先发制人2026
72.36M · 2026-03-22

在开发联系人管理系统时,我遇到了一个经典的数据库查询问题——笛卡尔积导致的数据重复。本文将详细记录这个问题的发现、分析和解决过程,希望能帮助遇到类似问题的开发者。
我使用 Java 实现了一个联系人管理系统,系统具有以下特点:
数据库设计采用了典型的多对多关联表结构:
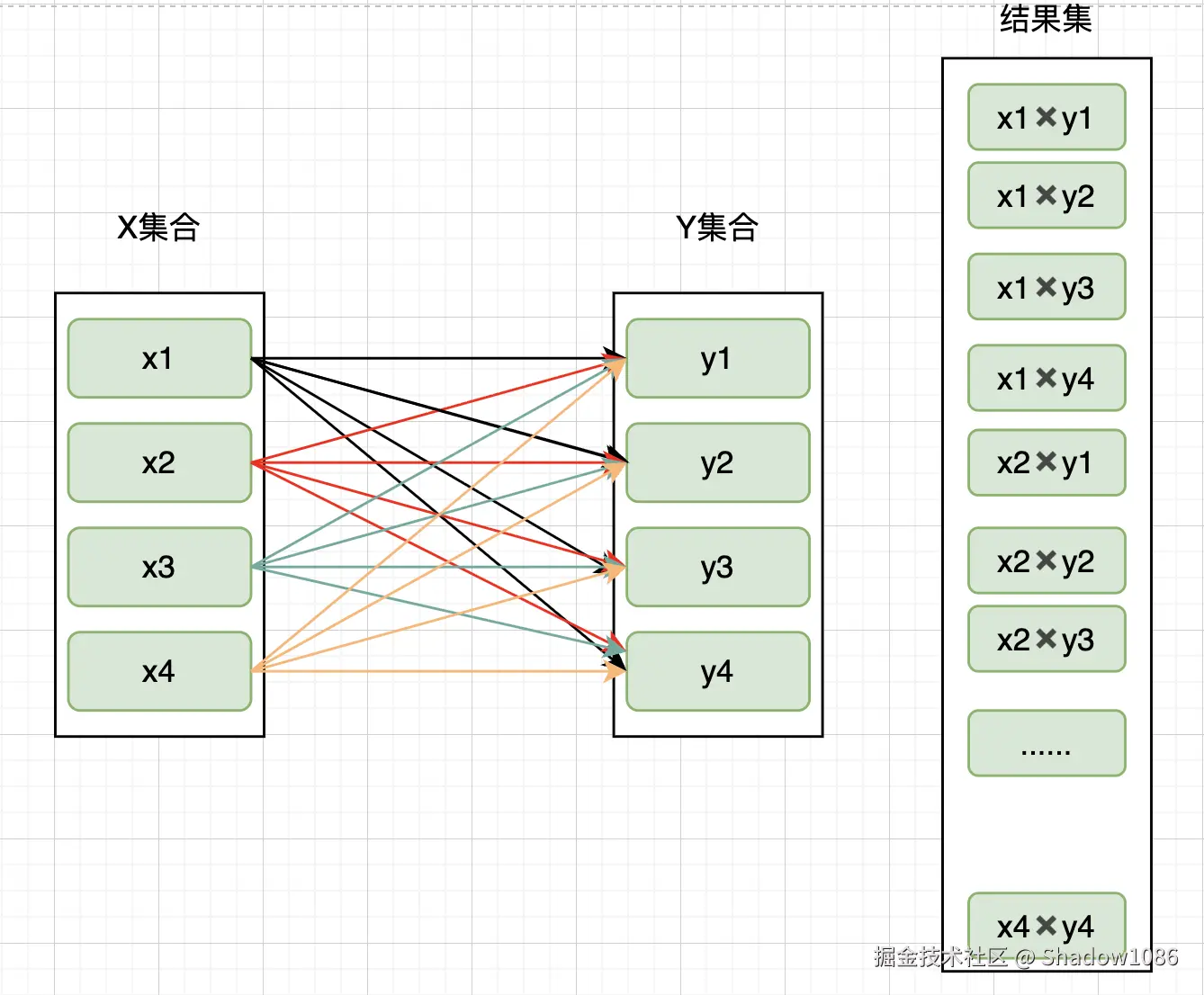
contacts - 联系人表groups - 分组表contacts_group - 联系人与分组的关联表tags - 标签表tag_contacts - 联系人与标签的关联表笛卡尔积(Cartesian Product)是指两个集合 X 和 Y 中所有元素的组合。
举例说明:如果集合 X = {1, 2, 3, 4},集合 Y = {A, B, C, D},那么它们的笛卡尔积将产生 4 × 4 = 16 个元素对:
(1,A), (1,B), (1,C), (1,D),
(2,A), (2,B), (2,C), (2,D),
(3,A), (3,B), (3,C), (3,D),
(4,A), (4,B), (4,C), (4,D)
在数据库查询中,笛卡尔积的出现绝大多数情况下都是错误的逻辑,会导致:
在实现文件导出功能时,我发现了一个奇怪的现象:
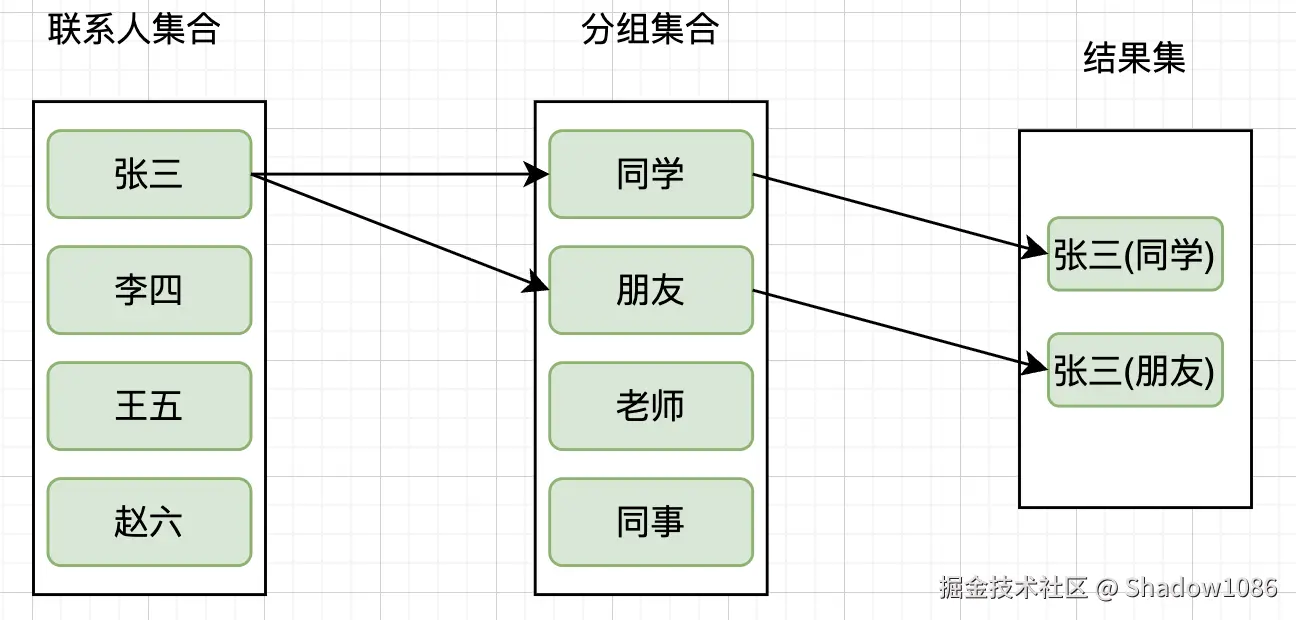
预期结果:导出一个联系人"张三",包含他的所有分组和标签
实际结果:导出了多个"张三",每个"张三"只包含一个分组
例如,张三有两个分组("同学"和"朋友"),导出时会出现:
这显然不是我想要的结果!
经过排查,我发现问题出在查询语句上。下面是最初的 SQL 查询:
SELECT c.name, c.tele1, c.tele2, c.home, c.email, c.notes,
g.group_name, t.tag_name
FROM contacts c
LEFT JOIN contacts_group cg ON c.id = cg.contacts_id
LEFT JOIN groups g ON g.id = cg.group_id
LEFT JOIN tag_contacts tc ON c.id = tc.contacts_id
LEFT JOIN tags t ON t.id = tc.tag_id
这个查询语句存在严重的笛卡尔积问题:
假设场景:
查询结果:会产生 2 × 2 = 4 条记录!
| name | group_name | tag_name |
|---|---|---|
| 张三 | 同学 | 重要 |
| 张三 | 同学 | 工作 |
| 张三 | 朋友 | 重要 |
| 张三 | 朋友 | 工作 |
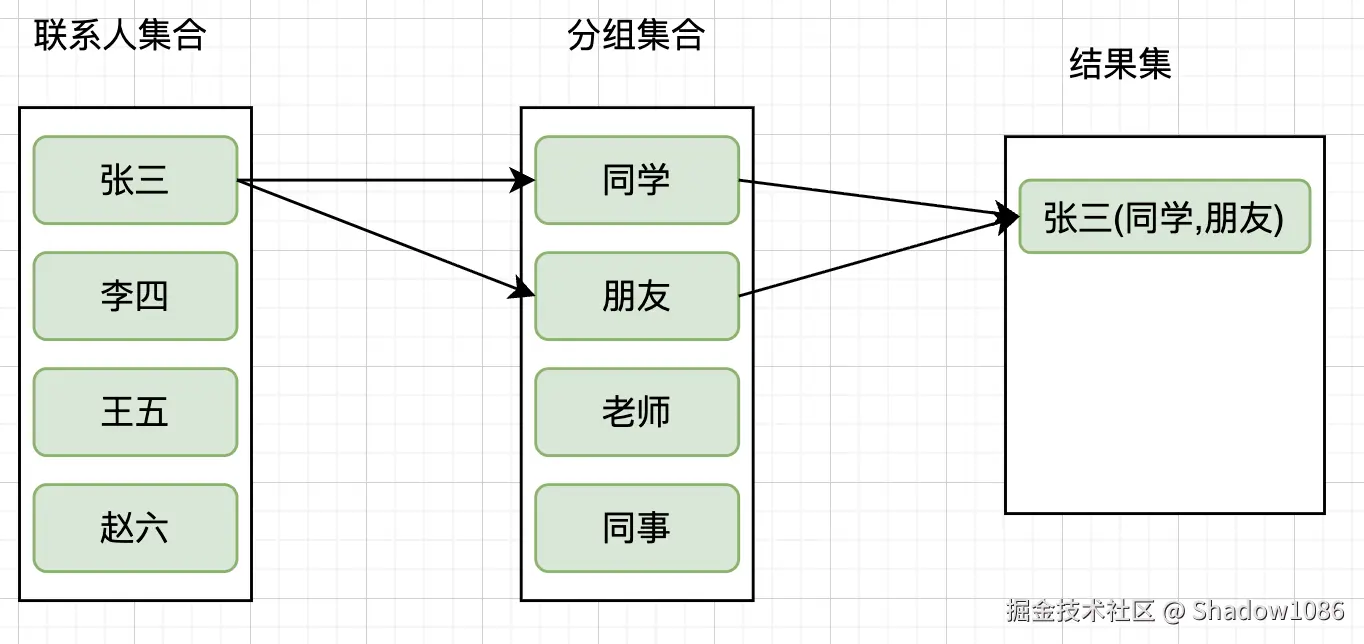
我们期望的结果:只有 1 条记录,包含所有分组和标签
| name | groups | tags |
|---|---|---|
| 张三 | 同学,朋友 | 重要,工作 |
聚合函数(Aggregate Function)是对一组值执行计算并返回单个值的函数。常见的聚合函数包括:
COUNT() - 计数SUM() - 求和AVG() - 平均值MAX() / MIN() - 最大值/最小值GROUP_CONCAT() - 字符串连接(本文重点)GROUP_CONCAT() 函数可以将分组内的多个值连接成一个字符串,这正是我们需要的功能!
基本语法:
GROUP_CONCAT([DISTINCT] expression [SEPARATOR separator])
参数说明:
DISTINCT:可选,去除重复值expression:要连接的字段或表达式SEPARATOR:分隔符,默认为逗号SELECT
c.name,
c.tele1,
c.tele2,
c.home,
c.email,
c.notes,
-- 聚合所有分组名称,用逗号分隔
GROUP_CONCAT(DISTINCT g.group_name, ',') AS groups,
-- 聚合所有标签,格式为"标签名(颜色)"
GROUP_CONCAT(DISTINCT t.tag_name || '(' || t.tag_color || ')', ',') AS tags
FROM contacts c
LEFT JOIN contacts_group cg ON c.id = cg.contacts_id
LEFT JOIN groups g ON g.id = cg.group_id
LEFT JOIN tag_contacts tc ON c.id = tc.contacts_id
LEFT JOIN tags t ON t.id = tc.tag_id
-- 按联系人 ID 分组,确保每个联系人只有一条记录
GROUP BY c.id;
代码解析:
分组聚合:
GROUP_CONCAT(DISTINCT g.group_name, ',') AS groups
DISTINCT 确保不会出现重复的分组名标签拼接:
GROUP_CONCAT(DISTINCT t.tag_name || '(' || t.tag_color || ')', ',') AS tags
|| 是 SQLite 的字符串拼接运算符tags += tag_name + "(" + tag_color + ")""同学(黄色),朋友(绿色)"GROUP BY 子句:
GROUP BY c.id
LEFT JOIN 的作用:
查询结果示例:
假设联系人"张三"有分组"同学"、"朋友",标签"同学(黄色)"、"朋友(绿色)":
groups = "同学,朋友"
tags = "同学(黄色),朋友(绿色)"
MySQL 的语法略有不同,主要体现在字符串拼接和分隔符的写法上:
SELECT
c.name,
c.tele1,
c.tele2,
c.home,
c.email,
c.notes,
-- MySQL 使用 SEPARATOR 关键字指定分隔符
GROUP_CONCAT(DISTINCT g.group_name SEPARATOR ',') AS groups,
-- MySQL 使用 CONCAT 函数拼接字符串
GROUP_CONCAT(DISTINCT CONCAT(t.tag_name, '(', t.tag_color, ')') SEPARATOR ',') AS tags
FROM contacts c
LEFT JOIN contacts_group cg ON c.id = cg.contacts_id
LEFT JOIN groups g ON g.id = cg.group_id
LEFT JOIN tag_contacts tc ON c.id = tc.contacts_id
LEFT JOIN tags t ON t.id = tc.tag_id
GROUP BY c.id;
SQLite 与 MySQL 的差异对比:
| 功能 | SQLite | MySQL |
|---|---|---|
| 字符串拼接 | || 运算符 | CONCAT() 函数 |
| 分隔符指定 | 直接用逗号 ',' | 使用 SEPARATOR ',' 关键字 |
在 Java 代码中,我们需要对查询结果进行解析:
// 从数据库查询结果中获取聚合后的字符串
String groupsStr = resultSet.getString("groups");
String tagsStr = resultSet.getString("tags");
// 将字符串分割成数组
String[] groups = groupsStr != null ? groupsStr.split(",") : new String[0];
String[] tags = tagsStr != null ? tagsStr.split(",") : new String[0];
// 设置到联系人对象中
contact.setGroups(Arrays.asList(groups));
contact.setTags(Arrays.asList(tags));
注意事项:
null(联系人可能没有分组或标签)split(",") 方法将字符串分割成数组使用聚合函数后,查询结果完美符合预期:
优化前:
优化后:
笛卡尔积的危害:
GROUP BY 和聚合函数解决GROUP_CONCAT 的使用场景:
LEFT JOIN 的重要性:
DISTINCT 避免重复数据LEFT JOIN 保证数据完整性GROUP BY 的情况下使用聚合函数这个问题的解决过程让我深刻理解了数据库查询中笛卡尔积的危害,以及聚合函数的强大之处。在实际开发中,遇到类似的多对多关系查询时,一定要注意数据聚合的问题。
如果你也遇到了类似的问题,希望这篇文章能对你有所帮助!

