) {
buffer = wrapWithCache(std::move(buffer), cache_disk);
}
return buffer;
}
技术要点:
IDisk 接口作为抽象部分,DiskS3 等作为实现部分,使上层存储引擎可以独立于具体存储后端演化。ReadBufferFromFileBase 对象负责管理数据缓冲。实现中可以灵活加入多层缓存(内存、本地文件系统),这对远程存储的性能至关重要。ReadSettings 允许从查询层面到底层IO进行细致的性能调优控制。IDatabase::getTablesIterator() - 元数据遍历的抽象此函数是 SHOW TABLES 或数据库内部管理表的基础。
// 代码来源: src/Databases/IDatabase.h (简化)
virtual DatabaseTablesIteratorPtr getTablesIterator(
ContextPtr context,
const FilterByNameFunction & filter_by_table_name = {},
bool skip_not_loaded = false) const = 0;
实现分析(以DatabaseOrdinary为例的伪代码):
DatabaseTablesIteratorPtr DatabaseOrdinary::getTablesIterator(
ContextPtr context,
const FilterByNameFunction & filter,
bool skip_not_loaded) const
{
// 1. 扫描元数据目录(如 /var/lib/clickhouse/metadata/db_name/)
std::vector<std::string> table_meta_files = disk->iterateDirectory(metadata_path);
// 2. 加载并过滤
Tables loaded_tables;
for (const auto & file : table_meta_files) {
String table_name = stripExtension(file);
if (filter && !filter(table_name)) continue;
// 3. 关键:可能触发表的懒加载
StoragePtr storage = tryGetTable(table_name, context);
if (!storage && skip_not_loaded) continue;
loaded_tables.emplace(table_name, storage); // storage可能为nullptr
}
// 4. 返回迭代器快照
return std::make_unique<DatabaseTablesSnapshotIterator>(std::move(loaded_tables), database_name);
}
技术要点:
tryGetTable 调用可能触发从元数据文件(.sql)异步加载表结构。skip_not_loaded 参数允许调用者决定是否等待加载完成。DatabaseTablesSnapshotIterator 在构造时已固定表列表,避免了在迭代过程中因表被创建或删除而产生的竞态条件。ClickHouse 通过列式存储这一根本设计,结合向量化执行引擎和丰富的表引擎,系统性地解决了海量数据分析的性能瓶颈。其架构清晰,通过 Planner、IDisk、IDatabase 等核心抽象层,实现了查询优化、存储解耦和元数据管理的高度模块化。从代码中体现出的对异步操作、缓存、事务性文件操作的支持,反映出其在追求极致性能的同时,也兼顾了工程上的健壮性和扩展性。尽管在应对高频点更新等场景时仍有其设计取舍,但ClickHouse在OLAP领域,尤其是在需要实时查询吞吐量的场景下,无疑是一个经过深度优化且设计严谨的系统。

